Vyrovnávání zatížení
Potřeba vyrovnávání zatížení v computingu vychází ze dvou základních požadavků: Zaprvé, vysoká dostupnost se dá zlepšit replikací. Za druhé se dá zlepšit výkon paralelním zpracováním. Vysoká dostupnost je vlastnost služby, která je k dispozici téměř 100 % času, kdy se kterýkoli klient pokouší o přístup ke službě. Kvalita určité služby (QoS) obecně zahrnuje několik hledisek, například požadavky na propustnost a latenci.
Co je vyrovnávání zatížení?
Nejznámější forma vyrovnávání zatížení je DNS s kruhovým dotazováním, které mnoho velkých webových služeb používá k vyrovnávání zatížení mezi několika servery. Konkrétně jde o to, že několik front-endových webových serverů, z nichž každý má jedinečnou IP adresu, sdílí název DNS. Aby bylo možné vyrovnávat počet požadavků na každém z těchto webových serverů, udržují a spravují velké společnosti jako Google fond IP adres přidružených k jednotlivým položkám DNS. Když klient odešle požadavek (například do domény www.google.com), dns Google vybere jednu z dostupných adres z fondu a odešle ji klientovi. Nejjednodušší strategií rozesílání IP adres je použití jednoduché fronty kruhového dotazování, kde se po každé odpovědi DNS změní pořadí adres v seznamu.
Před nástupem cloudu bylo vyrovnávání zatížení DNS jednoduchým způsobem, jak si poradit s latencí u vzdálených připojení. Dispečer na serveru DNS byl naprogramovaný tak, aby vrátil IP adresu serveru, který je ke klientovi geograficky nejblíž. Nejjednodušší schémata, jak to provést, zahrnovala pokus o vrácení takové IP adresy z fondu, která byla číselně nejbližší k IP adrese klienta. Tato metoda byla samozřejmě nespolehlivá, protože neexistuje žádná globální hierarchie distribuce IP adres. Současné techniky jsou propracovanější a spoléhají na softwarové mapování IP adres na polohy na základě fyzických map poskytovatelů internetových služeb (ISP). Vzhledem k tomu, že je tato metoda implementovaná jako nákladné softwarové vyhledávání, poskytuje sice přesnější výsledky, ale je náročná na výpočetní výkon. Náklady na pomalé vyhledávání jsou však zanedbatelné, protože k vyhledávání DNS dojde jenom tehdy, když klient naváže první připojení k serveru. Veškerá následná komunikace probíhá přímo mezi klientem a serverem, který vlastní odeslanou IP adresu. Na následujícím obrázku je znázorněna ukázka schématu vyrovnávání zatížení DNS.
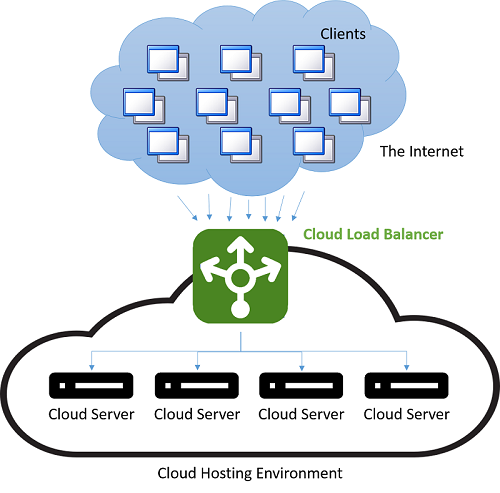
Obrázek 4: Vyrovnávání zatížení v cloudovém hostitelském prostředí
Nevýhoda této metody spočívá v tom, že při selhání serveru je přepnutí na jinou IP adresu závislé na konfiguraci TTL (Time to Live) mezipaměti DNS. Je známo, že položky DNS jsou dlouhodobé a že rozšíření aktualizací na internetu trvá více než týden. Proto je obtížné rychle „skrýt“ selhání serveru před klientem. Může pomoct omezení doby platnosti IP adresy v mezipaměti, to ale za cenu snížení výkonu a zvýšení počtu hledání.
Moderní vyrovnávání zatížení často využívá vyhrazenou instanci (nebo dvojici instancí) ke směrování příchozích přenosů na back-endové servery. U každé příchozí žádosti na zadaném portu přesměruje nástroj pro vyrovnávání zatížení provoz na jeden z back-endových serverů na základě strategie distribuce. Díky tomu nástroj pro vyrovnávání zatížení zachová metadata požadavku včetně informací, jako jsou hlavičky aplikačních protokolů (například hlavičky HTTP). V této situaci nenastává problém se zastaralými informacemi, protože každý požadavek prochází nástrojem pro vyrovnávání zatížení.
Všechny typy nástrojů pro vyrovnávání zatížení sítě budou jednoduše předávat informace uživatele spolu s jakýmkoli kontextem back-endovým serverům, ale pokud jde o odeslání odpovědi zpátky klientovi, můžou použít jednu ze dvou základních strategií:1
- Proxy: V tomto přístupu nástroj pro vyrovnávání zatížení obdrží odpověď z back-endu a předá ji zpět klientovi. Nástroj pro vyrovnávání zatížení se chová jako standardní webový proxy server a je zapojen do obou polovin síťové transakce, konkrétně předat žádost klientovi a poslat zpátky odpověď.
- Předávání protokolu TCP U tohoto přístupu se back-endovému serveru předává připojení TCP ke klientovi. Proto server odesílá odpověď přímo klientovi. Odpověď tedy neprochází přes nástroj pro vyrovnávání zatížení.
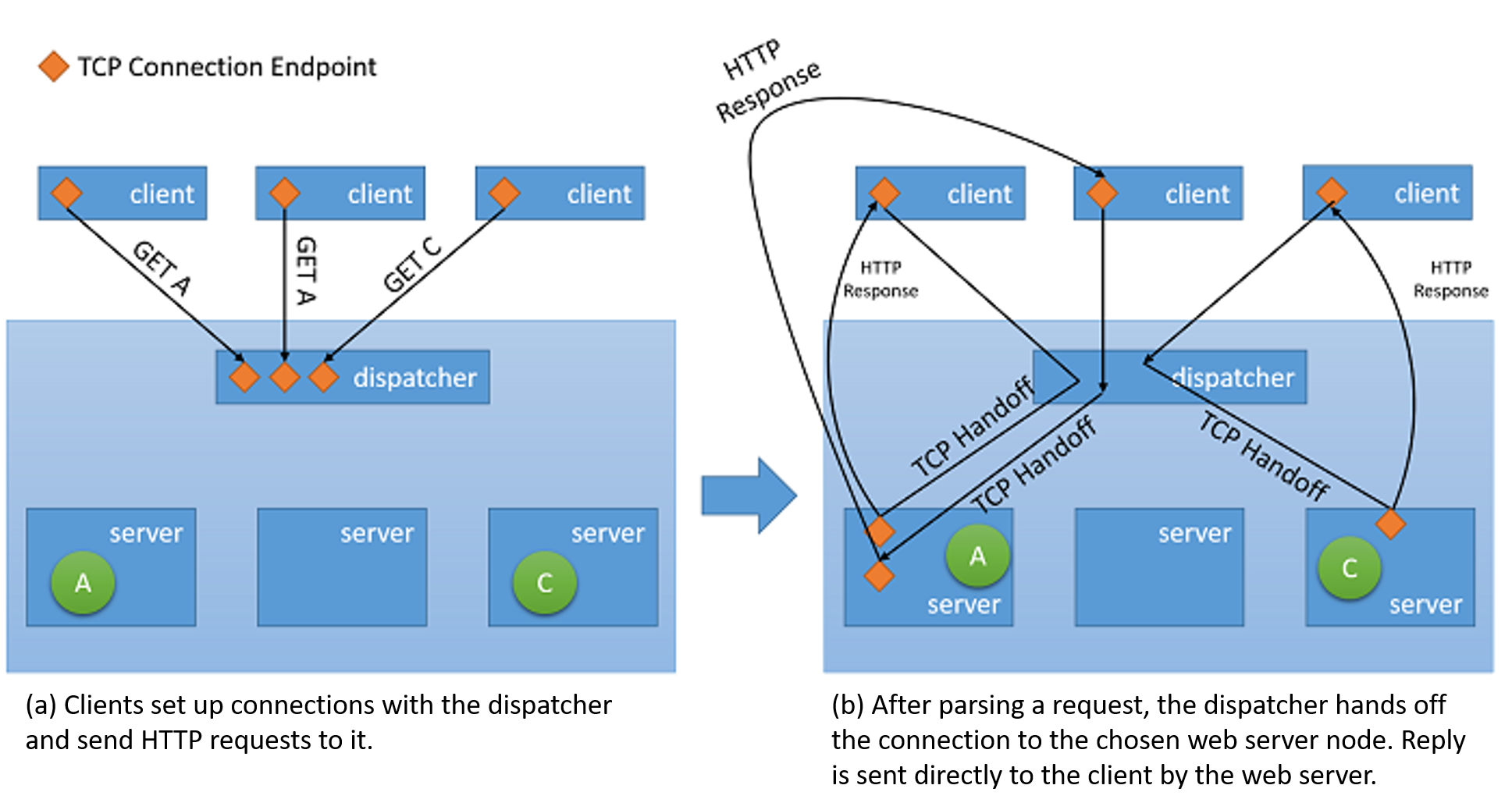
Obrázek 5: Mechanismus předání protokolu TCP od dispečera do back-endového serveru
Dopad na dostupnost a výkon
Vyrovnávání zatížení je důležitou strategií, jak maskovat selhání v systému. Pokud je klient systému vystavený jedinému koncovému bodu, který vyrovnává zatížení mezi několika prostředky, můžou být chyby v jednotlivých prostředcích před klientem zamaskovány jednoduše tak, že se obsluhy požadavku ujme jiný prostředek. Je ale důležité uvědomit si, že nástroj pro vyrovnávání zatížení se v takovém případě stává kritickým prvkem způsobujícím selhání služby. Pokud z nějakého důvodu selže, tak i kdyby všechny back-endové servery stále fungovaly, nebude možné zpracovat žádné požadavky klientů. Proto se kvůli zajištění vysoké dostupnosti implementují nástroje pro vyrovnávání zatížení často ve dvojicích.
Vyrovnávání zatížení umožňuje službě distribuovat úlohy napříč několika výpočetními prostředky v cloudu. Využívání jediné výpočetní instance v cloudu má několik omezení. Už jsme si popsali, že nastává fyzické omezení výkonu, když je při zvýšení zatížení potřeba více prostředků. Díky vyrovnávání zatížení můžou být větší objemy úloh distribuované do několika prostředků. Každý prostředek tak může uspokojovat přijaté požadavky nezávisle a souběžně, což zvýší propustnost aplikace. Také se tím zkrátí průměrná doba obsluhy, protože je k dispozici více serverů, které můžou úlohy zpracovat.
Služby zjišťování a monitorování jsou klíčem k úspěchu strategií vyrovnávání zatížení. Nástroj pro vyrovnávání zatížení musí zajistit splnění všech požadavků, a to tím, že zajistí dostupnost uzlů všech prostředků. V opačném případě není přenos směrován do konkrétního uzlu. Mezi nejoblíbenější způsoby, jak zkontrolovat stav uzlu konkrétního prostředku, patří monitorování příkazem ping-echo. Aby bylo možné vyhodnotit nejvhodnější prostředek pro přímý přenos, vyžadují některé strategie vyrovnávání zatížení kromě stavu uzlu i další informace, například údaje o propustnosti, latenci a využití procesoru.
Nástroje pro vyrovnávání zatížení musí často zaručit vysokou dostupnost. Nejjednodušší způsob, jak to provést, je vytvořit několik instancí vyrovnávání zatížení (každou s jedinečnou IP adresou) a propojit je s jedinou adresou DNS. Kdykoli dojde v instanci nástroje pro vyrovnávání zatížení z nějakého důvodu k chybě, nahradí se novou instancí. Veškerý provoz se pak předává do instance, která převzala služby při selhání. Dopad na výkon je minimální. Současně může být nová instance nástroje pro vyrovnávání zatížení nakonfigurovaná tak, aby nahradila tu, ve které došlo k chybě. Záznamy DNS by se měly hned aktualizovat.
Strategie vyrovnávání zatížení
V cloudu se používá několik strategií vyrovnávání zatížení.
Spravedlivé rozesílání
Toto je statický přístup k vyrovnávání zatížení, ve kterém se používá jednoduchý algoritmus kruhového dotazování. Ten rozděluje provoz rovnoměrně mezi všechny uzly, aniž by bral v úvahu využití konkrétních uzlů prostředků v systému nebo zohledňoval dobu vyřizování požadavků. Tento přístup se snaží udržet všechny uzly v systému zaneprázdněné a patří mezi přístupy s nejjednodušší implementací. Velkou nevýhodou tohoto přístupu je, že se může velké množství požadavků klientů agregovat v jednom datacentru, což způsobí, že několik uzlů bude zahlcených, zatímco jiné zůstanou nevyužité. Jde ovšem o situaci s velmi specifickým průběhem zatížení a je málo pravděpodobné, že by k ní v praxi došlo na velkém počtu klientů a serverů s poměrně jednotnou distribucí a kapacitou připojení. Při zvolení této strategie je ale obtížné implementovat strategie ukládání do mezipaměti v datacentru, které zohledňuje okolnosti jako geografická lokalita (kde předběžně načítáte a ukládáte do mezipaměti data v blízkosti právě načtených dat), protože další požadavek od stejného klienta může skončit na jiném serveru.
AWS používá tento přístup ve své nabídce ELB (Elastic Load Balancer). AWS ELB zřizuje nástroje pro vyrovnávání zatížení, které vyrovnávají provoz mezi připojenými instancemi EC2. Nástroje pro vyrovnávání zatížení jsou v podstatě také instancemi EC2, které jsou přímo zaměřeny na směrování provozu. Pokud dojde k horizontálnímu navýšení kapacity prostředků nástroje pro vyrovnávání zatížení, IP adresy nových prostředků se na záznamu DNS nástroje pro vyrovnávání zatížení aktualizují. Provedení tohoto procesu trvá několik minut, protože vyžaduje čas na monitorování i zřízení. Toto období škálování (doba, během které se nástroj pro vyrovnávání zatížení připravuje na zpracování vyššího zatížení) se označuje jako „zahřívání“ nástroje pro vyrovnávání zatížení.
Nástroje pro vyrovnávání zatížení ELB od AWS také monitorují u připojených prostředků distribuci úloh, aby mohly udržovat kontrolu stavu. K zajištění, aby všechny prostředky byly v dobrém stavu, se používá mechanismus příkazu ping-ozvěna. Uživatelé ELB můžou nakonfigurovat parametry kontroly stavu zadáním zpoždění a počtu opakování.
Distribuce na základě hodnoty hash
Tento přístup se snaží zajistit, aby požadavky odesílané klientem přes stejné připojení vždy skončily na stejném serveru. Navíc je to kvůli vyrovnání distribuce požadavků prováděno v náhodném pořadí. Oproti kruhovému dotazování má tento přístup několik výhod, například v aplikacích pracujících s relacemi, ve kterých můžou být trvalost stavu a strategie ukládání do mezipaměti mnohem jednodušší. Díky náhodné distribuci je zde také menší pravděpodobnost, že by určitý vzorec provozu vedl k zaseknutí dat na jednom serveru, i když zcela toto riziko vyloučit nelze. U každého požadavku se ale musí vyhodnotit metadata připojení kvůli směrování na správný server, proto dochází u požadavků k určité latenci.
Azure Load Balancer používá takový mechanismus založený na hashování jako způsob distribuce zatížení. Tento mechanismus vytvoří hodnotu hash pro každý požadavek na základě zdrojové IP adresy, zdrojového portu, cílové IP adresy, cílového portu a typu protokolu, aby se zajistilo, že každý paket ze stejného připojení vždy dorazí na stejný server. Je zvolena taková funkce hash, která zajistí dostatečně náhodnou distribuci připojení k serverům.
Azure poskytuje kontroly stavu prostřednictvím tří typů testů: sondy agenta hosta (na virtuálních počítačích PaaS), vlastní testy HTTP a vlastní sondy TCP. Všechny tři typy testů zajišťují kontrolu stavu pro uzly prostředků prostřednictvím mechanismu příkazu ping-echo.
Další oblíbené strategie
Existují i jiné strategie, jak vyrovnávat zatížení mezi několika prostředky. Každá z nich používá jiné metriky k měření nejvhodnějšího uzlu prostředku pro konkrétní požadavek:
- Strategie založené na době provádění požadavků: Tyto strategie používají algoritmus plánování priority, kdy se používají doby provádění požadavků k posouzení nejvhodnějšího pořadí distribuce zatížení. Hlavní problém tohoto přístupu spočívá v tom, že dobu provádění požadavku nelze přesně předvídat.
- Strategie založené na využití prostředků: Tyto strategie používají využití procesoru na každém uzlu prostředků k vyvážení využití napříč jednotlivými uzly. Nástroje pro vyrovnávání zatížení udržují seznam, kde jsou prostředky řazeny podle využití, aby mohly každý požadavek směrovat do nejméně zatíženého uzlu.
Jiné výhody
Centralizovaný nástroj pro vyrovnávání zatížení se uplatní hned v několika strategiích, které můžou zvýšit výkon služby. Je ale potřeba počítat s tím, že tyto strategie fungují jen tehdy, když nástroj pro vyrovnávání zatížení není přetížený. V opačném případě bude vše brzdit právě nástroj pro vyrovnávání zatížení. Některé z těchto strategií jsou uvedeny níže:
- Přesměrování zpracování SSL: Síťové transakce přes SSL mají spojené další náklady, protože potřebují zpracovávat šifrování a ověřování. Místo obsluhy všech požadavků přes SSL je možné využívat protokol SSL jen k připojení klienta k nástroji pro vyrovnávání zatížení, ale požadavky na přesměrování na jednotlivé servery vytvářet prostřednictvím protokolu HTTP. Tím se zatížení serverů výrazně sníží. A pokud se požadavky na přesměrování neprovádějí v otevřené síti, je navíc zajištěno i zabezpečení.
- Ukládání do vyrovnávací paměti PROTOKOLU TCP: Jedná se o strategii pro snižování zátěže klientů s pomalými připojeními k nástroji pro vyrovnávání zatížení, aby se uvolnily servery, které obsluhují odpovědi těmto klientům.
- Ukládání do mezipaměti: V některých scénářích může nástroj pro vyrovnávání zatížení udržovat mezipaměť pro nejoblíbenější požadavky (nebo požadavky, které je možné zpracovat bez přechodu na servery, jako je statický obsah), aby snížil zatížení serverů.
- Formování provozu: U některých aplikací se dá nástroj pro vyrovnávání zatížení použít ke zpoždění a přepisování toku paketů tak, aby se provoz mohl formovat tak, aby vyhovoval konfiguraci serveru. I když tento přístup u některých požadavků ovlivní QoS, může být díky němu příchozí zatížení obslouženo.
Odkazy
- Aron, Mohit and Sanders, Darren and Druschel, Peter and Zwaenepoel, Willy (2000). Škálovatelná distribuce požadavků pracujících s obsahem v síťových serverech založených na clusterech z konference Proceedings of the 2000 Annual USENIX technical Conference