Obecné vzory pro vícevláknové aplikace s nevhodným chováním
Vizualizér souběžnosti pomáhá vývojářům vizualizovat chování vícevláknové aplikace. Tento nástroj obsahuje galerii běžných vzorů pro vícevláknové aplikace, které se chovají špatně. Galerie obsahuje typické a rozpoznatelné vizuální vzory, které jsou vystaveny nástrojem, spolu s vysvětlením chování, které je reprezentováno jednotlivými vzory, pravděpodobného výsledku tohoto chování a nejběžnějším přístupem k jeho vyřešení.
Uzamčení kolizí a serializované spuštění

V některých případech paralelizovaná aplikace opakovaně provádí sériově, i když má několik vláken a počítač má dostatečný počet logických jader. Prvním příznakem je nízký výkon s více vlákny, možná i trochu pomalejší než sériová implementace. V zobrazení vláken nevidíte více vláken spuštěných paralelně; místo toho vidíte, že se spouští kdykoli pouze jedno vlákno. Pokud v tomto okamžiku kliknete na synchronizační segment ve vlákně, zobrazí se zásobník volání blokovaného vlákna (blokující zásobník volání) a vlákno, které odebralo blokující podmínku (odblokování zásobníku volání). Kromě toho, pokud v procesu, který analyzujete, dojde k odblokování zásobníku volání, zobrazí se konektor připravený pro vlákno. Od tohoto okamžiku můžete přejít do kódu z blokujících a odblokovat zásobníky volání, abyste prozkoumali příčinu serializace ještě více.
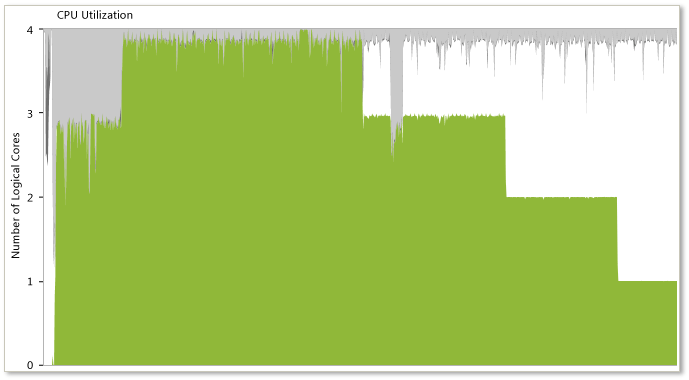
Jak je znázorněno na následujícím obrázku, vizualizér souběžnosti může tento příznak zveřejnit také v zobrazení využití procesoru, kde i přes přítomnost více vláken aplikace spotřebovává pouze jedno logické jádro.
Další informace naleznete v části "Začínáme s problémem" v článku Výkon vláken - Výkon prostředků Kolizí prostředků v sadě Visual Studio.

Nerovnoměrná distribuce úloh

Když v aplikaci dojde k nepravidelné distribuci práce napříč několika paralelními vlákny, zobrazí se typický vzor schodišťového kroku, protože každé vlákno dokončí svou práci, jak je znázorněno na předchozím obrázku. Vizualizér souběžnosti nejčastěji zobrazuje časy spuštění velmi blízko pro každé souběžné vlákno. Tato vlákna však obvykle končí nepravidelným způsobem místo toho, aby končila současně. Tento model označuje nepravidelné rozdělení práce mezi skupinu paralelních vláken, což by mohlo vést ke snížení výkonu. Nejlepším přístupem k takovému problému je znovu vyhodnotit algoritmus, pomocí kterého byla práce rozdělena mezi paralelní vlákna.
Jak je znázorněno na následujícím obrázku, Vizualizér souběžnosti může tento příznak zveřejnit také v zobrazení využití procesoru jako postupné krok dolů v využití procesoru.
Oversubscription
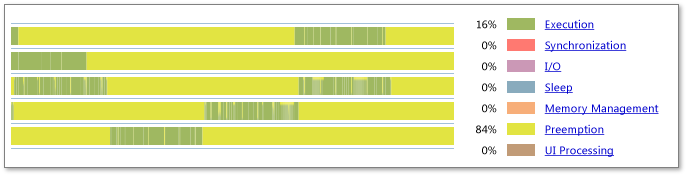
V případě nadměrného indexování je počet aktivních vláken v procesu větší než počet dostupných logických jader v systému. Předchozí obrázek znázorňuje výsledky nadměrného indexování s významným pruhováním preempce ve všech aktivních vláknech. Kromě toho legenda ukazuje velké procento času strávené v preemption (84 procent v tomto příkladu). To může znamenat, že proces žádá systém, aby spustil více souběžných vláken než počet logických jader. To však může také znamenat, že jiné procesy v systému používají prostředky, u které se předpokládá, že budou pro tento proces k dispozici.
Při vyhodnocování tohoto problému byste měli zvážit následující skutečnosti:
Celkový systém může být přepsán. Vezměte v úvahu, že ostatní procesy v systému můžou předcházet omezením vašich vláken. Když se pozastavíte nad segmentem preemption v zobrazení vláken, popis identifikuje vlákno a proces, který přerušil vlákno. Tento proces nemusí být nutně ten, který se spustil během celé doby, kdy byl proces zrušen, ale poskytuje nápovědu k tomu, co vytvořilo tlak preempce proti vašemu procesu.
Vyhodnoťte, jak proces určuje odpovídající počet vláken pro spuštění během této fáze práce. Pokud proces přímo vypočítá počet aktivních paralelních vláken, zvažte úpravu tohoto algoritmu, aby lépe odpovídal počtu dostupných logických jader v systému. Pokud používáte Concurrency Runtime, paralelní knihovnu úloh nebo PLINQ, tyto knihovny provádějí výpočet počtu vláken.
Neefektivní vstupně-výstupní operace

Nadměrné využití nebo zneužití vstupně-výstupních operací je běžnou příčinou nedostatečné efektivity v aplikacích. Představte si předchozí obrázek. Profil viditelné časové osy ukazuje, že vstupně-výstupní operace spotřebovávají 44 % času viditelného vlákna. Časová osa zobrazuje velké objemy vstupně-výstupních operací, což značí, že profilovaná aplikace je často blokovaná vstupně-výstupními operacemi. Pokud chcete zobrazit podrobnosti o typech vstupně-výstupních operací a tom, kde je program blokovaný, přibližte problematické oblasti, prozkoumejte profil viditelné časové osy a kliknutím na konkrétní vstupně-výstupní blok zobrazte aktuální zásobníky volání.
Uzamčení konvojů

Konvoje zámků nastanou, když aplikace získá zámky v objednávce, která nastane při prvním doručení, a když je míra přijetí u zámku vyšší než míra získání. Kombinace těchto dvou podmínek způsobí, že požadavek na zámek začne zálohovat. Jedním ze způsobů, jak tento problém vyřešit, je použít "nespravedlivé" zámky nebo zámky, které poskytují přístup k prvnímu vláknu, aby je našli v odemknutých stavech. Předchozí obrázek znázorňuje toto chování konvoje. Pokud chcete tento problém vyřešit, zkuste snížit kolize synchronizačních objektů a zkuste použít nespravedlivé zámky.