Grundlegendes zu Pfadlängen in Azure NetApp Files
Datei- und Pfadlänge bezieht sich auf die Anzahl von Unicode-Zeichen in einem Dateipfad (einschließlich Verzeichnissen). Dieses Limit ist ein Faktor für die individuellen Zeichenlängen, die durch die Größe des Zeichens in Bytes bestimmt werden. Beispielsweise sind bei NFS und SMB Pfadkomponenten mit einer Größe von 255 Bytes zulässig. Das Dateicodierungsformat von ASCII (American Standard Code for Information Interchange) verwendet eine 8-Bit-Codierung. Das bedeutet, Dateipfadkomponenten (z. B. Datei- oder Ordnernamen) in ASCII können bis zu 255 Zeichen lang sein, da ASCII-Zeichen 1 Byte groß sind.
Die folgende Tabelle zeigt die unterstützten Komponenten- und Pfadlängen in Azure NetApp Files-Volumes:
| Komponente | NFS | SMB |
|---|---|---|
| Größe der Pfadkomponente | 255 Bytes | 255 Bytes |
| Größe der Pfadlänge | Unbegrenzt | Standardwert: 255 Bytes Maximaler Wert in höheren Windows-Versionen: 32.767 Bytes |
| Maximale Pfadgröße auf Transversalebene | 4.096 Bytes | 255 Bytes |
Hinweis
Volumes mit zwei Protokollen verwenden den niedrigsten Maximalwert.
Wenn ein SMB-Freigabename \\SMB-SHARE lautet, erhöht er die Pfadlänge um 11 Unicode-Zeichen, da jedes Zeichen 1 Byte groß ist. Wenn der Pfad zu einer bestimmten Datei \\SMB-SHARE\apps\archive\file lautet, sind es 29 Unicode-Zeichen. jedes Zeichen (einschließlich der Schrägstriche) ist 1 Byte groß. Für NFS-Einbindungen gelten die gleichen Konzepte. Der Einbindungspfad /AzureNetAppFiles umfasst 17 Unicode-Zeichen mit einer jeweiligen Größe von 1 Byte.
Azure NetApp Files unterstützt die gleiche Pfadlänge für SMB-Freigaben wie moderne Windows-Server: bis zu 32.767 Bytes. Abhängig von der Version des Windows-Clients werden von einigen Anwendungen jedoch möglicherweise keine Pfade mit mehr als 260 Bytes unterstützt. Einzelne Pfadkomponenten (die Werte zwischen Schrägstrichen, z. B. Datei- oder Ordnernamen) unterstützen bis zu 255 Bytes. Beispielsweise darf ein Dateiname mit dem lateinischen Großbuchstaben „A“ (beansprucht 1 Byte pro Zeichen) in einem Dateipfad in Azure NetApp Files 255 Zeichen nicht überschreiten.
# mkdir 256charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
mkdir: cannot create directory ‘256charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa’: File name too long
# mkdir 255charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# ls | grep 255
255charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
Unterscheiden von Zeichengrößen
Das Linux-Hilfsprogramm uniutils kann verwendet werden, um die Bytegröße von Unicode-Zeichen zu ermitteln. Geben Sie hierzu mehrere Instanzen der Zeicheninstanz ein, und sehen Sie sich das Feld byte an.
Beispiel 1: Jede Verwendung des lateinischen Großbuchstabens A führt zu einer Erhöhung um 1 Byte (mit einzelnem Hexadezimalwert 41, der sich im Bereich zwischen 0 und 255 der ASCII-Zeichen befindet).
# printf %b 'AAA' | uniname
character byte UTF-32 encoded as glyph name
0 0 000041 41 A LATIN CAPITAL LETTER A
1 1 000041 41 A LATIN CAPITAL LETTER A
2 2 000041 41 A LATIN CAPITAL LETTER A
Ergebnis 1: Der Name „AAA“ beansprucht 3 von 255 Bytes.
Beispiel 2: Jede Instanz des japanischen Zeichens „字“ erhöht den Wert um 3 Bytes. Dies kann auch mithilfe der drei separaten Hexadezimalcode-Werte (E5, AD, 97) unter dem Feld encoded as berechnet werden. Die Hexadezimalwerte stellen jeweils 1 Byte dar:
# printf %b '字字字' | uniname
character byte UTF-32 encoded as glyph name
0 0 005B57 E5 AD 97 字 CJK character Nelson 1281
1 3 005B57 E5 AD 97 字 CJK character Nelson 1281
2 6 005B57 E5 AD 97 字 CJK character Nelson 1281
Ergebnis 2: Eine Datei mit dem Namen „字字字“ beansprucht 9 von 255 Bytes.
Beispiel 3: Der Buchstabe „Ä“ mit Diärese beansprucht 2 Bytes pro Instanz (C3 + 84).
# printf %b 'ÄÄÄ' | uniname
character byte UTF-32 encoded as glyph name
0 0 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
1 2 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
2 4 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
Ergebnis 3: Eine Datei mit dem Namen „ÄÄÄ“ beansprucht 6 von 255 Bytes.
Beispiel 4: Ein Sonderzeichen wie etwa das Emoji 😃 fällt in einen nicht definierten Bereich, der über die für Unicode-Zeichen verwendeten 0 bis 3 Bytes hinausgeht. Daher wird ein Ersatzzeichenpaar für die Zeichencodierung verwendet. In diesem Fall beansprucht jede Instanz des Zeichens 4 Bytes.
# printf %b '😃😃😃' | uniname
character byte UTF-32 encoded as glyph name
0 0 01F603 F0 9F 98 83 😃 Character in undefined range
1 4 01F603 F0 9F 98 83 😃 Character in undefined range
2 8 01F603 F0 9F 98 83 😃 Character in undefined range
Ergebnis 4: Eine Datei mit dem Namen „😃😃😃“ beansprucht 12 von 255 Bytes.
Die meisten Emojis fallen in den Bereich von 4 Bytes. Manche können aber auch bis zu 7 Bytes beanspruchen. Von den mehr als tausend Standard-Emojis gehören ca. 180 zur grundlegenden mehrsprachigen Ebene (Basic Multilingual Plane, BMP). Das bedeutet, dass sie in Azure NetApp Files je nach clientseitiger Unterstützung des Sprachtyps als Text oder als Emoji angezeigt werden können.
Ausführlichere Informationen zu BMP und zu anderen Unicode-Ebenen finden Sie unter Grundlegendes zu Volumesprachen in Azure NetApp Files.
Auswirkungen von Zeichenbytes auf Pfadlängen
Die Pfadlänge wird zwar als Anzahl von Zeichen in einem Datei- oder Ordnernamen betrachtet, tatsächlich handelt es sich dabei jedoch um die Größe der unterstützten Bytes im Pfad. Da sich durch jedes Zeichen die Bytegröße eines Namens erhöht, unterstützen unterschiedliche Zeichensätze in unterschiedlichen Sprachen unterschiedliche Dateinamenlängen.
Betrachten Sie die folgenden Szenarien:
Bei einer Datei oder einem Ordner wird im Dateinamen das Zeichen „A“ aus dem lateinischen Alphabet wiederholt. (Beispiel: AAAAAAAA)
Da „A“ 1 Byte beansprucht und das Größenlimit der Pfadkomponente 255 Bytes beträgt, wären in einem Dateinamen 255 Instanzen von „A“ zulässig.
Bei einer Datei oder einem Ordner wird das japanische Zeichen „字“ im Namen wiederholt.
Da „字“ eine Größe von 3 Bytes hat, ist die Länge des Dateinamens auf 85 Instanzen von „字“ (3 Bytes × 85 = 255 Bytes) bzw. auf insgesamt 85 Zeichen beschränkt.
Bei einer Datei oder einem Ordner wird das grinsende Emoji (😃) im Namen wiederholt.
Ein grinsendes Emoji (😃) beansprucht 4 Bytes, was bedeutet, dass ein Dateiname, der außer diesem Emoji keine anderen Zeichen enthält, dieses Emoji insgesamt 64 Mal (255 Bytes/4 Bytes) enthalten kann.
- Für eine Datei oder einen Ordner wird eine Kombination aus verschiedenen Zeichen (z. B. „Name字😃“) verwendet.
Wenn in einem Datei- oder Ordnernamen verschiedene Zeichen mit unterschiedlichen Bytegrößen verwendet werden, wird die Bytegröße jedes Zeichens in die Datei- oder Ordnerlänge einbezogen. Der Datei- oder Ordnername „Name字😃“ beansprucht beispielsweise 11 Bytes (1+1+1+1+3+4) der Gesamtlänge von 255 Bytes.
Konzepte für spezielle Emojis
Spezielle Emojis (z. B. Flaggen-Emojis) fallen unter die BMP-Klassifizierung: Das Emoji wird je nach Clientunterstützung als Text oder Bild gerendert. Wenn ein Client die Bildbereitstellung nicht unterstützt, verwendet er stattdessen regionale textbasierte Bereitstellungen.
Für die US-Flagge werden beispielsweise die Zeichen „us“ verwendet. Diese ähneln zwar den lateinischen Zeichen „U“ und „S“, sind aber tatsächlich Sonderzeichen mit unterschiedlicher Codierung. Uniname zeigt die Unterschiede zwischen den Zeichen.
# printf %b 'US' | uniname
character byte UTF-32 encoded as glyph name
0 0 000055 55 U LATIN CAPITAL LETTER U
1 1 000053 53 S LATIN CAPITAL LETTER S
# printf %b '🇺🇸' | uniname
character byte UTF-32 encoded as glyph name
0 0 01F1FA F0 9F 87 BA 🇺 Character in undefined range
1 4 01F1F8 F0 9F 87 B8 🇸 Character in undefined range
Zeichen für die Flaggen-Emojis werden in unterstützten Systemen in Flaggenbilder umgewandelt. In nicht unterstützten Systemen bleiben sie dagegen Textwerte. Diese Zeichen beanspruchen jeweils 4 Bytes, sodass die Verwendung eines Flaggen-Emojis zu insgesamt 8 Bytes führt. Somit sind insgesamt 31 Flaggen-Emojis in einem Dateinamen zulässig (255 Bytes/8 Bytes).
SMB-Pfadlimits
Standardmäßig unterstützen Windows-Server und -Clients Pfadlängen von bis zu 260 Bytes. Aufgrund von Metadaten, die Windows-Pfaden hinzugefügt werden (z. B. der Wert <NUL> und Domäneninformationen), sind die tatsächlichen Dateipfadlängen allerdings kürzer.
Bei Überschreitung eines Pfadlimits unter Windows wird ein Dialogfeld angezeigt:
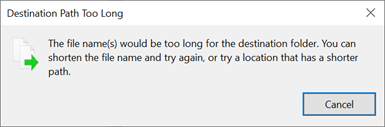
SMB-Pfadlängen können durch die Verwendung von Windows 10/Windows Server 2016 (ab Version 1607) oder durch Änderung eines Registrierungswerts erweitert werden, wie unter Beschränkung der maximal zulässigen Pfadlänge beschrieben. Durch Änderung dieses Werts können Pfade auf eine Länge von bis zu 32.767 Bytes (abzüglich Metadatenwerten) erweitert werden.
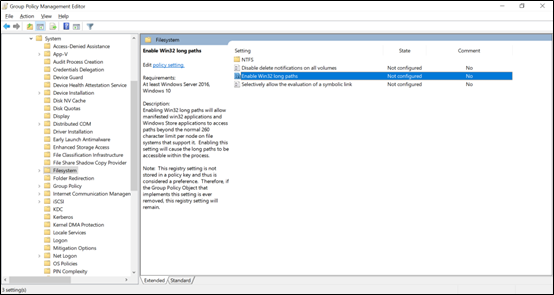
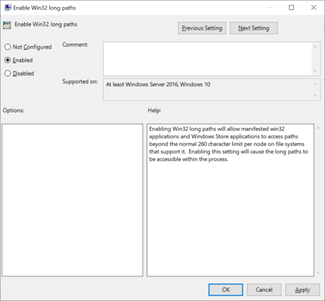
Nach Aktivierung dieses Features müssen Sie beim Zugriff auf die SMB-Freigabe \\?\ im Pfad verwenden, um längere Pfade zuzulassen. Diese Methode unterstützt keine UNC-Pfade. Daher muss die SMB-Freigabe einem Laufwerkbuchstaben zugeordnet werden.
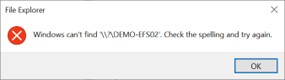
Die Verwendung von \\?\Z: ermöglicht den Zugriff und unterstützt längere Dateipfade.

Hinweis
CMD unter Windows unterstützt die Verwendung von \\?\ derzeit nicht.
Problemumgehung, wenn die maximale Pfadlänge nicht erhöht werden kann
Wenn die maximale Pfadlänge in der Windows-Umgebung nicht aktiviert werden kann oder die Windows-Clientversionen zu niedrig sind, gibt es eine Problemumgehung. Sie können die SMB-Freigabe tiefer in die Verzeichnisstruktur einbinden und die Länge des abgefragten Pfads verringern.
Verwenden Sie also beispielsweise nicht die Zuordnung „\\NAS-SHARE\AzureNetAppFiles zu Z:“, sondern „\\NAS-SHARE\AzureNetAppFiles\folder1\folder2\folder3\folder4 zu Z:“.
NFS-Pfadlimits
Bei NFS-Pfadlimits für Azure NetApp Files-Volumes gilt das gleiche Limit von 255 Bytes für einzelne Pfadkomponenten. Jede Komponente wird jedoch einzeln ausgewertet und kann bis zu 4.096 Bytes pro Anforderung mit einer nahezu unbegrenzten Gesamtpfadlänge verarbeiten. Wenn also beispielsweise jede Pfadkomponente 255 Bytes umfasst, kann ein NFS-Client bis zu 15 Komponenten pro Anforderung auswerten (einschließlich /-Zeichen). Eine cd-Anforderung für einen Pfad, der über das Limit von 4.096 Bytes hinausgeht, führt zu einer Fehlermeldung mit dem Hinweis, dass der Dateiname zu lang ist.
In den meisten Fällen beanspruchen Unicode-Zeichen maximal 1 Byte, sodass der Grenzwert von 4.096 Bytes mit 4.096 Zeichen gleichzusetzen ist. Wenn ein Zeichen größer als 1 Byte ist, beträgt die Pfadlänge weniger als 4.096 Zeichen. Zeichen mit einer Größe von mehr als 1 Byte fallen hinsichtlich der Gesamtzeichenanzahl stärker ins Gewicht als 1-Byte-Zeichen.
Die maximal zulässige Pfadlänge kann mithilfe des Befehls getconf PATH_MAX /NFSmountpoint abgefragt werden.
Hinweis
Das Limit wird in der Datei limits.h auf dem NFS-Client definiert. Diese Limits sollten nicht angepasst werden.
Überlegungen zu Volumes mit zwei Protokollen
Wenn Sie Azure NetApp Files für Doppelprotokollzugriff verwenden, kann der Unterschied bei der Behandlung von Pfadlängen in NFS- und SMB-Protokollen zu datei- und ordnerübergreifenden Inkompatibilitäten führen. Windows SMB unterstützt z. B. bis zu 32.767 Zeichen in einem Pfad (vorausgesetzt, das Feature für lange Pfade ist auf dem SMB-Client aktiviert). Die NFS-Unterstützung kann jedoch über diesen Wert hinausgehen. Wenn also in NFS eine Pfadlänge erstellt wird, die über die Unterstützung von SMB hinausgeht, können Clients nicht mehr auf die Daten zugreifen, nachdem die Höchstwerte für die Pfadlänge erreicht wurden. In derartigen Fällen müssen entweder bei der Erstellung von Datei- und Ordnernamen (sowie bei der Ordnerpfadtiefe) die protokollübergreifenden Untergrenzen von Dateipfadlängen berücksichtigt oder SMB-Freigaben näher am gewünschten Ordnerpfad zugeordnet werden, um die Pfadlänge zu verringern.
Anstatt die SMB-Freigabe der obersten Ebene des Volumes zuzuordnen, um zu einem Pfad wie \\share\folder1\folder2\folder3\folder4 zu navigieren, empfiehlt es sich gegebenenfalls, die SMB-Freigabe dem gesamten Pfad \\share\folder1\folder2\folder3\folder4 zuzuordnen. Die Laufwerkbuchstabenzuordnung zu Z: führt somit zum gewünschten Ordner und reduziert die Pfadlänge von Z:\folder1\folder2\folder3\folder4\file auf Z:\file.
Überlegungen im Zusammenhang mit Sonderzeichen
Azure NetApp Files-Volumes verwenden den Sprachtyp C.UTF-8, der viele Länder/Regionen und Sprachen umfasst, darunter Deutsch, Kyrillisch, Hebräisch und den Großteil von Chinesisch/Japanisch/Koreanisch (CJK). Die meisten gängigen Textzeichen in Unicode haben eine Größe von maximal 3 Bytes. Sonderzeichen wie etwa Emojis, musikalische Symbole und mathematische Symbole sind oftmals größer als 3 Bytes. Einige verwenden Logik für UTF-16-Ersatzzeichenpaare.
Wenn Sie ein Zeichen verwenden, das von Azure NetApp Files nicht unterstützt wird, wird möglicherweise eine Warnung mit der Aufforderung angezeigt, einen anderen Dateinamen anzugeben.
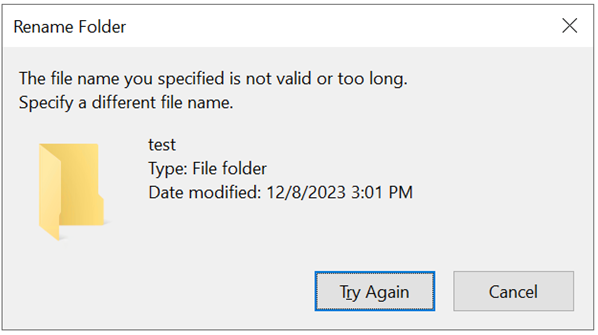
Der Fehler tritt allerdings nicht auf, weil der Name zu lang ist, sondern weil die Bytegröße der Zeichen für das Azure NetApp Files-Volume zu groß ist, um über SMB verwendet zu werden. Für diese Einschränkung gibt es in Azure NetApp Files keine Problemumgehung. Weitere Informationen zur Behandlung von Sonderzeichen in Azure NetApp Files finden Sie unter Protokollverhalten mit Sonderzeichensätzen.