Worum handelt es sich bei Azure HDInsight?
Azure HDInsight ist ein umfassender, verwalteter Open-Source-Analysedienst in der Cloud für Unternehmen. Mit HDInsight können Sie Open-Source-Frameworks wie Apache Spark, Apache Hive, LLAP, Apache Kafka, Hadoop und andere in Ihrer Azure-Umgebung verwenden.
Was sind HDInsight und der Hadoop-Technologiestapel?
Azure HDInsight ist eine verwaltete Clusterplattform, die das Ausführen von Big Data-Frameworks wie Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop und anderen in Ihrer Azure-Umgebung erleichtert. Es wurde entwickelt, um große Datenmengen mit hoher Geschwindigkeit und Effizienz zu verarbeiten.
Argumente für die Verwendung von Azure HDInsight
| Funktion | BESCHREIBUNG |
|---|---|
| Cloudbasiert | Azure HDInsight ermöglicht es Ihnen, optimierte Cluster für Spark, Interactive Query (LLAP), Kafka, HBase und Hadoop in Azure zu erstellen. Darüber hinaus bietet HDInsight eine End-to-End-SLA für alle Ihre Produktionsworkloads. |
| Kostengünstig und skalierbar | Mit HDInsight können Sie Workloads hoch- und herunterskalieren. Durch das Erstellen bedarfsgesteuerter Cluster können Sie Ihre Kosten senken, indem Sie nur für das bezahlen, was Sie tatsächlich nutzen. Außerdem können Sie Datenpipelines für die Operationalisierung Ihrer Aufträge erstellen. Die Entkoppelung von Compute und Speicher sorgt für bessere Leistung und mehr Flexibilität. |
| Sicher und konform | Mit HDInsight können Sie die Datenressourcen Ihres Unternehmens durch die Verwendung von Azure Virtual Network, Verschlüsselung und Integration von Microsoft Entra ID schützen. Darüber hinaus erfüllt HDInsight die gängigsten branchen- und behördenspezifischen Compliancestandards. |
| Überwachung | Dank der Integration mit Azure Monitor-Protokollen bietet Azure HDInsight eine zentrale Oberfläche für die Überwachung Ihrer gesamten Cluster. |
| Globale Verfügbarkeit | HDInsight ist in mehr Regionen verfügbar als jede andere Big Data-Analyselösung. Zudem steht Azure HDInsight für Azure Government, China und Deutschland zur Verfügung, was die Erfüllung geschäftlicher Anforderungen in zentralen unabhängigen Bereichen ermöglicht. |
| Produktivität | Mit Azure HDInsight können Sie umfangreiche Produktivitätstools für Hadoop und Spark in Ihrer bevorzugten Entwicklungsumgebung nutzen. Zu diesen Entwicklungsumgebungen gehören Visual Studio, VSCode, Eclipse und IntelliJ für die Unterstützung von Scala, Python, Java und .NET. |
| Erweiterungen | Sie können die HDInsight-Cluster um installierte Komponenten erweitern (z. B. Hue, Presto usw.), indem Sie Skriptaktionen verwenden, Edgeknoten hinzufügen oder andere, für Big Data zertifizierte Anwendungen integrieren. HDInsight lässt sich mittels One-Click-Bereitstellung nahtlos in die gängigsten Big Data-Lösungen integrieren. |
Was versteht man unter "Big Data"?
Große Datenmengen, also „Big Data“, werden in immer größeren Mengen, mit immer höherer Geschwindigkeit und in immer mehr Formaten als jemals zuvor erfasst. Dabei kann es sich um Verlaufsdaten (also gespeicherte Daten) oder um Echtzeitdaten (von der Quelle gestreamt) handeln. Informationen zu den gängigsten Anwendungsfällen für Big Data finden Sie unter Verwendungsszenarien für HDInsight.
Clustertypen in HDInsight
HDInsight umfasst bestimmte Clustertypen und Clusteranpassungsfunktionen, z.B. die Möglichkeit zum Hinzufügen von Komponenten, Hilfsprogrammen und Sprachen. HDInsight bietet die folgenden Clustertypen:
| Clustertyp | BESCHREIBUNG | Erste Schritte |
|---|---|---|
| Apache Hadoop | Ein Framework, das Hadoop Distributed File System, die YARN-Ressourcenverwaltung und ein einfaches MapReduce-Programmiermodell zum parallelen Verarbeiten und Analysieren von Batchdaten nutzt. | Erstellen eines Apache Hadoop-Clusters |
| Apache Spark | Ein Open-Source-Framework für die Parallelverarbeitung, das die arbeitsspeicherinterne Verarbeitung unterstützt, um die Leistung von Anwendungen zur Analyse von Big Data zu steigern. Siehe Was ist Apache Spark in HDInsight? | Erstellen eines Apache Spark-Clusters |
| Apache HBase | Eine auf Hadoop basierende NoSQL-Datenbank, die wahlfreien Zugriff und starke Konsistenz für große Mengen unstrukturierter und teilstrukturierter Daten bietet – in einer potenziellen Dimension von Milliarden von Zeilen multipliziert mit Milliarden von Spalten. Siehe Was ist HBase in HDInsight? | Erstellen eines Apache HBase-Clusters |
| Interaktive Apache-Abfrage | Arbeitsspeicherinternes Caching für interaktive und schnellere Hive-Abfragen. Siehe Use Interactive Query in HDInsight (Verwenden von Interactive Query in HDInsight). | Erstellen eines Interactive Query-Clusters |
| Apache Kafka | Eine Open Source-Plattform zum Erstellen von Streamingdatenpipelines und -anwendungen. Kafka bietet auch eine Nachrichtenwarteschlangenfunktion, die Ihnen das Veröffentlichen und Abonnieren von Datenströmen ermöglicht. Siehe Introduction to Apache Kafka on HDInsight (Einführung in Apache Kafka in HDInsight). | Erstellen eines Apache Kafka-Clusters |
Verwendungsszenarien für HDInsight
Azure HDInsight kann im Rahmen verschiedenster Szenarien für die Big Data-Verarbeitung verwendet werden. Dabei kann es sich um Verlaufsdaten (Daten, die bereits erfasst und gespeichert wurden) oder um Echtzeitdaten (Daten, die direkt von der Quelle gestreamt werden) handeln. Die Szenarien für die Verarbeitung dieser Daten lassen sich in folgende Kategorien unterteilen:
Batchverarbeitung (ETL)
Extrahieren, Transformieren und Laden (ETL) ist ein Prozess, bei dem nicht strukturierte und strukturierte Daten aus heterogenen Datenquellen extrahiert werden. Anschließend werden sie in ein strukturiertes Format transformiert und in einen Datenspeicher geladen. Sie können die transformierten Daten für Data Science- oder Data Warehousing-Zwecke verwenden.
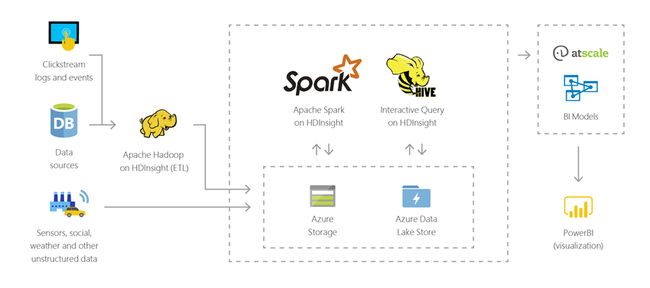
Data Warehousing
Mit HDInsight können Sie interaktive Abfragen für Petabytes von strukturierten oder unstrukturierten Daten in einem beliebigen Format durchführen. Darüber hinaus können Sie Modelle für die Verknüpfung mit BI-Tools erstellen.
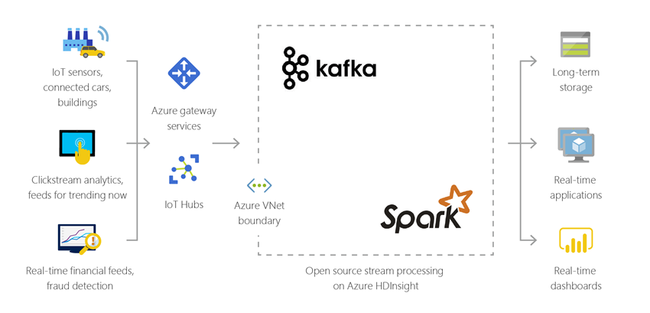
Internet der Dinge (IoT, Internet of Things)
Mit HDInsight können Sie Streamingdaten verarbeiten, die in Echtzeit von verschiedenen Arten von Geräten empfangen werden. Weitere Informationen finden Sie in diesem Azure-Blog, in dem die öffentliche Vorschauversion von Apache Kafka unter HDInsight mit Azure Managed Disks angekündigt wird.
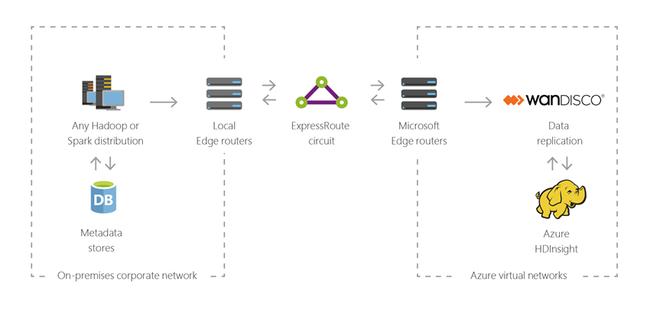
Hybrid
Mit HDInsight können Sie Ihre vorhandene lokale Big Data-Infrastruktur auf Azure ausdehnen und die erweiterten Analysefunktionen der Cloud anwenden.
Open-Source-Komponenten in HDInsight
Azure HDInsight ermöglicht Ihnen die Erstellung von Clustern mit Open-Source-Frameworks wie Spark, Hive, LLAP, Kafka, Hadoop und HBase. Diese Cluster enthalten standardmäßig verschiedene Open-Source-Komponenten wie Apache Ambari, Avro, Apache Hive 3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie und Apache ZooKeeper.
Programmiersprachen in HDInsight
HDInsight-Cluster, z.B. Spark, HBase, Kafka, Hadoop und andere, unterstützen viele Programmiersprachen. Einige Programmiersprachen werden nicht standardmäßig installiert. Verwenden Sie eine Skriptaktion, um Bibliotheken, Module oder Pakete zu installieren, die standardmäßig nicht installiert sind.
| Programmiersprache | Information |
|---|---|
| Standardmäßige Unterstützung für Programmiersprachen | Standardmäßig unterstützen HDInsight-Cluster folgende Sprachen:
|
| JVM-Sprachen (Java Virtual Machine) | Auf einer Java Virtual Machine (JVM) können neben Java auch viele andere Sprachen ausgeführt werden. Bei der Ausführung von einigen dieser Sprachen müssen Sie im Cluster unter Umständen aber mehr Komponenten installieren. Die folgenden JVM-basierten Sprachen werden in HDInsight-Clustern unterstützt:
|
| Hadoop-spezifische Sprachen | HDInsight-Cluster bieten Unterstützung für die folgenden Sprachen, die für den Hadoop-Technologiestapel spezifisch sind:
|
Entwicklungstools für HDInsight
Sie können HDInsight-Entwicklungstools wie IntelliJ, Eclipse, Visual Studio Code und Visual Studio verwenden, um HDInsight-Datenabfragen und -aufträge zu erstellen und zu übermitteln – mit nahtloser Integration in Azure.
- Azure-Toolkit für IntelliJ 10
- Azure-Toolkit für Eclipse 6
- Azure HDInsight-Tools für VS Code 13
- Azure Data Lake-Tools für Visual Studio 9
Business Intelligence in HDInsight
Bekannte Business Intelligence-Tools (BI) rufen Daten, die in HDInsight integriert sind, entweder über das Power Query-Add-In oder den Microsoft Hive ODBC-Treiber ab, analysieren sie und erstellen Berichte:
Apache Spark BI mit Datenvisualisierungstools unter Azure HDInsight
Visualisieren von Apache Hive-Daten mit Microsoft Power BI in Azure HDInsight
Visualize Interactive Query Hive data with Microsoft Power BI using direct query in Azure HDInsight (Visualisieren von Interactive Query-Hive-Daten mit Microsoft Power BI mittels direkter Abfrage in Azure HDInsight)
Verbinden von Excel mit Apache Hadoop mithilfe von Power Query (setzt Windows voraus)
Verbinden von Excel mit Apache Hadoop über den Microsoft Hive ODBC-Treiber (setzt Windows voraus)
Data Residency in der Region
Spark, Hadoop und LLAP speichern keine Kundendaten, sodass diese Dienste automatisch die im Trust Center festgelegten Anforderungen an die Datenresidenz in der Region erfüllen.
Kafka und HBase speichern Kundendaten. Diese Daten werden von Kafka und HBase automatisch in einer einzigen Region gespeichert, sodass dieser Dienst im Trust Center festgelegten Anforderungen an die Datenresidenz in der Region erfüllt.
Bekannte Business Intelligence-Tools (BI) rufen Daten, die in HDInsight integriert sind, entweder über das Power Query-Add-In oder den Microsoft Hive ODBC-Treiber ab, analysieren sie und erstellen Berichte.