Azure Traffic Manager mit Azure Site Recovery
Mit Azure Traffic Manager können Sie die Verteilung von Datenverkehr auf Anwendungsendpunkte steuern. Ein Endpunkt ist ein Dienst mit Internetzugriff, der innerhalb oder außerhalb von Azure gehostet wird.
Traffic Manager verwendet das Domain Name System (DNS), um Clientanforderungen auf der Grundlage einer Datenverkehrsrouting-Methode und der Integrität der Endpunkte an den optimalen Endpunkt weiterzuleiten. Traffic Manager bietet eine Reihe von Datenverkehrsrouting-Methoden und Endpunktüberwachungsoptionen, die verschiedene Anwendungsanforderungen erfüllen sowie automatisches Failover ermöglichen. Clients stellen mit dem ausgewählten Endpunkt eine direkte Verbindung her. Traffic Manager ist kein Proxy oder Gateway und hat keinen Zugriff auf den Datenverkehr zwischen Client und Dienst.
In diesem Artikel wird beschrieben, wie Sie das intelligente Routing von Azure Traffic Manager mit den leistungsstarken Funktionen von Azure Site Recovery zur Notfallwiederherstellung und Migration kombinieren können.
Failover von einem lokalen Standort nach Azure
Für das erste Szenario sehen wir uns Unternehmen A an, dessen gesamte Anwendungsinfrastruktur in der lokalen Umgebung ausgeführt wird. Aus Gründen der Geschäftskontinuität und Konformität entscheidet sich Unternehmen A, Azure Site Recovery zum Schützen der Anwendungen zu verwenden.
Unternehmen A führt Anwendungen mit öffentlichen Endpunkten aus und möchte die Möglichkeit erhalten, Datenverkehr bei einem Notfall nahtlos nach Azure weiterzuleiten. Mithilfe des prioritätsbasierten Datenverkehrsroutings in Azure Traffic Manager kann Unternehmen A dieses Failovermuster problemlos implementieren.
Die Einrichtung erfolgt wie folgt:
- Unternehmen A erstellt ein Traffic Manager-Profil.
- Mithilfe der prioritätsbasierten Routingmethode erstellt Unternehmen A zwei Endpunkte – Primary für den lokalen Standort und Failover für Azure. Primary erhält die Priorität 1 und Failover die Priorität 2.
- Da der Endpunkt Primary außerhalb von Azure gehostet wird, erfolgt seine Erstellung als externer Endpunkt.
- Bei Azure Site Recovery verfügt der Azure-Standort über keine virtuellen Computer oder Anwendungen, die vor dem Failover ausgeführt werden. Deshalb wird der Endpunkt Failover ebenfalls als externer Endpunkt erstellt.
- Standardmäßig wird der Benutzerdatenverkehr an die lokale Anwendung geleitet, da diesem Endpunkt die höchste Priorität zugeordnet ist. Es wird kein Datenverkehr an Azure weitergeleitet, wenn der Endpunkt Primary fehlerfrei ist.
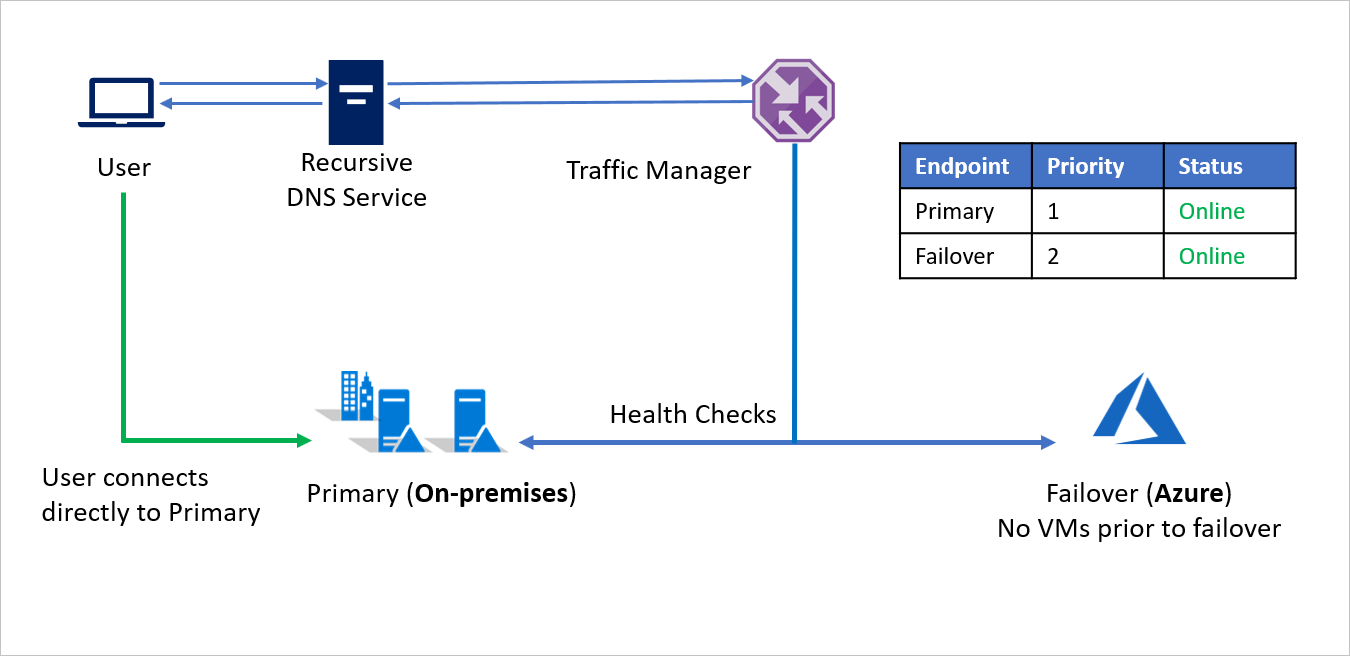
Bei einem Notfall kann Unternehmen A ein Failover nach Azure auslösen und seine Anwendungen in Azure wiederherstellen. Wenn Azure Traffic Manager erkennt, dass der Endpunkt Primary nicht mehr fehlerfrei ist, verwendet er automatisch den Endpunkt Failover in der DNS-Antwort. Die Benutzer stellen daraufhin Verbindungen mit der in Azure wiederhergestellten Anwendung her.
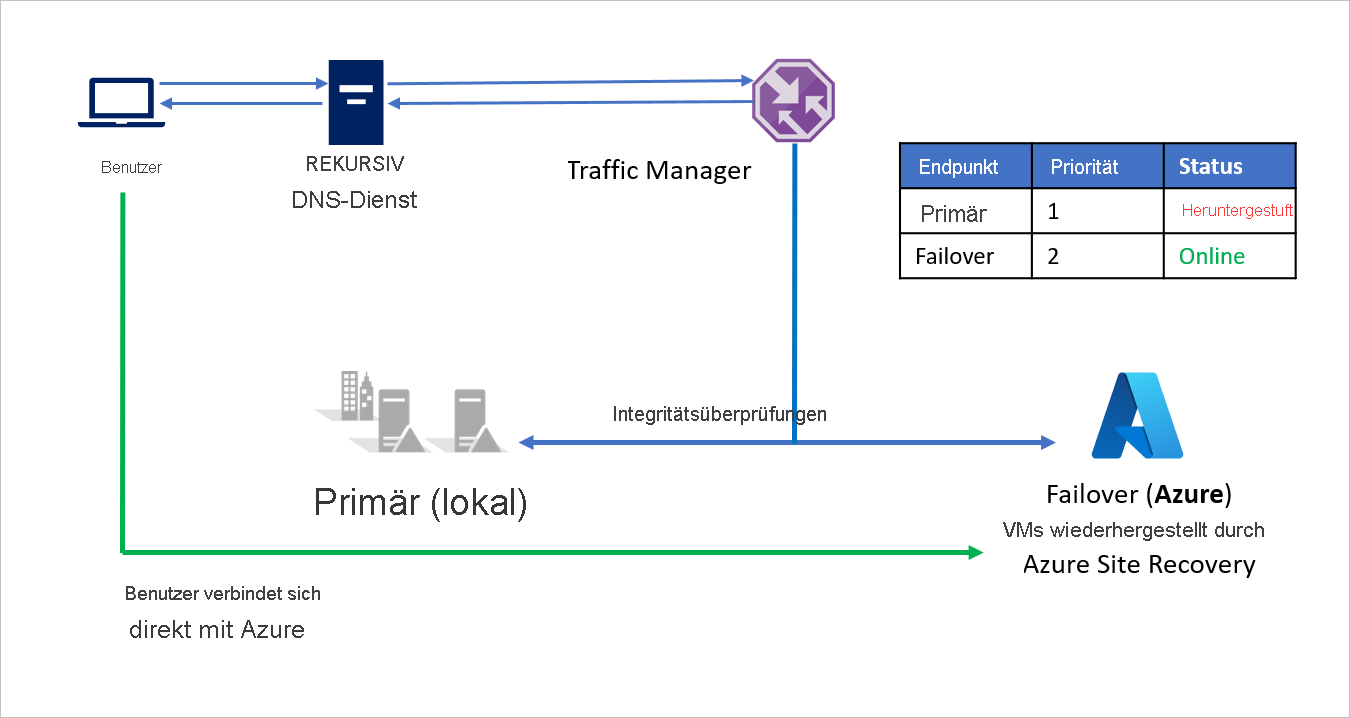
In Abhängigkeit von den Geschäftsanforderungen kann Unternehmen A eine höhere oder niedrigere Testhäufigkeit für Wechsel zwischen dem lokalen Standort und Azure bei einem Notfall festlegen und damit die Ausfallzeiten für Benutzer minimieren.
Nach dem Beheben des Notfalls kann Unternehmen A mithilfe von Azure Site Recovery ein Failback von Azure zur lokalen Umgebung (VMware oder Hyper-V) ausführen. Wenn Traffic Manager daraufhin erkennt, dass der Endpunkt Primary wieder fehlerfrei ist, nutzt er automatisch den Endpunkt Primary in den DNS-Antworten.
Migration von einem lokalen Standort zu Azure
Zusätzlich zur Notfallwiederherstellung ermöglicht Azure Site Recovery auch Migrationen zu Azure. Mithilfe der leistungsstarken Testfailover-Funktionen von Azure Site Recovery können Kunden ohne Auswirkungen auf ihre lokale Umgebung die Anwendungsleistung in Azure nutzen. Wenn Kunden dann eine Migration durchführen möchten, können sie vollständige Workloads gemeinsam migrieren oder eine graduelle Migration und Skalierung ausführen.
Die gewichtete Routingmethode von Azure Traffic Manager kann dazu verwendet werden, einen Teil des eingehenden Datenverkehrs nach Azure umzuleiten, während der Großteil weiterhin in die lokale Umgebung geleitet wird. Dieser Ansatz kann zu einer besseren Bewertung der Skalierung der Leistung führen, während Sie die Gewichtung in Richtung Azure erhöhen. So können Sie nach und nach einen größeren Anteil Ihrer Workloads zu Azure migrieren.
Beispielsweise entscheidet sich Unternehmen B für die Migration in Phasen. Es verschiebt zunächst einen Teil seiner Anwendungsumgebung, während der Rest lokal verbleibt. Bei den ersten Schritten – bei denen ein Großteil der Umgebung noch lokal ausgeführt wird –, ist der lokalen Umgebung eine höhere Gewichtung zugewiesen. Traffic Manager gibt basierend auf den zugewiesenen Gewichtungen der verfügbaren Endpunkte einen Endpunkt zurück.
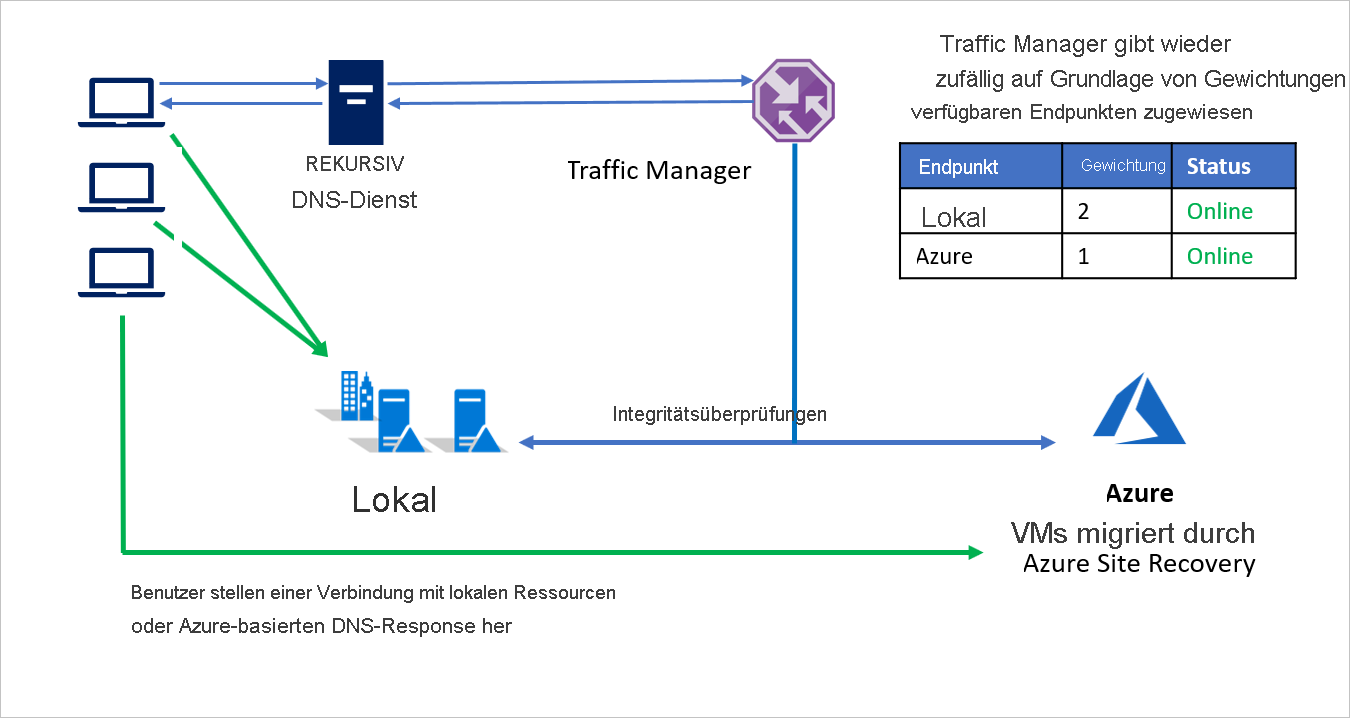
Während der Migration sind beide Endpunkte aktiv, und der Großteil des Datenverkehrs wird in die lokale Umgebung weitergeleitet. Im weiteren Verlauf der Migration kann dem Endpunkt in Azure eine größere Gewichtung zugewiesen werden, bis schließlich der lokale Endpunkt nach der Migration deaktiviert werden kann.
Failover von Azure nach Azure
Für dieses Beispiel sehen wir uns Unternehmen C an, bei dem die gesamte Anwendungsinfrastruktur in Azure ausgeführt wird. Aus Gründen der Geschäftskontinuität und Compliance entscheidet sich Unternehmen C dazu, Azure Site Recovery zum Schützen der eigenen Anwendungen zu verwenden.
Unternehmen C führt Anwendungen mit öffentlichen Endpunkten aus und möchte die Möglichkeit erhalten, Datenverkehr bei einem Notfall nahtlos in eine andere Azure-Region weiterzuleiten. Mithilfe der prioritätsbasierten Methode für das Datenverkehrsrouting kann Unternehmen C dieses Failovermuster problemlos implementieren.
Die Einrichtung erfolgt wie folgt:
- Unternehmen C erstellt ein Traffic Manager-Profil.
- Unternehmen C nutzt die prioritätsbasierte Routingmethode und erstellt zwei Endpunkte – Primary für die Ausgangsregion (Azure, Asien, Osten) und Failover für die Wiederherstellungsregion (Azure, Asien, Südosten). Primary erhält die Priorität 1 und Failover die Priorität 2.
- Da der Endpunkt Primary in Azure gehostet wird, kann der Endpunkt ein Azure-Endpunkt sein.
- Bei Azure Site Recovery verfügt der Azure-Wiederherstellungsstandort über keine virtuellen Computer oder Anwendungen, die vor dem Failover ausgeführt werden. Der Endpunkt Failover kann daher als externer Endpunkt erstellt werden.
- Standardmäßig wird der Benutzerdatenverkehr an die Ausgangsregion (Asien, Osten) geleitet, da diesem Endpunkt die höchste Priorität zugeordnet ist. Es wird kein Datenverkehr an die Wiederherstellungsregion weitergeleitet, wenn der Endpunkt Primary fehlerfrei ist.
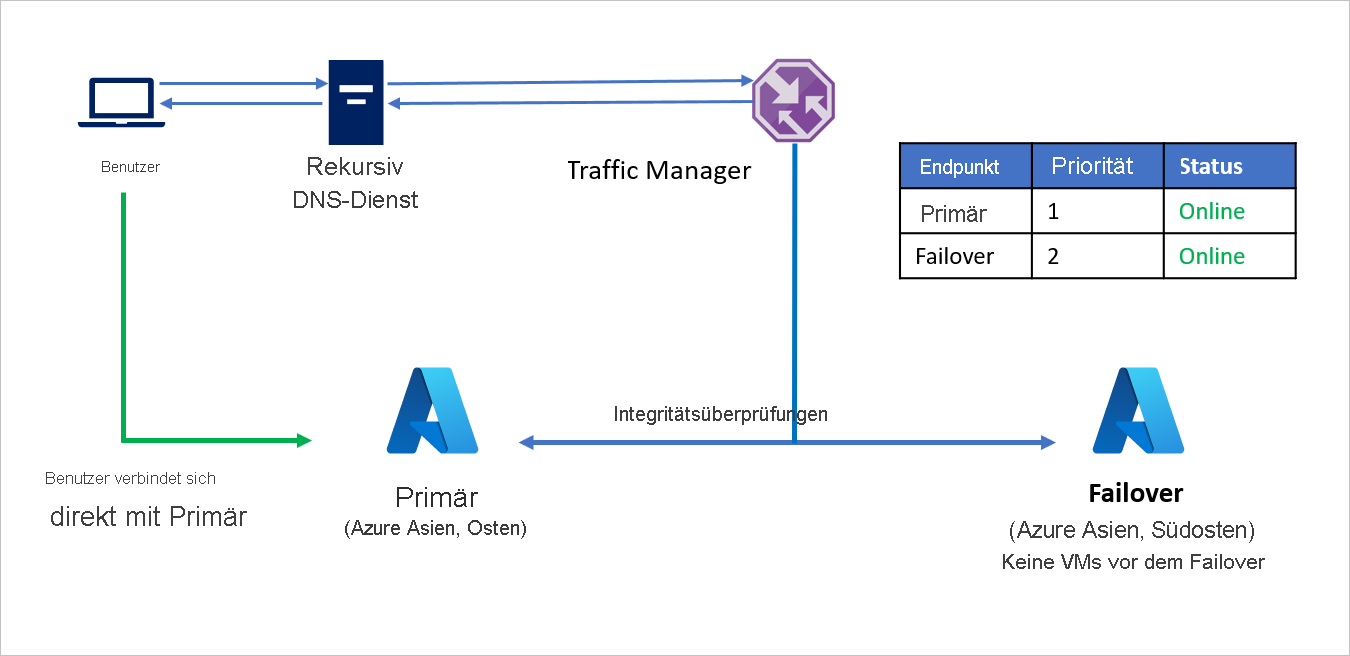
Bei einem Notfall kann Unternehmen C ein Failover auslösen und seine Anwendungen in der Azure-Wiederherstellungsregion wiederherstellen. Wenn Azure Traffic Manager erkennt, dass der Endpunkt „Primary“ nicht mehr fehlerfrei ist, verwendet er automatisch den Endpunkt Failover in der DNS-Antwort. Die Benutzer stellen daraufhin Verbindungen mit der in der Azure-Wiederherstellungsregion (Asien, Südosten) wiederhergestellten Anwendung her.
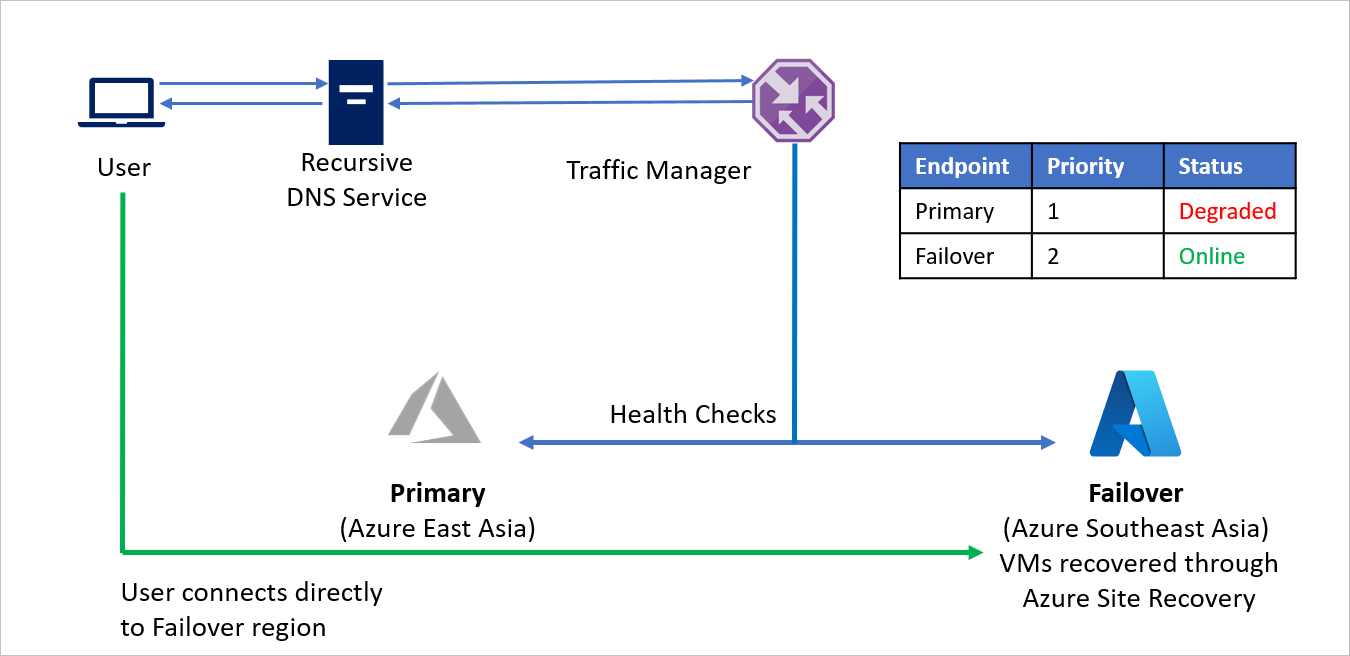
In Abhängigkeit von den Geschäftsanforderungen kann Unternehmen C eine höhere oder niedrigere Testhäufigkeit für Wechsel zwischen der Ausgangs- und der Wiederherstellungsregion festlegen und damit die Ausfallzeiten für Benutzer minimieren.
Wenn der Notfall behoben wurde, kann Unternehmen C mithilfe von Azure Site Recovery ein Failback von der Azure-Wiederherstellungsregion in die Azure-Ausgangsregion ausführen. Wenn Traffic Manager daraufhin erkennt, dass der Endpunkt Primary wieder fehlerfrei ist, nutzt er automatisch den Endpunkt Primary in den DNS-Antworten.
Schützen von Unternehmensanwendungen in mehreren Regionen
Global agierende Unternehmen steigern häufig die Benutzerfreundlichkeit, indem sie ihre Anwendungen an die regionalen Gegebenheiten anpassen. Lokalisierung und eine Verringerung der Wartezeiten können dazu führen, dass die Anwendungsinfrastruktur auf mehrere Regionen aufgeteilt wird. Darüber hinaus sind Unternehmen auch an regionale Gesetze zum Datenschutz gebunden und entscheiden sich daher oft dazu, einen Teil ihrer Anwendungsinfrastruktur innerhalb regionaler Grenzen zu isolieren.
Betrachten wir ein Beispiel, in dem Unternehmen D seine Anwendungsendpunkte so aufgeteilt hat, dass Deutschland und der Rest der Welt separat verarbeitet werden. Unternehmen D nutzt hierzu die geografische Routingmethode von Azure Traffic Manager. Sämtlicher Datenverkehr aus Deutschland wird an Endpoint 1 weitergeleitet, während Datenverkehr von außerhalb Deutschlands an Endpoint 2 weitergeleitet wird.
Das Problem bei diesem Setup ist, dass bei einem Ausfall von Endpoint 1 keine Umleitung des Datenverkehrs zu Endpoint 2 erfolgt. Datenverkehr aus Deutschland wird weiterhin an Endpoint 1 geleitet – unabhängig von der Integrität des Endpunkts. Dadurch haben deutsche Benutzer keinen Zugriff mehr auf die Anwendung von Unternehmen D. Entsprechend erfolgt bei einem Ausfall von Endpoint 2 keine Umleitung auf Endpoint 1.
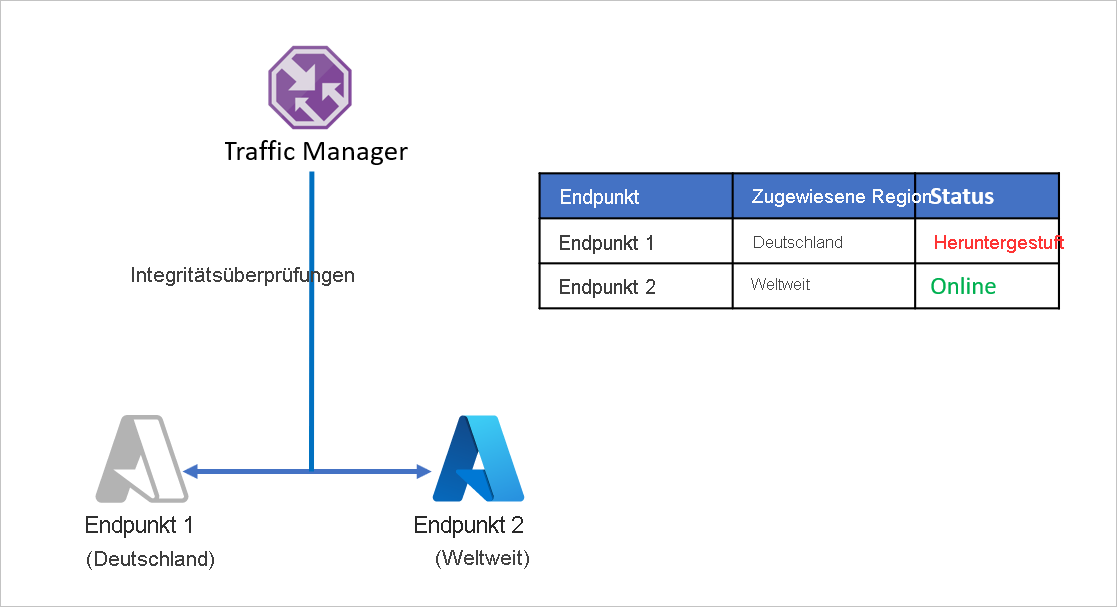
Zur Vermeidung dieses Problems und zum Sicherstellen der Anwendungsresilienz nutzt Unternehmen D die geschachtelten Traffic Manager-Profile mit Azure Site Recovery. In einem Setup mit geschachtelten Profilen wird der Datenverkehr nicht an einzelne Endpunkte, sondern an andere Traffic Manager-Profile umgeleitet. Funktionsweise dieses Setups:
- Anstelle des geografischen Routings mit einzelnen Endpunkten verwendet Unternehmen D das geografische Routing mit Traffic Manager-Profilen.
- Jedes untergeordnete Traffic Manager-Profil nutzt das prioritätsbasierte Routing mit einem primären und einem Wiederherstellungsendpunkt, sodass das prioritätsbasierte Routing im geografischen Routing geschachtelt ist.
- Um Anwendungsresilienz zu ermöglichen, verwendet jede Workloadverteilung bei einem Notfall Azure Site Recovery für ein Failover in eine Wiederherstellungsregion.
- Wenn das übergeordnete Traffic Manager-Profil eine DNS-Abfrage empfängt, wird diese an das entsprechende untergeordnete Traffic Manager-Profil weitergeleitet, das auf die Abfrage mit einem verfügbaren Endpunkt antwortet.
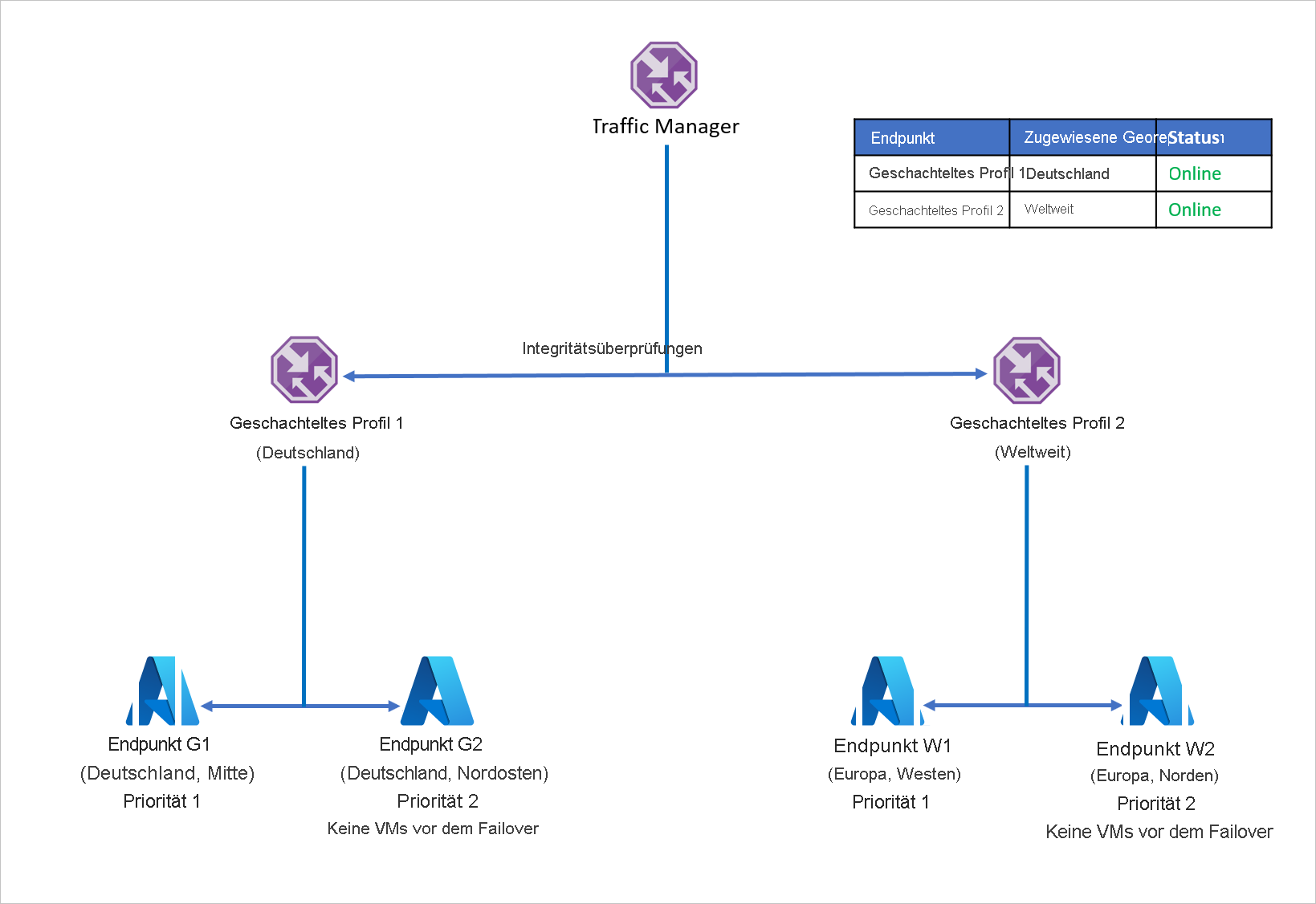
Wenn z.B. der Endpunkt in „Deutschland, Mitte“ ausfällt, kann die Anwendung schnell in „Deutschland, Nordosten“ wiederhergestellt werden. Der neue Endpunkt verarbeitet dann den Datenverkehr aus Deutschland mit einer nur minimalen Ausfallzeit für die Benutzer. Auf ähnliche Weise kann ein Endpunktausfall in der Region „Europa, Westen“ durch eine Wiederherstellung der Anwendungsworkload in „Europa, Norden“ behoben werden, wobei Azure Traffic Manager die DNS-Umleitung an den verfügbaren Endpunkt übernimmt.
Das oben beschriebene Setup kann erweitert werden, um die erforderliche Kombinationen von Regionen und Endpunkten zu erreichen. Traffic Manager erlaubt bis zu 10 Ebenen von geschachtelten Profilen. Er lässt aber keine Schleifen innerhalb der geschachtelten Konfiguration zu.
Überlegungen zur Recovery Time Objective (RTO)
In den meisten Organisationen erfolgt das Hinzufügen oder Ändern von DNS-Einträgen durch ein spezielles Team oder eine Person außerhalb der Organisation. Dadurch ist die Änderung von DNS-Einträgen relativ aufwendig. Die Zeit für das Aktualisieren von DNS-Einträgen durch andere Teams oder Organisationen, die die DNS-Infrastruktur verwalten, variiert von Organisation zu Organisation und wirkt sich auf die RTO der Anwendung aus.
Durch die Verwendung von Traffic Manager können Sie den Arbeitsaufwand für DNS-Updates vorab erledigen. Zum Zeitpunkt des tatsächlichen Failovers ist keine manuelle oder skriptgesteuerte Aktion erforderlich. Dieser Ansatz hilft beim schnellen Wechseln (und senkt damit die RTO). Außerdem werden so potenziell schwerwiegende und zeitaufwendige Fehler bei DNS-Änderungen während eines Notfalls verhindert. Bei Traffic Manager ist sogar der Failbackschritt automatisiert, der andernfalls separat verwaltet werden müsste.
Das Festlegen des richtigen Testintervalls über einfache oder schnelle Intervallintegritätsprüfungen kann die RTO während des Failovers und damit die Ausfallzeiten für Benutzer erheblich reduzieren.
Sie können außerdem den Wert für die DNS-Gültigkeitsdauer (TTL) für das Traffic Manager-Profil optimieren. Die Gültigkeitsdauer (TTL) ist die Dauer, die ein DNS-Eintrag von einem Client zwischengespeichert wird. Das DNS würde für einen Eintrag nicht zweimal innerhalb der Gültigkeitsdauer (TTL) abgefragt werden. Jedem DNS-Eintrag ist eine Gültigkeitsdauer (TTL) zugeordnet. Eine Reduzierung dieses Werts führt zwar zu mehr DNS-Abfragen an Traffic Manager, kann aber die RTO reduzieren, da Ausfälle schneller erkannt werden.
Die Gültigkeitsdauer (TTL) für den Client erhöht sich auch nicht, wenn die Anzahl der DNS-Resolver zwischen dem Client und dem autorisierenden DNS-Server erhöht wird. Die DNS-Resolver führen einen „Countdown“ der Gültigkeitsdauer (TTL) durch und geben nur einen TTL-Wert weiter, der die verstrichene Zeit seit dem Zwischenspeichern des Eintrags widerspiegelt. Dadurch wird sichergestellt, dass der DNS-Eintrag auf dem Client nach Ablauf der Gültigkeitsdauer aktualisiert wird – und zwar unabhängig von der Anzahl der DNS-Resolver in der Kette.
Nächste Schritte
- Informieren Sie sich ausführlicher über Traffic Manager-Routingmethoden.
- Informieren Sie sich ausführlicher über geschachtelte Traffic Manager-Profile.
- Weitere Informationen über Endpunktüberwachung.
- Informieren Sie sich ausführlicher über Wiederherstellungspläne zum Automatisieren des Anwendungsfailovers.