Schnellstart: Benutzerdefinierte benannte Entitätserkennung
In diesem Artikel lernen Sie, wie Sie ein Projekt für die benutzerdefinierte NER erstellen, in dem Sie benutzerdefinierte Modelle für die benutzerdefinierte Entitätserkennung trainieren können. Ein Modell ist KI-Software, die für eine bestimmte Aufgabe trainiert wurde. Für dieses System extrahieren die Modelle benannte Entitäten und werden durch Lernen anhand von gekennzeichneten Daten trainiert.
In diesem Artikel verwenden wir Language Studio, um wichtige Konzepte der benutzerdefinierten benannten Entitätserkennung (NER) zu veranschaulichen. Als Beispiel erstellen wir ein benutzerdefiniertes NER-Modell, um relevante Entitäten aus Kreditverträgen zu extrahieren, so wie:
- Datum des Vertrags
- Name, Adresse, Stadt und Staat des Schuldners
- Name, Adresse, Stadt und Staat des Kreditgebers
- Kredit- und Zinsbeträge
Voraussetzungen
- Azure-Abonnement – Erstellen eines kostenlosen Kontos
Erstellen einer neuen Azure KI Language-Ressource und eines Azure-Speicherkontos
Bevor Sie eine benutzerdefinierte Erkennung benannter Entitäten verwenden können, müssen Sie eine Azure KI Language-Ressource erstellen, wodurch Sie die Anmeldeinformationen erhalten, die Sie zum Erstellen eines Projekts und zum Starten des Trainings eines Modells benötigen. Sie benötigen außerdem ein Azure-Speicherkonto, in das Sie Ihr Dataset hochladen können, das zum Erstellen des Modells verwendet wird.
Wichtig
Für einen schnellen Einstieg empfehlen wir die Erstellung einer neuen Azure KI Language-Ressource mithilfe der in diesem Artikel bereitgestellten Schritte. Mit den Schritten in diesem Artikel können Sie gleichzeitig die Language-Ressource und das Speicherkonto erstellen – das ist einfacher als die Kontoerstellung zu einem späteren Zeitpunkt.
Wenn Sie eine bereits vorhandene Ressource verwenden möchten, müssen Sie sie mit dem Speicherkonto verknüpfen. Informationen finden Sie im Leitfaden zur Verwendung einer vorhandenen Ressource.
Erstellen einer neuen Ressource im Azure-Portal
Melden Sie sich beim Azure-Portal an, um eine neue Azure KI Language-Ressource zu erstellen.
Wählen Sie im angezeigten Fenster in den benutzerdefinierten Features Benutzerdefinierte Textklassifizierung und benutzerdefinierte Erkennung benannter Entitäten aus. Wählen Sie unten auf dem Bildschirm Erstellung Ihrer Ressource fortsetzen aus.

Erstellen Sie eine Sprachressource mit den folgenden Details:
Name BESCHREIBUNG Subscription Ihr Azure-Abonnement. Ressourcengruppe Eine Ressourcengruppe, die Ihre Ressource enthält. Sie können eine vorhandene verwenden oder eine neue erstellen. Region Die Region Ihrer Sprachressource. Beispiel: „USA, Westen 2“. Name Ein Name für Ihre Ressource. Tarif Der Tarif für Ihre Sprachressource Sie können den kostenlosen Tarif (F0) verwenden, um den Dienst auszuprobieren. Hinweis
Wenn Sie in einer Meldung darauf hingewiesen werden, dass Ihr Anmeldekonto kein Besitzer der Ressourcengruppe des ausgewählten Speicherkontos ist, muss Ihrem Konto eine Besitzerrolle für die Ressourcengruppe zugewiesen werden, bevor Sie eine Sprachressource erstellen können. Wenden Sie sich an den Besitzer des Azure-Abonnements, um Unterstützung zu erhalten.
Wählen Sie im Abschnitt Benutzerdefinierte Textklassifizierung und benutzerdefinierte Erkennung benannter Entitäten ein vorhandenes Speicherkonto aus, oder wählen Sie Neues Speicherkonto aus. Diese Werte sollen den Einstieg erleichtern und nicht unbedingt die Speicherkontowerte darstellen, die in Produktionsumgebungen verwendet werden sollten. Um Wartezeit beim Erstellen Ihres Projekts zu vermeiden, sollten Sie eine Verbindung mit Speicherkonten in derselben Region herstellen, in der sich auch Ihre Sprachressource befindet.
Speicherkontowert Empfohlener Wert Speicherkontoname Beliebiger Name Speicherkontotyp Standardmäßiger LRS Stellen Sie sicher, dass die verantwortungsvolle KI-Benachrichtigung überprüft wird. Wählen Sie dann am unteren Rand der Seite die Schaltfläche Überprüfen + Erstellen aus und wählen Sie dann Erstellen aus.

Hochladen von Beispieldaten in den Blobcontainer
Nachdem Sie ein Azure-Speicherkonto erstellt und es mit Ihrer Sprachressource verknüpft haben, müssen Sie die Dokumente aus dem Beispieldataset in das Stammverzeichnis Ihres Containers hochladen. Diese Dokumente werden später zum Trainieren Ihres Modells verwendet.
Öffnen Sie die ZIP-Datei, und extrahieren Sie den Ordner mit den darin enthaltenen Dokumenten.
Navigieren Sie im Azure-Portal zu dem Speicherkonto, das Sie erstellt haben, und wählen Sie es aus.
Klicken Sie in Ihrem Speicherkonto im Menü auf der linken Seite unter Datenspeicher auf Container. Klicken Sie im angezeigten Bildschirm auf + Container. Geben Sie dem Container den Namen example-data, und übernehmen Sie den Standardwert für Öffentliche Zugriffsebene.

Wählen Sie den neu erstellten Container aus. Wählen Sie dann die Schaltfläche Hochladen aus, um die Dateien
.txtund.jsonauszuwählen, die Sie zuvor heruntergeladen haben.


Das zur Verfügung gestellte Beispieldataset enthält 20 Kreditverträge. Jeder Vertrag beinhaltet zwei Parteien: einen Kreditgeber und einen Kreditnehmer. Sie können die bereitgestellte Beispieldatei verwenden, um relevante Informationen zu beiden Parteien, ein Vertragsdatum, einen Darlehensbetrag und einen Zinssatz zu extrahieren.
Erstellen eines benutzerdefinierten Projekts zur Erkennung benannter Entitäten
Nachdem Ihre Ressource und das Speicherkonto konfiguriert wurden, erstellen Sie ein neues benutzerdefiniertes NER-Projekt. Ein Projekt ist ein Arbeitsbereich zum Erstellen Ihrer benutzerdefinierten ML-Modelle auf der Grundlage Ihrer Daten. Auf Ihr Projekt können nur Sie und andere Personen zugreifen, die Zugriff auf die verwendete Sprachressource haben.
Melden Sie sich bei Language Studio an. Es wird ein Fenster angezeigt, in dem Sie Ihr Abonnement und Ihre Sprachressource auswählen können. Wählen Sie die Sprachressource aus, die Sie im Schritt oben erstellt haben.
Wählen Sie im Abschnitt Informationen extrahieren von Language Studio die Option Benutzerdefinierte benannte Entitätserkennung aus.

Wählen Sie im oberen Menü Ihrer Projektseite Neues Projekt erstellen aus. Durch das Erstellen eines Projekts können Sie Daten kennzeichnen sowie Ihre Modelle trainieren, auswerten, verbessern und bereitstellen.

Nachdem Sie auf Neues Projekt erstellen geklickt haben, wird ein Fenster angezeigt, in dem Sie eine Verbindung mit Ihrem Speicherkonto herstellen können. Wenn Sie bereits ein Speicherkonto verbunden haben, wird das verbundene Speicherkonto angezeigt. Falls nicht, wählen Sie Ihr Speicherkonto im angezeigten Dropdownmenü aus, und klicken Sie auf Speicherkonto verbinden. Dadurch werden die erforderlichen Rollen für Ihr Speicherkonto festgelegt. Dieser Schritt gibt möglicherweise einen Fehler zurück, wenn Sie nicht als Besitzer des Speicherkontos zugewiesen sind.
Hinweis
- Sie müssen diesen Schritt nur einmal für jede neue Ressource durchführen, die Sie verwenden.
- Dieser Prozess kann nicht rückgängig gemacht werden – wenn Sie ein Speicherkonto mit Ihrer Sprachressource verbinden, können Sie die Verbindung später nicht trennen.
- Sie können Ihre Sprachressource nur mit einem Speicherkonto verbinden.

Geben Sie die Projektinformationen ein, einschließlich eines Namens, einer Beschreibung und der Sprache der Dateien in Ihrem Projekt. Wenn Sie das Beispieldataset verwenden, wählen Sie Englisch aus. Sie können den Namen Ihres Projekts später nicht mehr ändern. Wählen Sie Weiter aus.
Tipp
Ihr Dataset muss nicht zur Gänze in derselben Sprache vorliegen. Sie können mehrere Dokumente verwenden, jedes mit jeweils anderen unterstützten Sprachen. Wenn Ihr Dataset Dokumente in verschiedenen Sprachen enthält oder Sie zur Laufzeit mit Text mit verschiedenen Sprachen rechnen, wählen Sie die Option Mehrsprachiges Dataset aktivieren aus, wenn Sie die grundlegenden Informationen für Ihr Projekt eingeben. Diese Option kann später auf der Seite Projekteinstellungen aktiviert werden.
Wählen Sie den Container aus, in den Sie Ihr Dataset hochgeladen haben. Wenn Sie die Daten bereits beschriftet haben, stellen Sie sicher, dass sie dem unterstützten Format entsprechen, und wählen Sie Ja, meine Dateien sind bereits beschriftet, und ich habe die JSON-Bezeichnungsdatei formatiert aus. Wählen Sie die Bezeichnungsdatei im Dropdownmenü aus. Wählen Sie Weiter aus.
Überprüfen Sie die eingegebenen Daten, und wählen Sie Projekt erstellen aus.



Trainieren Ihres Modells
Nachdem Sie ein Projekt erstellt haben, beginnen Sie in der Regel damit, die Dokumente zu markieren, die im mit Ihrem Projekt verknüpften Container vorhanden sind. Für diesen Schnellstart haben Sie ein markiertes Beispieldataset importiert und Ihr Projekt mit der JSON-Beispieltagsdatei initialisiert.
So beginnen Sie das Training Ihres Modells über Language Studio:
Wählen Sie Trainingsaufträge aus dem Menü auf der linken Seite aus.
Wählen Sie im oberen Menü Trainingsauftrag starten aus.
Wählen Sie Neues Modell trainieren aus, und geben Sie den Namen des Modells im Textfeld darunter ein. Sie können auch ein vorhandenes Modell überschreiben, indem Sie diese Option auswählen und das Modell, das Sie überschreiben möchten, im Dropdownmenü auswählen. Das Überschreiben eines trainierten Modells kann nicht rückgängig gemacht werden, wirkt sich jedoch erst auf Ihre bereitgestellten Modelle aus, wenn Sie das neue Modell bereitstellen.

Wählen Sie die Datenteilungsmethode aus. Sie können Automatisches Aufteilen des Testsatzes und der Trainingsdaten auswählen. Dabei teilt das System Ihre beschrifteten Daten gemäß den angegebenen Prozentsätzen zwischen dem Trainings- und dem Testsatz auf. Alternativ können Sie Manuelle Aufteilung von Trainings- und Testdaten verwenden nutzen. Diese Option ist nur aktiviert, wenn Sie während der Datenbeschriftung Dokumente zu Ihrem Testsatz hinzugefügt haben. Weitere Informationen zur Datenteilung finden Sie unter Trainieren eines Modells.
Wählen Sie die Schaltfläche Train (Trainieren) aus.
Wenn Sie die Trainingsauftrags-ID in der Liste auswählen, wird ein Seitenbereich angezeigt, in dem Sie den Trainingsfortschritt, den Auftragsstatus und andere Details für diesen Auftrag überprüfen können.
Hinweis
- Nur erfolgreich abgeschlossene Trainingsaufträge generieren Modelle.
- Je nach Größe Ihrer beschrifteten Daten kann das Training wenige Minuten oder mehrere Stunden dauern.
- Es kann jeweils nur ein Trainingsauftrag ausgeführt werden. Sie können keinen anderen Trainingsauftrag innerhalb desselben Projekts starten, bis der ausgeführte Auftrag abgeschlossen ist.

Bereitstellen Ihres Modells
Im Allgemeinen überprüfen Sie nach dem Trainieren eines Modells seine Auswertungsdetails und nehmen bei Bedarf Verbesserungen vor. In diesem Schnellstart stellen Sie einfach Ihr Modell bereit und stellen es zur Verfügung, um es in Language Studio auszuprobieren, oder Sie können die Vorhersage-API aufrufen.
So stellen Sie Ihr Modell über Language Studio bereit:
Wählen Sie im Menü auf der linken Seite Bereitstellen eines Modells aus.
Wählen Sie Bereitstellung hinzufügen aus, um einen neuen Bereitstellungsauftrag zu starten.
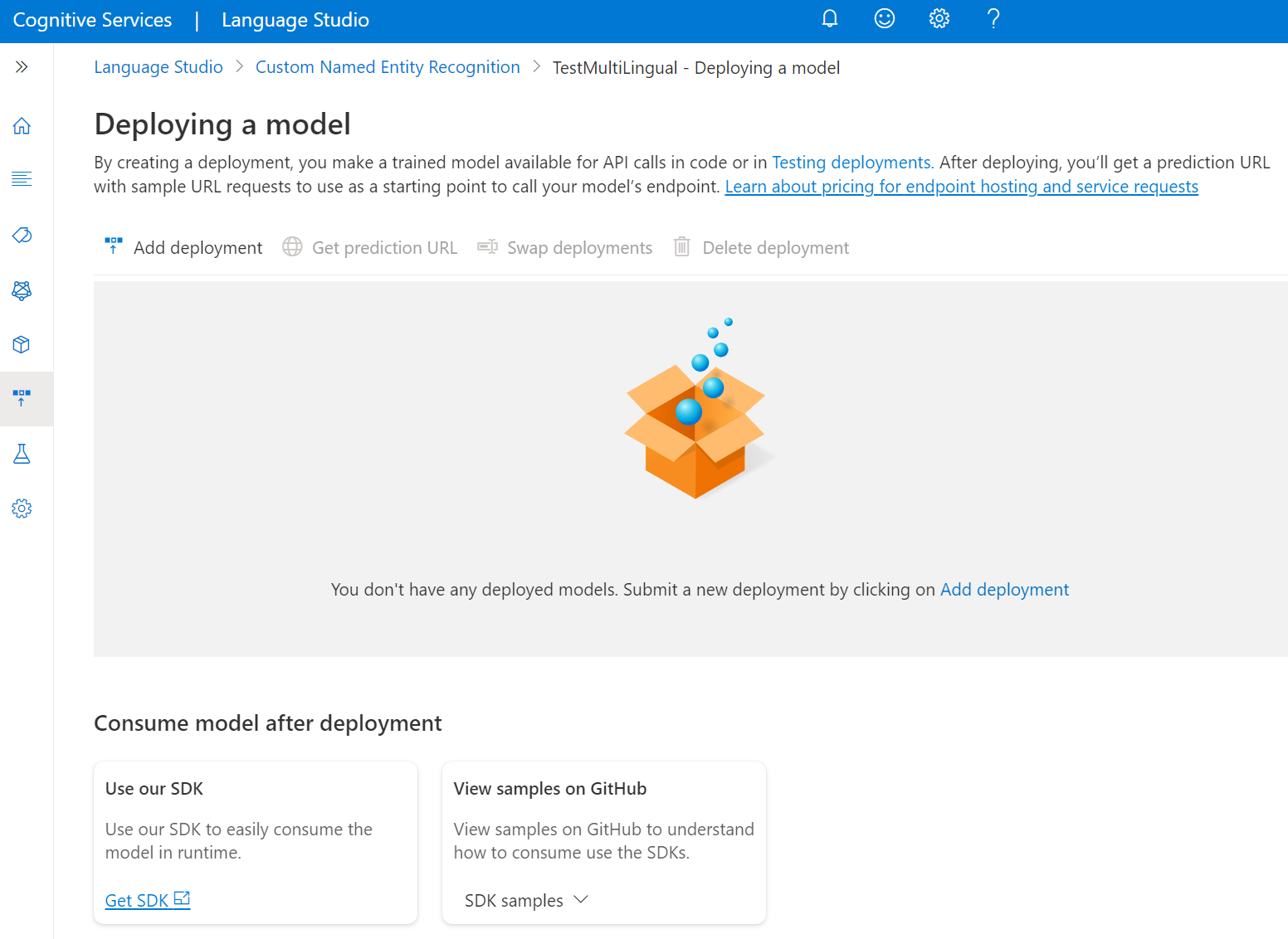
Wählen Sie Neue Bereitstellung erstellen aus, um eine neue Bereitstellung zu erstellen und ein trainiertes Modell aus der Dropdownliste unten zuzuweisen. Sie können auch eine vorhandene Bereitstellung überschreiben, indem Sie diese Option und das trainierte Modell auswählen, das Sie ihr aus der Dropdownliste zuweisen möchten.
Hinweis
Das Überschreiben einer vorhandenen Bereitstellung erfordert keine Änderungen an Ihrem Vorhersage-API-Aufruf, aber die Ergebnisse, die Sie erhalten, basieren auf dem neu zugewiesenen Modell.

Wählen Sie Bereitstellen aus, um die Bereitstellungsauftrag zu starten.
Nachdem die Bereitstellung ausgeführt wurde, wird ein Ablaufdatum neben dem Vorgang angezeigt. Der Bereitstellungsablauf ist dann, wenn Ihr bereitgestelltes Modell für die Vorhersage nicht verfügbar ist, was in der Regel zwölf Monate nach Ablauf einer Schulungskonfiguration der Fall ist.


Testen des Modells
Nachdem Ihr Modell bereitgestellt wurde, können Sie es verwenden, um Entitäten über die Vorhersage-API zu extrahieren. In dieser Schnellstartanleitung verwenden Sie Language Studio, um die Aufgabe für die benutzerdefinierte Entitätserkennung zu übermitteln und die Ergebnisse zu visualisieren. Im zuvor heruntergeladenen Beispieldataset finden Sie einige Testdokumente, die Sie in diesem Schritt verwenden können.
So testen Sie Ihre bereitgestellten Modelle über Language Studio
Wählen Sie Testbereitstellungen aus dem Menü auf der linken Seite aus.
Wählen Sie die Bereitstellung aus, die Sie testen möchten. Sie können nur Modelle testen, die Bereitstellungen zugewiesen sind.
Wählen Sie für mehrsprachige Projekte die Sprache des Textes, den Sie testen möchten, über das Dropdownmenü „Sprache“ aus.
Wählen Sie die Bereitstellung aus der Dropdownliste aus, die Sie abfragen bzw. testen möchten.
Sie können den Text eingeben, den Sie in der Anforderung übermitteln möchten, oder laden Sie eine zu verwendende
.txt-Datei hoch.Wählen Sie im oberen Menü Test ausführen aus.
Auf der Registerkarte Ergebnis sehen Sie die aus Ihrem Text extrahierten Entitäten und ihren Typ. Auf der Registerkarte JSON können Sie außerdem die JSON-Antwort anzeigen.

Bereinigen von Ressourcen
Wenn Sie Ihr Projekt nicht mehr benötigen, können Sie das Projekt mithilfe von Language Studio löschen. Wählen Sie oben Benutzerdefinierte Erkennung benannter Entitäten (NER) und das zu löschende Projekt und dann im oberen Menü Löschen aus.
Voraussetzungen
- Azure-Abonnement – Erstellen eines kostenlosen Kontos
Erstellen einer neuen Azure KI Language-Ressource und eines Azure-Speicherkontos
Bevor Sie eine benutzerdefinierte Erkennung benannter Entitäten verwenden können, müssen Sie eine Azure KI Language-Ressource erstellen, wodurch Sie die Anmeldeinformationen erhalten, die Sie zum Erstellen eines Projekts und zum Starten des Trainings eines Modells benötigen. Sie benötigen außerdem ein Azure-Speicherkonto, in das Sie Ihr Dataset hochladen können, das zum Erstellen des Modells verwendet wird.
Wichtig
Für einen schnellen Einstieg empfehlen wir die Erstellung einer neuen Azure KI Language-Ressource mithilfe der in diesem Artikel bereitgestellten Schritte. Auf diese Weise können Sie die Sprachressource und zugleich ein Speicherkonto erstellen und/oder verknüpfen, was einfacher ist als es später nachzuholen.
Wenn Sie eine bereits vorhandene Ressource verwenden möchten, müssen Sie sie mit dem Speicherkonto verknüpfen. Weitere Informationen finden Sie unter Projekt erstellen.
Erstellen einer neuen Ressource im Azure-Portal
Melden Sie sich beim Azure-Portal an, um eine neue Azure KI Language-Ressource zu erstellen.
Wählen Sie im angezeigten Fenster in den benutzerdefinierten Features Benutzerdefinierte Textklassifizierung und benutzerdefinierte Erkennung benannter Entitäten aus. Wählen Sie unten auf dem Bildschirm Erstellung Ihrer Ressource fortsetzen aus.
Erstellen Sie eine Sprachressource mit den folgenden Details:
Name BESCHREIBUNG Subscription Ihr Azure-Abonnement. Ressourcengruppe Eine Ressourcengruppe, die Ihre Ressource enthält. Sie können eine vorhandene verwenden oder eine neue erstellen. Region Die Region Ihrer Sprachressource. Beispiel: „USA, Westen 2“. Name Ein Name für Ihre Ressource. Tarif Der Tarif für Ihre Sprachressource Sie können den kostenlosen Tarif (F0) verwenden, um den Dienst auszuprobieren. Hinweis
Wenn Sie in einer Meldung darauf hingewiesen werden, dass Ihr Anmeldekonto kein Besitzer der Ressourcengruppe des ausgewählten Speicherkontos ist, muss Ihrem Konto eine Besitzerrolle für die Ressourcengruppe zugewiesen werden, bevor Sie eine Sprachressource erstellen können. Wenden Sie sich an den Besitzer des Azure-Abonnements, um Unterstützung zu erhalten.
Wählen Sie im Abschnitt Benutzerdefinierte Textklassifizierung und benutzerdefinierte Erkennung benannter Entitäten ein vorhandenes Speicherkonto aus, oder wählen Sie Neues Speicherkonto aus. Diese Werte sollen den Einstieg erleichtern und nicht unbedingt die Speicherkontowerte darstellen, die in Produktionsumgebungen verwendet werden sollten. Um Wartezeit beim Erstellen Ihres Projekts zu vermeiden, sollten Sie eine Verbindung mit Speicherkonten in derselben Region herstellen, in der sich auch Ihre Sprachressource befindet.
Speicherkontowert Empfohlener Wert Speicherkontoname Beliebiger Name Speicherkontotyp Standardmäßiger LRS Stellen Sie sicher, dass die verantwortungsvolle KI-Benachrichtigung überprüft wird. Wählen Sie dann am unteren Rand der Seite die Schaltfläche Überprüfen + Erstellen aus und wählen Sie dann Erstellen aus.
Hochladen von Beispieldaten in den Blobcontainer
Nachdem Sie ein Azure-Speicherkonto erstellt und es mit Ihrer Sprachressource verknüpft haben, müssen Sie die Dokumente aus dem Beispieldataset in das Stammverzeichnis Ihres Containers hochladen. Diese Dokumente werden später zum Trainieren Ihres Modells verwendet.
Öffnen Sie die ZIP-Datei, und extrahieren Sie den Ordner mit den darin enthaltenen Dokumenten.
Navigieren Sie im Azure-Portal zu dem Speicherkonto, das Sie erstellt haben, und wählen Sie es aus.
Klicken Sie in Ihrem Speicherkonto im Menü auf der linken Seite unter Datenspeicher auf Container. Klicken Sie im angezeigten Bildschirm auf + Container. Geben Sie dem Container den Namen example-data, und übernehmen Sie den Standardwert für Öffentliche Zugriffsebene.
Wählen Sie den neu erstellten Container aus. Wählen Sie dann die Schaltfläche Hochladen aus, um die Dateien
.txtund.jsonauszuwählen, die Sie zuvor heruntergeladen haben.
Das zur Verfügung gestellte Beispieldataset enthält 20 Kreditverträge. Jeder Vertrag beinhaltet zwei Parteien: einen Kreditgeber und einen Kreditnehmer. Sie können die bereitgestellte Beispieldatei verwenden, um relevante Informationen zu beiden Parteien, ein Vertragsdatum, einen Darlehensbetrag und einen Zinssatz zu extrahieren.
Abrufen Ihrer Ressourcenschlüssel und Endpunkte
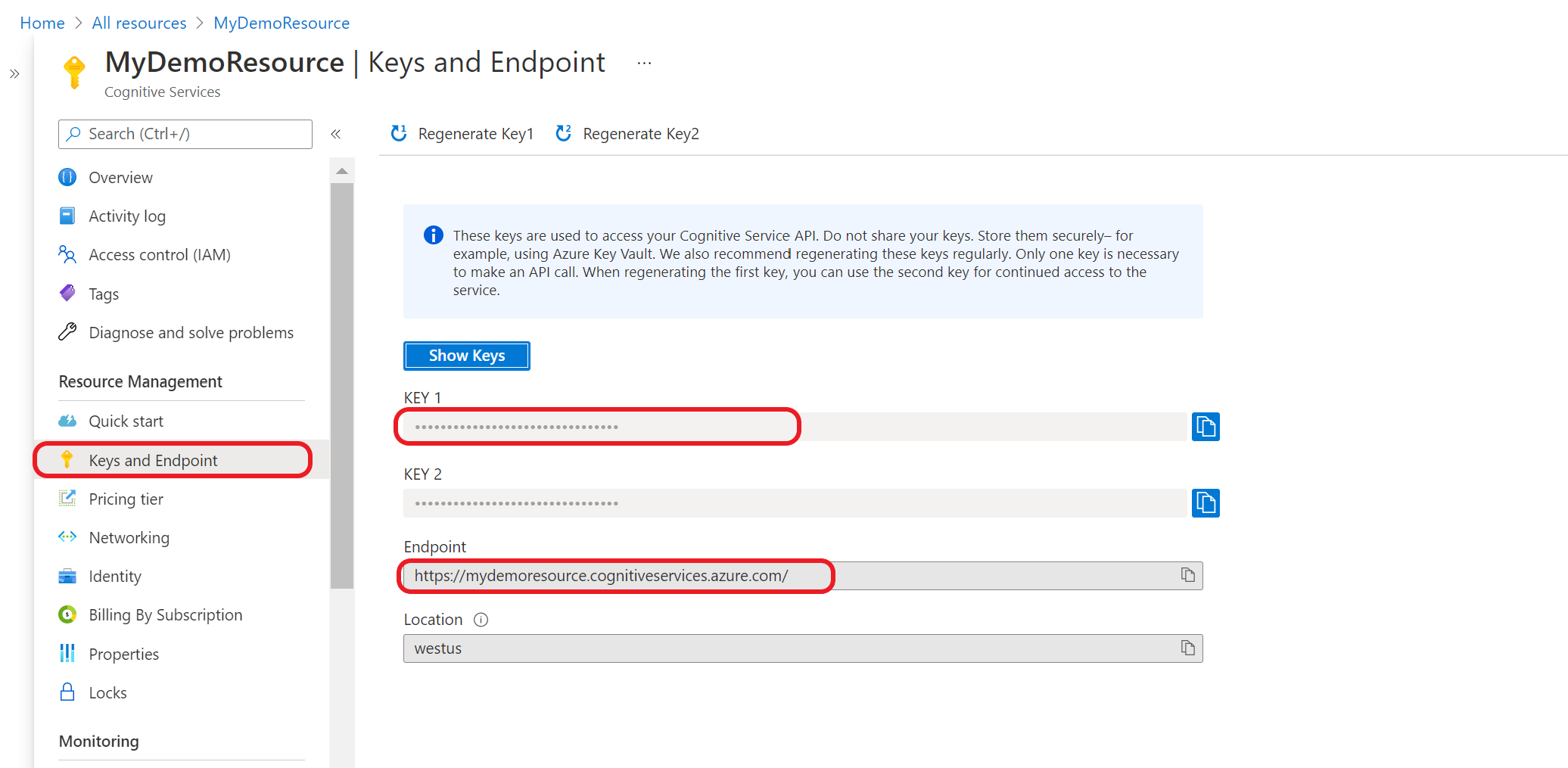
Navigieren Sie im Azure-Portal zur Übersichtsseite Ihrer Ressource.
Wählen Sie im Menü auf der linken Seite Schlüssel und Endpunkt aus. Sie verwenden den Endpunkt und Schlüssel für die API-Anforderungen.

Erstellen eines benutzerdefinierten NER-Projekts
Nachdem Ihre Ressource und das Speicherkonto konfiguriert wurden, erstellen Sie ein neues benutzerdefiniertes NER-Projekt. Ein Projekt ist ein Arbeitsbereich zum Erstellen Ihrer benutzerdefinierten ML-Modelle auf der Grundlage Ihrer Daten. Auf Ihr Projekt können nur Sie und andere Personen zugreifen, die Zugriff auf die verwendete Sprachressource haben.
Verwenden Sie die Tagdatei, die Sie aus den Beispieldaten im vorherigen Schritt heruntergeladen haben, und fügen Sie sie dem Textkörper der folgenden Anforderung hinzu.
Auslösen des Importprojektauftrags
Übermitteln Sie eine POST-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um Ihre Bezeichnungsdatei zu importieren. Stellen Sie sicher, dass die Bezeichnungsdatei dem akzeptierten Format entspricht.
Wenn bereits ein Projekt mit demselben Namen existiert, werden die Daten dieses Projekts ersetzt.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Body
Verwenden Sie den folgenden JSON-Code in Ihrer Anforderung. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomEntityRecognition",
"description": "Trying out custom NER",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomEntityRecognition",
"entities": [
{
"category": "Entity1"
},
{
"category": "Entity2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
api-version |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Die hier verwendete Version muss mit der API-Version in der URL identisch sein. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier. | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
projectKind |
CustomEntityRecognition |
Die Art Ihres Projekts | CustomEntityRecognition |
language |
{LANGUAGE-CODE} |
Eine Zeichenfolge, die den Sprachcode für die in Ihrem Projekt verwendeten Dokumente angibt. Wählen Sie bei einem mehrsprachigen Projekt den Sprachcode für die Sprache aus, die in den meisten der Dokumente verwendet wird. | en-us |
multilingual |
true |
Ein boolescher Wert, der es ermöglicht, dass Ihr Dataset Dokumente in mehreren Sprachen enthält. Wenn Ihr Modell bereitgestellt wird, können Sie das Modell in jeder unterstützten Sprache abfragen (nicht unbedingt in Ihren Trainingsdokumenten enthalten). Weitere Informationen zur Unterstützung mehrerer Sprachen finden Sie unter Sprachunterstützung. | true |
storageInputContainerName |
{CONTAINER-NAME} | Der Name Ihres Azure-Speichercontainers, in den Sie Ihre Dokumente hochgeladen haben | myContainer |
entities |
Dies ist ein Array mit allen Entitätstypen, die im Projekt enthalten sind. Dies sind die Entitätstypen, die aus Ihren Dokumenten extrahiert werden. | ||
documents |
Dies ist ein Array mit allen Dokumenten in Ihrem Projekt und die Liste der Entitäten, die innerhalb jedes Dokuments gekennzeichnet sind. | [] | |
location |
{DOCUMENT-NAME} |
Dies ist der Speicherort der Dokumente im Speichercontainer. Da sich alle Dokumente im Stammverzeichnis des Containers befinden, sollte dies der Dokumentname sein. | doc1.txt |
dataset |
{DATASET} |
Dies ist der Testsatz, in den diese Datei bei der Aufteilung vor dem Training aufgenommen wird. Weitere Informationen darüber, wie Ihre Daten geteilt werden, finden Sie unter Trainieren eines Modells. Mögliche Werte für dieses Feld sind Train und Test. |
Train |
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 202, die angibt, dass der Auftrag ordnungsgemäß übermittelt wurde. Extrahieren Sie in den Antwortheadern den operation-location-Wert. Er weist das folgende Format auf:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wird verwendet, um Ihre Anforderung zu identifizieren, da es sich um einen asynchronen Vorgang handelt. Sie verwenden diese URL, um den Status des Importauftrags abzurufen.
Mögliche Fehlerszenarios für diese Anforderung:
- Die ausgewählte Ressource verfügt nicht über die richtigen Berechtigungen für das Speicherkonto.
- Das angegebene
storageInputContainerName-Element ist nicht vorhanden. - Ein ungültiger Sprachcode wird verwendet, oder der Sprachcodetyp ist keine Zeichenfolge.
- Der Wert
multilingualist eine Zeichenfolge und kein boolescher Wert.
Abrufen des Importauftragsstatus
Verwenden Sie die folgende GET-Anforderung, um den Status Ihres Projekts abzurufen. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
Anfrage-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. Dieser Wert befindet sich im location-Headerwert, den Sie im vorherigen Schritt erhalten haben. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Trainieren Ihres Modells
Nachdem Sie ein Projekt erstellt haben, beginnen Sie in der Regel damit, die Dokumente zu markieren, die im mit Ihrem Projekt verknüpften Container vorhanden sind. Für diese Schnellstartanleitung haben Sie ein markiertes Beispieldataset importiert und Ihr Projekt mit der JSON-Beispieltagdatei initialisiert.
Starten des Trainingsauftrags
Nachdem das Projekt importiert wurde, können Sie mit dem Trainieren Ihres Modells beginnen.
Übermitteln Sie eine POST-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um einen Trainingsauftrag zu senden. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Anforderungstext
Verwenden Sie den folgenden JSON-Code im Anforderungstext. Das Modell wird {MODEL-NAME} benannt, nachdem das Training abgeschlossen ist. Nur erfolgreiche Trainingsaufträge generieren Modelle.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Der Modellname, der Ihrem Modell nach dem erfolgreichen Training zugewiesen wird | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Dies ist die Modellversion, die zum Trainieren des Modells verwendet wird. | 2022-05-01 |
| evaluationOptions | Option zum Aufteilen Ihrer Daten zwischen Trainings- und Testsätzen | {} |
|
| kind | percentage |
Aufteilungsmethoden Mögliche Werte sind percentage oder manual. Weitere Informationen finden Sie unter Trainieren eines Modells. |
percentage |
| trainingSplitPercentage | 80 |
Prozentsatz der markierten Daten, die in den Trainingssatz einbezogen werden sollen. Der empfohlene Wert ist 80. |
80 |
| testingSplitPercentage | 20 |
Prozentsatz der markierten Daten, die in den Testsatz einbezogen werden sollen. Der empfohlene Wert ist 20. |
20 |
Hinweis
trainingSplitPercentage und testingSplitPercentage sind nur erforderlich, wenn Kind auf percentage festgelegt ist, und die Summe beider Prozentsätze sollte 100 ergeben.
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 202, die angibt, dass der Auftrag ordnungsgemäß übermittelt wurde. Extrahieren Sie in den Antwortheadern den location-Wert. Er weist das folgende Format auf:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wird verwendet, um Ihre Anforderung zu identifizieren, da es sich um einen asynchronen Vorgang handelt. Sie können diese URL zum Abrufen des Trainingsstatus verwenden.
Abrufen des Trainingsauftragsstatus
Das Training kann zwischen 10 und 30 Minuten für dieses Beispieldataset dauern. Sie können die folgende Anforderung verwenden, um den Status des Trainingsauftrags bis zum erfolgreichen Abschluss abzufragen.
Verwenden Sie die folgende GET-Anforderung, um den Trainingsstatus Ihres Modells abzufragen. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
Anfrage-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. Dieser Wert befindet sich im location-Headerwert, den Sie im vorherigen Schritt erhalten haben. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Antworttext
Nachdem Sie die Anforderung gesendet haben, erhalten Sie die folgende Antwort.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Bereitstellen Ihres Modells
Im Allgemeinen überprüfen Sie nach dem Trainieren eines Modells seine Auswertungsdetails und nehmen bei Bedarf Verbesserungen vor. In diesem Schnellstart stellen Sie einfach Ihr Modell bereit und stellen es zur Verfügung, um es in Language Studio auszuprobieren. Alternativ können Sie die Vorhersage-API aufrufen.
Starten des Bereitstellungsauftrags
Übermitteln Sie eine PUT-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um einen Bereitstellungsauftrag zu senden. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{DEPLOYMENT-NAME} |
Der Name Ihrer Bereitstellung. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | staging |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Anforderungstext
Verwenden Sie die folgende JSON-Datei im Textkörper Ihrer Anforderung. Verwenden Sie den Namen des Modells, das Sie der Bereitstellung zuweisen.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Der Modellname, der Ihrer Bereitstellung zugewiesen wird. Sie können nur Modelle zuweisen, für die das Training erfolgreich war. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myModel |
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 202, die angibt, dass der Auftrag ordnungsgemäß übermittelt wurde. Extrahieren Sie in den Antwortheadern den operation-location-Wert. Er weist das folgende Format auf:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wird verwendet, um Ihre Anforderung zu identifizieren, da es sich um einen asynchronen Vorgang handelt. Sie können diese URL verwenden, um den Bereitstellungsstatus abzurufen.
Abrufen des Auftragsstatus der Bereitstellung
Verwenden Sie die folgende GET-Anforderung, um den Status des Bereitstellungsauftrags abzurufen. Sie können die URL verwenden, die Sie im vorherigen Schritt erhalten haben, oder die Platzhalterwerte unten durch Ihre eigenen Werte ersetzen.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{DEPLOYMENT-NAME} |
Der Name Ihrer Bereitstellung. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | staging |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. Diese befindet sich im location-Headerwert, den Sie im vorherigen Schritt erhalten haben. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Antworttext
Nachdem Sie die Anforderung gesendet haben, erhalten Sie die folgende Antwort. Setzen Sie den Abruf dieses Endpunkts fort, bis der Parameter status zu „succeeded“ (erfolgreich) wechselt. Sie sollten einen 200-Code erhalten, der den Erfolg der Anforderung angibt.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Extrahieren benutzerdefinierter Entitäten
Nachdem Ihr Modell bereitgestellt wurde, können Sie es verwenden, um über die Vorhersage-API Entitäten aus Ihrem Text zu extrahieren. Im zuvor heruntergeladenen Beispieldataset finden Sie einige Testdokumente, die Sie in diesem Schritt verwenden können.
Übermitteln einer Aufgabe für benutzerdefinierte NER
Verwenden Sie diese POST-Anforderung, um eine Textklassifizierungsaufgabe zu starten.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
| Schlüssel | Wert |
|---|---|
| Ocp-Apim-Subscription-Key | Ihr Schlüssel, der den Zugriff auf diese API ermöglicht. |
Body
{
"displayName": "Extracting entities",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomEntityRecognition",
"taskName": "Entity Recognition",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
displayName |
{JOB-NAME} |
Dies ist der Name Ihres Auftrags. | MyJobName |
documents |
[{},{}] | Dies ist die Liste der Dokumente, für die Aufgaben ausgeführt werden sollen. | [{},{}] |
id |
{DOC-ID} |
Hierbei handelt es sich um den Namen oder die ID des Dokuments. | doc1 |
language |
{LANGUAGE-CODE} |
Dies ist eine Zeichenfolge, die den Sprachcode des Dokuments angibt. Wenn dieser Schlüssel nicht angegeben ist, nimmt der Dienst die Standardsprache des Projekts an, die bei der Projekterstellung ausgewählt wurde. Unter Sprachunterstützung finden sie eine Liste der unterstützten Sprachcodes. | en-us |
text |
{DOC-TEXT} |
Dies ist die Dokumentaufgabe, für die die Aufgaben ausgeführt werden sollen. | Lorem ipsum dolor sit amet |
tasks |
Liste der Aufgaben, die ausgeführt werden sollen. | [] |
|
taskName |
CustomEntityRecognition |
Aufgabenname | CustomEntityRecognition |
parameters |
Dies ist die Liste der Parameter, die an die Aufgabe übergeben werden. | ||
project-name |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Der Name Ihrer Bereitstellung. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | prod |
Antwort
Sie erhalten eine Antwort vom Typ „202“, die angibt, dass Ihre Aufgabe erfolgreich übermittelt wurde. Extrahieren Sie operation-location in den Antwortheadern.
operation-location weist dieses Format auf:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Sie können diese URL verwenden, um den Abschlussstatus der Aufgabe abzufragen und die Ergebnisse abzurufen, wenn die Aufgabe abgeschlossen ist.
Abrufen der Aufgabenergebnisse
Verwenden Sie die folgende GET-Anforderung, um den Status/die Ergebnisse der Aufgabe für die Erkennung von benutzerdefinierten Entitäten abzufragen.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
| Schlüssel | Wert |
|---|---|
| Ocp-Apim-Subscription-Key | Ihr Schlüssel, der den Zugriff auf diese API ermöglicht. |
Antworttext
Die Antwort ist ein JSON-Dokument mit den folgenden Parametern.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "EntityRecognitionLROResults",
"taskName": "Recognize Entities",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"category": "Event",
"confidenceScore": 0.61,
"length": 4,
"offset": 18,
"text": "trip"
},
{
"category": "Location",
"confidenceScore": 0.82,
"length": 7,
"offset": 26,
"subcategory": "GPE",
"text": "Seattle"
},
{
"category": "DateTime",
"confidenceScore": 0.8,
"length": 9,
"offset": 34,
"subcategory": "DateRange",
"text": "last week"
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Bereinigen von Ressourcen
Wenn Sie Ihr Projekt nicht mehr benötigen, können Sie es mit der folgenden DELETE-Anforderung löschen. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
| Ocp-Apim-Subscription-Key | Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 202, die anzeigt, dass Ihr Projekt erfolgreich gelöscht wurde. Ein erfolgreicher Aufruf enthält einen Operation-Location-Header, mit dem der Auftragsstatus überprüft wird.
Nächste Schritte
Nachdem Sie das Entitätsextraktionsmodell erstellt haben, haben Sie dies:
Wenn Sie beginnen, eigene benutzerdefinierte NER-Projekte zu erstellen, verwenden Sie die Anleitungsartikel, um ausführlichere Informationen zum Kennzeichnen, Trainieren und Nutzen Ihres Modells zu erhalten: