Testen der Erkennungsqualität eines Custom Speech-Modells
Sie können die Erkennungsqualität eines Custom Speech-Modells in Speech Studio überprüfen. Sie können hochgeladene Audiodaten wiedergeben und bestimmen, ob das angegebene Erkennungsergebnis korrekt ist. Nachdem ein Test erfolgreich erstellt wurde, können Sie sehen, wie ein Modell das Audiodataset transkribiert, oder die Ergebnisse von zwei Modellen direkt miteinander vergleichen.
Parallele Modelltests sind nützlich, um zu überprüfen, welches Spracherkennungsmodell für eine Anwendung am besten geeignet ist. Informationen zu einem objektiven Maß der Genauigkeit, für die eine Transkription der Dataseteingabe erforderlich ist, finden Sie unter Quantitatives Testen des Modells.
Wichtig
Beim Testen führt das System eine Transkription durch. Dies sollten Sie nicht vergessen, da die Preise pro Serviceangebot und Abonnementebene variieren. Aktuelle Informationen finden Sie immer auf der offiziellen Seite „Azure KI Services-Preise“.
Erstellen eines Tests
Gehen Sie wie folgt vor, um einen Test zu erstellen:
Melden Sie sich in Speech Studio an.
Navigieren Sie zu Speech Studio>Custom Speech und wählen Sie Ihren Projektnamen in der Liste aus.
Wählen Sie Testmodelle>Neuen Test erstellen aus.
Wählen Sie Qualität überprüfen (reine Audiodaten)>Weiter aus.
Wählen Sie ein Audiodataset aus, das Sie zum Testen verwenden möchten, und wählen Sie dann Weiter aus. Wenn keine Datasets verfügbar sind, brechen Sie das Setup ab, und wechseln Sie dann zum Menü Speech-Datasets, um Datasets hochzuladen.
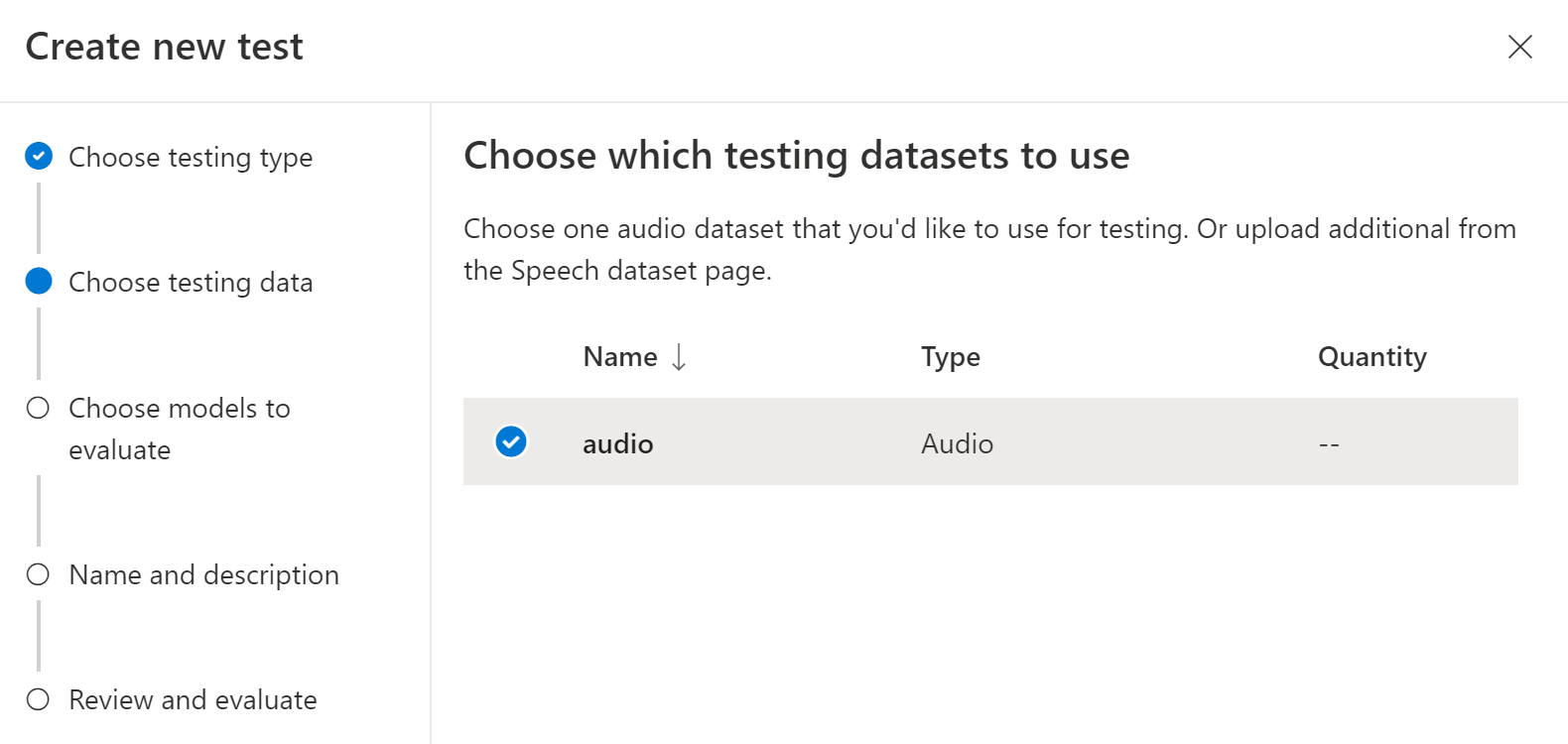
Wählen Sie ein oder zwei Modelle aus, um die Genauigkeit auszuwerten und zu vergleichen.
Geben Sie den Testnamen und eine Beschreibung ein, und wählen Sie dann Weiter aus.
Überprüfen Sie Ihre Einstellungen, und wählen Sie anschließend Speichern und schließen aus.
Zum Erstellen eines Tests verwenden Sie den Befehl spx csr evaluation create. Erstellen Sie die Anforderungsparameter gemäß den folgenden Anweisungen:
- Legen Sie den
project-Parameter auf die ID eines vorhandenen Projekts fest. Dieser Parameter empfiehlt sich, damit Sie den Test auch in Speech Studio anzeigen können. Mit dem Befehlspx csr project listkönnen Sie verfügbare Projekte abrufen. - Legen Sie den erforderlichen
model1-Parameter auf die ID eines Modells fest, das Sie testen möchten. - Legen Sie den erforderlichen
model2-Parameter auf die ID eines anderen Modells fest, das Sie testen möchten. Wenn Sie nicht zwei Modelle vergleichen möchten, verwenden Sie das gleiche Modell sowohl fürmodel1als auch fürmodel2. - Legen Sie den erforderlichen
dataset-Parameter auf die ID eines Datasets fest, das Sie für den Test verwenden möchten. - Legen Sie den
language-Parameter fest, andernfalls legt die Speech-Befehlszeilenschnittstelle standardmäßig „en-US“ fest. Dieser Parameter sollte das Gebietsschema des Datasetinhalts sein. Das Gebietsschema können Sie später nicht mehr ändern. Der Parameterlanguageder Speech-Befehlszeilenschnittstelle entspricht derlocale-Eigenschaft in der JSON-Anforderung und -Antwort. - Legen Sie den erforderlichen
name-Parameter fest. Dieser Parameter ist der Name, der im Speech Studio angezeigt wird. Der Parameternameder Speech-Befehlszeilenschnittstelle entspricht derdisplayName-Eigenschaft in der JSON-Anforderung und -Antwort.
Hier ist ein beispielhafter Befehl der Speech-Befehlszeilenschnittstelle, der einen Test erstellt:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 13fb305e-09ad-4bce-b3a1-938c9124dda3 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Inspection" --description "My Inspection Description"
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Die oberste self-Eigenschaft im Antworttext ist der URI der Auswertung. Verwenden Sie diesen URI, um Details zum Projekt und Testergebnisse abzurufen. Sie verwenden diesen URI auch, um die Auswertung zu aktualisieren oder zu löschen.
Führen Sie den folgenden Befehl aus, um Hilfe für die Speech-Befehlszeilenschnittstelle mit Auswertungen zu erhalten:
spx help csr evaluation
Verwenden Sie zum Erstellen eines Tests den Vorgang Evaluations_Create der Spracherkennung-REST-API. Erstellen Sie den Anforderungstext gemäß den folgenden Anweisungen:
- Legen Sie die
project-Eigenschaft auf den URI eines vorhandenen Projekts fest. Diese Eigenschaft empfiehlt sich, damit Sie den Test auch in Speech Studio anzeigen können. Sie können eine Projects_List-Anforderung zum Abrufen verfügbarer Projekte ausführen. - Legen Sie die erforderliche
model1-Eigenschaft auf den URI eines Modells fest, das Sie testen möchten. - Legen Sie die erforderliche
model2-Eigenschaft auf den URI eines anderen Modells fest, das Sie testen möchten. Wenn Sie nicht zwei Modelle vergleichen möchten, verwenden Sie das gleiche Modell sowohl fürmodel1als auch fürmodel2. - Legen Sie den erforderlichen
dataset-Parameter auf die ID eines Datasets fest, das Sie für den Test verwenden möchten. - Legen Sie die erforderliche
locale-Eigenschaft fest. Diese Eigenschaft sollte das Gebietsschema des Datasetinhalts sein. Das Gebietsschema können Sie später nicht mehr ändern. - Legen Sie die erforderliche
displayName-Eigenschaft fest. Diese Eigenschaft ist der Name, der im Speech Studio angezeigt wird.
Erstellen Sie eine HTTP POST-Anforderung mithilfe des URI, wie im folgenden Beispiel gezeigt. Ersetzen Sie YourSubscriptionKey durch Ihren Speech-Ressourcenschlüssel, ersetzen Sie YourServiceRegion durch die Region der Speech-Ressource, und legen Sie die Anforderungstexteigenschaften wie zuvor beschrieben fest.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Die oberste self-Eigenschaft im Antworttext ist der URI der Auswertung. Verwenden Sie diesen URI, um Details über das Projekt und die Testergebnisse der Auswertung abzurufen. Sie verwenden diesen URI auch, um die Auswertung zu aktualisieren oder zu löschen.
Abrufen von Testergebnissen
Sie sollten die Testergebnisse abrufen und die Audiodatensätze im Vergleich mit den Transkriptionsergebnissen für jedes Modell überprüfen.
Führen Sie die folgenden Schritte aus, um Testergebnisse abzurufen:
- Melden Sie sich in Speech Studio an.
- Wählen Sie Custom Speech> Ihr Projektname >Modelle testen aus.
- Wählen Sie den Link anhand des Testnamens aus.
- Nachdem der Test abgeschlossen ist, wie durch den auf Erfolgreich festgelegten Status angegeben, sollten Sie Ergebnisse sehen, die die WER-Zahl für jedes getestete Modell enthalten.
Auf dieser Seite sind alle Äußerungen in Ihrem Dataset und die Erkennungsergebnisse neben der Transkription aus dem übermittelten Dataset aufgelistet. Sie können zwischen verschiedenen Fehlertypen umschalten, darunter Einfügung, Löschung und Ersetzung. Durch Anhören der Audiodaten und Vergleich mit den Erkennungsergebnissen in den einzelnen Spalten können Sie entscheiden, welches Modell Ihre Anforderungen erfüllt und ermitteln, wo weiteres Training und Verbesserungen erforderlich sind.
Verwenden Sie den Befehl spx csr evaluation status, um Testergebnisse abzurufen. Erstellen Sie die Anforderungsparameter gemäß den folgenden Anweisungen:
- Legen Sie den erforderlichen
evaluation-Parameter auf die ID der Auswertung fest, für die Sie Testergebnisse abrufen möchten.
Hier ist ein beispielhafter Befehl der Speech-Befehlszeilenschnittstelle, der Testergebnisse abruft:
spx csr evaluation status --api-version v3.2 --evaluation 9c06d5b1-213f-4a16-9069-bc86efacdaac
Die Modelle, Audiodatasets, Transkriptionen und weiteren Details werden im Antworttext zurückgegeben.
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Führen Sie den folgenden Befehl aus, um Hilfe für die Speech-Befehlszeilenschnittstelle mit Auswertungen zu erhalten:
spx help csr evaluation
Zum Abrufen von Testergebnissen beginnen Sie mit dem Vorgang Evaluations_Get der Spracherkennung-REST-API.
Erstellen Sie eine HTTP GET-Anforderung mithilfe des URI, wie im folgenden Beispiel gezeigt. Ersetzen Sie YourEvaluationId durch Ihre Auswertungs-ID, YourSubscriptionKey durch den Schlüssel Ihrer Speech-Ressource und YourServiceRegion durch die Region Ihrer Speech-Ressource.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
Die Modelle, Audiodatasets, Transkriptionen und weiteren Details werden im Antworttext zurückgegeben.
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Vergleichen der Transkription mit Audio
Sie können die Transkriptionsausgabe für jedes getestete Modell anhand des Audioeingabedatasets untersuchen. Wenn Sie zwei Modelle in den Test eingeschlossen haben, können Sie ihre Transkriptionsqualität nebeneinander vergleichen.
So überprüfen Sie die Qualität der Transkriptionen:
- Melden Sie sich in Speech Studio an.
- Wählen Sie Custom Speech> Ihr Projektname >Modelle testen aus.
- Wählen Sie den Link anhand des Testnamens aus.
- Geben Sie eine Audiodatei wieder, während Sie die entsprechende Transkription durch ein Modell lesen.
Wenn das Testdataset mehrere Audiodateien enthält, werden in der Tabelle mehrere Zeilen angezeigt. Wenn Sie zwei Modelle in den Test eingeschlossen haben, werden Transkriptionen in Spalten nebeneinander angezeigt. Transkriptionsunterschiede zwischen Modellen werden in blauer Textschriftart angezeigt.
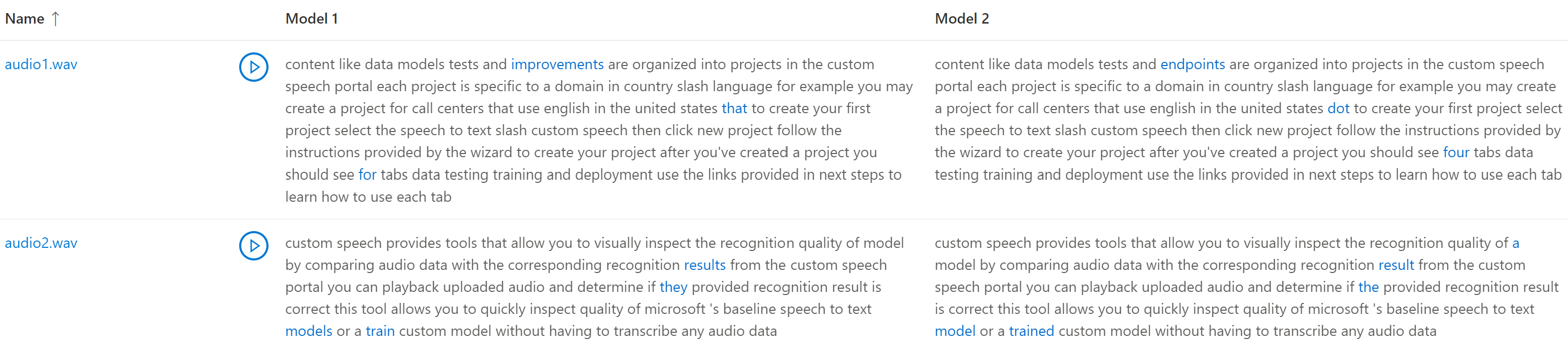
Die getesteten Audiotestdatasets, Transkriptionen und Modelle werden in den Testergebnissen zurückgegeben. Wenn nur ein Modell getestet wurde, stimmt der model1-Wert mit model2 überein und der transcription1-Wert stimmt mit transcription2 überein.
So überprüfen Sie die Qualität der Transkriptionen:
- Laden Sie das Audiotestdataset herunter, es sei denn, Sie verfügen bereits über eine Kopie.
- Laden Sie die ausgegebenen Transkriptionen herunter.
- Geben Sie eine Audiodatei wieder, während Sie die entsprechende Transkription durch ein Modell lesen.
Wenn Sie die Qualität zwischen zwei Modellen vergleichen, achten Sie besonders auf Unterschiede zwischen den Transkriptionen der Modelle.
Die getesteten Audiotestdatasets, Transkriptionen und Modelle werden in den Testergebnissen zurückgegeben. Wenn nur ein Modell getestet wurde, stimmt der model1-Wert mit model2 überein und der transcription1-Wert stimmt mit transcription2 überein.
So überprüfen Sie die Qualität der Transkriptionen:
- Laden Sie das Audiotestdataset herunter, es sei denn, Sie verfügen bereits über eine Kopie.
- Laden Sie die ausgegebenen Transkriptionen herunter.
- Geben Sie eine Audiodatei wieder, während Sie die entsprechende Transkription durch ein Modell lesen.
Wenn Sie die Qualität zwischen zwei Modellen vergleichen, achten Sie besonders auf Unterschiede zwischen den Transkriptionen der Modelle.