Worum handelt es sich bei der Schlüsselworterkennung?
Die Schlüsselworterkennung erkennt ein Wort oder einen kurzen Ausdruck innerhalb eines Audiodatenstroms. Diese Technik wird auch als Schlüsselwortsuche bezeichnet.
Der häufigste Anwendungsfall der Schlüsselworterkennung ist die Sprachaktivierung virtueller Assistenten. „Hey Cortana“ ist z. B. das Schlüsselwort für den Cortana-Assistenten. Bei Erkennung des Schlüsselworts wird eine szenariospezifische Aktion ausgeführt. Bei Szenarien mit virtuellen Assistenten ist eine häufige resultierende Aktion die Spracherkennung von Audioinformationen, die auf das Schlüsselwort folgen.
Im Allgemeinen lauschen virtuelle Assistenten immer. Die Schlüsselworterkennung dient als Datenschutzgrenze für den Benutzer. Eine Schlüsselwortanforderung fungiert als Tor, das verhindert, dass zusammenhangslose Audioinformationen des Benutzers vom lokalen Gerät in die Cloud gelangen.
Um ein Gleichgewicht zwischen Genauigkeit, Wartezeit und Berechnungskomplexität zu erreichen, wird die Schlüsselworterkennung als mehrstufiges System implementiert. Für alle Stufen, die über die erste hinausgehen, werden Audiodaten nur dann verarbeitet, wenn die vorherige Stufe das betreffende Schlüsselwort erkennt.
Das aktuelle System ist mit mehreren Stufen konzipiert, die sich über Edge und Cloud erstrecken:
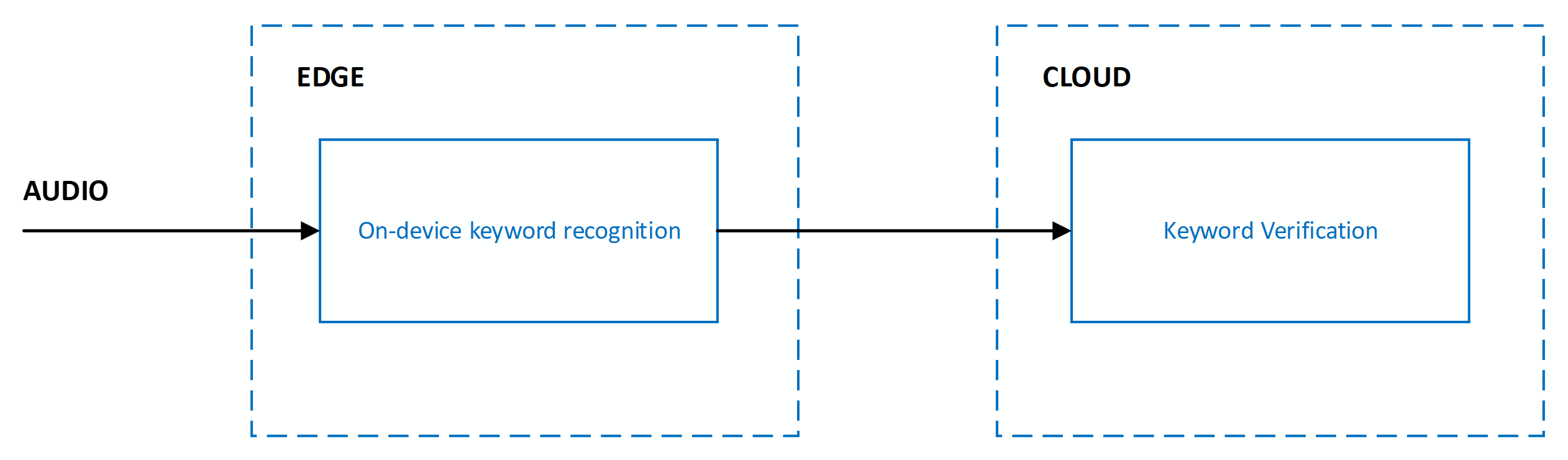
Die Genauigkeit der Schlüsselworterkennung wird anhand der folgenden Metriken gemessen:
- Akzeptanzrate für richtige Begriffe: misst die Fähigkeit des Systems, das von einem Benutzer gesprochene Schlüsselwort zu erkennen. Die Akzeptanzrate für richtige Begriffe wird auch als True Positive-Rate bezeichnet.
- Akzeptanzrate für falsche Begriffe: Misst die Fähigkeit des Systems, Audiodaten herauszufiltern, die nicht das von einem Benutzer gesprochene Schlüsselwort sind. Die Akzeptanzrate für falsche Begriffe wird auch als False Positive-Rate bezeichnet.
Ziel ist es, die Akzeptanzrate für richtige Begriffe zu maximieren und gleichzeitig die Akzeptanzrate für falsche Begriffe zu minimieren. Das aktuelle System ist darauf ausgelegt, ein Schlüsselwort oder einen Ausdruck zu erkennen, dem eine kurze Zeit der Stille vorausgeht. Die Erkennung eines Schlüsselworts in der Mitte eines Satzes oder einer Äußerung wird nicht unterstützt.
Benutzerdefiniertes Schlüsselwort für gerätebasierte Modelle
Mit dem Portal „Benutzerdefiniertes Schlüsselwort“ in Speech Studio können Sie durch die Angabe eines beliebigen Worts oder eines kurzen Ausdrucks Modelle für die Erkennung von Schlüsselwörtern generieren, die am Edge ausgeführt werden. Sie können Ihr Schlüsselwortmodell weiter personalisieren, indem Sie die richtigen Aussprachen auswählen.
Preise
Es entstehen keine Kosten, wenn Sie ein benutzerdefiniertes Schlüsselwort zum Erstellen von Modellen verwenden, einschließlich der einfachen und erweiterten Modelle. Es fallen auch keine Kosten für die Ausführung von gerätebasierten Modellen mit dem Speech-SDK an, wenn die Verwendung mit anderen Speech-Dienstfeatures wie Spracherkennung erfolgt.
Typen von Modellen
Mit einem benutzerdefinierten Schlüsselwort können Sie zwei Typen von gerätebasierten Modellen für jedes beliebige Schlüsselwort generieren:
| Modelltyp | BESCHREIBUNG |
|---|---|
| Basic | Am besten geeignet für Demos oder die schnelle Erstellung von Prototypen. Die Modelle werden mit einem gemeinsamen Basismodell generiert und können bis zu 15 Minuten in Anspruch nehmen, bis sie bereit sind. Die Modelle weisen möglicherweise keine optimalen Genauigkeitsmerkmale auf. |
| Fortgeschrittene | Am besten für die Produktintegration geeignet. Die Modelle werden durch Anpassung eines gemeinsamen Basismodells unter Verwendung simulierter Trainingsdaten generiert, um die Genauigkeitsmerkmale zu verbessern. Es kann bis zu 48 Stunden dauern, bis die Modelle bereit sind. |
Hinweis
Eine Liste der Regionen, die den Modelltyp Erweitert unterstützen, finden Sie in der Dokumentation zur Unterstützung von Regionen für die Schlüsselworterkennung.
Keiner der Modelltypen erfordert, dass Sie Trainingsdaten hochladen. „Benutzerdefiniertes Schlüsselwort“ übernimmt die komplette Datengenerierung und das Modelltraining.
Aussprache
Beim Erstellen eines neuen Modells generiert „Benutzerdefiniertes Schlüsselwort“ automatisch mögliche Aussprachen des angegebenen Schlüsselworts. Sie können den einzelnen Aussprachen lauschen und alle auswählen, die am ehesten die Art und Weise repräsentieren, wie Sie erwarten, dass Benutzer das Schlüsselwort aussprechen. Alle anderen Aussprachen sollten nicht ausgewählt werden.
Es ist wichtig, die Aussprache bewusst zu wählen, um die besten Genauigkeitsmerkmale sicherzustellen. Wenn Sie beispielsweise mehr Aussprachen als nötig auswählen, kann dies zu höheren Akzeptanzraten für falsche Begriffe führen. Die Auswahl von zu wenigen Aussprachen, bei denen nicht alle erwarteten Variationen abgedeckt sind, kann zu niedrigeren Akzeptanzraten für richtige Begriffe führen.
Testmodelle
Nachdem das benutzerdefinierte Schlüsselwort auf Gerätemodellen generiert wurden, können die Modelle direkt im Portal getestet werden. Sie können das Portal verwenden, um direkt in Ihren Browser zu sprechen und Ergebnisse der Schlüsselworterkennung abzurufen.
Schlüsselwortüberprüfung
Bei der Schlüsselwortüberprüfung handelt es sich um einen Clouddienst, der die Auswirkungen der Annahme falscher Begriffe von gerätebasierten Modellen mit stabilen Modellen reduziert, die in Azure ausgeführt werden. Damit die Schlüsselwortüberprüfung mit Ihrem Schlüsselwort funktioniert, sind weder Optimierung noch Training erforderlich. Inkrementelle Modellupdates werden kontinuierlich für den Dienst bereitgestellt, um die Genauigkeit und Wartezeit zu verbessern. Sie sind für Clientanwendungen transparent.
Preise
Die Schlüsselwortüberprüfung wird immer in Kombination mit der Spracherkennung verwendet. Über die Kosten für die Spracherkennung hinaus fallen keine Kosten für die Verwendung der Schlüsselwortüberprüfung an.
Schlüsselwortüberprüfung und Spracherkennung
Wenn die Schlüsselwortüberprüfung verwendet wird, erfolgt dies immer in Kombination mit der Spracherkennung. Beide Dienste werden parallel ausgeführt. Das bedeutet, dass Audiodaten zur gleichzeitigen Verarbeitung an beide Dienste gesendet werden.
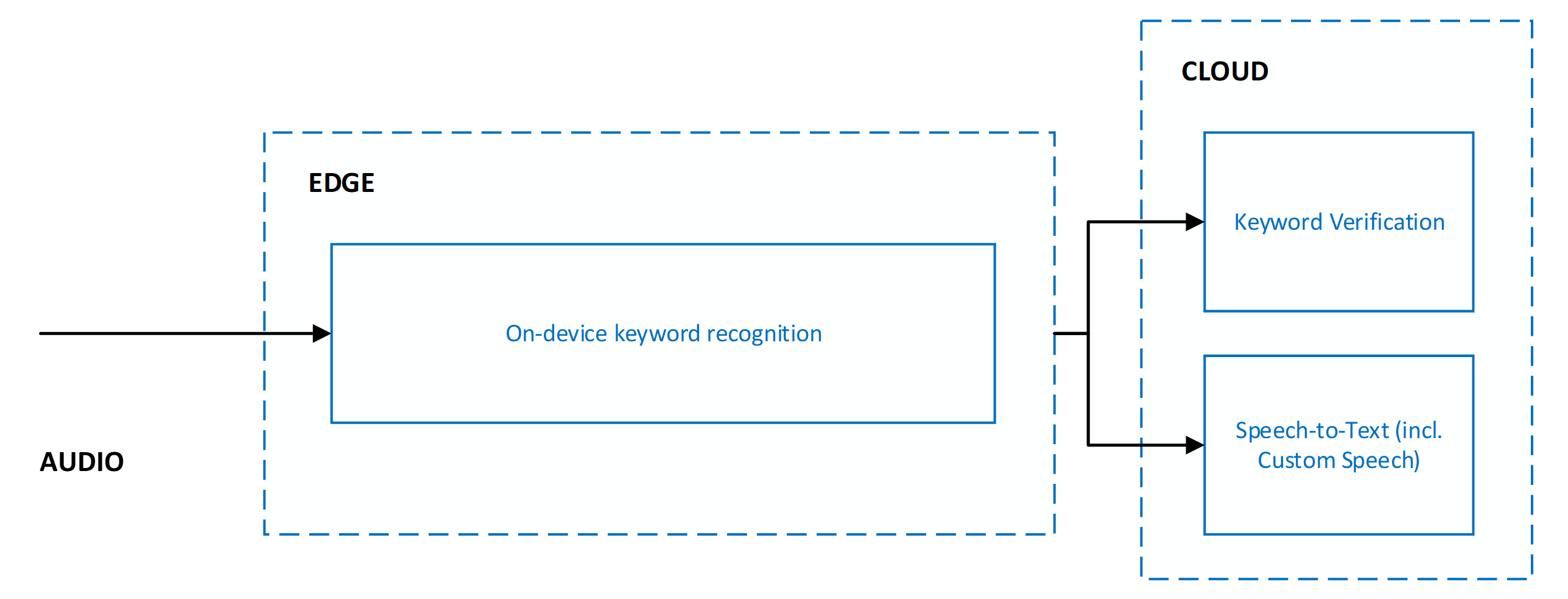
Die parallele Ausführung von Schlüsselwortüberprüfung und Spracherkennung bietet die folgenden Nutzen:
- Keine zusätzliche Wartezeit bei Spracherkennungsergebnissen: Parallele Ausführung bedeutet, dass die Schlüsselwortüberprüfung keine Wartezeit hinzufügt. Der Client empfängt Spracherkennungsergebnisse genauso schnell. Wenn bei der Schlüsselwortüberprüfung festgestellt wird, dass das Schlüsselwort in den Audiodaten nicht vorhanden war, wird die Spracherkennungsverarbeitung beendet. Diese Aktion schützt vor unnötiger Verarbeitung durch die Spracherkennung. Die Verarbeitung von Netzwerk- und Cloudmodellen erhöht die vom Benutzer wahrgenommene Wartezeit der Sprachaktivierung. Weitere Informationen finden Sie unter Empfehlungen und Richtlinien für die Schlüsselworterkennung.
- Erzwungenes Schlüsselwortpräfix in Spracherkennungsergebnissen: Die Spracherkennungsverarbeitung stellt sicher, dass den an den Client gesendeten Ergebnissen das Schlüsselwort vorangestellt wird. Dieses Verhalten ermöglicht eine höhere Genauigkeit in den Spracherkennungsergebnissen für die Sprache, die auf das Schlüsselwort folgt.
- Erhöhtes Timeout für die Spracherkennung: Aufgrund des erwarteten Vorhandenseins des Schlüsselworts am Anfang der Audiodaten erlaubt die Spracherkennung eine längere Pause von bis zu fünf Sekunden nach dem Schlüsselwort, bevor das Ende der Sprache bestimmt und die Spracherkennungsverarbeitung beendet wird. Durch dieses Verhalten wird sichergestellt, dass der Benutzer bei gestaffelten Befehlen (<keyword><pause><command>) und bei verketteten Befehlen (<keyword><command>) eine ordnungsgemäße Erfahrung erhält.
Überlegungen zu Antworten und Wartezeit bei der Schlüsselwortüberprüfung
Für jede Anforderung an den Dienst gibt die Schlüsselwortüberprüfung eine von zwei Antworten zurück: „Accepted“ (Akzeptiert) oder „Rejected“ (Abgelehnt). Die Verarbeitungswartezeit variiert in Abhängigkeit von der Länge des Schlüsselworts und der Länge des Audiosegments, das das Schlüsselwort enthalten soll. Die Verarbeitungswartezeit umfasst nicht die Netzwerkkosten zwischen dem Client und den Speech-Diensten.
| Antwort der Schlüsselwortüberprüfung | BESCHREIBUNG |
|---|---|
| Akzeptiert | Zeigt an, dass der Dienst davon ausgeht, dass das Schlüsselwort in dem als Teil der Anforderung bereitgestellten Audiodatenstrom vorhanden ist. |
| Rejected (Abgelehnt) | Zeigt an, dass der Dienst davon ausgeht, dass das Schlüsselwort in dem als Teil der Anforderung bereitgestellten Audiodatenstrom nicht vorhanden ist. |
Abgelehnte Fälle führen häufig zu höheren Wartezeiten, da der Dienst mehr Audiodaten verarbeitet als akzeptierte Fälle. Standardmäßig verarbeitet die Schlüsselwortüberprüfung maximal zwei Sekunden an Audiodaten, um nach dem Schlüsselwort zu suchen. Wird festgestellt, dass das Schlüsselwort in zwei Sekunden nicht gefunden wird, tritt beim Dienst ein Timeout auf und er signalisiert dem Client als Antwort eine Ablehnung.
Verwenden der Schlüsselwortüberprüfung mit gerätebasierten Modellen aus „Benutzerdefiniertes Schlüsselwort“
Das Speech SDK ermöglicht die nahtlose Verwendung von gerätebasierten Modellen, die mithilfe von benutzerdefinierten Schlüsselwörtern mit Schlüsselwortüberprüfung und Spracherkennung erstellt wurden. Es verarbeitet Folgendes auf transparente Weise:
- Audiozulassung zur Schlüsselwortüberprüfung und Spracherkennung basierend auf dem Ergebnis des gerätebasierten Modells
- Kommunizieren des Schlüsselworts an die Schlüsselwortüberprüfung
- Kommunizieren weiterer Metadaten an die Cloud für die Orchestrierung des End-to-End-Szenarios
Sie müssen keine Konfigurationsparameter explizit angeben. Alle erforderlichen Informationen werden automatisch aus dem von „Benutzerdefiniertes Schlüsselwort“ generierten gerätebasierten Modell extrahiert.
In den folgenden verlinkten Beispielen und Tutorials wird die Verwendung des Speech SDK veranschaulicht:
- Beispiele für Sprachassistenten auf GitHub
- Tutorial: Aktivieren der Sprachsteuerung für Ihren Assistenten, der mit Azure KI Bot Service mit dem C# Speech-SDK erstellt wurde
Speech SDK: Integration und Szenarien
Das Speech SDK ermöglicht die einfache Verwendung personalisierter gerätebasierter Modelle zur Schlüsselworterkennung, die mit „Benutzerdefiniertes Schlüsselwort“ und der Schlüsselwortüberprüfung generiert wurden. Um sicherzustellen, dass Ihre Produktanforderungen erfüllt werden können, unterstützt das SDK die beiden folgenden Szenarien:
| Szenario | BESCHREIBUNG | Beispiele |
|---|---|---|
| End-to-End-Schlüsselworterkennung mit Spracherkennung | Am besten geeignet für Produkte, die ein angepasstes gerätebasiertes Schlüsselwortmodell von benutzerdefinierten Schlüsselwörtern mit der Schlüsselwortüberprüfung und Spracherkennung verwenden. Dies ist das häufigste Szenario. | |
| Offlineschlüsselworterkennung | Am besten für Produkte ohne Netzwerkkonnektivität geeignet, die ein angepasstes gerätebasiertes Schlüsselwortmodell von „Benutzerdefiniertes Schlüsselwort“ verwenden. |