Was ist Sprachsynthese?
In diesem Überblick lernen Sie die Vorteile und Funktionen des Sprachsynthesefeatures des Speech-Diensts kennen, der Teil von Azure KI Services ist.
Die Sprachsynthese versetzt Ihre Anwendungen, Tools oder Geräte in die Lage, Text in menschlich klingende synthetisierte Sprache zu konvertieren. Die Sprachsynthese wird auch als Text-zu-Sprache-Funktion bezeichnet. Verwenden Sie menschlich klingende, vordefinierte neuronale Stimmen, oder erstellen Sie eine benutzerdefinierte neuronale Stimme speziell für Ihr Produkt oder Ihre Marke. Eine vollständige Liste der unterstützten Stimmen, Sprachen und Gebietsschemas finden Sie unter Sprach- und Stimmunterstützung für den Speech-Dienst.
Wichtige Funktionen
Die Sprachsynthese umfasst die folgenden Funktionen:
| Funktion | Zusammenfassung | Demo |
|---|---|---|
| Vordefinierte neuronale Stimme (auf der Seite mit der Preisübersicht als Neuronal bezeichnet) | Äußerst natürliche, sofort einsetzbare Stimmen. Erstellen Sie ein Azure-Abonnement und eine Speech-Ressource. Verwenden Sie anschließend das Speech SDK, oder besuchen Sie das Speech Studio-Portal, und wählen Sie für den Einstieg vordefinierte neuronale Stimmen aus. Sehen Sie sich die Preisdetails an. | Überprüfen Sie den Stimmkatalog und wählen Sie die für Ihre Geschäftsanforderungen geeignete Stimme aus. |
| Benutzerdefinierte neuronale Stimme (auf der Seite mit der Preisübersicht als Benutzerdefiniert neuronal bezeichnet) | Einfach zu verwendende Self-Service-Dienste zum Erstellen einer natürlichen Markenstimme mit eingeschränktem Zugriff für die verantwortungsvolle Verwendung. Erstellen Sie ein Azure-Abonnement und eine Speech-Ressource (mit der S0-Ebene), und beantragen Sie, die benutzerdefinierte Sprachfunktion zu verwenden. Nachdem Sie Zugriff erhalten haben, können Sie das Speech Studio-Portal besuchen und für den Einstieg Custom Voice auswählen. Sehen Sie sich die Preisdetails an. | Hören Sie sich die Sprachbeispiele an. |
Weitere Informationen zu neuronalen Sprachsynthesefeatures
Die Sprachsynthese verwendet Deep Neural Network-Instanzen, um die Stimmen von Computern so zu gestalten, dass sie von Aufzeichnungen von Personen kaum zu unterscheiden sind. Durch die klare Aussprache von Wörtern kann die neuronale Sprachsynthese die Hörermüdung bei der Interaktion mit KI-Systemen erheblich verringern.
Die Betonungs- und Intonationsmuster in gesprochener Sprache werden als Satzrhythmus bezeichnet. Die traditionellen Sprachsynthesesysteme untergliedern den Satzrhythmus in separate linguistische Analyse- und akustische Vorhersageschritte, die von unabhängigen Modellen gesteuert werden. Dies kann zu einer dumpfen, dröhnenden Sprachsynthese führen.
Nachfolgend finden Sie weitere Informationen zu neuronalen Sprachsynthesefeatures im Speech-Dienst und wie diese die Grenzen herkömmlicher Sprachsynthesesysteme überwinden:
Sprachsynthese in Echtzeit: Verwenden Sie das Speech SDK oder die REST-API, um mithilfe von vordefinierten neuronalen Stimmen oder benutzerdefinierten neuronalen Stimmen Text in Sprache zu konvertieren.
Asynchrone Synthese von langen Audiodateien: Verwenden Sie die Batchsynthese-API, um Text-zu-Sprache-Dateien von mehr als 10 Minuten Länge (z. B. Audiobücher oder Vorlesungen) asynchron zu synthetisieren. Anders als bei der Synthese über das Speech SDK oder die Spracherkennungs-REST-API werden Antworten nicht in Echtzeit zurückgegeben. Es wird davon ausgegangen, dass Anforderungen asynchron gesendet werden, Antworten abgerufen werden und das synthetisierte Audiosignal heruntergeladen wird, wenn es durch den Dienst zur Verfügung gestellt wird.
Vordefinierte neuronale Stimmen: Azure KI Speech verwendet Deep Neural Network-Instanzen, um die Grenzen der herkömmlichen Sprachsynthese in Bezug auf Betonung und Intonation in gesprochener Sprache zu überwinden. Die Vorhersage der Satzgliederung und die Stimmensynthese erfolgen gleichzeitig, sodass eine flüssigere und natürlicher klingende Ausgabe entsteht. Jedes vordefinierte neuronale Sprachmodell ist mit 24 kHz und als High-Fidelity-Version mit 48 kHz verfügbar. Sie können neuronale Stimmen für folgende Zwecke verwenden:
- Natürlicheres und ansprechenderes Gestalten der Interaktionen mit Chatbots und Sprachassistenten
- Konvertieren von digitalen Texten, z. B. E-Books in Audiobooks
- Verbessern von Navigationssystemen im Auto
Eine vollständige Liste der vorab erstellten neuronalen Stimmen von Azure KI Speech finden Sie unter Sprach- und Stimmunterstützung für den Speech-Dienst.
Verbessern der Text-zu-Sprache-Ausgabe mit SSML: Die Markupsprache für Sprachsynthese (Speech Synthesis Markup Language, SSML) ist eine XML-basierte Markupsprache, mit der Ausgaben der Sprachsynthese angepasst werden. Mit SSML können Sie die Tonhöhe anpassen, Pausen hinzufügen, die Aussprache verbessern, die Sprechgeschwindigkeit ändern, die Lautstärke anpassen und einem einzelnen Dokument mehrere Stimmen zuordnen.
Sie können SSML verwenden, um eigene Lexika zu definieren oder zu verschiedenen Sprechstilen zu wechseln. Mit den mehrsprachigen Stimmen können Sie auch die gesprochenen Sprachen über SSML anpassen. Informationen zum Verbessern der Sprachausgabe für Ihr Szenario finden Sie unter Verbessern der Synthese mit Speech Synthesis Markup Language und Sprachsynthese mit dem Tool für die Audioinhaltserstellung.
Viseme: Viseme (Mundbilder) sind die wichtigsten Gesichtsausdrücke beim Sprechen und umfassen u. a. die Position der Lippen, des Kiefers und der Zunge beim Erzeugen eines bestimmten Phonems. Viseme sind stark mit Stimmen und Phonemen korreliert.
Mithilfe von Visemereignissen im Speech SDK können Sie Gesichtsanimationsdaten generieren. Mit diesen Daten lassen sich Gesichter für die Kommunikation durch Lippenlesen, für Unterricht, Unterhaltung oder Kundendienst animieren. Viseme werden derzeit nur für die neuronalen Stimmen vom Typ
en-US(amerikanisches Englisch) unterstützt.
Hinweis
Zusätzlich zu neuronalen (nicht HD)-Stimmen von Azure KI Speech können Sie auch Azure KI Speech High Definition (HD)-Stimmen und neurale Azure OpenAI-Stimmen (HD- und Nicht-HD)-Stimmen verwenden. Die HD-Stimmen bieten eine höhere Qualität für vielseitigere Szenarien.
Einige Stimmen unterstützen nicht alle SSML-Tags (Speech Synthesis Markup Language). Dazu gehören neuronale Sprachsynthese für HD-Stimmen, persönliche Stimmen und eingebettete Stimmen.
- Überprüfen Sie für HD-Stimmen (High Definition) von Azure KI Speech die SSML-Unterstützung hier.
- Für persönliche Stimme finden Sie die SSML-Unterstützung hier.
- Überprüfen Sie für eingebettete Stimmen die SSML-Unterstützung hier.
Erste Schritte
Verwenden Sie die Schnellstartanleitung, um mit der Sprachsynthese loszulegen. Die Sprachsynthese ist über das Speech SDK, die REST-API und die Speech CLI verfügbar.
Tipp
Zum Konvertieren von Text in Sprache ohne Programmieren testen Sie das Audioinhaltserstellungs-Tool in Speech Studio.
Beispielcode
Beispielcode für Text-zu-Sprache finden Sie auf GitHub. Diese Beispiele umfassen die Text-zu-Sprache-Konvertierung in den gängigsten Programmiersprachen:
Benutzerdefinierte neuronale Stimme
Zusätzlich zu den vordefinierten neuronalen Stimmen können Sie auch benutzerdefinierte neuronale Stimmen erstellen, die für Ihr Produkt oder Ihre Marke einzigartig sind. Für den Einstieg benötigen Sie lediglich einige Audiodateien und die dazugehörigen Transkriptionen. Weitere Informationen finden Sie unter Erste Schritte mit „Benutzerdefinierte neuronale Stimme“.
Preishinweis
Abrechenbare Zeichen
Wenn Sie das Sprachsynthesefeature verwenden, wird Ihnen jedes in Sprache umgewandelte Zeichen in Rechnung gestellt, auch Satzzeichen. Obwohl das SSML-Dokument selbst nicht abrechenbar ist, werden optionale Elemente, wie Phoneme und Tonhöhe, mit denen angepasst wird, wie der Text in Sprache umgewandelt wird, als abrechenbare Zeichen gezählt. Folgendes wird abgerechnet:
- Text, der dem Sprachsynthesefeature im SSML-Text der Anforderung übergeben wird
- Alle Markups im Textfeld des Anforderungstexts im SSML-Format, mit Ausnahme von
<speak>- und<voice>-Tags - Buchstaben, Satzzeichen, Leerzeichen, Tabulatoren, Markups und alle sonstigen Leerzeichen
- Jeder in Unicode definierte Codepunkt
Ausführliche Informationen finden Sie unter Sprachdienste – Preise.
Wichtig
Jedes chinesische Zeichen wird bei der Abrechnung als zwei Zeichen gezählt, einschließlich der japanischen Kanji, der koreanischen Hanja oder der in anderen Sprachen verwendeten Hanzi.
Modellieren der Trainings- und Hostingzeit für benutzerdefinierte neuronale Stimme
Sowohl Training als auch Hosting der benutzerdefinierten neuronalen Stimme werden in Stunden berechnet und pro Sekunde abgerechnet. Informationen zum Preis der Abrechnungseinheiten finden Sie unter Speech-Dienst – Preise.
Die Trainingszeit für „Benutzerdefinierte neuronale Stimme“ (Custom Neural Voice, CNV) wird nach „Computestunde“ (einer Einheit zum Messen der Computerlaufzeit) gemessen. Beim Trainieren eines Sprachmodells werden in der Regel zwei Rechenaufgaben parallel ausgeführt. Die berechneten Computestunden sind daher länger als die tatsächliche Trainingszeit. Im Durchschnitt ist für das Training einer CNV Lite-Stimme weniger als eine Computestunde erforderlich. Bei CNV Pro dauert es in der Regel 20 bis 40 Computestunden, um eine Stimme mit einem Sprechstil zu trainieren, und etwa 90 Computestunden, um eine Stimme mit mehreren Stilen zu trainieren. Die CNV-Trainingszeit wird mit einer Obergrenze von 96 Computestunden abgerechnet. Wenn ein Sprachmodell über 98 Computestunden trainiert wird, werden Ihnen also nur 96 Computestunden in Rechnung gestellt.
Das Hosten von CNV-Endpunkten (Benutzerdefinierte neuronale Stimme) wird auf der Grundlage der tatsächlichen Zeit (Stunde) gemessen. Die Hostingzeit (Stunden) für jeden Endpunkt wird täglich für die vorherigen 24 Stunden um 00:00 UTC berechnet. Wenn der Endpunkt beispielsweise am ersten Tag 24 Stunden aktiv war, werden für ihn am zweiten Tag um 00:00 Uhr UTC 24 Stunden in Rechnung gestellt. Wenn der Endpunkt neu erstellt oder während des Tages angehalten wurde, wird für ihn am zweiten Tag die akkumulierte Laufzeit bis 00:00 UTC in Rechnung gestellt. Wenn der Endpunkt derzeit nicht gehostet wird, wird er nicht in Rechnung gestellt. Zusätzlich zur täglichen Berechnung um 00:00 UTC wird auch sofort eine Abrechnung ausgelöst, wenn ein Endpunkt gelöscht oder angehalten wird. Beispielsweise wird für einen Endpunkt, der am 1. Dezember um 08:00 Uhr UTC erstellt wurde, die Hostingstunde um 00:00 Uhr UTC am 2. Dezember mit 16 Stunden und um 00:00 Uhr UTC am 3. Dezember mit 24 Stunden berechnet. Wenn der Benutzer das Hosten des Endpunkts am 3. Dezember um 16:30 Uhr UTC abbricht, wird für die Abrechnung die Dauer (16,5 Stunden) von 00:00 bis 16:30 Uhr UTC am 3. Dezember berechnet.
Persönliche Stimme
Wenn Sie das Feature „Personalisierte Stimme“ verwenden, werden Ihnen sowohl die Speicherung des Profils als auch die Synthese in Rechnung gestellt.
- Profilspeicher: Nachdem ein personalisiertes Stimmenprofil erstellt wurde, wird es in Rechnung gestellt, bis es aus dem System entfernt wird. Die Abrechnungseinheit ist pro Stimme pro Tag. Wenn der Sprachdatenspeicher weniger als 24 Stunden genutzt wird, wird dennoch ein ganzer Tag berechnet.
- Synthese: Pro Zeichen abgerechnet. Einzelheiten zu den abrechenbaren Zeichen finden Sie unter den oben genannten abrechenbaren Zeichen.
Sprachsynthese-Avatar
Bei Verwendung des Avatar-Features mit Text-zu-Sprache werden Gebühren basierend auf der Länge der Videoausgabe pro Sekunde abgerechnet. Für den Echtzeitavatar werden die Gebühren jedoch pro Sekunde auf der Grundlage der Zeit berechnet, in der der Avatar aktiv ist, unabhängig davon, ob er spricht oder schweigt. Informationen zur Optimierung der Kosten für die Nutzung von Echtzeitavataren finden Sie im Chatbeispielcode für Avatare in den Tipps unter „Lokales Video für Leerlauf verwenden“.
Die Zeit für das Training von benutzerdefinierten Text-zu-Sprache-Avataren wird nach „Computestunde“ (Computerlaufzeit) gemessen und pro Sekunde abgerechnet. Die Trainingsdauer hängt von der Menge der verwendeten Daten ab. Das Trainieren eines benutzerdefinierten Avatars dauert normalerweise 20–40 Computestunden. Die Trainingszeit des Avatars wird mit einer Obergrenze von 96 Computestunden abgerechnet. Wenn ein Avatarmodell über 98 Computestunden trainiert wird, werden Ihnen also nur 96 Computestunden in Rechnung gestellt.
Avatarhosting wird pro Sekunde pro Endpunkt abgerechnet. Sie können Ihren Endpunkt aussetzen, um Kosten zu sparen. Wenn Sie Ihren Endpunkt anhalten möchten, können Sie ihn direkt löschen. Um ihn erneut zu verwenden, stellen Sie den Endpunkt erneut bereit.
Überwachen von Azure-Sprachsynthesemetriken
Die Überwachung wichtiger Metriken im Zusammenhang mit Sprachsynthesediensten ist für die Verwaltung der Ressourcennutzung und die Kostenkontrolle von entscheidender Bedeutung. In diesem Abschnitt erfahren Sie, wie Sie Nutzungsinformationen im Azure-Portal finden und detaillierte Definitionen der wichtigsten Metriken bereitstellen. Weitere Informationen zu Azure Monitor-Metriken finden Sie unter Überblick über Metriken in Azure Monitor.
So finden Sie Nutzungsinformationen im Azure-Portal
Damit Sie Ihre Azure-Ressourcen effektiv verwalten können, ist es wichtig, regelmäßig auf Nutzungsinformationen zuzugreifen und diese zu überprüfen. So finden Sie die Nutzungsinformationen:
Wechseln Sie zum Azure-Portal, und melden Sie sich mit Ihrem Azure-Konto an.
Navigieren Sie zu Ressourcen, und wählen Sie die Ressource aus, die Sie überwachen möchten.
Wählen Sie im linken Menü unter Überwachung die Option Metriken aus.
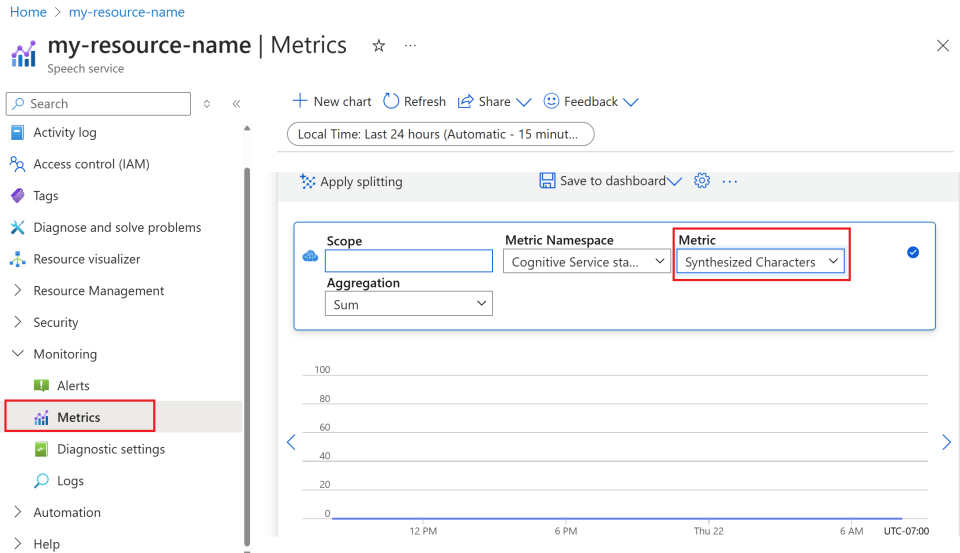
Passen Sie die Metrikansichten an.
Sie können Daten nach Ressourcentyp, Metriktyp, Zeitraum und anderen Parametern filtern, um benutzerdefinierte Ansichten zu erstellen, die ihren Überwachungsanforderungen entsprechen. Darüber hinaus können Sie die Metrikansicht in Dashboards speichern, indem Sie In Dashboard speichern auswählen, um einfachen Zugriff auf häufig verwendete Metriken zu erhalten.
Einrichten von Warnungen.
Um die Nutzung effektiver zu verwalten, richten Sie Warnungen ein, indem Sie im linken Menü unter Überwachung zur Registerkarte Warnungen navigieren. Sie können sich durch Warnungen benachrichtigen lassen, wenn Ihre Nutzung bestimmte Schwellenwerte erreicht, um unerwartete Kosten zu vermeiden.
Definition von Metriken
In der nachfolgenden Tabelle sind die wichtigsten Metriken für die Azure-Sprachsynthese zusammengefasst.
| Metrikname | Beschreibung |
|---|---|
| Synthetisierte Zeichen | Verfolgt die Anzahl der in Sprache konvertierten Zeichen, einschließlich vordefinierter neuraler Stimme und benutzerdefinierter neuraler Stimme. Einzelheiten zu den abrechenbaren Zeichen finden Sie unter Abrechenbare Zeichen. |
| Synthetisierte Videosekunden | Misst die Gesamtdauer des synthetisierten Videomaterials, einschließlich Batch-Avatarsynthese, Echtzeit-Avatarsynthese und benutzerdefinierte Avatarsynthese. |
| Hostingsekunden des Avatarmodells | Verfasst die Gesamtzeit in Sekunden, die Ihr benutzerdefiniertes Avatarmodell gehostet wird. |
| Hostingstunden des Stimmmodells | Erfasst die Gesamtzeit in Stunden, in denen Ihr benutzerdefiniertes neurales VoIP-Modell gehostet wird. |
| Trainingsminuten des Stimmmodells | Misst die Gesamtzeit in Minuten, die zum Trainieren Ihres benutzerdefinierten neuralen Sprachmodells aufgewendet wurde. |
Referenz
Verantwortungsvolle KI
Zu einem KI-System gehört nicht nur die Technologie, sondern auch die Personen, die das System verwenden, sowie die davon betroffenen Personen und die Umgebung, in der es bereitgestellt wird. Lesen Sie die Transparenzhinweise, um mehr über die verantwortungsvolle Nutzung und den Einsatz von KI in Ihren Systemen zu erfahren.
- Transparenzhinweis und Anwendungsfälle für die benutzerdefinierte neuronale Stimme
- Merkmale und Einschränkungen bei der Verwendung der benutzerdefinierten neuronalen Stimme
- Eingeschränkter Zugriff auf die benutzerdefinierte neuronale Stimme
- Richtlinien für die verantwortungsvolle Bereitstellung von Technologien mit künstlicher Sprache
- Offenlegung für Sprecher
- Entwurfsrichtlinien für die Offenlegung
- Entwurfsmuster für die Offenlegung
- Verhaltensregeln für Sprachsynthese-Integrationen
- Daten, Datenschutz und Sicherheit für die benutzerdefinierte neuronale Stimme