Benutzerdefinierter Translator für Einsteiger
Mit dem benutzerdefinierten Translator können Sie ein Übersetzungssystem erstellen, das Ihre geschäfts-, branchen- und domänenspezifische Terminologie und Ihren spezifischen Stil widerspiegelt. Das Trainieren und Bereitstellen eines benutzerdefinierten Systems ist einfach und erfordert keine Programmierkenntnisse. Das angepasste Übersetzungssystem lässt sich nahtlos in Ihre vorhandenen Anwendungen, Workflows und Websites integrieren und ist in Azure über denselben cloudbasierten Textübersetzungs-API-Dienst von Microsoft verfügbar, der jeden Tag Milliarden von Übersetzungen ermöglicht.
Die Plattform ermöglicht Benutzern das Erstellen und Veröffentlichen benutzerdefinierter Systeme für die Übersetzung ins Englische und aus dem Englischen. Der benutzerdefinierte Translator unterstützt mehr als 60 Sprachen, die direkt den für neuronale maschinelle Übersetzung (NMT) verfügbaren Sprachen zugeordnet sind. Eine vollständige Liste finden Sie unter Sprachunterstützung für Translator.
Ist ein benutzerdefiniertes Übersetzungsmodell die richtige Wahl für mich?
Ein gut trainiertes benutzerdefiniertes Übersetzungsmodell bietet präzisere fachgebietsspezifische Übersetzungen, da es auf zuvor übersetzte Dokumente aus dem Fachgebiet zurückgreift, um bevorzugte Übersetzungen zu erlernen. Translator verwendet diese Begriffe und Ausdrücke im Kontext, um unter Berücksichtigung der kontextabhängigen Grammatik flüssige Übersetzungen in der Zielsprache zu erzeugen.
Das Trainieren eines vollständigen benutzerdefinierten Übersetzungsmodells erfordert eine beträchtliche Datenmenge. Wenn Sie nicht über mindestens 10.000 Sätze von zuvor trainierten Dokumenten verfügen, können Sie kein Übersetzungsmodell mit vollständiger Sprachunterstützung trainieren. Sie können jedoch entweder ein Modell trainieren, das ausschließlich auf Wörterbuchdaten basiert, oder die qualitativ hochwertigen, vordefinierten Übersetzungen verwenden, die mit der Textübersetzungs-API bereitgestellt werden.
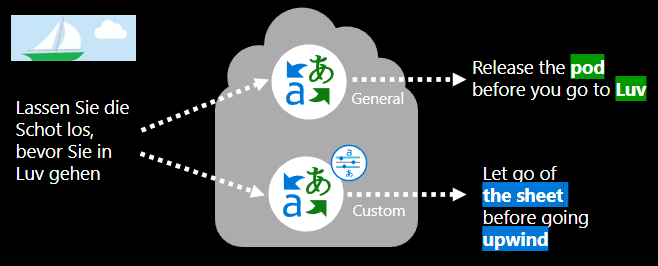
Was beinhaltet das Trainieren eines benutzerdefinierten Übersetzungsmodells?
Zum Erstellen eines benutzerdefinierten Übersetzungsmodells ist Folgendes erforderlich:
Verstehen des Anwendungsfalls
Beschaffen domänenbezogener übersetzter Daten (vorzugsweise von Menschen übersetzt)
Bewertung von Übersetzungsqualität oder Zielsprachenübersetzungen
Wie bewerte ich meinen Anwendungsfall?
Der erste Schritt zur Beschaffung geeigneter Trainingsdaten besteht darin, sich Klarheit über den Anwendungsfall und die Erfolgsaussichten zu verschaffen. Beachten Sie dabei Folgendes:
Ist Ihr gewünschtes Ergebnis angegeben, und wie wird es gemessen?
Ist Ihre Geschäftsdomäne identifiziert?
Verfügen Sie über domänenbezogene Sätze mit ähnlicher Terminologie und ähnlichem Stil?
Umfasst Ihr Anwendungsfall mehrere Domänen? Wenn ja, sollten Sie ein Übersetzungssystem oder mehrere Systeme erstellen?
Haben Sie Anforderungen, die sich auf die regionale Datenresidenz im Ruhezustand und während der Übertragung auswirken?
Befinden sich die Zielbenutzer in einer oder mehreren Regionen?
Aus welcher Quelle sollte ich meine Daten beziehen?
Das Suchen domänenbezogener Qualitätsdaten ist häufig eine schwierige Aufgabe, die je nach Benutzerklassifizierung variiert. Im Folgenden finden Sie einige Fragen, die Sie sich stellen können, um zu überlegen, welche Daten Ihnen möglicherweise zur Verfügung stehen:
Sind in Ihrem Unternehmen frühere Übersetzungsdaten verfügbar, die Sie verwenden können? Unternehmen verfügen häufig über eine Vielzahl von Übersetzungsdaten, die sich über viele Jahre durch menschliche Übersetzung angesammelt haben.
Verfügen Sie über eine große Menge an einsprachigen Daten? Einsprachige Daten sind Daten in nur einer Sprache. Wenn ja, können Sie Übersetzungen für diese Daten anfordern?
Können Sie Onlineportale durchforsten, um Sätze in der Quellsprache zu sammeln und Sätze in der Zielsprache zu synthetisieren?
Was sollte ich als Trainingsmaterial verwenden?
| `Source` | Funktionsbeschreibung | Zu befolgende Regeln |
|---|---|---|
| Zweisprachige Trainingsdokumente | Vermittelt dem System Ihre Terminologie und Ihren Stil | Seien Sie aufgeschlossen. Jede domänenbezogene menschliche Übersetzung ist besser als die maschinelle Übersetzung. Fügen Sie Dokumente hinzu, und entfernen Sie sie, und versuchen Sie, die BLEU-Bewertung zu verbessern. |
| Optimieren von Dokumenten | Trainiert die Parameter der neuronalen maschinellen Übersetzung | Seien Sie streng. Ordnen Sie die Parameter so an, dass sie Ihre Übersetzungen in der Zukunft optimal abbilden. |
| Testen von Dokumenten | Berechnen der BLEU-Bewertung | Seien Sie streng. Ordnen Sie die Testdokumente so an, dass sie Ihre Übersetzung in der Zukunft optimal abbilden. |
| Ausdruckswörterbuch | Erzwingt die angegebene Übersetzung in 100 % der Fälle | Seien Sie restriktiv. Bei einem Ausdruckswörterbuch wird die Groß-/Kleinschreibung beachtet, und alle aufgelisteten Wörter oder Ausdrücke werden auf die von Ihnen angegebene Weise übersetzt. In vielen Fällen ist es besser, kein Ausdruckswörterbuch zu verwenden und das System lernen zu lassen. |
| Satzwörterbuch | Erzwingt die angegebene Übersetzung in 100 % der Fälle | Seien Sie streng. Bei einem Wörterbuch mit ganzen Sätze wird die Groß-/Kleinschreibung nicht beachtet, und es eignet sich gut für allgemeine Sätze in der Domäne. Damit eine Übereinstimmung im Satzwörterbuch gefunden wird, muss der gesamte übermittelte Satz dem Wörterbucheintrag in der Ausgangssprache entsprechen. Wenn die Übereinstimmung nur für einen Teil des Satzes gilt, stimmt der Eintrag nicht überein. |
Was ist eine BLEU-Bewertung?
BLEU (Bilingual Evaluation Understudy) ist ein Algorithmus zur Bewertung der Genauigkeit von Text, der maschinell von einer Sprache in eine andere übersetzt wurde. Der benutzerdefinierte Translator verwendet die BLEU-Metrik als eine Möglichkeit, die Übersetzungsgenauigkeit darzustellen.
Eine BLEU-Bewertung ist eine Zahl zwischen 0 und 100. Eine Bewertung von 0 (null) gibt eine Übersetzung von geringer Qualität an, bei der nichts in der Übersetzung mit der Referenz übereinstimmt. Eine Bewertung von 100 gibt eine perfekte Übersetzung an, die mit der Referenz identisch ist. Es ist nicht erforderlich, eine Bewertung von 100 zu erreichen. Eine BLEU-Bewertung zwischen 40 und 60 deutet auf eine qualitativ hochwertige Übersetzung hin.
Was geschieht, wenn ich keine Optimierungs- oder Testdaten bereitstelle?
Optimierungs- und Testsätze sind optimal repräsentativ für das, was Sie in Zukunft übersetzen möchten. Wenn Sie keine Optimierungs- oder Testdaten übermitteln, schließt der benutzerdefinierte Translator automatisch Sätze aus Ihren Trainingsdokumenten aus, die als Optimierungs- und Testdaten verwendet werden sollen.
| Vom System generiert | Manuelle Auswahl |
|---|---|
| Bequem | Ermöglicht eine Feinabstimmung für Ihre zukünftigen Anforderungen |
| Gut, wenn Sie wissen, dass Ihre Trainingsdaten repräsentativ für das sind, was Sie übersetzen möchten | Bietet mehr Freiheit beim Zusammenstellen Ihrer Trainingsdaten |
| Bei einer Vergrößerung oder Verkleinerung der Domäne leicht zu wiederholen | Ermöglicht mehr Daten und eine bessere Domänenabdeckung |
| Ändert sich bei jedem Trainingslauf | Bleibt bei wiederholten Trainingsläufen statisch |
Wie wird Trainingsmaterial vom benutzerdefinierten Translator verarbeitet?
Zur Vorbereitung auf das Training durchlaufen Dokumente eine Reihe von Verarbeitungs- und Filterschritten. Kenntnisse des Filterprozesses können ihnen dabei helfen, die angezeigte Satzanzahl sowie die Schritte zu verstehen, die Sie ausführen können, um Trainingsdokumente für das Training mit dem benutzerdefinierten Translator vorzubereiten. Die Filterschritte lauten wie folgt:
Satzausrichtung
Wenn das Dokument nicht im
XLIFF-,XLSX-,TMX- oderALIGN-Format vorliegt, richtet der benutzerdefinierte Translator die Sätze Ihrer Quell- und Zieldokumente Satz für Satz aneinander aus. Der Translator führt keine Dokumentausrichtung durch. Er folgt Ihrer Benennungskonvention für die Dokumente, um ein passendes Dokument in der anderen Sprache zu finden. Innerhalb des Quelltexts versucht der benutzerdefinierte Translator, den entsprechenden Satz in der Zielsprache zu finden. Er verwendet Dokumentmarkups wie eingebettete HTML-Tags, um die Ausrichtung zu unterstützen.Wenn Sie eine große Abweichung zwischen der Anzahl der Sätze in den Quell- und Zieldokumenten feststellen, ist Ihr Quelldokument möglicherweise nicht parallel oder konnte nicht ausgerichtet werden. Die Dokumentpaare mit einen großen Unterschied (>10%) zwischen den Sätzen auf beiden Seiten sollten erneut überprüft werden, um sicherzustellen, dass sie tatsächlich parallel sind.
Optimieren und Testen der Datenextraktion
Optimierungs- und Testdaten sind optional. Wenn Sie diese nicht bereitstellen, entnimmt das System einen gewissen Prozentsatz aus Ihren Trainingsdokumenten, um diese zum Optimieren und Testen zu verwenden. Diese Entnahme erfolgt dynamisch im Rahmen des Trainingsprozesses. Da dieser Schritt innerhalb des Trainings erfolgt, sind Ihre hochgeladenen Dokumente davon nicht betroffen. Sie können die endgültige Anzahl verwendeter Sätze für jede Datenkategorie (Training, Optimierung, Test und Wörterbuch) nach erfolgreichem Training auf der Seite mit Modelldetails anzeigen.
Längenfilter
- Entfernt Sätze mit nur einem Wort auf jeder Seite.
- Entfernt Sätze mit mehr als 100 Wörtern auf jeder Seite. Chinesisch, Japanisch, Koreanisch sind ausgenommen.
- Entfernt Sätze mit weniger als drei Zeichen. Chinesisch, Japanisch, Koreanisch sind ausgenommen.
- Entfernt Sätze mit mehr als 2,000 Zeichen für Chinesisch, Japanisch und Koreanisch.
- Entfernt Sätze mit weniger als 1 % alphanumerischen Zeichen.
- Entfernt Wörterbucheinträge, die mehr als 50 Wörter enthalten.
Leerzeichen
- Ersetzt eine beliebige Folge von Leerzeichen, einschließlich Tabstopps und CR/LF-Folgen, durch ein einzelnes Leerzeichen.
- Entfernt vorangestellte oder nachfolgende Leerzeichen im Satz.
Interpunktion am Satzende
Ersetzt mehrere Satzendzeichen durch ein einzelnes. Normalisierung von japanischen Zeichen.
Konvertiert Buchstaben und Ziffern normaler Breite in Zeichen halber Breite.
Nicht durch Escapezeichen formatierte XML-Tags
Wandelt Tags ohne Escapezeichen in Tags mit Escapezeichen um:
Tag Wird zu < < > > & & Ungültige Zeichen
Der benutzerdefinierte Translator entfernt Sätze, die das Unicode-Zeichen U+FFFD enthalten. Das Zeichen U+FFFD gibt an, dass eine Codierungskonvertierung fehlgeschlagen ist.
Welche Schritte muss ich vor dem Hochladen von Daten ausführen?
- Entfernen Sie Sätze mit ungültiger Codierung.
- Entfernen Sie Unicode-Steuerzeichen.
- Richten Sie Sätze nach Möglichkeit aus (Quelle an Ziel).
- Entfernen Sie Quell- und Zielsätze, die der Quell- und Zielsprache nicht entsprechen.
- Wenn Quell- und Zielsätze gemischte Sprachen enthalten, stellen Sie sicher, dass nicht übersetzte Wörter beabsichtigt sind, z. B. Namen von Organisationen und Produkten.
- Vermeiden Sie Fehler beim Unterrichten ihres Modells, indem Sie sicherstellen, dass Grammatik und Typografie korrekt sind.
- Weisen Sie einen Quellsatz einem Zielsatz zu. Obwohl unser Trainingsprozess Quell- und Zielzeilen behandelt, die mehrere Sätze enthalten, ist eine 1:1-Zuordnung eine bewährte Methode.
Wie werte ich die Ergebnisse aus?
Nachdem Ihr Modell erfolgreich trainiert wurde, können Sie die BLEU-Bewertung des Modells und die BLEU-Bewertung des Baselinemodells auf der Seite mit den Modelldetails anzeigen. Wir verwenden den gleichen Satz Testdaten, um sowohl die BLEU-Bewertung des Modells als auch die BLEU-Grundbewertung zu erstellen. Diese Daten helfen Ihnen, eine fundierte Entscheidung darüber zu treffen, welches Modell für Ihren Anwendungsfall besser geeignet ist.