Achtung
Dieser Artikel bezieht sich auf CentOS, eine Linux-Distribution mit dem End-of-Life-(EOL-)Status. Sie sollten Ihre Nutzung entsprechend planen. Weitere Informationen finden Sie im CentOS End-of-Life-Leitfaden.
Dieses Beispielszenario zeigt, wie Sie Apache NiFi in Azure ausführen. NiFi stellt ein System zum Verarbeiten und Verteilen von Daten bereit.
Apache®, Apache NiFi® und NiFi® sind entweder eingetragene Marken oder Marken der Apache Software Foundation in den USA und/oder anderen Ländern. Die Verwendung dieser Markierungen impliziert kein Endorsement durch die Apache Software Foundation.
Aufbau

Laden Sie eine Visio-Datei dieser Architektur herunter.
Workflow
Die NiFi-Anwendung wird auf VMs in NiFi-Clusterknoten ausgeführt. Die VMs befinden sich in einer VM-Skalierungsgruppe, die von der Konfiguration über Verfügbarkeitszonen hinweg bereitgestellt werden.
Apache ZooKeeper wird auf VMs in einem separaten Cluster ausgeführt. NiFi verwendet den ZooKeeper-Cluster für folgende Zwecke:
- Zum Auswählen eines Clusterkoordinatorknotens
- Zum Koordinieren des Datenflusses
Azure Application Gateway bietet Layer-7-Lastenausgleich für die Benutzeroberfläche, die auf den NiFi-Knoten ausgeführt wird.
Monitor und das Log Analytics-Feature sammeln und analysieren Telemetriedaten aus dem NiFi-System und reagieren darauf. Zu den Telemetriedaten gehören NiFi-Systemprotokolle und Metriken zur Systemintegrität und -leistung.
Die Zertifikate und Schlüssel für den NiFi-Cluster werden sicher in Azure Key Vault gespeichert.
Microsoft Entra ID ermöglicht einmaliges Anmelden (Single Sign-On, SSO) und Multi-Faktor-Authentifizierung (MFA).
Komponenten
- NiFi stellt ein System zum Verarbeiten und Verteilen von Daten bereit.
- ZooKeeper ist ein Open-Source-Server, der verteilte Systeme verwaltet.
- Microsoft Azure Virtual Machines ist ein IaaS-Angebot (Infrastructure as a Service). Sie können mit Virtual Machines skalierbare Computingressourcen bedarfsorientiert bereitstellen. Virtual Machines bietet die Flexibilität der Virtualisierung, jedoch ohne den Wartungsaufwand für physische Hardware.
- Mit Microsoft Azure Virtual Machine Scale Sets kann eine Gruppe von VMs mit Lastenausgleich erstellt und verwaltet werden. Die Anzahl von VM-Instanzen in einer Gruppe kann automatisch erhöht oder verringert werden, wenn sich der Bedarf ändert, oder es kann ein Zeitplan festgelegt werden.
- Verfügbarkeitszonen sind eindeutige physische Standorte in einer Azure-Region. Diese Hochverfügbarkeitsangebote schützen Anwendungen und Daten vor Ausfällen von Rechenzentren.
- Application Gateway ist ein Lastenausgleichsmodul, das den an Webanwendungen fließenden Datenverkehr verwaltet.
- Monitor erfasst und analysiert Daten zu Umgebungen und Azure-Ressourcen. Diese Daten umfassen App-Telemetriedaten, z. B. Leistungsmetriken und Aktivitätsprotokolle. Weitere Informationen finden Sie unter Aspekte der Überwachung weiter unten in diesem Artikel.
- Log Analytics ist ein Tool im Azure-Portal zum Ausführen von Abfragen für Monitor-Protokolldaten. Darüber hinaus bietet Log Analytics Features zum Erstellen von Diagrammen sowie für statistische Analysen von Abfrageergebnissen.
- Azure DevOps Services bietet Dienste, Tools und Umgebungen zum Verwalten von Codierungsprojekten und Bereitstellungen.
- Mit Key Vault werden Geheimnisse eines Systems – z. B. API-Schlüssel, Kennwörter, Zertifikate und kryptografische Schlüssel – sicher gespeichert und der Zugriff darauf gesteuert.
- Microsoft Entra ID ist ein cloudbasierter Identitätsdienst, der den Zugriff auf Azure und andere Cloud-Apps steuert.
Alternativen
- Azure Data Factory stellt eine Alternative zu dieser Lösung dar.
- Anstelle von Key Vault können Sie auch einen vergleichbaren Dienst zum Speichern von Systemgeheimnissen verwenden.
- Apache Airflow. Informationen zu den Unterschieden zwischen Airflow und NiFi finden Sie hier.
- Es ist möglich, eine unterstützte NiFi-Alternative für Unternehmen wie Cloudera Apache NiFi zu verwenden. Das Cloudera-Angebot ist über den Azure Marketplace verfügbar.
Szenariodetails
In diesem Szenario wird NiFi in einer Clusterkonfiguration auf Azure-VMs in einer Skalierungsgruppe ausgeführt. Die meisten Empfehlungen in diesem Artikel gelten jedoch auch für Szenarien, in denen NiFi im Einzelinstanzmodus auf einer einzelnen VM (virtueller Computer) ausgeführt wird. Die bewährten Methoden in diesem Artikel veranschaulichen eine skalierbare, hochverfügbare und sichere Bereitstellung.
Mögliche Anwendungsfälle
NiFi eignet sich gut für das Verschieben von Daten und das Verwalten von Datenflüssen:
- Verbinden entkoppelter Systeme in der Cloud
- Verschieben von Daten in und aus Azure Storage und anderen Datenspeichern
- Integrieren von Edge-to-Cloud- und Hybrid Cloud-Anwendungen in Azure IoT, Azure Stack und Azure Kubernetes Service (AKS)
Aus diesen Gründen eignet sich diese Lösung für viele Bereiche:
In modernen Data Warehouses (MDWs) werden strukturierte und unstrukturierte Daten im großen Stil zusammengeführt. Dort werden Daten aus verschiedenen Quellen, Senken und Formaten gesammelt und gespeichert. NiFi zeichnet sich aus folgenden Gründen beim Erfassen von Daten in Azure-basierten MDWs aus:
- Über 200 Prozessoren stehen zum Lesen, Schreiben und Bearbeiten von Daten zur Verfügung.
- Das System unterstützt Storage-Dienste wie Azure Blob Storage, Azure Data Lake Storage, Azure Event Hubs, Azure Queue Storage, Azure Cosmos DB und Azure Synapse Analytics.
- Stabile Datengovernancefunktionen ermöglichen die Implementierung konformer Lösungen. Weitere Informationen zum Erfassen der Datenherkunft im Log Analytics-Feature von Azure Monitor finden Sie unter Überlegungen zur Berichterstellung weiter unten in diesem Artikel.
NiFi kann eigenständig auf Geräten mit geringem Speicherbedarf ausgeführt werden. In solchen Fällen ermöglicht NiFi die Verarbeitung von Edgedaten und das Verschieben dieser Daten in größere NiFi-Instanzen oder -Cluster in der Cloud. NiFi unterstützt Sie beim Filtern, Transformieren und Priorisieren von Edgedaten während der Übertragung und sorgt damit für zuverlässige und effiziente Datenflüsse.
IIoT-Lösungen (Industrial IoT) verwalten den Datenfluss vom Edge zum Rechenzentrum. Dieser Fluss beginnt mit der Datenerfassung von industriellen Steuerungssystemen und -geräten. Die Daten werden dann in Datenverwaltungslösungen und MDWs verschoben. NiFi bietet Funktionen, die sich gut für die Datenerfassung und -verschiebung eignen:
- Verarbeitungsfunktionen für Edgedaten
- Unterstützung für Protokolle, die von IoT-Gateways und -Geräten verwendet werden
- Integration in Event Hubs- und Storage-Dienste
IoT-Anwendungen in den Bereichen Predictive Maintenance und Supply Chain Management können diese Funktionalität nutzen.
Empfehlungen
Beachten Sie Folgendes, wenn Sie diese Lösung verwenden:
Empfohlene Versionen von NiFi
Wenn Sie diese Lösung in Azure ausführen, wird empfohlen, mindestens Version 1.13.2 von NiFi zu verwenden. Sie können andere Versionen ausführen, die aber möglicherweise andere Konfigurationen als die in diesem Leitfaden erfordern.
Um NiFi auf Azure-VMs zu installieren, ist es am besten, die Binärdateien von der NiFi-Downloadseite herunterzuladen. Sie können die Binärdateien auch aus dem Quellcode erstellen.
Empfohlene Versionen von ZooKeeper
Für diese Beispielworkload wird die Verwendung der Version 3.5.5 oder höher oder von Version 3.6.x von ZooKeeper empfohlen.
Sie können ZooKeeper mithilfe der offiziellen Binärdateien oder über den Quellcode auf Azure-VMs installieren. Beide sind auf der Seite mit den Apache ZooKeeper-Releases verfügbar.
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Informationen zum Konfigurieren von NiFi finden Sie im Apache NiFi-Systemadministratorhandbuch. Beachten Sie auch die folgenden Überlegungen, wenn Sie diese Lösung implementieren.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
- Verwenden Sie den Azure-Preisrechner, um die Kosten für die Ressourcen in dieser Architektur abschätzen zu können.
- Eine Schätzung, die alle Dienste in dieser Architektur mit Ausnahme der benutzerdefinierten Warnungslösung enthält, finden Sie in diesem Beispielkostenprofil.
VM-Aspekte
In den folgenden Abschnitten wird ausführlich beschrieben, wie Sie die NiFi-VMs konfigurieren:
Größe des virtuellen Computers
In dieser Tabelle sind die empfohlenen VM-Größen für den Einstieg aufgeführt. Für die meisten allgemeinen Datenflüsse ist Standard_D16s_v3 am besten geeignet. Aber jeder Datenfluss in NiFi weist unterschiedliche Anforderungen auf. Testen Sie Ihren Fluss, und ändern Sie die Größe ggf. basierend auf den tatsächlichen Anforderungen.
Ziehen Sie auf den beschleunigten Netzwerkbetrieb auf den VMs in Betracht, um die Netzwerkleistung zu erhöhen. Weitere Informationen finden Sie unter Netzwerk für Azure-VM-Skalierungsgruppen.
| Größe des virtuellen Computers | vCPU | Arbeitsspeicher in GB | Maximaler Datenträgerdurchsatz ohne Cache bei E/A-Vorgängen pro Sekunde (IOPS) pro MBit/s* | Max. Netzwerkschnittstellen (NICs)/erwartete Netzwerkbandbreite (MBit/s) |
|---|---|---|---|---|
| Standard_D8s_v3 | 8 | 32 | 12.800/192 | 4/4.000 |
| Standard_D16s_v3** | 16 | 64 | 25.600/384 | 8/8.000 |
| Standard_D32s_v3 | 32 | 128 | 51.200/768 | 8/16.000 |
| Standard_M16m | 16 | 437,5 | 10.000/250 | 8/4.000 |
* Deaktivieren Sie die Zwischenspeicherung von Schreibzugriffen für alle Datenträger, die Sie auf NiFi-Knoten verwenden.
** Diese SKU wird für die meisten allgemeinen Datenflüsse empfohlen. Azure-VM-SKUs mit ähnlichen vCPU- und Arbeitsspeicherkonfigurationen sollten ebenfalls geeignet sein.
VM-Betriebssystem
Es wird empfohlen, NiFi in Azure unter einem der folgenden Gastbetriebssysteme zu verwenden:
- Ubuntu 18.04 LTS oder neuer
- CentOS 7.9
Um die spezifischen Anforderungen Ihres Datenflusses zu erfüllen, müssen mehrere Einstellungen auf Betriebssystemebene angepasst werden:
- Maximale Anzahl geforkter Prozesse
- Maximale Anzahl von Dateihandles
- Zugriffszeit (
atime)
Nachdem Sie das Betriebssystem an Ihren erwarteten Anwendungsfall angepasst haben, verwenden Sie Azure VM Image Builder, um die Generierung dieser optimierten Images zu codieren. Einen spezifischen Leitfaden für NiFi finden Sie im Apache NiFi-Systemadministratorhandbuch unter den bewährten Methoden für die Konfiguration.
Storage
Drei wichtige Gründe sprechen dafür, die verschiedenen NiFi-Repositorys auf Datenträgern und nicht auf dem Betriebssystemdatenträger zu speichern:
- Datenflüsse haben häufig hohe Anforderungen an den Datenträgerdurchsatz, die ein einzelner Datenträger nicht erfüllen kann.
- Es hat sich bewährt, die NiFi-Datenträgervorgänge von den Vorgängen auf dem Betriebssystemdatenträger zu trennen.
- Die Repositorys sollten sich nicht in temporärem Speicher gespeichert werden.
In den folgenden Abschnitten finden Sie Leitfäden zum Konfigurieren der Datenträger. Diese Leitfäden gelten speziell für Azure. Weitere Informationen zum Konfigurieren der Repositorys finden Sie im Apache NiFi-Systemadministratorhandbuch unter dem Thema Zustandsverwaltung.
Datenträgertyp und -größe
Berücksichtigen Sie folgende Faktoren beim Konfigurieren der Datenträger für NiFi:
- Datenträgertyp
- Datenträgergröße
- Gesamtzahl von Datenträgern
Hinweis
Aktuelle Informationen zu Datenträgertypen, -größen und -preisen finden Sie unter Einführung in verwaltete Azure-Datenträger.
Die folgende Tabelle zeigt die Typen von verwalteten Datenträgern, die derzeit in Azure verfügbar sind. Sie können NiFi mit jedem dieser Datenträgertypen verwenden. Für Datenflüsse mit hohem Durchsatz wird jedoch empfohlen, SSD Premium zu verwenden.
| Disk Ultra (NVM Express (NVMe)) | SSD Premium | SSD Standard | HDD Standard | |
|---|---|---|---|---|
| Datenträgertyp | SSD | SSD | SSD | Festplattenlaufwerk |
| Maximale Datenträgergröße | 65.536 GB | 32.767 GB | 32.767 GB | 32.767 GB |
| Max. Durchsatz | 2000 MiB/s | 900 MiB/s | 750 MiB/s | 500 MiB/s |
| Max. IOPS | 160.000 | 20.000 | 6\.000 | 2\.000 |
Verwenden Sie mindestens drei Datenträger, um den Durchsatz des Datenflusses zu erhöhen. Bewährte Methoden zum Konfigurieren der Repositorys auf den Datenträgern finden Sie weiter unten in diesem Artikel unter Repositorykonfiguration.
In der folgenden Tabelle sind die relevanten Größen und Durchsätze für die einzelnen Datenträgergrößen und -typen aufgeführt.
| HDD Standard S15 | HDD Standard S20 | HDD Standard S30 | SSD Standard S15 | SSD Standard S20 | SSD Standard S30 | SSD Premium P15 | SSD Premium P20 | SSD Premium P30 | |
|---|---|---|---|---|---|---|---|---|---|
| Festplattengröße in GB | 256 | 512 | 1\.024 | 256 | 512 | 1\.024 | 256 | 512 | 1\.024 |
| IOPS pro Datenträger | Bis zu 500 | Bis zu 500 | Bis zu 500 | Bis zu 500 | Bis zu 500 | Bis zu 500 | 1\.100 | 2\.300 | 5\.000 |
| Durchsatz pro Datenträger | Bis zu 60 MBit/s | Bis zu 60 MBit/s | Bis zu 60 MBit/s | Bis zu 60 MBit/s | Bis zu 60 MBit/s | Bis zu 60 MBit/s | 125 MBit/s | 150 MBit/s | 200 MBit/s |
Wenn Ihr System die VM-Grenzwerte erreicht, kann das Hinzufügen zusätzlicher Datenträger den Durchsatz möglicherweise nicht erhöhen:
- Die Grenzwerte für IOPS und Durchsatz hängen von der Größe des Datenträgers ab.
- Die ausgewählte VM-Größe bestimmt die Grenzwerte für IOPS und Durchsatz für die VM auf allen Datenträgern.
Weitere Informationen zu den Grenzwerten für den Datenträgerdurchsatz auf VM-Ebene finden Sie unter Größen für virtuelle Computer in Azure.
Datenträgercaching auf VMs
Auf Azure-VMs verwaltet das Feature für die Hostzwischenspeicherung das Zwischenspeichern von Schreibvorgängen auf den Datenträgern. Um den Durchsatz von Datenträgern zu erhöhen, die Sie für Repositorys verwenden, deaktivieren Sie die Zwischenspeicherung von Schreibvorgängen auf Datenträgern, indem Sie Hostzwischenspeicherung auf None festlegen.
Repositorykonfiguration
Für NiFi gilt die Verwendung separater Datenträger für jedes dieser Repositorys als bewährte Methode:
- Inhalt
- FlowFile
- Herkunft
Für diesen Ansatz sind mindestens drei Datenträger erforderlich.
NiFi unterstützt auch das Striping auf Anwendungsebene. Diese Funktionalität erhöht die Größe oder Leistung der Datenrepositorys.
Der folgende Auszug stammt aus der Konfigurationsdatei nifi.properties. Diese Konfiguration partitioniert und verteilt die Repositorys auf verwaltete Datenträger, die an die VMs angefügt sind:
nifi.provenance.repository.directory.stripe1=/mnt/disk1/ provenance_repository
nifi.provenance.repository.directory.stripe2=/mnt/disk2/ provenance_repository
nifi.provenance.repository.directory.stripe3=/mnt/disk3/ provenance_repository
nifi.content.repository.directory.stripe1=/mnt/disk4/ content_repository
nifi.content.repository.directory.stripe2=/mnt/disk5/ content_repository
nifi.content.repository.directory.stripe3=/mnt/disk6/ content_repository
nifi.flowfile.repository.directory=/mnt/disk7/ flowfile_repository
Weitere Informationen zum Entwerfen für Hochleistungsspeicher finden Sie unter Azure Storage Premium: Entwurf für hohe Leistung.
Berichterstellung
NiFi enthält einen Berichtstask für die Datenherkunft für das Log Analytics-Feature.
Mit diesem Berichtstask können Sie Ereignisse zur Herkunft in einen kostengünstigen, dauerhaften, langfristigen Speicher auslagern. Das Log Analytics-Feature stellt eine Abfrageschnittstelle zum Anzeigen und Erstellen von Graphen für die einzelnen Ereignisse bereit. Weitere Informationen zu diesen Abfragen finden Sie unter Log Analytics-Abfragen weiter unten in diesem Artikel.
Sie können diesen Task auch mit flüchtigem Speicher im Arbeitsspeicher für die Herkunft verwenden. In vielen Szenarien können Sie damit eine Erhöhung des Durchsatzes erzielen. Dieser Ansatz ist jedoch riskant, wenn Sie Ereignisdaten beibehalten müssen. Stellen Sie sicher, dass flüchtiger Speicher Ihre Anforderungen an die Dauerhaftigkeit für Herkunftsereignisse erfüllt. Weitere Informationen finden Sie im Apache NiFi-Systemadministratorhandbuch im Thema zum Herkunftsrepository.
Bevor Sie diesen Prozess verwenden, erstellen Sie einen Log Analytics-Arbeitsbereich in Ihrem Azure-Abonnement. Es ist am besten, den Arbeitsbereich in derselben Region wie Ihre Workload einzurichten.
So konfigurieren Sie den Berichtstask zur Herkunft
- Öffnen Sie die Controllereinstellungen in NiFi.
- Wählen Sie das Menü für Berichtstasks aus.
- Wählen Sie Create a new reporting task (Neuen Berichtstask erstellen) aus.
- Wählen Sie Azure Log Analytics Reporting Task (Azure Log Analytics-Berichtstask) aus.
Der folgende Screenshot zeigt das Eigenschaftenmenü für diesen Berichtstask:
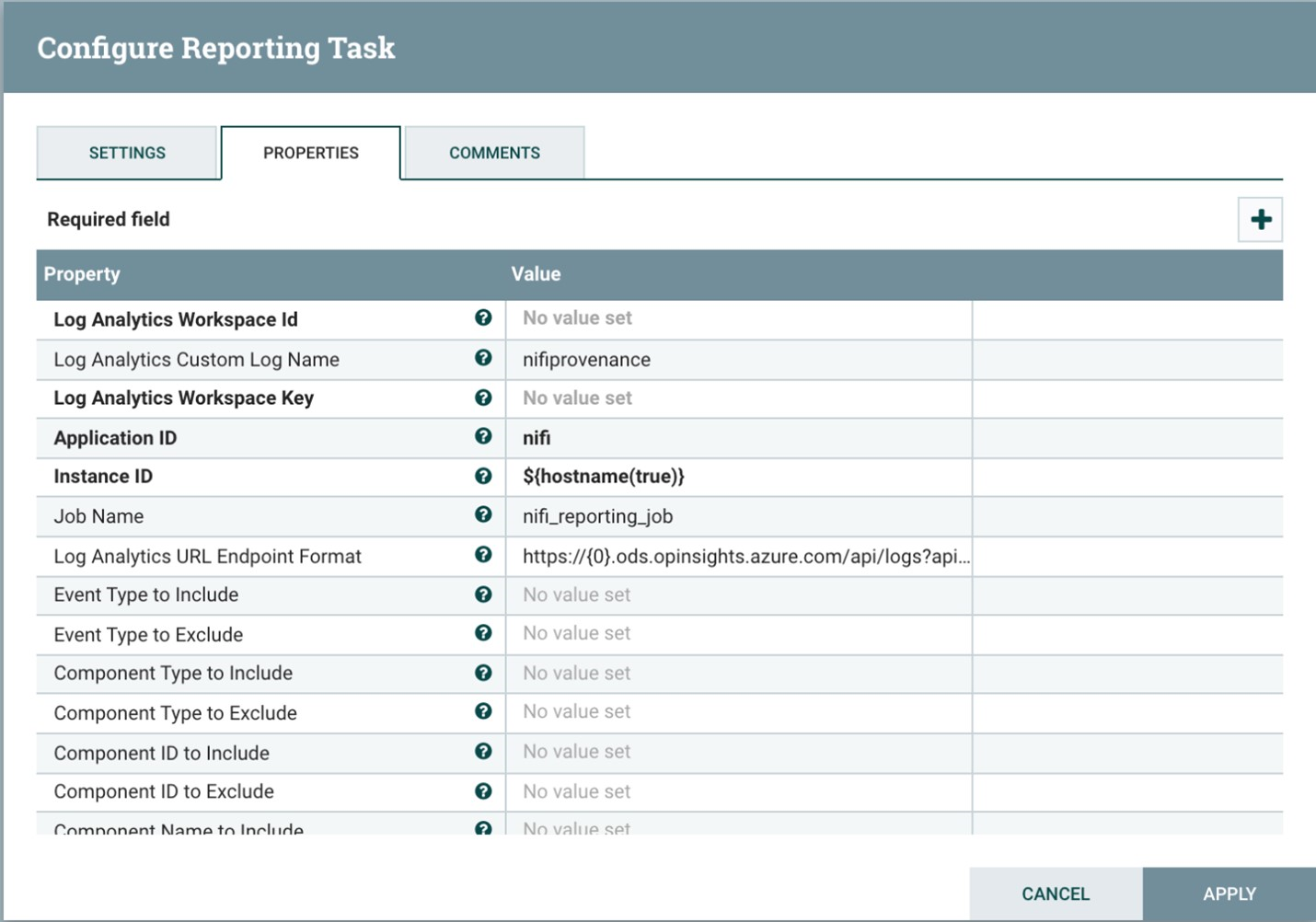
Zwei Eigenschaften sind erforderlich:
- Die ID des Log Analytics-Arbeitsbereichs
- Der Schlüssel des Log Analytics-Arbeitsbereichs
Sie finden diese Werte im Azure-Portal, indem Sie zu Ihrem Log Analytics-Arbeitsbereich navigieren.
Es stehen noch weitere Optionen zum Anpassen und Filtern der vom System gesendeten Herkunftsereignisse zur Verfügung.
Sicherheit
Sicherheit bietet Schutz vor vorsätzlichen Angriffen und dem Missbrauch Ihrer wertvollen Daten und Systeme. Weitere Informationen finden Sie unter Übersicht über die Säule „Sicherheit“.
Sie können NiFi auch hinsichtlich der Authentifizierung und Autorisierung schützen. Außerdem können Sie NiFi für die gesamte Netzwerkkommunikation schützen, einschließlich:
- Innerhalb des Clusters
- Zwischen dem Cluster und ZooKeeper
Anweisungen zum Aktivieren der folgenden Optionen finden Sie im Apache NiFi-Administratorhandbuch:
- Kerberos
- Lightweight Directory Access-Protokoll (LDAP)
- Zertifikatbasierte Authentifizierung und Autorisierung
- Zwei-Wege-SSL (Secure Sockets Layer) für die Clusterkommunikation
Wenn Sie den sicheren ZooKeeper-Clientzugriff aktivieren, konfigurieren Sie NiFi, indem Sie die zugehörige Eigenschaften in der Konfigurationsdatei bootstrap.conf hinzufügen. Die folgenden Konfigurationseinträge zeigen ein Beispiel:
java.arg.18=-Dzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNetty
java.arg.19=-Dzookeeper.client.secure=true
java.arg.20=-Dzookeeper.ssl.keyStore.location=/path/to/keystore.jks
java.arg.21=-Dzookeeper.ssl.keyStore.password=[KEYSTORE PASSWORD]
java.arg.22=-Dzookeeper.ssl.trustStore.location=/path/to/truststore.jks
java.arg.23=-Dzookeeper.ssl.trustStore.password=[TRUSTSTORE PASSWORD]
Allgemeine Empfehlungen finden Sie in der Linux-Sicherheitsbaseline.
Netzwerksicherheit
Beachten Sie beim Implementieren dieser Lösung die folgenden Aspekte der Netzwerksicherheit:
Netzwerksicherheitsgruppen
Sie können in Azure Netzwerksicherheitsgruppen verwenden, um den Netzwerkdatenverkehr zu beschränken.
Für administrative Aufgaben wird eine Jumpbox zum Herstellen einer Verbindung mit dem NiFi-Cluster empfohlen. Verwenden Sie diese sicherheitsgehärteten VM mit Just-In-Time-Zugriff oder Azure Bastion. Richten Sie Netzwerksicherheitsgruppen ein, um den Zugriff auf die Jumpbox oder Azure Bastion zu steuern. Netzwerkisolation und -steuerung erzielen Sie, indem Sie Netzwerksicherheitsgruppen in den verschiedenen Subnetzen der Architektur mit Umsicht verwenden.
Der folgende Screenshot zeigt Komponenten in einem typischen virtuellen Netzwerk. Sie enthält ein gemeinsames Subnetz für die Jumpbox, die VM-Skalierungsgruppe und die ZooKeeper-VMs. In dieser vereinfachten Netzwerktopologie werden die Komponenten in einem Subnetz zusammengefasst. Befolgen Sie die Leitfäden Ihrer Organisation für die Aufgabentrennung und den Netzwerkentwurf.
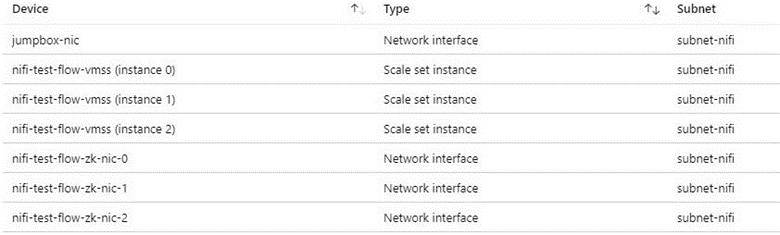
Überlegungen zum ausgehenden Internetzugriff
NiFi in Azure benötigt für die Ausführung keinen Zugriff auf das öffentliche Internet. Wenn der Datenfluss keinen Internetzugriff zum Abrufen von Daten benötigt, steigern Sie die Sicherheit des Clusters, indem Sie die folgenden Schritte befolgen, um den ausgehenden Internetzugriff zu deaktivieren:
Erstellen Sie eine zusätzliche Regel für die Netzwerksicherheitsgruppe im virtuellen Netzwerk.
Verwenden Sie die folgenden Einstellungen:
- Quelle:
Any - Ziel:
Internet - Aktion:
Deny
- Quelle:

Mit dieser Regel können Sie weiterhin über den Datenfluss auf einige Azure-Dienste zugreifen, wenn Sie einen privaten Endpunkt im virtuellen Netzwerk konfigurieren. Verwenden Sie zu diesem Zweck Azure Private Link. Dieser Dienst bietet eine Möglichkeit für Ihren Datenverkehr, das Microsoft-Backbonenetzwerk zu durchlaufen, ohne dass ein darüber hinaus gehender externer Netzwerkzugriff erforderlich ist. NiFi unterstützt derzeit Private Link für Blob Storage- und Data Lake Storage-Prozessoren. Wenn in Ihrem privaten Netzwerk kein NTP-Server (Network Time Protocol) verfügbar ist, lassen Sie ausgehenden Zugriff auf NTP zu. Ausführliche Informationen finden Sie unter Zeitsynchronisierung für Linux-VMs in Azure.
Schutz von Daten
Es ist möglich, NiFi ungeschützt ohne Verbindungsverschlüsselung, IAM (Identity & Access Management) oder Datenverschlüsselung zu betreiben. Es wird jedoch empfohlen, Bereitstellungen in der Produktion und in öffentlichen Clouds auf folgende Weise zu schützen:
- Verschlüsseln der Kommunikation mit TLS (Transport Layer Security)
- Verwenden eines unterstützten Authentifizierungs- und Autorisierungsmechanismus
- Verschlüsselung für ruhende Daten
Azure Storage bietet serverseitige transparente Datenverschlüsselung. Ab Release 1.13.2 konfiguriert NiFi jedoch nicht standardmäßig die Verbindungsverschlüsselung oder IAM. Dieses Verhalten ist möglicherweise in einem zukünftigen Release anders.
In den folgenden Abschnitten wird gezeigt, wie Bereitstellungen durch Folgendes geschützt werden:
- Aktivieren der Verbindungsverschlüsselung mit TLS
- Konfigurieren der Authentifizierung basierend auf Zertifikaten oder Microsoft Entra ID
- Verwalten von verschlüsseltem Speicher in Azure
Datenträgerverschlüsselung
Verwenden Sie die Azure-Datenträgerverschlüsselung, um die Sicherheit zu erhöhen. Eine ausführliche Beschreibung finden Sie unter Verschlüsseln von Betriebssystem- und angefügten Datenträgern in einer VM-Skalierungsgruppe mit Azure CLI. Dieses Dokument enthält auch Anweisungen zum Bereitstellen eines eigenen Verschlüsselungsschlüssels. Die folgenden Schritte beschreiben ein einfaches Beispiel für NiFi, das bei den meisten Bereitstellungen funktioniert:
Verwenden Sie den folgenden Azure CLI-Befehl, um die Datenträgerverschlüsselung in einer vorhandenen Key Vault-Instanz zu aktivieren:
az keyvault create --resource-group myResourceGroup --name myKeyVaultName --enabled-for-disk-encryptionAktivieren Sie die Verschlüsselung der Datenträger der VM-Skalierungsgruppe mit dem folgenden Befehl:
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet --disk-encryption-keyvault myKeyVaultID --volume-type DATAOptional können Sie einen Schlüsselverschlüsselungsschlüssel (Key Encryption Key, KEK) verwenden. Verwenden Sie den folgenden Azure CLI-Befehl zum Verschlüsseln mit einem KEK:
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet \ --disk-encryption-keyvault myKeyVaultID \ --key-encryption-keyvault myKeyVaultID \ --key-encryption-key https://<mykeyvaultname>.vault.azure.net/keys/myKey/<version> \ --volume-type DATA
Hinweis
Wenn Sie Ihre VM-Skalierungsgruppe mit dem manuellen Updatemodus konfiguriert haben, führen Sie den Befehl update-instances aus. Schließen Sie die Version des Verschlüsselungsschlüssels ein, den Sie in Key Vault gespeichert haben.
Verschlüsselung während der Übertragung
NiFi unterstützt TLS 1.2 für die Verschlüsselung während der Übertragung. Dieses Protokoll bietet Schutz für den Benutzerzugriff auf die Benutzeroberfläche. Bei Clustern schützt das Protokoll die Kommunikation zwischen den NiFi-Knoten. Es kann auch für den Schutz der Kommunikation mit ZooKeeper verwendet werden. Wenn Sie TLS aktivieren, verwendet NiFi gegenseitiges TLS (mutual TLS, mTLS) zur gegenseitigen Authentifizierung für:
- Die zertifikatbasierte Clientauthentifizierung, wenn Sie diesen Authentifizierungstyp konfiguriert haben
- Die gesamte clusterinterne Kommunikation
Führen Sie die folgenden Schritte aus, um TLS zu aktivieren:
Erstellen Sie einen Keystore und einen Vertrauensspeicher für Client-Server-Kommunikation und die clusterinterne Kommunikation und Authentifizierung.
Konfigurieren Sie die
$NIFI_HOME/conf/nifi.properties. Legen Sie die folgenden Werte fest:- Hostnamen
- Ports
- Eigenschaften des Keystores
- Eigenschaften des Vertrauensspeichers
- Cluster- und ZooKeeper-Sicherheitseigenschaften, falls zutreffend
Sie konfigurieren die Authentifizierung in
$NIFI_HOME/conf/authorizers.xmlin der Regel mit einem anfänglichen Benutzer, der zertifikatbasiert oder mit einer anderen Option authentifiziert wird.Konfigurieren Sie optional mTLS und eine Proxyleserichtlinie zwischen NiFi und den Proxys, Lastenausgleichsmodulen oder externen Endpunkten.
Eine vollständige exemplarische Vorgehensweise finden Sie in der Apache-Projektdokumentation unter dem Thema zum Schützen von NiFi mit TLS.
Hinweis
Ab Version 1.13.2:
- NiFi aktiviert TLS standardmäßig nicht.
- Es gibt keine vorkonfigurierte Unterstützung für anonymen und Einzelbenutzerzugriff für TLS-fähige NiFi-Instanzen.
Um TLS für die Verschlüsselung während der Übertragung zu aktivieren, konfigurieren Sie eine Benutzergruppe und einen Richtlinienanbieter für die Authentifizierung und Autorisierung in $NIFI_HOME/conf/authorizers.xml. Weitere Informationen finden Sie weiter unten in diesem Artikel unter Identität und Zugriffssteuerung.
Zertifikate, Schlüssel und Keystores
Um TLS zu unterstützen, generieren Sie Zertifikate, speichern diese in Java KeyStore und TrustStore und verteilen sie in einem NiFi-Cluster. Es gibt zwei allgemeine Optionen für Zertifikate:
- Selbstsignierte Zertifikate
- Zertifikate, die von Zertifizierungsstellen (CAs) signiert wurden
Bei von einer Zertifizierungsstelle signierten Zertifikaten ist es am besten, eine Zwischenzertifizierungsstelle zu verwenden, um Zertifikate für Knoten im Cluster zu generieren.
KeyStore und TrustStore sind die Schlüssel- und Zertifikatcontainer der Java-Plattform. KeyStore speichert den privaten Schlüssel und das Zertifikat eines Knotens im Cluster. TrustStore speichert einen der folgenden Zertifikattypen:
- Alle vertrauenswürdigen Zertifikate für selbstsignierte Zertifikate in KeyStore
- Ein Zertifikat von einer Zertifizierungsstelle für von der Zertifizierungsstelle signierte Zertifikate in KeyStore
Berücksichtigen Sie bei der Auswahl eines Containers die Skalierbarkeit Ihres NiFi-Clusters. Beispielsweise könnte die Anzahl der Knoten in einem Cluster in Zukunft erhöht oder verringert werden. Wählen Sie in diesem Fall von einer Zertifizierungsstelle signierte Zertifikate in KeyStore und mindestens ein Zertifikat von einer Zertifizierungsstelle in TrustStore aus. Bei dieser Option ist es nicht erforderlich, den vorhandenen TrustStore in den vorhandenen Knoten des Clusters zu aktualisieren. Ein vorhandener TrustStore vertraut Zertifikaten von den folgenden Knotentypen und akzeptiert sie:
- Knoten, die Sie dem Cluster hinzufügen
- Knoten, die andere Knoten im Cluster ersetzen
NiFi-Konfiguration
Um TLS für NiFi zu aktivieren, verwenden Sie $NIFI_HOME/conf/nifi.properties, um die Eigenschaften in dieser Tabelle zu konfigurieren. Stellen Sie sicher, dass die folgenden Eigenschaften den Hostnamen enthalten, den Sie für den Zugriff auf NiFi verwenden:
nifi.web.https.hostodernifi.web.proxy.host- Der zugewiesene Name des Hostzertifikats oder alternative Antragstellernamen
Andernfalls kann bei der Überprüfung des Hostnamens oder des HTTP-HOST-Headers ein Fehler auftreten, durch den Ihnen der Zugriff verweigert wird.
| Eigenschaftenname | BESCHREIBUNG | Beispielwerte |
|---|---|---|
nifi.web.https.host |
Hostname oder IP-Adresse für die Benutzeroberfläche und REST-API. Dieser Wert sollte intern auflösbar sein. Es wird empfohlen, keinen öffentlich zugänglichen Namen zu verwenden. | nifi.internal.cloudapp.net |
nifi.web.https.port |
HTTPS-Port für die Benutzeroberfläche und die REST-API | 9443 (Standard) |
nifi.web.proxy.host |
Durch Trennzeichen getrennte Liste alternativer Hostnamen, die Clients für den Zugriff auf die Benutzeroberfläche und die REST-API verwenden. Diese Liste enthält in der Regel jeden Hostnamen, der als alternativer Antragstellername (Subject Alternative Name, SAN) im Serverzertifikat angegeben ist. Sie kann auch alle Hostnamen und Ports enthalten, die von Lastenausgleichsmodulen, Proxys oder Kubernetes-Eingangscontrollern verwendet werden. | 40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443 |
nifi.security.keystore |
Der Pfad zu einem JKS- oder PKCS12-Keystore, der den privaten Schlüssel des Zertifikats enthält | ./conf/keystore.jks |
nifi.security.keystoreType |
Der Keystoretyp | JKS oder PKCS12 |
nifi.security.keystorePasswd |
Das Keystorekennwort | O8SitLBYpCz7g/RpsqH+zM |
nifi.security.keyPasswd |
(Optional:) Das Kennwort für den privaten Schlüssel | |
nifi.security.truststore |
Der Pfad zu einem JKS- oder PKCS12-Vertrauensspeicher, der Zertifikate oder Zertifizierungsstellenzertifikate enthält, mit denen vertrauenswürdige Benutzer*innen und Clusterknoten authentifiziert werden | ./conf/truststore.jks |
nifi.security.truststoreType |
Der Vertrauensspeichertyp | JKS oder PKCS12 |
nifi.security.truststorePasswd |
Das Vertrauensspeicherkennwort | RJlpGe6/TuN5fG+VnaEPi8 |
nifi.cluster.protocol.is.secure |
Der Status von TLS für die clusterinterne Kommunikation. Wenn nifi.cluster.is.node auf true festgelegt ist, legen Sie diesen Wert auf true fest, um TLS für die Cluster zu aktivieren. |
true |
nifi.remote.input.secure |
Der Status von TLS für die Kommunikation zwischen Standorten. | true |
Das folgende Beispiel zeigt, wie diese Eigenschaften in $NIFI_HOME/conf/nifi.properties dargestellt werden: Beachten Sie, dass die Werte nifi.web.http.host und nifi.web.http.port leer sind.
nifi.remote.input.secure=true
nifi.web.http.host=
nifi.web.http.port=
nifi.web.https.host=nifi.internal.cloudapp.net
nifi.web.https.port=9443
nifi.web.proxy.host=40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443
nifi.security.keystore=./conf/keystore.jks
nifi.security.keystoreType=JKS
nifi.security.keystorePasswd=O8SitLBYpCz7g/RpsqH+zM
nifi.security.keyPasswd=
nifi.security.truststore=./conf/truststore.jks
nifi.security.truststoreType=JKS
nifi.security.truststorePasswd=RJlpGe6/TuN5fG+VnaEPi8
nifi.cluster.protocol.is.secure=true
ZooKeeper-Konfiguration
Anweisungen zum Aktivieren von TLS in Apache ZooKeeper für die Quorumkommunikation und den Clientzugriff finden Sie im ZooKeeper-Administratorhandbuch. Diese Funktionalität wird erst ab Version 3.5.5 unterstützt.
NiFi verwendet ZooKeeper für Clustering ohne Hauptcluster und die Clusterkoordination. Ab Version 1.13.0 unterstützt NiFi den sicheren Clientzugriff auf TLS-fähige Instanzen von ZooKeeper. ZooKeeper speichert die Clustermitgliedschaft und den Prozessorstatus für den Clusterbereich im Nur-Text-Format. Daher ist es wichtig, den sicheren Clientzugriff auf ZooKeeper zu verwenden, um ZooKeeper-Clientanforderungen zu authentifizieren. Verschlüsseln Sie vertrauliche Werte auch während der Übertragung.
Legen Sie die folgenden Eigenschaften in $NIFI_HOME/conf/nifi.properties fest, um TLS für den NiFi-Clientzugriff auf ZooKeeper zu aktivieren. Wenn Sie nifi.zookeeper.client.secure true festlegen, ohne nifi.zookeeper.security-Eigenschaften zu konfigurieren, führt NiFi ein Fallback auf den Keystore und Vertrauensspeicher durch, die Sie in nifi.securityproperties angegeben haben.
| Name der Eigenschaft | BESCHREIBUNG | Beispielwerte |
|---|---|---|
nifi.zookeeper.client.secure |
Der Status von TLS auf Clients beim Herstellen einer Verbindung mit ZooKeeper | true |
nifi.zookeeper.security.keystore |
Der Pfad zu einem JKS-, PKCS12- oder PEM-Keystore, der den privaten Schlüssel des Zertifikats enthält, das ZooKeeper zur Authentifizierung präsentiert wird. | ./conf/zookeeper.keystore.jks |
nifi.zookeeper.security.keystoreType |
Der Keystoretyp | JKS, PKCS12, PEM oder automatische Erkennung durch die Erweiterung |
nifi.zookeeper.security.keystorePasswd |
Das Keystorekennwort | caB6ECKi03R/co+N+64lrz |
nifi.zookeeper.security.keyPasswd |
(Optional:) Das Kennwort für den privaten Schlüssel | |
nifi.zookeeper.security.truststore |
Der Pfad zu einem JKS-, PKCS12- oder PEM-Vertrauensspeicher, der Zertifikate oder Zertifizierungsstellenzertifikate enthält, die zum Authentifizieren von ZooKeeper verwendet werden. | ./conf/zookeeper.truststore.jks |
nifi.zookeeper.security.truststoreType |
Der Vertrauensspeichertyp | JKS, PKCS12, PEM oder automatische Erkennung durch die Erweiterung |
nifi.zookeeper.security.truststorePasswd |
Das Vertrauensspeicherkennwort | qBdnLhsp+mKvV7wab/L4sv |
nifi.zookeeper.connect.string |
Die Verbindungszeichenfolge für den ZooKeeper-Host oder das Quorum. Bei dieser Zeichenfolge handelt es sich um eine durch Trennzeichen getrennte Liste von host:port-Werten. In der Regel ist der Wert secureClientPort nicht mit dem Wert clientPort identisch. Den richtigen Wert finden Sie in der ZooKeeper-Konfiguration. |
zookeeper1.internal.cloudapp.net:2281, zookeeper2.internal.cloudapp.net:2281, zookeeper3.internal.cloudapp.net:2281 |
Das folgende Beispiel zeigt, wie diese Eigenschaften in $NIFI_HOME/conf/nifi.properties dargestellt werden:
nifi.zookeeper.client.secure=true
nifi.zookeeper.security.keystore=./conf/keystore.jks
nifi.zookeeper.security.keystoreType=JKS
nifi.zookeeper.security.keystorePasswd=caB6ECKi03R/co+N+64lrz
nifi.zookeeper.security.keyPasswd=
nifi.zookeeper.security.truststore=./conf/truststore.jks
nifi.zookeeper.security.truststoreType=JKS
nifi.zookeeper.security.truststorePasswd=qBdnLhsp+mKvV7wab/L4sv
nifi.zookeeper.connect.string=zookeeper1.internal.cloudapp.net:2281,zookeeper2.internal.cloudapp.net:2281,zookeeper3.internal.cloudapp.net:2281
Weitere Informationen zum Schützen von ZooKeeper mit TLS finden Sie im Apache NiFi-Administratorhandbuch.
Identität und Zugriffssteuerung
In NiFi werden Identität und Zugriffssteuerung durch die Benutzerauthentifizierung und -autorisierung erreicht. Für die Benutzerauthentifizierung bietet NiFi mehrere Auswahlmöglichkeiten: Einzelbenutzer, LDAP, Kerberos, SAML (Security Assertion Markup Language) und OIDC (OpenID Connect). Wenn Sie keine Option konfigurieren, verwendet NiFi Clientzertifikate, um Benutzer*innen über HTTPS zu authentifizieren.
Wenn Sie die Multi-Faktor-Authentifizierung in Erwägung ziehen, wird eine Kombination aus Microsoft Entra ID und OIDC empfohlen. Microsoft Entra ID unterstützt cloudnatives einmaliges Anmelden mit OIDC. Mit dieser Kombination können Benutzer*innen viele Sicherheitsfeatures für Unternehmen nutzen:
- Protokollierung und Warnung bei verdächtigen Aktivitäten von Benutzerkonten
- Überwachung von Zugriffsversuchen auf deaktivierte Anmeldeinformationen
- Warnung bei ungewöhnlichem Anmeldeverhalten mit einem Konto
Für die Autorisierung ermöglicht NiFi das Erzwingen auf Basis von Benutzer-, Gruppen- und Zugriffsrichtlinien. NiFi bietet diese Erzwingung über UserGroupProviders und AccessPolicyProviders. Standardanbieter sind Datei, LDAP, Shell und UserGroupProviders auf Azure Graph-Grundlage. Mit AzureGraphUserGroupProvider können Sie Benutzergruppen aus Microsoft Entra ID verwenden. Anschließend können Sie diesen Gruppen Richtlinien zuweisen. Anweisungen zur Konfiguration finden Sie im Apache NiFi-Administratorhandbuch.
Derzeit stehen AccessPolicyProviders, die auf Dateien und Apache Ranger basieren, für das Verwalten und Speichern von Benutzer- und Gruppenrichtlinien zur Verfügung. Ausführliche Informationen finden Sie in der Apache NiFi-Dokumentation und in der Apache Ranger-Dokumentation.
Anwendungsgateway
Ein Anwendungsgateway ermöglicht den verwalteten Layer-7-Lastenausgleich für die NiFi-Schnittstelle. Konfigurieren Sie das Anwendungsgateway so, dass die VM-Skalierungsgruppe der NiFi-Knoten als Back-End-Pool verwendet wird.
Für die meisten NiFi-Installationen wird die folgende Konfiguration für Application Gateway empfohlen:
- Tarif: Standard
- SKU-Größe: mittel
- Anzahl der Instanzen: zwei oder mehr
Verwenden Sie einen Integritätstest zur Überwachung der Integrität des Webservers auf jedem Knoten: Entfernen Sie fehlerhafte Knoten aus der Rotation für den Lastenausgleich. Dieser Ansatz vereinfacht das Anzeigen der Benutzeroberfläche, wenn der Cluster insgesamt fehlerhaft ist. Der Browser leitet Sie nur zu Knoten weiter, die derzeit fehlerfrei sind und auf Anforderungen reagieren.
Sie sollten zwei wichtige Integritätstests in Erwägung ziehen. Zusammen bieten sie einen regelmäßigen Heartbeat für die allgemeine Integrität jedes Knotens im Cluster. Konfigurieren Sie den ersten Integritätstest so, dass er auf den Pfad /NiFi verweist. Mit diesem Test wird die Integrität der NiFi-Benutzeroberfläche auf jedem Knoten bestimmt. Konfigurieren Sie einen zweiten Integritätstest für den Pfad /nifi-api/controller/cluster. Dieser Test gibt an, ob jeder Knoten derzeit fehlerfrei ist und mit dem gesamten Cluster verbunden ist.
Sie haben zwei Möglichkeiten, die Front-End-IP-Adresse des Anwendungsgateways zu konfigurieren:
- Mit einer öffentlichen IP-Adresse
- Mit einer privaten Subnetz-IP-Adresse
Fügen Sie nur dann eine öffentliche IP-Adresse ein, wenn Benutzer*innen über das öffentliche Internet auf die Benutzeroberfläche zugreifen müssen. Wenn kein öffentlicher Internetzugriff für die Benutzer*innen erforderlich ist, greifen Sie über eine Jumpbox im virtuellen Netzwerk oder per Peering mit Ihrem privaten Netzwerk auf das Front-End für den Lastenausgleich zu. Wenn Sie das Anwendungsgateway mit einer öffentlichen IP-Adresse konfigurieren, wird empfohlen, für NiFi die Clientzertifikatauthentifizierung und für die NiFi-Benutzeroberfläche TLS zu aktivieren. Sie können auch eine Netzwerksicherheitsgruppe im Subnetz des delegierten Anwendungsgateways verwenden, um die Quell-IP-Adressen einzuschränken.
Diagnose und Systemüberwachung
In den Diagnoseeinstellungen von Application Gateway gibt es eine Konfigurationsoption zum Senden von Metriken und Zugriffsprotokollen. Mithilfe dieser Option können Sie diese Informationen vom Lastenausgleichsmodul an verschiedene Ziele senden:
- ein Speicherkonto
- Event Hubs
- Einen Log Analytics-Arbeitsbereich.
Das Aktivieren dieser Einstellung ist für das Debuggen von Lastenausgleichsproblemen und zum Gewinnen von Erkenntnissen zur Integrität von Clusterknoten nützlich.
Die folgende Log Analytics-Abfrage zeigt die Integrität von Clusterknoten im Zeitverlauf aus Sicht von Application Gateway. Sie können eine ähnliche Abfrage verwenden, um Warnungen oder automatisierte Korrekturmaßnahmen für fehlerhafte Knoten zu generieren.
AzureDiagnostics
| summarize UnHealthyNodes = max(unHealthyHostCount_d), HealthyNodes = max(healthyHostCount_d) by bin(TimeGenerated, 5m)
| render timechart
Das folgende Diagramm der Abfrageergebnisse zeigt eine Zeitansicht der Integrität des Clusters:

Verfügbarkeit
Beachten Sie beim Implementieren dieser Lösung die folgenden Aspekte der Verfügbarkeit:
Load Balancer
Verwenden Sie einen Lastenausgleich für die Benutzeroberfläche, um die Verfügbarkeit der Benutzeroberfläche bei einem Knotenausfall zu erhöhen.
Separate VMs
Um die Verfügbarkeit zu erhöhen, stellen Sie den ZooKeeper-Cluster auf separaten VMs bereit, die von den VMs im NiFi-Cluster getrennt sind. Weitere Informationen zum Konfigurieren von ZooKeeper finden Sie im Apache NiFi-Systemadministratorhandbuch unter dem Thema Zustandsverwaltung.
Verfügbarkeitszonen
Stellen Sie sowohl die NiFi-VM-Skalierungsgruppe als auch den ZooKeeper-Cluster in einer zonenübergreifenden Konfiguration bereit, um die Verfügbarkeit zu maximieren. Wenn die Kommunikation zwischen den Knoten im Cluster über Verfügbarkeitszonen hinweg erfolgt, führt dies zu einer geringen Latenz. Diese Latenz hat jedoch in der Regel nur minimale Auswirkungen auf den Durchsatz des Clusters.
VM-Skalierungsgruppen
Es wird empfohlen, die NiFi-Knoten in einer einzelnen VM-Skalierungsgruppe bereitzustellen, die mehrere Verfügbarkeitszonen umfasst (sofern verfügbar). Ausführliche Informationen zu dieser Art der Verwendung von Skalierungsgruppen finden Sie unter Erstellen einer VM-Skalierungsgruppe, die Verfügbarkeitszonen verwendet.
Überwachung
Verwenden Sie Berichtsaufgaben, um die Integrität und Leistung eines NiFi-Clusters zu überwachen.
Überwachung mithilfe von Berichtstasks
Für die Überwachung können Sie einen Berichtstask verwenden, den Sie in NiFi konfigurieren und ausführen. Wie unter Diagnose und Integritätsüberwachung erläutert, stellt Log Analytics einen Berichtstask im NiFi-Azure-Paket zur Verfügung. Sie können diesen Berichtstask verwenden, um die Überwachung in Log Analytics oder vorhandene Überwachungs- oder Protokollierungssysteme zu integrieren.
Log Analytics-Abfragen
Die Beispielabfragen in den folgenden Abschnitten helfen Ihnen bei den ersten Schritten. Eine Übersicht über das Abfragen von Log Analytics-Daten finden Sie unter Azure Monitor-Protokollabfragen.
Für Protokollabfragen in Monitor und Log Analytics wird eine Version der Kusto-Abfragesprache verwendet. Es bestehen jedoch Unterschiede zwischen Protokollabfragen und Kusto-Abfragen. Weitere Informationen finden Sie in der Übersicht über Kusto-Abfragen.
Weitere Informationen zum strukturierten Lernen finden Sie in den folgenden Tutorials:
- Erste Schritte mit Protokollabfragen in Azure Monitor
- Erste Schritte mit Log Analytics in Azure Monitor
Log Analytics-Berichtstask
Standardmäßig sendet NiFi Metrikdaten an die Tabelle nifimetrics. Sie können jedoch in den Eigenschaften des Berichtstasks ein anderes Ziel konfigurieren. Der Berichtstask erfasst die folgenden NiFi-Metriken:
| Metriktyp | Metrikname |
|---|---|
| NiFi-Metriken | FlowFilesReceived |
| NiFi-Metriken | FlowFilesSent |
| NiFi-Metriken | FlowFilesQueued |
| NiFi-Metriken | BytesReceived |
| NiFi-Metriken | BytesWritten |
| NiFi-Metriken | BytesRead |
| NiFi-Metriken | BytesSent |
| NiFi-Metriken | BytesQueued |
| Portstatusmetriken | InputCount |
| Portstatusmetriken | InputBytes |
| Verbindungsstatusmetriken | QueuedCount |
| Verbindungsstatusmetriken | QueuedBytes |
| Portstatusmetriken | OutputCount |
| Portstatusmetriken | OutputBytes |
| JVM-Metriken (Java Virtual Machine) | jvm.uptime |
| JVM-Metriken | jvm.heap_used |
| JVM-Metriken | jvm.heap_usage |
| JVM-Metriken | jvm.non_heap_usage |
| JVM-Metriken | jvm.thread_states.runnable |
| JVM-Metriken | jvm.thread_states.blocked |
| JVM-Metriken | jvm.thread_states.timed_waiting |
| JVM-Metriken | jvm.thread_states.terminated |
| JVM-Metriken | jvm.thread_count |
| JVM-Metriken | jvm.daemon_thread_count |
| JVM-Metriken | jvm.file_descriptor_usage |
| JVM-Metriken | jvm.gc.runs jvm.gc.runs.g1_old_generation jvm.gc.runs.g1_young_generation |
| JVM-Metriken | jvm.gc.time jvm.gc.time.g1_young_generation jvm.gc.time.g1_old_generation |
| JVM-Metriken | jvm.buff_pool_direct_capacity |
| JVM-Metriken | jvm.buff_pool_direct_count |
| JVM-Metriken | jvm.buff_pool_direct_mem_used |
| JVM-Metriken | jvm.buff_pool_mapped_capacity |
| JVM-Metriken | jvm.buff_pool_mapped_count |
| JVM-Metriken | jvm.buff_pool_mapped_mem_used |
| JVM-Metriken | jvm.mem_pool_code_cache |
| JVM-Metriken | jvm.mem_pool_compressed_class_space |
| JVM-Metriken | jvm.mem_pool_g1_eden_space |
| JVM-Metriken | jvm.mem_pool_g1_old_gen |
| JVM-Metriken | jvm.mem_pool_g1_survivor_space |
| JVM-Metriken | jvm.mem_pool_metaspace |
| JVM-Metriken | jvm.thread_states.new |
| JVM-Metriken | jvm.thread_states.waiting |
| Metriken auf Prozessorebene | BytesRead |
| Metriken auf Prozessorebene | BytesWritten |
| Metriken auf Prozessorebene | FlowFilesReceived |
| Metriken auf Prozessorebene | FlowFilesSent |
Mit der folgenden Beispielabfrage wird die Metrik BytesQueued eines Clusters abgefragt:
let table_name = nifimetrics_CL;
let metric = "BytesQueued";
table_name
| where Name_s == metric
| where Computer contains {ComputerName}
| project TimeGenerated, Computer, ProcessGroupName_s, Count_d, Name_s
| summarize sum(Count_d) by bin(TimeGenerated, 1m), Computer, Name_s
| render timechart
Diese Abfrage erzeugt ein Diagramm wie das in diesem Screenshot:

Hinweis
Wenn Sie NiFi in Azure ausführen, sind Sie nicht auf den Log Analytics-Berichtstask beschränkt. NiFi unterstützt Berichtstasks für viele Überwachungstechnologien von Drittanbietern. Eine Liste der unterstützten Berichtstasks finden Sie im Abschnitt zu Berichtstasks in der Apache NiFi-Dokumentation.
NiFi-Infrastrukturüberwachung
Installieren Sie neben dem Berichtstask auch die Log Analytics-VM-Erweiterung auf den NiFi- und ZooKeeper-Knoten. Diese Erweiterung sammelt Protokolle, zusätzliche Metriken auf VM-Ebene und Metriken von ZooKeeper.
Benutzerdefinierte Protokolle zu NiFi-App, Benutzer*innen, Bootstrap und ZooKeeper
Führen Sie die folgenden Schritte aus, um zusätzliche Protokolle zu erfassen:
Navigieren Sie im Azure-Portal zu Log Analytics-Arbeitsbereiche, und wählen Sie dann Ihren Arbeitsbereich aus.
Wählen Sie unter Einstellungen die Option Benutzerdefinierte Protokolle aus.
Wählen Sie Benutzerdefiniertes Protokoll hinzufügen aus.
Richten Sie ein benutzerdefiniertes Protokoll mit den folgenden Werten ein:
- Name:
NiFiAppLogs - Pfadtyp:
Linux - Pfadname:
/opt/nifi/logs/nifi-app.log
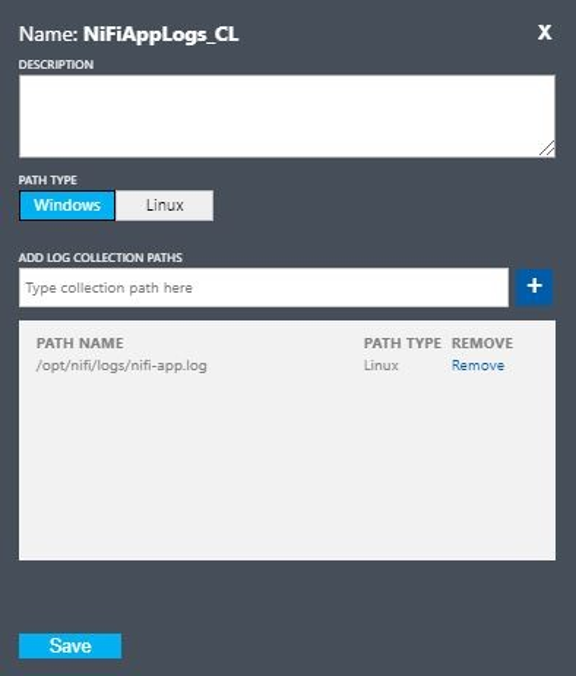
- Name:
Richten Sie ein benutzerdefiniertes Protokoll mit den folgenden Werten ein:
- Name:
NiFiBootstrapAndUser - Erster Pfadtyp:
Linux - Erster Pfadname:
/opt/nifi/logs/nifi-user.log - Zweiter Pfadtyp:
Linux - Zweiter Pfadname:
/opt/nifi/logs/nifi-bootstrap.log
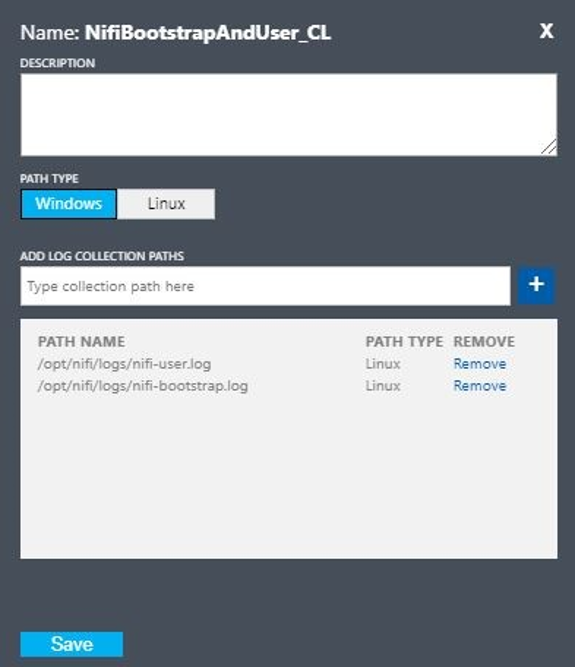
- Name:
Richten Sie ein benutzerdefiniertes Protokoll mit den folgenden Werten ein:
- Name:
NiFiZK - Pfadtyp:
Linux - Pfadname:
/opt/zookeeper/logs/*.out
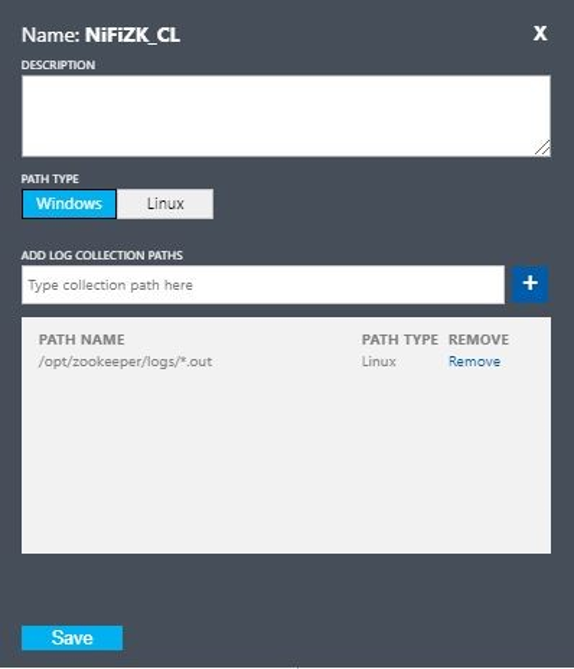
- Name:
Die folgende Abfrage ist ein Beispiel für NiFiAppLogs für die benutzerdefinierte Tabelle, die im ersten Beispiel erstellt wurde:
NiFiAppLogs_CL
| where TimeGenerated > ago(24h)
| where Computer contains {ComputerName} and RawData contains "error"
| limit 10
Diese Abfrage erzeugt Ergebnisse ähnlich den folgenden:

Konfiguration des Infrastrukturprotokolls
Sie können mit Monitor VMs oder physische Computer überwachen und verwalten. Diese Ressourcen können sich in Ihrem lokalen Rechenzentrum oder in einer anderen Cloudumgebung befinden. Stellen Sie zum Einrichten dieser Überwachung den Log Analytics-Agent bereit. Konfigurieren Sie den Agent so, dass er seine Ergebnisse an einen Log Analytics-Arbeitsbereich übermittelt. Weitere Informationen finden Sie unter Übersicht über Log Analytics-Agents.
Der folgende Screenshot zeigt eine Beispielkonfiguration für den Agent für NiFi-VMs. Die gesammelten Daten werden in der Tabelle Perf gespeichert.

Mit der folgenden Beispielabfrage werden die NiFi-App-Protokolle in Perf abgefragt:
let cluster_name = {ComputerName};
// The hourly average of CPU usage across all computers.
Perf
| where Computer contains {ComputerName}
| where CounterName == "% Processor Time" and InstanceName == "_Total"
| where ObjectName == "Processor"
| summarize CPU_Time_Avg = avg(CounterValue) by bin(TimeGenerated, 30m), Computer
Diese Abfrage erzeugt einen Bericht wie den in diesem Screenshot:

Alerts
Verwenden Sie Monitor, um Warnungen zur Integrität und Leistung des NiFi-Clusters zu erstellen. Beispiele für Warnungen:
- Die Gesamtanzahl der Warteschlangen hat einen Schwellenwert überschritten.
- Der Wert von
BytesWrittenliegt unter einem erwarteten Schwellenwert. - Der Wert von
FlowFilesReceivedliegt unter einem Schwellenwert. - Der Cluster ist fehlerhaft.
Weitere Informationen zum Einrichten von Warnungen in Monitor finden Sie unter Überblick über Warnungen in Microsoft Azure.
Konfigurationsparameter
In den folgenden Abschnitten werden empfohlene, nicht standardmäßige Konfigurationen für NiFi und die zugehörigen Abhängigkeiten erläutert, einschließlich ZooKeeper und Java. Diese Einstellungen eignen sich für Clustergrößen, die in der Cloud möglich sind. Sie legen die Eigenschaften in den folgenden Konfigurationsdateien fest:
$NIFI_HOME/conf/nifi.properties$NIFI_HOME/conf/bootstrap.conf$ZOOKEEPER_HOME/conf/zoo.cfg$ZOOKEEPER_HOME/bin/zkEnv.sh
Ausführliche Informationen zu verfügbaren Konfigurationseigenschaften und -dateien finden Sie im Apache NiFi-Systemadministratorhandbuch und im ZooKeeper-Administratorhandbuch.
NiFi
Bei einer Azure-Bereitstellung sollten Sie die Eigenschaften in $NIFI_HOME/conf/nifi.properties anpassen. In der folgenden Tabelle sind die wichtigsten Eigenschaften aufgeführt. Weitere Empfehlungen und Erkenntnisse finden Sie in den Apache NiFi-Mailinglisten.
| Parameter | BESCHREIBUNG | Standard | Empfehlung |
|---|---|---|---|
nifi.cluster.node.connection.timeout |
Wartezeit beim Herstellen einer Verbindung mit anderen Clusterknoten | 5 Sekunden | 60 Sekunden |
nifi.cluster.node.read.timeout |
Wartezeit auf eine Antwort auf eine Anforderung an andere Clusterknoten | 5 Sekunden | 60 Sekunden |
nifi.cluster.protocol.heartbeat.interval |
Sendehäufigkeit für Heartbeats zurück an den Clusterkoordinator | 5 Sekunden | 60 Sekunden |
nifi.cluster.node.max.concurrent.requests |
Grad an Parallelität beim Replizieren von HTTP-Aufrufen wie REST-API-Aufrufen an andere Clusterknoten | 100 | 500 |
nifi.cluster.node.protocol.threads |
Anfängliche Threadpoolgröße für die clusterübergreifende/replizierte Kommunikation | 10 | 50 |
nifi.cluster.node.protocol.max.threads |
Maximale Anzahl von Threads für die clusterübergreifende/replizierte Kommunikation | 50 | 75 |
nifi.cluster.flow.election.max.candidates |
Anzahl der Knoten, die bei der Entscheidung über den aktuellen Fluss verwendet werden. Dieser Wert begrenzt die Abstimmung auf die angegebene Zahl. | empty | 75 |
nifi.cluster.flow.election.max.wait.time |
Wartezeit auf Knoten, bevor entschieden wird, was der aktuelle Fluss ist | 5 Minuten | 5 Minuten |
Clusterverhalten
Beachten Sie beim Konfigurieren von Clustern die folgenden Punkte.
Timeout
Um die allgemeine Integrität eines Clusters und seiner Knoten sicherzustellen, kann es vorteilhaft sein, die Timeouts zu erhöhen. Dadurch wird sichergestellt, dass Ausfälle nicht durch vorübergehende Netzwerkprobleme oder hohe Auslastungen verursacht werden.
In einem verteilten System variiert die Leistung der einzelnen Systeme. Diese Abweichungen betreffen auch die Netzwerkkommunikation und Latenz, die sich in der Regel auf die Kommunikation zwischen Knoten und Clustern auswirken. Sie kann durch die Netzwerkinfrastruktur oder das System selbst verursacht werden. Daher ist die Wahrscheinlichkeit von Abweichungen in großen Systemclustern höher. In Java-Anwendungen unter Last kann sich das Anhalten der Garbage Collection (GC) auf der Java-VM (JVM) auch auf die Antwortzeiten von Anforderungen auswirken.
Verwenden Sie die Eigenschaften in den folgenden Abschnitten, um die Timeouts entsprechend den Anforderungen Ihres Systems zu konfigurieren:
nifi.cluster.node.connection.timeout und nifi.cluster.node.read.timeout
Die nifi.cluster.node.connection.timeout-Eigenschaft gibt an, wie lange beim Herstellen einer Verbindung gewartet werden soll. Die nifi.cluster.node.read.timeout-Eigenschaft gibt an, wie lange beim Empfang von Daten zwischen Anforderungen gewartet werden soll. Der Standardwert der Eigenschaften ist fünf Sekunden. Diese Eigenschaften gelten für Anforderungen zwischen Knoten. Durch das Erhöhen dieser Werte können Sie mehrere zusammenhängende Probleme beheben:
- Verbindungstrennung durch den Clusterkoordinator aufgrund von Heartbeatunterbrechungen
- Fehler beim Abrufen des Flusses vom Koordinator beim Beitritt zum Cluster
- Einrichten der Kommunikation zwischen Standorten (Site-to-Site, S2S) und für den Lastenausgleich
Verwenden Sie Werte, die größer als die Standardwerte sind, es sei denn, Ihr Cluster enthält eine sehr kleine Skalierungsgruppe mit nicht mehr als drei Knoten.
nifi.cluster.protocol.heartbeat.interval
Im Rahmen der NiFi-Clusterstrategie gibt jeder Knoten einen Heartbeat aus, um seinen fehlerfreien Status zu kommunizieren. Standardmäßig senden die Knoten alle fünf Sekunden Heartbeats. Wenn der Clusterkoordinator erkennt, dass acht aufeinanderfolgende Heartbeats eines Knotens ausfallen, trennt er die Verbindung mit dem Knoten. Erhöhen Sie das in der nifi.cluster.protocol.heartbeat.interval-Eigenschaft festgelegte Intervall, um langsame Heartbeats zu unterstützen und damit zu verhindern, dass der Cluster die Knoten unnötig trennt.
Parallelität
Verwenden Sie die Eigenschaften in den folgenden Abschnitten, um Parallelitätseinstellungen zu konfigurieren:
nifi.cluster.node.protocol.threads und nifi.cluster.node.protocol.max.threads
Die nifi.cluster.node.protocol.max.threads-Eigenschaft gibt die maximale Anzahl von Threads an, die für die clusterbasierte Kommunikation wie S2S-Lastenausgleich und Benutzeroberflächenaggregation verwendet werden. Der Standardwert für diese Eigenschaft ist 50 Threads. Erhöhen Sie diesen Wert bei großen Clustern, um die größere Anzahl von Anforderungen zu bewältigen, die diese Vorgänge erfordern.
Die nifi.cluster.node.protocol.threads-Eigenschaft bestimmt die anfängliche Threadpoolgröße. Der Standardwert ist 10 Threads. Dieser Wert ist ein Minimum. Er steigt bei Bedarf bis zu dem in nifi.cluster.node.protocol.max.threads festgelegten Höchstwert. Erhöhen Sie den Wert von nifi.cluster.node.protocol.threads bei Clustern, die beim Start eine große Skalierungsgruppe verwenden.
nifi.cluster.node.max.concurrent.requests
Viele HTTP-Anforderungen wie REST-API- und Benutzeroberflächenaufrufe müssen auf andere Knoten im Cluster repliziert werden. Wenn die Größe des Clusters zunimmt, wird eine wachsende Anzahl von Anforderungen repliziert. Die nifi.cluster.node.max.concurrent.requests-Eigenschaft schränkt die Anzahl ausstehender Anforderungen ein. Ihr Wert sollte größer die erwartete Clustergröße sein. Der Standardwert ist 100 gleichzeitige Anforderungen. Sofern Sie keinen kleinen Cluster mit nicht mehr als drei Knoten ausführen, verhindern Sie fehlerhafte Anforderungen, indem Sie diesen Wert erhöhen.
Flussauswahl
Verwenden Sie die Eigenschaften in den folgenden Abschnitten, um Einstellungen zur Flussauswahl zu konfigurieren:
nifi.cluster.flow.election.max.candidates
NiFi verwendet Clustering ohne Hauptknoten. Das bedeutet, dass es keinen bestimmten autoritativen Knoten gibt. Stattdessen stimmen die Knoten darüber ab, welche Flussdefinition als die richtige gilt. Sie stimmen auch ab, welche Knoten dem Cluster beitreten.
Standardmäßig ist die nifi.cluster.flow.election.max.candidates-Eigenschaft die maximale Wartezeit, die von der nifi.cluster.flow.election.max.wait.time-Eigenschaft angegeben wird. Wenn dieser Wert zu hoch ist, kann der Start langsam sein. Der Standardwert von nifi.cluster.flow.election.max.wait.time beträgt fünf Minuten. Legen Sie die maximale Anzahl von Kandidaten auf einen nicht leeren Wert wie 1 oder höher fest, um sicherzustellen, dass die Wartezeit nicht länger als erforderlich ist. Wenn Sie diese Eigenschaft festlegen, weisen Sie ihr einen Wert zu, der der Clustergröße oder einem Anteil der erwarteten Clustergröße entspricht. Legen Sie für kleine, statische Cluster mit 10 oder weniger Knoten diesen Wert auf die Anzahl der Knoten im Cluster fest.
nifi.cluster.flow.election.max.wait.time
In einer elastischen Cloudumgebung wirkt sich die Zeit für das Bereitstellen von Hosts auf die Startzeit der Anwendung aus. Die nifi.cluster.flow.election.max.wait.time-Eigenschaft bestimmt, wie lange NiFi auf die Entscheidung für einen Fluss wartet. Legen Sie diesen Wert auf ein angemessenes Verhältnis zur Gesamtstartzeit des Clusters bei seiner Startgröße an. Bei ersten Tests sind fünf Minuten in allen Azure-Regionen mit den empfohlenen Instanztypen mehr als ausreichend. Sie können diesen Wert jedoch erhöhen, wenn die Zeit für die Bereitstellung regelmäßige den Standardwert überschreitet.
Java
Es wird empfohlen, ein LTS-Release von Java zu verwenden. Von diesen Releases ist Java 11 gegenüber Java 8 geringfügig besser geeignet, da Java 11 eine schnellere Garbage Collection-Implementierung unterstützt. Es ist jedoch mit beiden Release möglich, eine leistungsstarke NiFi-Bereitstellung zu erreichen.
In den folgenden Abschnitten werden allgemeine JVM-Konfigurationen erläutert, die beim Ausführen von NiFi verwendet werden. Sie legen die JVM-Parameter in der Bootstrap-Konfigurationsdatei unter $NIFI_HOME/conf/bootstrap.conf fest.
Garbage Collector
Wenn Sie Java 11 ausführen, wird in den meisten Situationen empfohlen, den G1-Garbage Collector (G1GC) zu verwenden. G1GC hat eine höhere Leistung als ParallelGC, da bei G1GC die Länge von GC-Pausen reduziert ist. G1GC ist die Standardeinstellung in Java 11. Sie können dies jedoch explizit konfigurieren, indem Sie den folgenden Wert in bootstrap.conf festlegen:
java.arg.13=-XX:+UseG1GC
Wenn Sie Java 8 ausführen, verwenden Sie G1GC nicht. Verwenden Sie stattdessen ParallelGC. Es gibt Mängel in der Java 8-Implementierung von G1GC, die verhindern, dass Sie das Tool mit den empfohlenen Repositoryimplementierungen verwenden können. ParallelGC ist langsamer als G1GC. Mit ParallelGC können Sie jedoch trotzdem eine leistungsstarke NiFi-Bereitstellung mit Java 8 erzielen.
Heap
Ein Teil der Eigenschaften in der Datei bootstrap.conf bestimmt die Konfiguration des NiFi-JVM-Heaps. Konfigurieren Sie für einen Standardfluss einen Heap mit 32 GB, und verwenden Sie die folgenden Einstellungen:
java.arg.3=-Xmx32g
java.arg.2=-Xms32g
Um die optimale Heapgröße auszuwählen, die auf den JVM-Prozess angewandt werden soll, berücksichtigen Sie zwei Faktoren:
- Die Merkmale des Datenflusses
- Die Art und Weise, wie NiFi den Arbeitsspeicher bei der Verarbeitung verwendet
Eine ausführliche Dokumentation finden Sie unter Apache NiFi in Depth (Details zu Apache NiFi).
Machen Sie den Heap nur so groß wie nötig, um die Verarbeitungsanforderungen zu erfüllen. Mit diesem Ansatz minimieren Sie die Dauer von GC-Pausen. Allgemeine Überlegungen zur Java-Garbage Collection finden Sie im Leitfaden zur Optimierung der Garbage Collection für Ihre Java-Version.
Berücksichtigen Sie beim Anpassen der JVM-Arbeitsspeichereinstellungen die folgenden wichtigen Faktoren:
Die Anzahl von FlowFiles, oder NiFi-Datensätzen, die während eines bestimmten Zeitraums aktiv sind. Diese Zahl umfasst FlowFiles, die zurückgestellt oder in die Warteschlange eingereiht wurden.
Die Anzahl von Attributen, die in FlowFiles definiert sind
Die Menge an Arbeitsspeicher, die ein Prozessor zum Verarbeiten eines bestimmten Inhalts benötigt
Die Art und Weise, wie ein Prozessor Daten verarbeitet:
- Streamingdaten
- Verwendung von datensatzorientierten Prozessoren
- Gleichzeitiges Speichern aller Daten im Arbeitsspeicher
Diese Details sind wichtig. Während der Verarbeitung behält NiFi Verweise und Attribute für jedes FlowFile im Arbeitsspeicher bei. Bei Spitzenleistung ist die vom System verwendete Arbeitsspeichermenge proportional zur Anzahl der FlowFiles und allen Attributen, die sie enthalten. Diese Zahl schließt FlowFiles in der Warteschlange ein. NiFi kann eine Auslagerung auf den Datenträger durchführen. Sie sollten diese Option jedoch vermeiden, da sie die Leistung beeinträchtigt.
Berücksichtigen Sie auch die grundlegende Speichernutzung durch Objekte. Legen Sie insbesondere Ihren Heap groß genug fest, damit Objekte im Arbeitsspeicher beibehalten werden können. Beachten Sie die folgenden Tipps zum Konfigurieren der Arbeitsspeichereinstellungen:
- Führen Sie Ihren Fluss mit repräsentativen Daten und minimalem Druck aus, indem Sie mit der Einstellung
-Xmx4Gbeginnen und dann den Arbeitsspeicher bei Bedarf vorsichtig erhöhen. - Führen Sie Ihren Fluss mit repräsentativen Daten und maximalem Druck aus, indem Sie mit der Einstellung
-Xmx4Gbeginnen und dann die Clustergröße bei Bedarf vorsichtig erhöhen. - Analysieren Sie die Anwendung während der Flussausführung mit Tools wie VisualVM und YourKit.
- Wenn ein langsamer Anstieg des Heaps die Leistung nicht erheblich verbessert, sollten Sie erwägen, Flüsse, Prozessoren oder andere Aspekte Ihres Systems umzugestalten.
Weitere JVM-Parameter
In der folgenden Tabelle werden weitere JVM-Optionen aufgelistet. Außerdem werden die Werte angegeben, die bei ersten Tests am besten funktioniert haben. Bei den Tests wurden die GC-Aktivität und die Arbeitsspeicherauslastung überwacht und eine sorgfältige Profilerstellung angewandt.
| Parameter | BESCHREIBUNG | JVM-Standard | Empfehlung |
|---|---|---|---|
InitiatingHeapOccupancyPercent |
Die Menge des Heaps, der verwendet wird, bevor ein Markierungszyklus ausgelöst wird | 45 | 35 |
ParallelGCThreads |
Die Anzahl der Threads, die von der GC verwendet werden. Dieser Wert ist begrenzt, um die Gesamtauswirkung auf das System einzuschränken. | 5/8 der Anzahl von vCPUs | 8 |
ConcGCThreads |
Die Anzahl der parallel auszuführenden GC-Threads. Dieser Wert wird erhöht, um begrenzte ParallelGCThreads zu berücksichtigen. | 1/4 des Werts von ParallelGCThreads |
4 |
G1ReservePercent |
Der Prozentsatz des reservierten Arbeitsspeichers, der frei bleiben soll. Dieser Wert wird erhöht, um zu vermeiden, dass der Speicherplatz erschöpft ist, wodurch eine vollständige GC vermieden wird. | 10 | 20 |
UseStringDeduplication |
Gibt an, ob versucht werden soll, Verweise auf identische Zeichenfolgen zu identifizieren und zu deduplizieren. Das Aktivieren dieses Features kann zu Einsparungen beim Arbeitsspeicher führen. | - | Geschenk |
Konfigurieren Sie diese Einstellungen, indem Sie in der NiFi-Datei bootstrap.conf die folgenden Einträge hinzufügen:
java.arg.17=-XX:+UseStringDeduplication
java.arg.18=-XX:G1ReservePercent=20
java.arg.19=-XX:ParallelGCThreads=8
java.arg.20=-XX:ConcGCThreads=4
java.arg.21=-XX:InitiatingHeapOccupancyPercent=35
ZooKeeper
Um die Fehlertoleranz zu verbessern, führen Sie ZooKeeper als Cluster aus. Nutzen Sie diesen Ansatz auch dann, wenn die meisten NiFi-Bereitstellungen eine relativ geringe Last für ZooKeeper darstellen. Aktivieren Sie explizit das Clustering für ZooKeeper. Standardmäßig wird ZooKeeper im Einzelservermodus ausgeführt. Ausführliche Informationen finden Sie im ZooKeeper-Administratorhandbuch unter Clustered (Multi-Server) Setup (Clustereinrichtung (mehrere Server)).
Verwenden Sie mit Ausnahme der Clusteringeinstellungen die Standardwerte für Ihre ZooKeeper-Konfiguration.
Bei einem großen NiFi-Cluster müssen Sie möglicherweise eine größere Anzahl von ZooKeeper-Servern verwenden. Für niedrigere Clustergrößen sind kleinere VM-Größen und verwaltete Datenträger vom Typ SSD Standard ausreichend.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Muazma Zahid | Principal PM Manager
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
Das Material und die Empfehlungen in diesem Dokument stammen aus mehreren Quellen:
- Experimentieren
- Best Practices in Azure
- Communitywissen, bewährte Methoden und Dokumentation zu NiFi
Weitere Informationen finden Sie in den folgenden Ressourcen:
- Apache NiFi-Systemadministratorhandbuch
- Apache NiFi-Mailinglisten
- Cloudera best practices for setting up a high-performance NiFi installation (Cloudera: Bewährte Methoden für das Einrichten einer NiFi-Hochleistungsinstallation)
- Azure Storage Premium: für hohe Leistung konzipiert
- Behandeln von Leistungsproblemen von virtuellen Azure-Computern unter Linux oder Windows
Zugehörige Ressourcen
- Helm-basierte Bereitstellungen für Apache NiFi
- Überwachung mit Azure Data Explorer
- [Hybrid ETL (Extrahieren, Transformieren, Laden) mit Azure Data Factory][Hybrid ETL mit Azure Data Factory]
- [DataOps für das moderne Data Warehouse] [DataOps für das moderne Data Warehouse]
- Data Warehousing und Analysen