Diese Beispielarchitektur basiert auf der Architektur der einfachen Unternehmensintegration. Sie erweitert diese Architektur, um die Integration von Back-End-Systemen von Unternehmen mithilfe von Nachrichtenbrokern und Ereignissen zu veranschaulichen, um eine Entkoppelung der Dienste und damit eine bessere Skalierbarkeit und Zuverlässigkeit zu erreichen. Sie müssen mit diesem Entwurf und den in der Architektur der einfachen Integration verwendeten Komponenten vertraut sein. Er enthält grundlegende Informationen zu den Kernkomponenten, die hier nicht erneut behandelt werden.
Aufbau
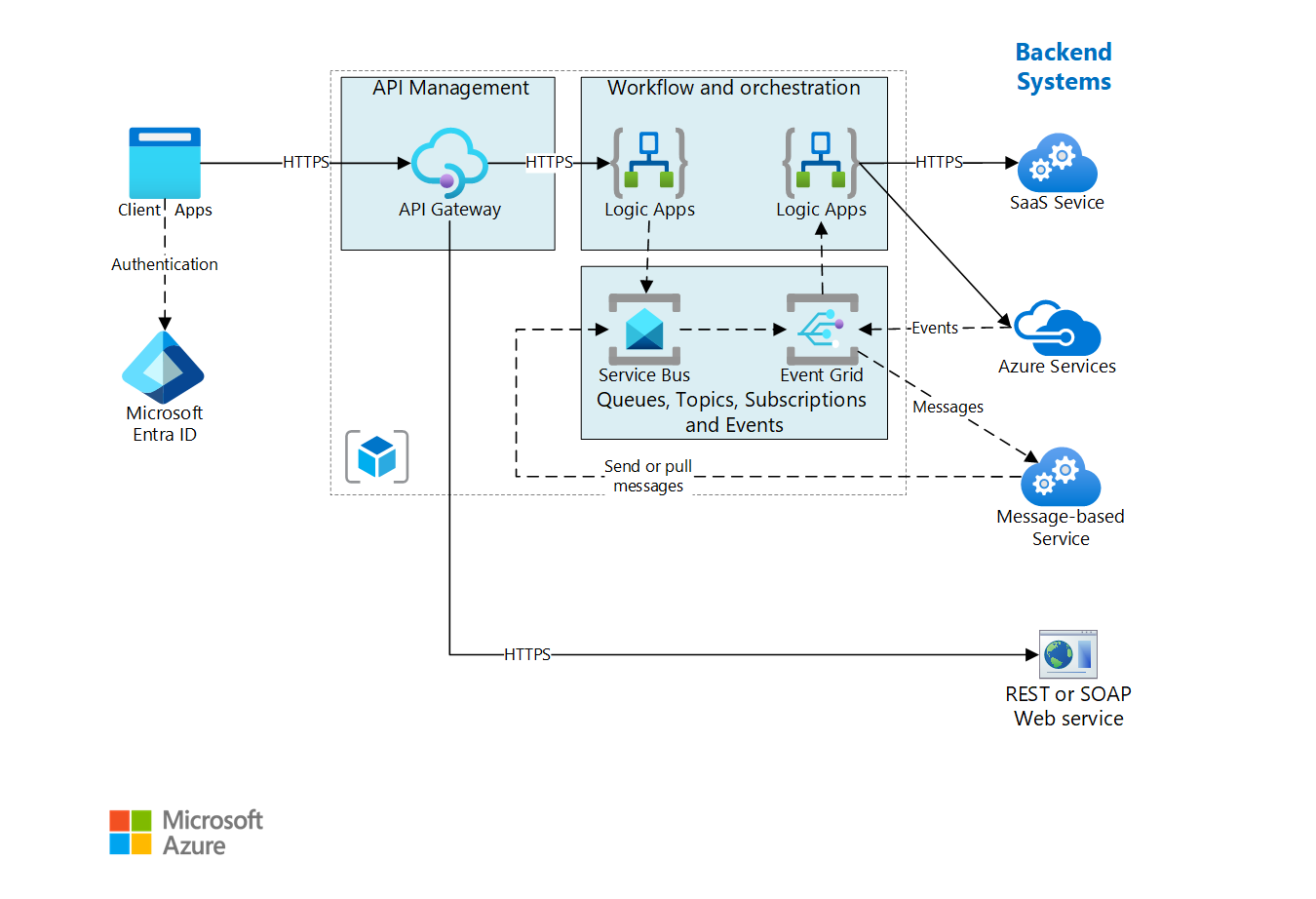
Die Back-End-Systeme, auf die in diesem Entwurf Bezug genommen wird, können SaaS-Systeme (Software-as-a-Service), Azure-Dienste und vorhandene Webdienste in Ihrem Unternehmen enthalten.
Laden Sie eine Visio-Datei mit dieser Architektur herunter.
Workflow
Die hier gezeigte Architektur basiert auf der einfacheren Architektur aus Einfache Unternehmensintegration. Diese Architektur verwendet Logic Apps zum direkten Orchestrieren von Workflows mit Back-End-Systemen und API Management zum Erstellen von API-Katalogen.
Bei der vorliegenden Version der Architektur werden zwei Komponenten hinzugefügt, um das System zuverlässiger und besser skalierbar zu machen:
Azure Service Bus . Service Bus ist ein sicherer und zuverlässiger Nachrichtenbroker.
Azure Event Grid . Event Grid ist ein Ereignisroutingdienst. Er verwendet ein Ereignismodell vom Typ Veröffentlichen/Abonnieren.
Die asynchrone Kommunikation über einen Nachrichtenbroker bietet die folgenden Vorteile gegenüber synchronen Direktaufrufen für Back-End-Dienste:
- Lastenausgleich zur Bewältigung von Workloadspitzen mithilfe des warteschlangenbasierten Lastenausgleichsmusters
- Stellt die Übertragung von Nachrichten an mehrere Consumer mithilfe von Herausgeber-Abonnement-Mustern bereit.
- Zuverlässige Nachverfolgung des Status von Workflows mit langer Laufzeit, die mehrere Schritte oder Anwendungen umfassen
- Entkoppelung von Anwendungen
- Integration in vorhandene nachrichtenbasierte Systeme
- Möglichkeit, Aufgaben einer Warteschlange hinzuzufügen, wenn ein Back-End-System nicht verfügbar ist
Event Grid ermöglicht es den verschiedenen Komponenten im System, auf Ereignisse zu reagieren, sobald diese eintreten. Dadurch sind sie nicht auf Abfragen oder geplante Aufgaben angewiesen. Diese trägt genau wie Nachrichtenwarteschlangen und Themen zur Entkoppelung von Anwendungen und Diensten bei. Eine Anwendung oder ein Dienst kann Ereignisse veröffentlichen, und alle interessierten Abonnenten werden benachrichtigt. Neu Abonnenten können hinzugefügt werden, ohne den Sender zu aktualisieren.
Das Senden von Ereignissen an Event Grid wird von zahlreichen Azure-Diensten unterstützt. So kann beispielsweise eine Logik-App auf ein Ereignis lauschen, wenn einem Blobspeicher neue Dateien hinzugefügt werden. Dieses Muster ermöglicht reaktive Workflows, bei denen das Hochladen einer Datei oder das Platzieren einer Nachricht in einer Warteschlange eine Reihe von Prozessen auslöst. Die Prozesse können parallel oder in einer bestimmten Reihenfolge ausgeführt werden.
Empfehlungen
Die Empfehlungen aus Einfache Unternehmensintegration gelten auch für diese Architektur.
Service Bus
Service Bus verfügt über zwei Übermittlungsmodi: Pull und Push mit Proxy. Bei Verwendung des Pull-Modell fragt der Empfänger kontinuierlich ab, ob neue Nachrichten vorhanden sind. Abrufe können ineffizient sein – insbesondere, wenn Sie über viele Warteschlangen verfügen, die jeweils nur einige wenige Nachrichten empfangen, oder wenn die Nachrichten zeitlich weit auseinander liegen. Bei Verwendung des Push-Modells mit Proxy sendet Service Bus ein Ereignis über Event Grid, wenn neue Nachrichten vorhanden sind. Der Empfänger abonniert das Ereignis. Wenn das Ereignis ausgelöst wird, pullt der Empfänger den nächsten Nachrichtenstapel von Service Bus.
Wenn Sie eine Logik-App erstellen, um Service Bus-Nachrichten zu nutzen, empfiehlt es sich, das Push-Modell mit Proxy mit Event Grid-Integration zu verwenden. Da die Logik-App keine Abfragen an Service Bus richten muss, ist es meistens kosteneffizienter. Weitere Informationen finden Sie in der Übersicht über die Integration von Azure Service Bus in Event Grid. Für Event Grid-Benachrichtigungen wird derzeit der Premium-Tarif von Service Bus benötigt.
Verwenden Sie PeekLock, um auf eine Gruppe von Nachrichten zuzugreifen. Mit PeekLock kann die Logik-App dann Schritte ausführen, um die einzelnen Nachrichten zu überprüfen, bevor sie abgeschlossen oder verworfen werden. Dieser Ansatz schützt vor versehentlichem Nachrichtenverlust.
Event Grid
Wenn ein Event Grid-Trigger ausgelöst wird, bedeutet das, dass mindestens ein Ereignis eingetreten ist. Wenn also beispielsweise eine Logik-App einen Event Grid-Trigger für eine Service Bus-Nachricht erhält, ist davon auszugehen, dass unter Umständen mehrere Nachrichten zur Verarbeitung vorliegen.
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Zuverlässigkeit
Zuverlässigkeit stellt sicher, dass Ihre Anwendung Ihre Verpflichtungen gegenüber den Kunden erfüllen kann. Weitere Informationen finden Sie in der Überblick über die Säule „Zuverlässigkeit“.
- Microsoft Entra ID: Microsoft Entra ID ist eine global verteilte, hochverfügbare SaaS-Plattform (Software-as-a-Service). Details zur garantierten Verfügbarkeit finden Sie in der SLA.
- API Management: API Management kann je nach Geschäftsanforderungen und Kostentoleranz in mehreren hochverfügbaren Konfigurationen bereitgestellt werden. Eine vollständige Übersicht über die Optionen finden Sie unter Sicherstellen der Verfügbarkeit und Zuverlässigkeit von API Management. Details zur garantierten Verfügbarkeit finden Sie auch in der SLA.
- Logic Apps: Für Logic Apps ist auf der Planebene für den Verbrauch georedundanter Speicher verfügbar. Informationen zum Entwerfen einer Lösung für Business Continuity & Disaster Recovery finden Sie in der Anleitung. Details zur garantierten Verfügbarkeit finden Sie auch in der SLA.
- Event Grid: Event Grid-Ressourcendefinitionen für Themen, Systemthemen, Domänen sowie Ereignisabonnements und Ereignisdaten werden automatisch in drei Verfügbarkeitszonen (sofern verfügbar) in der Region repliziert. Wenn in einer der Verfügbarkeitszonen ein Fehler auftritt, erfolgt für Event Grid-Ressourcen ohne Eingreifen des Benutzers ein automatisches Failover auf eine andere Verfügbarkeitszone. Informationen zum Entwerfen einer Notfallwiederherstellungslösung für ein Failover auf eine andere Region finden Sie unter Regionsübergreifende georedundante Notfallwiederherstellung. Details zur garantierten Verfügbarkeit finden Sie auch in der SLA.
- Service Bus: Service Bus Premium unterstützt georedundante Notfallwiederherstellung und Verfügbarkeitszonen. Die Replikation ist für Service Bus Standard verfügbar. Details zur garantierten Verfügbarkeit finden Sie auch in der SLA.
Sicherheit
Sicherheit bietet Schutz vor vorsätzlichen Angriffen und dem Missbrauch Ihrer wertvollen Daten und Systeme. Weitere Informationen finden Sie unter Übersicht über die Säule „Sicherheit“.
Verwenden Sie zum Schützen von Service Bus die Microsoft Entra-Authentifizierung in Kombination mit verwalteten Identitäten. Die Microsoft Entra-Integration für Service Bus-Ressourcen bietet rollenbasierte Zugriffssteuerung (Role-Based Access Control, RBAC) von Azure, mit der Sie den Zugriff eines Clients auf Ressourcen differenziert steuern können. Mit Azure RBAC können einem Sicherheitsprinzipal Berechtigungen erteilt werden. Bei einem Sicherheitsprinzipal kann es sich um einen Benutzer, um eine Gruppe oder um einen Anwendungsdienstprinzipal (in diesem Fall eine verwaltete Identität) handeln.
Wenn Microsoft Entra ID nicht verfügbar ist, können Sie Shared Access Signature (SAS) verwenden. Mit der SAS-Authentifizierung können Sie einem Benutzer Zugriff auf Service Bus-Ressourcen mit spezifischen Rechten gewähren.
Wenn Sie eine Service Bus-Warteschlange oder ein Thema als HTTP-Endpunkt verfügbar machen müssen, beispielsweise zum Veröffentlichen neuer Nachrichten, verwenden Sie API Management zum Sichern der Warteschlange, indem der Endpunkt verfügbar gemacht wird. Anschließend können Sie den Endpunkt mit Zertifikaten oder OAuth-Authentifizierung sichern. Ein Endpunkt lässt sich am einfachsten durch die Verwendung einer Logik-App mit einem Anforderung-/Antwort-HTTP-Trigger als Zwischenstufe schützen.
Der Event Grid-Dienst sichert die Ereignisübermittlung durch einen Validierungscode. Wenn Sie Logic Apps verwenden, um das Ereignis abzurufen, wird die Validierung automatisch ausgeführt. Weitere Informationen finden Sie unter Event Grid – Sicherheit und Authentifizierung.
Netzwerksicherheit
Die Netzwerksicherheit sollte während des gesamten Entwurfs berücksichtigt werden.
- Service Bus Premium kann an einen VNet-Subnetzdienstendpunkt gebunden werden, um den Namespace so zu schützen, dass nur Datenverkehr aus autorisierten virtuellen Netzwerken akzeptiert wird. Verwenden Sie außerdem private Endpunkte, um Ihren VNet-Datenverkehr auf privaten Datenverkehr über Private Link zu beschränken.
- Logic Apps Logic Apps Standard und Premium können so konfiguriert werden, dass eingehender Datenverkehr über private Endpunkte akzeptiert und ausgehender Datenverkehr über die VNET-Integration gesendet wird.
- API Management bietet mehrere Optionen, um den Zugriff auf Ihre API Management-Instanz und APIs über ein virtuelles Azure-Netzwerk zu schützen. Eine ausführliche Beschreibung der Optionen finden Sie in der Dokumentation Verwenden Sie ein virtuelles Netzwerk mit Azure API Management. Private Endpunkte werden ebenfalls unterstützt.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
Im Allgemeinen sollten Sie den Azure-Preisrechner verwenden, um Ihre Kosten zu ermitteln. Hier finden Sie einige weitere Überlegungen dazu.
API Management
Es entstehen Kosten für alle API Management-Instanzen, sobald sie ausgeführt werden. Wenn Sie hochskaliert haben, das entsprechende Leistungsniveau jedoch nicht durchgehend benötigen, können Sie manuell herunterskalieren oder die automatische Skalierung konfigurieren.
Verwenden Sie für Workloads mit geringer Nutzung ggf. die Verbrauchsebene. Dabei handelt es sich um eine kostengünstige, serverlose Option. Die Verbrauchsebene wird pro API-Aufruf in Rechnung gestellt, die anderen Dienstebenen werden hingegen pro Stunde abgerechnet.
Logic Apps
Logic Apps verwendet ein serverloses Modell. Die Abrechnung erfolgt basierend auf Aktionen und Connectorausführung. Weitere Informationen hierzu finden Sie unter Logic Apps – Preise.
Service Bus: Warteschlangen, Themen und Abonnements
Service Bus-Warteschlangen und -Abonnements unterstützen das Pushmodell mit Proxy und das Pullmodell für die Übermittlung von Nachrichten. Beim Pullmodell wird jede Abrufanforderung als Aktion gemessen. Auch bei langen Abrufintervallen von 30 Sekunden (Standardeinstellung) können die Kosten hoch sein. Erwägen Sie die Verwendung des Pushmodells mit Proxy, sofern Sie keine Echtzeitzustellung von Nachrichten benötigen.
Service Bus-Warteschlangen sind in allen Tarifen enthalten (Basic, Standard und Premium). Service Bus-Themen und -Abonnements sind in Standard- und Premium-Tarifen erhältlich. Weitere Informationen finden Sie auf der Azure Service Bus-Preisseite.
Event Grid
Event Grid verwendet ein serverloses Modell. Die Abrechnung erfolgt auf Basis der Anzahl der Vorgänge (Ereignisausführungen). Zu den Vorgängen gehören der Eingang von Ereignissen für Domänen oder Themen, erweiterte Übereinstimmungen, Übermittlungsversuche und Verwaltungsaufrufe. Die Nutzung von bis zu 100.000 Vorgängen ist kostenlos.
Weitere Informationen finden Sie unter Event Grid-Preise.
Weitere Informationen finden Sie im Abschnitt zu Kosten im Microsoft Azure Well-Architected Framework.
Optimaler Betrieb
Die Referenzarchitektur für die einfache Unternehmensintegration enthält Anleitungen zu DevOps-Mustern, die sich an der Säule Optimaler Betrieb des Well-Architected Framework orientieren.
Eine möglichst starke Automatisierung von Wiederherstellungsvorgängen ist ein wesentlicher Bestandteil von „Optimaler Betrieb“. Vor diesem Hintergrund können Sie die Azure-Protokollüberwachung mit Azure Automation kombinieren, um das Failover Ihrer Service Bus-Ressourcen zu automatisieren. Ein Beispiel für Automatisierungslogik zum Initiieren eines Failovers finden Sie im Diagramm in der Dokumentation zum Failoverflow.
Effiziente Leistung
Leistungseffizienz ist die Fähigkeit Ihrer Workload, auf effiziente Weise eine den Anforderungen der Benutzer entsprechende Skalierung auszuführen. Weitere Informationen finden Sie unter Übersicht über die Säule „Leistungseffizienz“.
Mit dem Service Bus-Premium-Tarif lässt sich die Anzahl von Nachrichteneinheiten aufskalieren, um eine höhere Skalierbarkeit zu erreichen. Weitere Informationen zu den Vorteilen des Premium-Tarifs finden Sie in der Dokumentation Service Bus Premium- und Standard-Tarif für Messaging. Informationen zum Konfigurieren der automatischen Skalierung von Messagingeinheiten finden Sie außerdem in der Dokumentation Automatisches Aktualisieren von Messagingeinheiten eines Azure Service Bus-Namespace.
Weitere Empfehlungen für Service Bus finden Sie unter Bewährte Methoden für Leistungsoptimierungen mithilfe von Service Bus Messaging.
Nächste Schritte
Weitere Informationen finden Sie in der Service Bus-Dokumentation:
- Übersicht über die Integration von Azure Service Bus in Event Grid
- Service Bus Premium- und Standard-Preisstufe für Messaging
- Automatisches Aktualisieren von Messagingeinheiten eines Azure Service Bus-Namespace
- Bewährte Methoden für Leistungsoptimierungen mithilfe von Service Bus Messaging