Dieser Artikel enthält Überlegungen zur Verwaltung von Daten in einer Microservices-Architektur. Da jeder Microservice seine eigenen Daten verwaltet, sind Datenintegrität und -konsistenz von entscheidender Bedeutung.
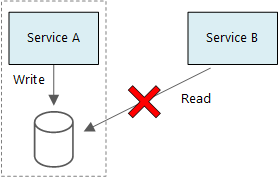
Ein Grundprinzip von Microservices ist die Verwaltung der jeweils eigenen Daten. Zwei Dienste sollten sich nicht den gleichen Datenspeicher teilen. Stattdessen ist jeder Dienst für seinen eigenen privaten Datenspeicher zuständig, und andere Dienste können nicht direkt auf diesen Datenspeicher zugreifen.
Mit dieser Regel wird eine unbeabsichtigte Kopplung von Diensten vermieden, die entstehen kann, wenn Dienste die gleichen zugrunde liegenden Datenschemas nutzen. Eine Änderung des Datenschemas muss für jeden Dienst koordiniert werden, der auf der betroffenen Datenbank basiert. Die Isolierung des Datenspeichers der einzelnen Dienste ermöglicht eine Eingrenzung des Änderungsumfangs, und die Agilität vollständig unabhängiger Bereitstellungen bleibt erhalten. Darüber hinaus kann jeder Microservice über eigene Datenmodelle, Abfragen oder Lese-/Schreibmuster verfügen. Bei Verwendung eines gemeinsamen Datenspeichers können die einzelnen Teams den Datenspeicher nicht mehr uneingeschränkt für ihren jeweiligen Dienst optimieren.
Dieses Konzept führt ganz natürlich zu Polyglot Persistence (also zur Verwendung mehrerer Datenspeichertechnologien in einer einzelnen Anwendung). Ein Dienst benötigt möglicherweise die Schema-on-Read-Funktionen einer Dokumentdatenbank. Ein anderer benötigt unter Umständen die referenzielle Integrität eines Managementsystems für relationale Datenbanken (Relational Database Management System, RDBMS). Jedes Team kann seinen Dienst optimal konfigurieren.
Hinweis
Dienste können ohne Weiteres den gleichen physischen Datenbankserver verwenden. Problematisch wird es, wenn Dienste das gleiche Schema verwenden oder Lese-/Schreibvorgänge für die gleiche Gruppe von Datenbanktabellen ausführen.
Herausforderungen
Dieses Konzept der verteilten Datenverwaltung ist mit gewissen Herausforderungen verbunden. Da wäre zum einen eine mögliche Redundanz in den Datenspeichern, die dazu führt, dass die gleichen Datenelemente an mehreren Orten vorhanden sind. So kann es beispielsweise vorkommen, dass Daten als Teil einer Transaktion und anschließend anderswo zur Analyse, Berichterstellung oder Archivierung gespeichert werden. Duplizierte oder partitionierte Daten können zu Problemen mit der Integrität und Konsistenz der Daten führen. Wenn sich Datenbeziehungen über mehrere Dienste erstrecken, lassen sich die Beziehungen nicht mithilfe herkömmlicher Datenverwaltungstechniken erzwingen.
Bei der herkömmlichen Datenmodellierung wird die Regel „ein Fakt an einem Ort“ angewandt – jede Entität liegt also genau einmal im Schema vor. Andere Entitäten können zwar Verweise auf die Entität enthalten, sie darf jedoch nicht dupliziert werden. Das herkömmliche Konzept hat natürlich den Vorteil, dass Aktualisierungen an einem einzelnen Ort durchgeführt und somit Probleme mit der Datenkonsistenz vermieden werden. In einer Microservices-Architektur müssen Sie sich Gedanken zur dienstübergreifenden Verteilung von Aktualisierungen machen und sich überlegen, wie Sie letztlich für Konsistenz sorgen können, wenn sich Daten an mehreren Orten ohne starke Konsistenz befinden.
Datenverwaltungskonzepte
In Ermangelung eines Allzweckkonzepts finden Sie im Anschluss einige allgemeine Richtlinien für die Datenverwaltung in einer Microservices-Architektur.
Definieren Sie die erforderliche Konsistenzstufe pro Komponente, und bevorzugen Sie ggf. eine einheitliche Konsistenz. Überlegen Sie sich, wo Sie im System starke Konsistenz oder ACID-Transaktionen benötigen und wo die letztliche Konsistenz ausreicht. Unter Verwenden von taktischem DDD zum Entwerfen von Mikroservices finden Sie weitere Komponentenanleitungen.
Wenn Sie starke Konsistenz gewährleisten müssen, kann ein einzelner Dienst als gültige Quelle für eine bestimmte Entität fungieren, die über eine API verfügbar gemacht wird. Andere Dienste können über ihre eigene Kopie der Daten oder über eine Teilmenge der Daten verfügen, die zwar letztlich mit den Masterdaten konsistent ist, aber nicht als gültige Quelle betrachtet wird. Stellen Sie sich zum Beispiel ein E-Commerce-System mit einem Kundenbestelldienst und einem Empfehlungsdienst vor. Der Empfehlungsdienst lauscht zwar unter Umständen auf Ereignisse aus dem Bestelldienst, sollte ein Kunde jedoch eine Rückerstattung beantragen, ist es der Bestelldienst (und nicht der Empfehlungsdienst), der über den vollständigen Transaktionsverlauf verfügt.
Verwenden Sie für Transaktionen Muster wie Scheduler-Agent-Supervisor und Kompensierende Transaktion, um Daten über mehrere Dienste hinweg konsistent zu halten. Gegebenenfalls muss zur Erfassung des Zustands einer Arbeitseinheit, die mehrere Dienste umfasst, ein zusätzliches Datenelement gespeichert werden, um Teilfehler zwischen mehreren Diensten zu vermeiden. Speichern Sie hierzu beispielsweise ein Arbeitselement während der Ausführung einer mehrstufigen Transaktion in einer permanenten Warteschlange.
Speichern Sie nur die Daten, die ein Dienst benötigt. Ein Dienst benötigt möglicherweise nur einen Teil der Informationen zu einer Domänenentität. Im Rahmen des Versandkontexts müssen wir beispielsweise wissen, welcher Kunde zu einer bestimmten Lieferung gehört. Die Rechnungsadresse des Kunden wird in diesem Kontext allerdings nicht benötigt und stattdessen im Rahmen des Kontokontexts verwaltet. Hier kann es hilfreich sein, sich Gedanken zur Domäne zu machen und einen DDD-Ansatz zu verwenden.
Überlegen Sie, ob Ihre Dienste kohärent und lose gekoppelt sind. Wenn zwei Dienste kontinuierlich Informationen austauschen, führt dies zu einer intensiven API-Kommunikation. In diesem Fall empfiehlt es sich unter Umständen, die Dienstgrenzen neu zu definieren, indem Sie zwei Dienste zusammenführen oder ihre Funktionen umgestalten.
Verwenden Sie einen ereignisgesteuerten Architekturstil. Bei diesem Architekturstil veröffentlicht ein Dienst ein Ereignis, wenn Änderungen an seinen öffentlichen Modellen oder Entitäten vorgenommen werden. Diese Ereignisse können von Diensten abonniert werden, für die sie interessant sind. So kann beispielsweise ein anderer Dienst auf der Grundlage der Ereignisse eine materialisierte Sicht der Daten erstellen, die besser für Abfragen geeignet ist.
Ein Dienst, der Ereignisse besitzt, sollte ein Schema veröffentlichen, das die Automatisierung der Serialisierung und Deserialisierung der Ereignisse ermöglicht, um eine enge Kopplung zwischen Herausgebern und Abonnenten zu vermeiden. Erwägen Sie die Verwendung eines JSON-Schemas oder eines Frameworks wie Microsoft Bond, Protobuf oder Avro.
Da sich Ereignisse bei intensiver Nutzung als Engpass für das System erweisen können, empfiehlt es sich ggf., die Gesamtlast mittels Aggregation oder Batchverarbeitung zu verringern.
Beispiel: Auswählen von Datenspeichern für die Drohnenlieferungsanwendung
In den vorherigen Artikeln dieser Reihe wird ein Drohnenlieferdienst als Beispiel herangezogen. Weitere Informationen zum Szenario sowie die entsprechende Referenzimplementierung finden Sie hier. Dieses Beispiel eignet sich ideal für die Flugzeug- sowie die Luft- und Raumfahrtindustrie.
Diese Anwendung definiert mehrere Microservices für die Planung von Lieferungen per Drohne. Wenn ein Benutzer einen Termin für eine neue Lieferung festlegt, enthält die Clientanforderung sowohl Informationen zur Lieferung (etwa den Abhol- und den Zielort) als auch Informationen zum Paket (etwa Größe und Gewicht). Diese Informationen definieren eine Arbeitseinheit.
Für die verschiedenen Back-End-Dienste sind unterschiedliche Teilinformationen aus der Anforderung interessant, und sie verfügen über unterschiedliche Lese- und Schreibprofile.
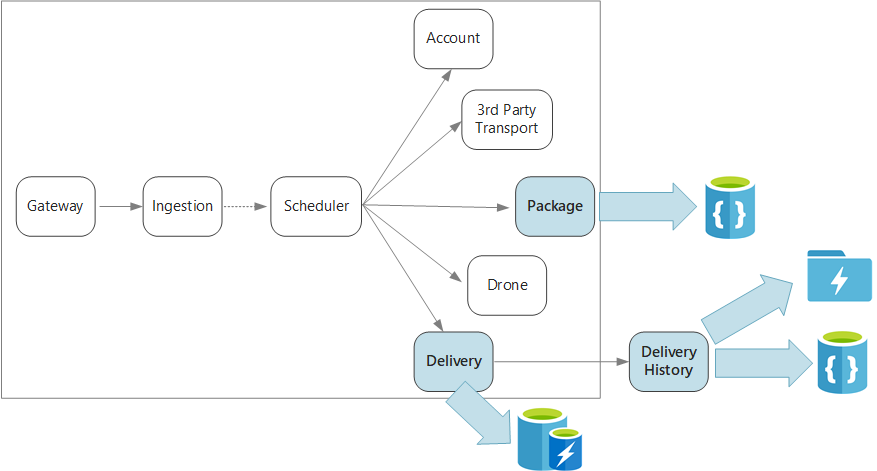
Dienst „Delivery“ (Lieferung)
Der Dienst „Delivery“ speichert Informationen zu jeder Lieferung, die derzeit geplant ist oder durchgeführt wird. Er lauscht auf Ereignisse von den Drohnen und verfolgt den Status aktiver Lieferungen. Darüber hinaus sendet er Domänenereignisse mit Lieferstatusupdates.
Es ist davon auszugehen, dass Benutzer mehrmals den Status einer Lieferung prüfen, während sie auf ihr Paket warten. Der Dienst „Delivery“ benötigt daher einen Datenspeicher, bei dem Durchsatz (Lesen und Schreiben) einen höheren Stellenwert hat als langfristige Speicherung. Darüber hinaus führt der Dienst „Delivery“ keine komplexen Abfragen oder Analysen durch, sondern ruft einfach nur den aktuellen Status für eine bestimmte Lieferung ab. Das Team für den Dienst „Delivery“ entscheidet sich aufgrund der hohen Leistung bei Lese- und Schreibvorgängen für Azure Cache for Redis. Die in Redis gespeicherten Informationen sind relativ kurzlebig. Nach Abschluss der Lieferung wird der Dienst „Delivery History“ (Lieferverlauf) zum System of Record.
Dienst „Delivery History“
Der Dienst „Delivery History“ lauscht auf Lieferstatusereignisse des Diensts „Delivery“. Diese Daten werden langfristig speichert. Für diese Verlaufsdaten sind zwei Anwendungsfälle mit jeweils unterschiedlichen Datenspeicheranforderungen denkbar.
Im ersten Szenario sollen die Daten für die Datenanalyse aggregiert werden, um geschäftliche Abläufe zu optimieren oder die Servicequalität zu verbessern. Beachten Sie, dass die eigentliche Datenanalyse nicht vom Dienst „Delivery History“ durchgeführt wird. Dieser ist nur für die Erfassung und Speicherung der Daten zuständig. In diesem Szenario muss der Speicher für die Analyse eines umfangreichen Datensatzes optimiert sein und ein Schema-on-Read-Konzept verwenden, um verschiedene Datenquellen verarbeiten zu können. Azure Data Lake Store ist eine gute Wahl für dieses Szenario. Bei Data Lake Store handelt es sich um ein mit HDFS (Hadoop Distributed File System) kompatibles, leistungsoptimiertes Apache Hadoop-Dateisystem für Szenarien mit anspruchsvollen Datenanalysen.
Im anderen Szenario soll Benutzern die Möglichkeit gegeben werden, den Verlauf einer Lieferung nach Abschluss der Lieferung nachzuvollziehen. Für dieses Szenario ist Azure Data Lake nicht optimiert. Zur Erzielung einer optimalen Leistung empfiehlt Microsoft, Zeitreihendaten in Data Lake in nach Datum partitionierten Ordnern zu speichern. (Siehe Optimieren der Leistung von Azure Data Lake Store.) Für die ID-basierte Suche nach einzelnen Datensätzen ist diese Struktur jedoch nicht optimal. Sollte Ihnen der Zeitstempel nicht bekannt sein, muss bei einer ID-basierten Suche die gesamte Sammlung durchsucht werden. Aus diesem Grund speichert der Dienst „Delivery History“ auch einen Teil der Verlaufsdaten in Azure Cosmos DB, um ein schnelleres Nachschlagen zu ermöglichen. Die Datensätze müssen nicht unbegrenzt lange in Azure Cosmos DB gespeichert werden. Ältere Lieferungen können archiviert werden – beispielsweise nach einem Monat. Hierzu kann gelegentlich ein Batchvorgang ausgeführt werden. Durch die Archivierung älterer Daten können die Kosten für Cosmos DB gesenkt werden, während die Daten weiterhin für historische Berichte auf der Grundlage des Data Lake verfügbar bleiben.
Dienst „Package“ (Paket)
Der Dienst „Package“ speichert Informationen zu allen Paketen. Für Pakete gelten folgende Speicheranforderungen:
- Langfristige Speicherung
- Hoher Schreibdurchsatz zur Bewältigung einer hohen Anzahl von Paketen
- Unterstützung einfacher Abfragen mit Paket-ID. Keine komplexen Joins oder Anforderungen für die referenzielle Integrität.
Da es sich bei den Paketdaten nicht um relationale Daten handelt, eignet sich eine objektorientierte Dokumentdatenbank, und Azure Cosmos DB kann mithilfe von Shardsammlungen einen hohen Durchsatz erreichen. Das für den Dienst „Package“ zuständige Team ist mit dem MEAN-Stack (MongoDB, Express.js, AngularJS und Node.js) vertraut und wählt daher die MongoDB-API für Azure Cosmos DB. Dadurch kann das Team auf die bereits gesammelten Erfahrungen mit MongoDB zurückgreifen und gleichzeitig von Azure Cosmos DB (einem verwalteten Azure-Dienst) profitieren.
Nächste Schritte
Informieren Sie sich über Entwurfsmuster, die Ihnen helfen können, einige häufige Herausforderungen in einer Microservicearchitektur zu verringern.