Koordinieren Sie die von einer Sammlung zusammenarbeitender Instanzen ausgeführten Aktionen in einer verteilten Anwendung, indem Sie eine Instanz als übergeordnete Instanz auswählen, die die Verantwortung für die Verwaltung der anderen übernimmt. Dies kann dazu beitragen, sicherzustellen, dass Instanzen nicht in Konflikt miteinander, um freigegebene Ressourcen oder versehentlich auch mit der Arbeit anderer Instanzen stehen.
Kontext und Problem
Eine typische Cloudanwendung weist viele Aufgaben auf, die koordiniert ausgeführt werden. Bei diesen Aufgaben kann es sich um Instanzen handeln, die alle denselben Code ausführen und auf dieselben Ressourcen zugreifen möchten, oder sie können parallel gemeinsam an Bestandteilen einer komplexen Berechnung arbeiten.
Zu einem großen Teil werden die Taskinstanzen möglicherweise separat ausgeführt, es kann jedoch auch notwendig sein, die Aktionen der einzelnen Instanzen zu koordinieren, um sicherzustellen, dass sie nicht in Konflikt miteinander, um freigegebene Ressourcen oder versehentlich auch mit der Arbeit anderer Instanzen stehen.
Zum Beispiel:
- In einem cloudbasierten System, in dem eine horizontale Skalierung implementiert ist, können mehrere Instanzen desselben Tasks gleichzeitig ausgeführt werden, wobei jede Instanz einem anderen Benutzer zugeordnet ist. Wenn diese Instanzen in eine freigegebene Ressource schreiben, müssen ihre Aktionen koordiniert werden, um zu verhindern, dass jede Instanz die von der anderen vorgenommenen Änderungen überschreibt.
- Wenn die Aufgaben einzelne Elemente einer komplexen Berechnung parallel ausführen, müssen die Ergebnisse aggregiert werden, wenn alle abgeschlossen sind.
Alle Taskinstanzen sind gleichrangig, daher gibt es keine natürliche übergeordnete Instanz, die als Koordinator oder Aggregator fungieren kann.
Lösung
Eine einzelne Aufgabeninstanz sollte zur übergeordneten Instanz gewählt werden. Diese Instanz koordiniert die Aktionen der anderen untergeordneten Taskinstanzen. Wenn alle Taskinstanzen denselben Code ausführen, kann jede als übergeordnete Instanz fungieren. Daher muss das Wahlverfahren sorgfältig gehandhabt werden, um zu verhindern, dass zwei oder mehr Instanzen gleichzeitig die Führungsposition einnehmen.
Das System muss einen stabilen Mechanismus für die Auswahl der übergeordneten Instanz bereitstellen. Diese Methode muss mit Ereignissen wie Netzwerkausfällen oder Prozessfehlern umgehen können. In vielen Lösungen überwachen die untergeordneten Aufgabeninstanzen die übergeordnete durch eine Taktmethode oder durch Polls. Wenn die festgelegte übergeordnete Instanz unerwartet beendet wird oder ein Netzwerkausfall dafür sorgt, dass sie nicht verfügbar ist, müssen die anderen Instanzen eine neue übergeordnete Instanz wählen.
Für die Wahl einer übergeordneten Instanz zwischen mehreren in einer verteilten Umgebung gibt es mehrere Strategien, einschließlich:
- Wettbewerb um den Abruf eines verteilten gegenseitigen Ausschlusses. Die erste Aufgabeninstanz, die den gegenseitigen Ausschluss abruft, ist die übergeordnete Instanz. Das System muss jedoch sicherstellen, dass beim Beenden oder Trennen der übergeordneten Instanz vom restlichen System der gegenseitige Ausschluss aufgehoben wird, sodass eine andere Aufgabeninstanz die übergeordnete Instanz werden kann. Diese Strategie wird im folgenden Beispiel demonstriert.
- Implementieren eines der verbreiteten Algorithmen für die Wahl der übergeordneten Instanz, z. B. Bullyalgorithmus, Floß-Konsensalgorithmus oder Ringalgorithmus. Bei diesen Algorithmen wird davon ausgegangen, dass jeder Kandidat im Wahlverfahren eine eindeutige ID aufweist und zuverlässig mit den anderen Kandidaten kommunizieren kann.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Die Wahl einer übergeordneten Instanz sollte gegenüber vorübergehenden und permanenten Fehlern robust sein.
- Es muss möglich sein, zu erkennen, wenn die übergeordnete Instanz einen Fehler aufweist oder anderweitig nicht mehr verfügbar ist, z. B. aufgrund eines Kommunikationsfehlers. Wie schnell eine Erkennung benötigt wird, ist systemabhängig. Einige Systeme funktionieren möglicherweise für kurze Zeit ohne übergeordnete Instanz. In dieser Zeit kann ein vorübergehender Fehler behoben werden. In anderen Fällen kann es erforderlich sein, den Ausfall der übergeordneten Instanz sofort zu erkennen und eine neue Wahl auszulösen.
- In einem System, in dem eine automatische horizontale Skalierung implementiert ist, kann die übergeordnete Instanz möglicherweise beendet werden, wenn das System zurückskaliert und einige der Verarbeitungsressourcen herunterfährt.
- Mit der Verwendung eines freigegebenen, nicht verteilten gegenseitigen Ausschlusses wird eine Abhängigkeit von dem externen Dienst, der den gegenseitigen Ausschluss bereitstellt, eingeführt. Der Dienst stellt einen Single Point of Failure dar. Wenn er aus irgendeinem Grund nicht verfügbar ist, kann das System keine übergeordnete Instanz wählen.
- Die Verwendung eines einzelnen dedizierten Prozesses als übergeordnete Instanz ist ein einfaches Verfahren. Wenn bei dem Verfahren jedoch ein Fehler auftritt, kann es während des Neustarts zu einer erheblichen Verzögerung kommen. Die resultierende Latenz kann die Leistung und die Antwortzeiten anderer Prozesse beeinträchtigen, wenn sie zum Koordinieren eines Vorgangs auf die übergeordnete Instanz warten.
- Die größte Flexibilität für die Feinabstimmung und Optimierung des Codes ist bei der manuellen Implementierung eines der Wahlalgorithmen für die übergeordnete Instanz gegeben.
- Vermeiden Sie es, die übergeordnete Instanz zu einem Engpass im System zu machen. Die übergeordnete Instanz dient zum Koordinieren der Arbeit der untergeordneten Aufgaben und muss nicht unbedingt selbst an dieser Arbeit teilnehmen – obwohl dies möglich sein sollte, wenn die Aufgabe nicht zur übergeordneten Instanz gewählt wurde.
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn die Aufgaben in einer verteilten Anwendung wie einer in der Cloud gehosteten Lösung eine sorgfältige Koordination erfordern und keine natürliche übergeordnete Instanz besteht.
Dieses Muster ist in folgenden Fällen möglicherweise nicht geeignet:
- Es gibt eine natürliche übergeordnete Instanz oder einen dedizierten Prozess, der immer die Rolle der übergeordneten Instanz übernehmen kann. Beispielsweise kann es möglich sein, einen Singleton-Prozess zu implementieren, der die Aufgabeninstanzen koordiniert. Wenn bei diesem Prozess ein Fehler auftritt oder seine Integrität beeinträchtigt wird, kann das System ihn herunterfahren und neu starten.
- Die Koordination zwischen Aufgaben kann mithilfe einer weniger aufwendigen Methode erreicht werden. Wenn beispielsweise mehrere Aufgabeninstanzen einfach einen koordinierten Zugriff auf eine freigegebene Ressource benötigen, ist eine optimistische oder pessimistische Sperrung zum Steuern des Zugriffs eine bessere Lösung.
- Eine Drittanbieterlösung, wie Apache Zookeeper, kann eine effizientere Lösung sein.
Workloadentwurf
Ein Architekt sollte evaluieren, wie das Leader Election-Pattern im Design seines Workloads verwendet werden kann, um die Ziele und Prinzipien zu erreichen, die in den Azure Well-Architected Framework-Säulen behandelt werden. Zum Beispiel:
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Zuverlässigkeitsdesignentscheidungen tragen dazu bei, dass Ihre Workload ausfallsicher wird und dass sie nach einem Ausfall wieder in einen voll funktionsfähigen Zustand zurückkehrt. | Dieses Muster mildert die Auswirkungen von Knotenfehlfunktionen durch eine zuverlässige Umleitung der Arbeit. Außerdem wird ein Failover über Konsensalgorithmen implementiert, wenn ein Leader ausfällt. - RE:05 Redundanz - RE:07 Selbstreparatur |
Berücksichtigen Sie wie bei jeder Designentscheidung alle Kompromisse im Hinblick auf die Ziele der anderen Säulen, die mit diesem Muster eingeführt werden könnten.
Beispiel
Das Beispiel von Leader Election auf GitHub zeigt, wie ein Lease auf einem Azure-Storage-Blob verwendet werden kann, um einen Mechanismus für die Implementierung eines gemeinsamen, verteilten Mutex bereitzustellen. Dieser Mutex kann verwendet werden, um einen Anführer unter einer Gruppe verfügbarer Worker-Instanzen zu wählen. Die erste Instanz, die die Lease erwirbt, wird zum Leader gewählt und bleibt es, bis sie die Lease auflöst oder nicht in der Lage ist, die Lease zu erneuern. Andere Arbeitsinstanzen können den Blob-Lease weiter überwachen, falls der Leader nicht mehr verfügbar ist.
Eine Bloblease ist eine exklusive Schreibsperre auf ein Blob. Ein einzelnes Blob kann jeweils nur einer Lease unterliegen. Eine Worker-Instanz kann eine Lease für einen bestimmten Blob anfordern und erhält diese Lease, wenn keine andere Worker-Instanz eine Lease für denselben Blob besitzt. Andernfalls wird die Anfrage eine Ausnahme auslösen.
Um zu vermeiden, dass eine fehlerhafte Leader-Instanz die Lease auf unbestimmte Zeit behält, geben Sie eine Lebensdauer für die Lease an. Wenn diese abläuft, ist die Lease wieder verfügbar. Solange eine Instanz die Lease innehat, kann sie jedoch eine Verlängerung der Lease beantragen, die ihr dann für einen weiteren Zeitraum gewährt wird. Die führende Instanz kann diesen Prozess ständig wiederholen, wenn sie die Lease behalten will. Weitere Informationen zum Leasen eines Blobs finden Sie unter Leasen eines Blobs (REST-API).
Die Klasse BlobDistributedMutex im folgenden C#-Beispiel enthält die Methode RunTaskWhenMutexAcquired, mit der eine Worker-Instanz versuchen kann, einen Lease für einen bestimmten Blob zu erwerben. Die Details des Blobs (Name, Container und Speicherkonto) werden in den Konstruktor in einem BlobSettings-Objekt übergeben, wenn das BlobDistributedMutex-Objekt erstellt wird (eine einfache Struktur, die im Beispielcode enthalten ist). Der Konstruktor akzeptiert auch eine Task, die auf den Code verweist, den die Worker-Instanz ausführen soll, wenn sie erfolgreich die Lease für den Blob erwirbt und zum Leader gewählt wird. Beachten Sie, dass der Code für die Verarbeitung der Details auf niedriger Ebene zum Abrufen der Lease in der separaten Hilfsklasse BlobLeaseManager implementiert wird.
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
Die RunTaskWhenMutexAcquired-Methode im obigen Codebeispiel ruft die im folgenden Codebeispiel gezeigte RunTaskWhenBlobLeaseAcquired-Methode auf, um die Lease abzurufen. Die RunTaskWhenBlobLeaseAcquired-Methode wird asynchron ausgeführt. Wenn die Lease erfolgreich erworben wurde, ist die Arbeitsinstanz zum Anführer gewählt worden. Die Aufgabe des Delegaten taskToRunWhenLeaseAcquired ist es, die Arbeit auszuführen, die die anderen Arbeitsinstanzen koordinieren. Wenn die Lease nicht erworben wird, wurde eine andere Arbeiterinstanz zum Anführer gewählt und die aktuelle Arbeiterinstanz bleibt untergeordnet. Beachten Sie, dass die TryAcquireLeaseOrWait-Methode eine Hilfsmethode ist, die zum Abrufen der Lease das BlobLeaseManager-Objekt verwendet.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
Die von der übergeordneten Instanz gestartete Aufgabe wird ebenfalls asynchron ausgeführt. Während der Ausführung dieser Aufgabe versucht die im folgenden Codebeispiel gezeigte RunTaskWhenBlobLeaseAcquired-Methode in regelmäßigen Abständen, die Lease zu verlängern. Dies trägt dazu bei, dass die Arbeiterinstanz die Führung behält. In der Beispiellösung ist die Zeitspanne zwischen den Erneuerungsanfragen kürzer als die für die Dauer der Lease angegebene Zeit, um zu verhindern, dass eine andere Arbeiterinstanz zum Anführer gewählt wird. Wenn die Erneuerung aus irgendeinem Grund fehlschlägt, wird die führerspezifische Aufgabe abgebrochen.
Wenn die Lease nicht verlängert wird oder die Aufgabe abgebrochen wird (möglicherweise als Folge des Herunterfahrens der Arbeitsinstanz), wird die Lease freigegeben. Zu diesem Zeitpunkt kann diese oder eine andere Arbeiterinstanz zum Anführer gewählt werden. Der Codeausschnitt unten zeigt diesen Teil des Vorgangs.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
Die KeepRenewingLease-Methode ist eine weitere Hilfsmethode, die das BlobLeaseManager-Objekt zum Erneuern der Lease verwendet. Die CancelAllWhenAnyCompletes-Methode bricht die als die ersten beiden Parameter angegebenen Aufgaben ab. Das folgende Diagramm veranschaulicht, wie mit der BlobDistributedMutex-Klasse eine übergeordnete Instanz gewählt und eine Aufgabe ausgeführt wird, die Vorgänge koordiniert.
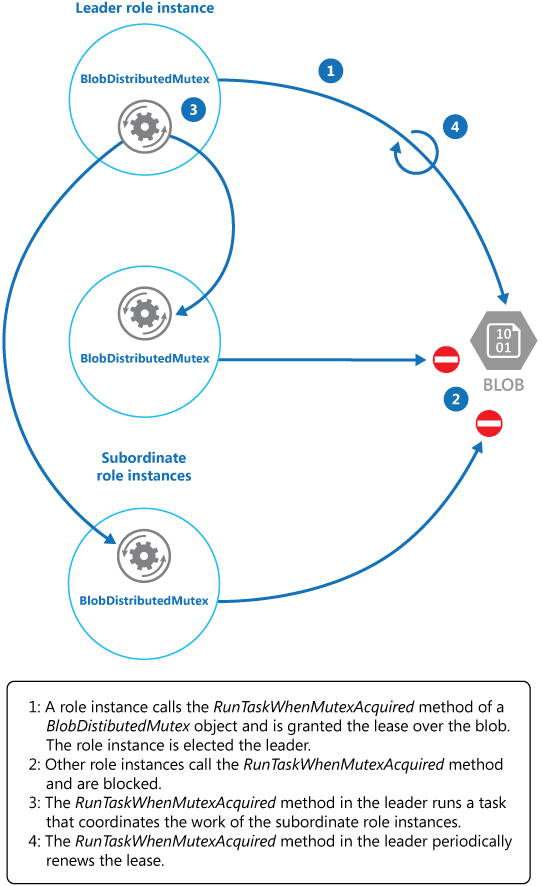
Das folgende Codebeispiel zeigt, wie die Klasse BlobDistributedMutex innerhalb einer Worker-Instanz verwendet wird. Dieser Code erwirbt einen Lease über einen Blob mit dem Namen MyLeaderCoordinatorTask im Lease-Container Azure Blob Storage und legt fest, dass der in der Methode MyLeaderCoordinatorTask definierte Code ausgeführt werden soll, wenn die Worker-Instanz zum Leader gewählt wird.
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
Beachten Sie die folgenden Punkte bezüglich der Beispiellösung:
- Das Blob ist potenziell ein Single Point of Failure. Wenn der Blob-Dienst nicht mehr verfügbar oder nicht mehr erreichbar ist, kann der Leader die Lease nicht mehr erneuern und keine andere Worker-Instanz kann die Lease übernehmen. In diesem Fall kann keine Arbeiterinstanz als Anführerin fungieren. Der Blob-Dienst ist jedoch auf Stabilität ausgelegt, daher wird ein vollständiger Ausfall des Blob-Diensts als sehr unwahrscheinlich betrachtet.
- Wenn die vom Anführer durchgeführte Aufgabe ins Stocken gerät, kann der Anführer die Lease weiter verlängern, wodurch verhindert wird, dass eine andere Arbeiterinstanz die Lease erwirbt und die Anführerposition übernimmt, um die Aufgaben zu koordinieren. In der Praxis sollte die Integrität der übergeordneten Instanz häufig überprüft werden.
- Der Wahlvorgang ist nicht deterministisch. Sie können keine Vermutungen darüber anstellen, welche Arbeiterinstanz den Blob-Leasingvertrag erwerben und der Anführer werden wird.
- Das als Ziel für die Bloblease verwendete Blob sollte nicht für andere Zwecke verwendet werden. Wenn eine Arbeitsinstanz versucht, Daten in diesem Blob zu speichern, kann auf diese Daten nur zugegriffen werden, wenn die Arbeitsinstanz der Leader ist und die Blob-Lease hält.
Nächste Schritte
Die folgenden Richtlinien sind unter Umständen beim Implementieren dieses Musters ebenfalls relevant:
- Dieses Muster verfügt über eine herunterladbare Beispielanwendung.
- Leitfaden für die automatische Skalierung. Instanzen der Aufgabenhosts können gestartet und beendet werden, wenn sich die Auslastung Anwendung ändert. Automatische Skalierung kann dabei helfen, den Durchsatz und die Leistung während Zeiten maximaler Verarbeitung beizubehalten.
- Das aufgabenbasierte asynchrone Muster.
- Ein Beispiel zur Veranschaulichung des Bullyalgorithmus
- Ein Beispiel zur Veranschaulichung des Ringalgorithmus
- Apache Curator, eine Clientbibliothek für Apache ZooKeeper
- Der Artikel Leasen eines Blobs (REST-API) bei MSDN