Erhöhen Sie die Ausfallsicherheit durch Replizieren Ihres Log Analytics-Arbeitsbereichs über Regionen hinweg (Vorschau)
Die regionsübergreifende Replizierung Ihres Log Analytics-Arbeitsbereichs erhöht die Ausfallsicherheit, da Sie im Falle eines regionalen Ausfalls auf den replizierten Arbeitsbereich umschalten und den Betrieb fortsetzen können. In diesem Artikel wird erläutert, wie die Replizierung von Log Analytics-Arbeitsbereichen funktioniert, wie Sie Ihren Arbeitsbereich replizieren, wie Sie hin- und herschalten und wie Sie entscheiden, wann Sie zwischen Ihren replizierten Arbeitsbereichen wechseln.
Das folgende Video gibt einen kurzen Überblick über die Funktionsweise der Log Analytics-Arbeitsbereichsreplikation:
Wichtig
Obwohl wir manchmal den Begriff „Failover“ verwenden, z. B. im API-Aufruf, wird Failover auch allgemein zur Beschreibung eines automatischen Prozesses verwendet. Daher wird in diesem Artikel der Begriff „Switchover“ verwendet, um zu betonen, dass der Wechsel zum replizierten Arbeitsbereich eine Aktion ist, die Sie manuell auslösen.
Erforderliche Berechtigungen
| Aktion | Erforderliche Berechtigungen |
|---|---|
| Aktivieren der Arbeitsbereichreplikation | Berechtigungen vom Typ Microsoft.OperationalInsights/workspaces/write und Microsoft.Insights/dataCollectionEndpoints/write, wie sie z. B. von der integrierten Rolle „Mitwirkender an der Überwachung“ bereitgestellt werden |
| Wechseln und Zurückwechseln im Rahmen des Switchovers (Auslösen von Failover und Failback) | Berechtigungen vom Typ Microsoft.OperationalInsights/locations/workspaces/failover, Microsoft.OperationalInsights/workspaces/failback und Microsoft.Insights/dataCollectionEndpoints/triggerFailover/action, wie sie z. B. von der integrierten Rolle „Mitwirkender an der Überwachung“ bereitgestellt werden |
| Überprüfen des Arbeitsbereichsstatus | Berechtigungen vom Typ Microsoft.OperationalInsights/workspaces/read für den Log Analytics-Arbeitsbereich, wie sie beispielsweise von der integrierten Rolle „Mitwirkender an der Überwachung“ bereitgestellt werden |
Funktionsweise der Log Analytics-Arbeitsbereichreplikation
Ihr ursprünglicher Arbeitsbereich und die zugehörige Region werden als primär bezeichnet. Der replizierte Arbeitsbereich und die alternative Region werden als sekundär bezeichnet.
Der Prozess der Arbeitsbereichsreplikation erstellt eine Instanz Ihres Arbeitsbereichs in der sekundären Region. Der Prozess erstellt den sekundären Arbeitsbereich mit der gleichen Konfiguration wie Ihren primären Arbeitsbereich, und Azure Monitor aktualisiert den sekundären Arbeitsbereich automatisch mit allen zukünftigen Änderungen, die Sie an der Konfiguration Ihres primären Arbeitsbereichs vornehmen.
Der sekundäre Arbeitsbereich ist ein „Schatten“-Arbeitsbereich, der nur zu Ausfallsicherheitszwecken dient. Der sekundäre Arbeitsbereich wird im Azure-Portal nicht angezeigt, und Sie können ihn nicht direkt verwalten oder darauf zugreifen.
Wenn Sie die Arbeitsbereichsreplikation aktivieren, sendet Azure Monitor neue Protokolle, die in Ihren primären Arbeitsbereich aufgenommen werden, auch an Ihre sekundäre Region. Protokolle, die Sie in den Arbeitsbereich aufnehmen, bevor Sie die Replikation des Arbeitsbereichs aktivieren, werden nicht kopiert.
Wenn Ihre primäre Region von einem Ausfall betroffen ist, können Sie umschalten und alle Erfassungs- und Abfrageanforderungen an Ihre sekundäre Region weiterleiten. Nachdem Azure den Ausfall beseitigt hat und Ihr primärer Arbeitsbereich wieder in Ordnung ist, können Sie wieder zu Ihrer primären Region wechseln.
Wenn Sie wechseln, wird der sekundäre Arbeitsbereich aktiv und Ihr primärer wird inaktiv. Azure Monitor nimmt dann neue Daten über die Erfassungspipeline in Ihrer sekundären Region auf, anstatt in der primären Region. Wenn Sie zu Ihrer sekundären Region wechseln, repliziert Azure Monitor alle Daten, die Sie aus der sekundären Region in die primäre Region erfassen. Der Prozess ist asynchron und hat keinen Einfluss auf die Erfassungslatenz.
Wichtig
Wenn die primäre Region nach dem Wechsel zur sekundären Region keine eingehenden Protokolldaten verarbeiten kann, puffert Azure Monitor die Daten in der sekundären Region für bis zu 11 Tage. Während der ersten vier Tage versucht Azure Monitor automatisch in regelmäßigen Abständen, die Daten zu replizieren.

Unterstützte Regionen
Die Replikation von Arbeitsbereichen wird derzeit für Arbeitsbereiche in einer begrenzten Anzahl von Regionen unterstützt, die nach Regionsgruppen (Gruppen von geografisch benachbarten Regionen) organisiert sind. Wenn Sie die Replikation aktivieren, wählen Sie einen sekundären Standort aus der Liste der unterstützten Regionen in derselben Regionsgruppe wie der primäre Standort des Arbeitsbereichs. Zum Beispiel kann ein Arbeitsbereich in „Europa, Westen“ in „Europa, Norden“ repliziert werden, aber nicht in „USA, Westen 2“, da diese Regionen zu unterschiedlichen Regionengruppen gehören.
Die folgenden Regionengruppen und Regionen werden derzeit unterstützt:
| Regionsgruppe | Regions | Hinweise |
|---|---|---|
| Nordamerika | East US | Die Replikation in oder aus der Region „USA, Osten 2“ wird nicht unterstützt. |
| USA (Ost) 2 | Die Replikation in oder aus der Region „USA, Osten“ wird nicht unterstützt. | |
| USA (Westen) | ||
| USA, Westen 2 | ||
| USA (Mitte) | ||
| USA Süd Mitte | ||
| Kanada, Mitte | ||
| Europa | Europa, Westen | |
| Nordeuropa | ||
| Süd-Vereinigtes Königreich | ||
| Vereinigtes Königreich, Westen | ||
| Deutschland, Westen-Mitte | ||
| Frankreich, Mitte |
Anforderungen an die Datenresidenz
Die Kundschaft hat unterschiedliche Anforderungen an die Datenaufbewahrung, daher ist es wichtig, dass Sie die Kontrolle darüber haben, wo Ihre Daten gespeichert werden. Azure Monitor verarbeitet und speichert Protokolle in den von Ihnen gewählten primären und sekundären Regionen. Weitere Informationen finden Sie unter Unterstützte Regionen.
Unterstützung für Sentinel und andere Dienste
Verschiedene Dienste und Funktionen, die Log Analytics-Arbeitsbereiche verwenden, sind mit der Arbeitsbereichsreplikation und dem Switchover kompatibel. Diese Dienste und Funktionen funktionieren weiterhin, wenn Sie zum sekundären Arbeitsbereich wechseln.
So können sich beispielsweise regionale Netzwerkprobleme, die eine Latenz bei der Protokollaufnahme verursachen, auf die Sentinel-Kundschaft auswirken. Die Kundschaft, die replizierte Arbeitsbereiche verwendet, kann zu ihrer sekundären Region wechseln, um mit ihrem Log Analytics-Arbeitsbereich und Sentinel weiterzuarbeiten. Wenn sich das Netzwerkproblem jedoch auf den Zustand des Sentinel-Dienstes auswirkt, kann ein Wechsel in eine andere Region das Problem nicht beheben.
Einige Azure Monitor-Benutzeroberflächen, einschließlich Application Insights und VM Insights, sind derzeit nur teilweise mit Arbeitsbereichsreplikation und Switchover kompatibel. Die vollständige Liste finden Sie unter Einschränkungen und Beschränkungen.
Aktivieren und Deaktivieren der Arbeitsbereichsreplikation
Sie aktivieren und deaktivieren die Arbeitsbereichsreplikation mit einem REST-Befehl. Der Befehl löst einen zeitintensiven Vorgang aus, d. h. es kann einige Minuten dauern, bis die neuen Einstellungen übernommen werden. Nachdem Sie die Replikation aktiviert haben, kann es bis zu einer Stunde dauern, bis alle Tabellen (Datentypen) mit der Replikation beginnen, und einige Datentypen beginnen möglicherweise vor anderen mit der Replikation. Änderungen, die Sie an Tabellenschemata vornehmen, nachdem Sie die Arbeitsbereichsreplikation aktiviert haben – z. B. neue benutzerdefinierte Protokolltabellen oder benutzerdefinierte Felder, die Sie erstellen, oder Diagnoseprotokolle, die für neue Ressourcentypen eingerichtet werden – können bis zu einer Stunde dauern, bis die Replikation beginnt.
Wichtig
Die Replikation von Log Analytics-Arbeitsbereichen, die mit einem dedizierten Cluster verbunden sind, wird derzeit nicht unterstützt.
Aktivieren der Arbeitsbereichreplikation
Verwenden Sie den Befehl PUT, um die Replikation in Ihrem Log Analytics-Arbeitsbereich zu aktivieren:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
Hierbei gilt:
<subscription_id>: Die Abonnement-ID, die sich auf Ihren Arbeitsbereich bezieht.<resourcegroup_name>: Die Ressourcengruppe, die Ihre Log Analytics-Arbeitsbereichsressource enthält.<workspace_name>: Der Name Ihres Arbeitsbereichs.<primary_region>: Die primäre Region für Ihren Log Analytics-Arbeitsbereich.<secondary_region>: Die Region, in der Azure Monitor den sekundären Arbeitsbereich erstellt.
Die unterstützten location-Werte finden Sie unter Unterstützte Regionen.
Der Befehl PUT ist ein zeitintensiver Vorgang, der einige Zeit in Anspruch nehmen kann. Ein erfolgreicher Aufruf gibt einen 200-Statuscode zurück. Sie können den Bereitstellungsstatus Ihrer Anforderung nachverfolgen, wie im Überprüfen des Anforderungsbereitstellungsstatus beschrieben.
Überprüfen des Anforderungsbereitstellungsstatus
Führen Sie den Befehl GET aus, um den Bereitstellungsstatus Ihrer Anforderung zu überprüfen:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
Hierbei gilt:
<subscription_id>: Die Abonnement-ID, die sich auf Ihren Arbeitsbereich bezieht.<resourcegroup_name>: Die Ressourcengruppe, die Ihre Log Analytics-Arbeitsbereichsressource enthält.<workspace_name>: Der Name Ihres Log Analytics-Arbeitsbereichs.
Verwenden Sie den Befehl GET, um zu überprüfen, ob der Bereitstellungsstatus des Arbeitsbereichs von Updating auf Succeeded wechselt und die sekundäre Region wie erwartet eingestellt ist.
Hinweis
Wenn Sie die Replikation für Arbeitsbereiche aktivieren, die mit Sentinel interagieren, kann es bis zu 12 Tage dauern, bis Watchlist- und Threat Intelligence-Daten vollständig auf den sekundären Arbeitsbereich repliziert sind.
Datensammlungsregeln mit dem Endpunkt der Systemdatenerfassung verknüpfen
Die Datensammlungsregeln (Data Collection Rules, DCR) werden zum Sammeln von Protokolldaten mit Azure Monitor Agent und der Logs Ingestion API verwendet.
Wenn Sie Datensammlungsregeln anwenden, die Daten an Ihren primären Arbeitsbereich senden, müssen Sie die Regeln mit einem Systemdatensammlungsendpunkt (Data Collection Endpoint, DCE) verknüpfen, den Azure Monitor erstellt, wenn Sie die Arbeitsbereichsreplikation aktivieren. Der Name des Endpunkts der Systemdatensammlung ist identisch mit Ihrer Arbeitsbereichs-ID. Nur Datensammlungsregeln, die Sie mit dem Endpunkt für die Systemdatensammlung des Arbeitsbereichs verknüpfen, ermöglichen Replikation und Switchover. Mit diesem Verhalten können Sie die Menge der zu replizierenden Protokollströme angeben, was Ihnen hilft, Ihre Replikationskosten zu steuern.
Um Daten, die Sie mithilfe von Datensammlungsregeln sammeln, zu replizieren, verknüpfen Sie Ihre Datensammlungsregeln mit dem Endpunkt für die Systemdatensammlung Ihres Log Analytics-Arbeitsbereichs:
Wählen Sie im Azure-Portal die Datensammlungsregeln aus.
Wählen Sie im Bildschirm Datensammlungsregeln eine Datensammlungsregel aus, die Daten an Ihren primären Log Analytics-Arbeitsbereich sendet.
Wählen Sie auf der Seite Übersicht DCE konfigurieren aus, und wählen Sie den Endpunkt für die Systemdatensammlung aus der verfügbaren Liste aus:
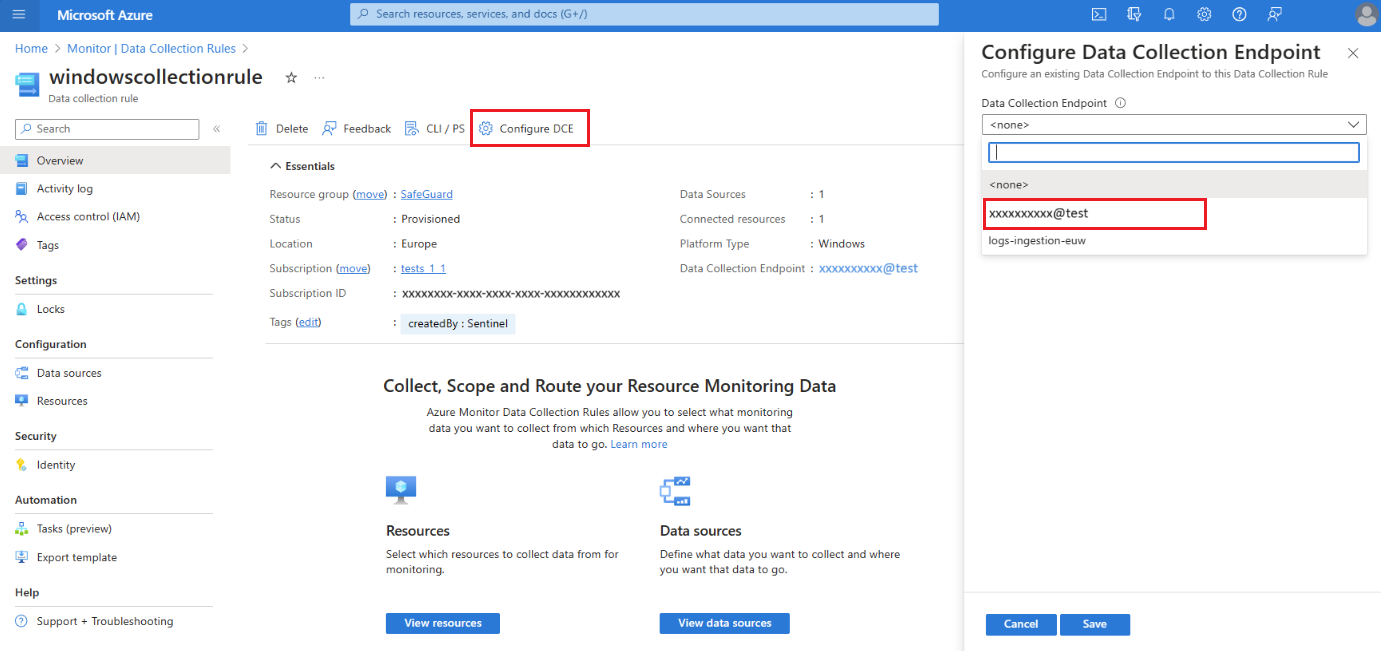 Ausführliche Informationen zum System-DCE finden Sie in den Arbeitsbereichsobjekteigenschaften.
Ausführliche Informationen zum System-DCE finden Sie in den Arbeitsbereichsobjekteigenschaften.

Wichtig
Datensammlungsregeln, die mit dem Endpunkt für die Systemdatensammlung eines Arbeitsbereichs verbunden sind, können nur auf diesen speziellen Arbeitsbereich abzielen. Die Datensammlungsregeln dürfen nicht auf andere Ziele abzielen, z. B. auf andere Arbeitsbereiche oder Azure Storage-Konten.
Deaktivieren der Arbeitsbereichreplikation
Verwenden Sie den Befehl PUT, um die Replikation für einen Arbeitsbereich zu deaktivieren:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
Hierbei gilt:
<subscription_id>: Die Abonnement-ID, die sich auf Ihren Arbeitsbereich bezieht.<resourcegroup_name>: Die Ressourcengruppe, die Ihre Arbeitsbereichressource enthält.<workspace_name>: Der Name Ihres Arbeitsbereichs.<primary_region>: Die primäre Region für Ihren Arbeitsbereich.
Der Befehl PUT ist ein zeitintensiver Vorgang, der einige Zeit in Anspruch nehmen kann. Ein erfolgreicher Aufruf gibt einen 200-Statuscode zurück. Sie können den Bereitstellungsstatus Ihrer Anforderung nachverfolgen, wie im Überprüfen des Anforderungsbereitstellungsstatus beschrieben.
Überwachen des Arbeitsbereichs und der Dienstintegrität
Erfassungslatenz oder Abfrageausfälle sind Beispiele für Probleme, die oft durch einen Failover zu Ihrer sekundären Region gelöst werden können. Solche Probleme können mit Hilfe von Service Health-Benachrichtigungen und Protokollabfragen erkannt werden.
Service Health-Benachrichtigungen sind für dienstbezogene Probleme nützlich. Um Probleme zu identifizieren, die sich auf Ihren spezifischen Arbeitsbereich (und möglicherweise nicht auf den gesamten Dienst) auswirken, können Sie andere Maßnahmen ergreifen:
- Erstellen von Warnungen basierend auf der Ressourcenintegrität des Arbeitsbereichs
- Festlegen eigener Schwellenwerte für Arbeitsbereichsintegritätsmetriken
- Erstellen Sie eigene Überwachungsabfragen, die als benutzerdefinierte Integritätsindikatoren für Ihren Arbeitsbereich dienen, wie unter Überwachen der Arbeitsbereichleistung mithilfe von Abfragen beschrieben:
- Messen der Erfassungslatenz pro Tabelle
- Identifizieren, ob die Quelle der Latenz die Erfassungsagenten oder die Erfassungspipeline ist
- Überwachen Sie Anomalien des Erfassungsvolumens pro Tabelle und Ressource
- Überwachen der Abfrageerfolgsrate pro Tabelle, benutzende Person oder Ressource
- Erstellen von Warnungen basierend auf Ihren Abfragen
Hinweis
Sie können auch Protokollabfragen verwenden, um Ihren sekundären Arbeitsbereich zu überwachen, aber bedenken Sie, dass die Replikation von Protokollen in Batch-Operationen durchgeführt wird. Die gemessene Latenz kann schwanken und deutet nicht auf ein Problem mit Ihrem sekundären Arbeitsbereich hin. Weitere Informationen finden Sie unter Überwachen des inaktiven Arbeitsbereichs.
Wechseln zum sekundären Arbeitsbereich
Während des Switchover funktionieren die meisten Vorgänge genauso wie bei der Verwendung des primären Arbeitsbereichs und der Region. Einige Vorgänge weisen jedoch ein geringfügig anderes Verhalten auf oder werden blockiert. Weitere Informationen finden Sie unter Einschränkungen und Begrenzungen.
Wann sollte ich wechseln?
Sie entscheiden auf der Grundlage der laufenden Leistungs- und Zustandsüberwachung sowie Ihrer Systemstandards und -anforderungen, wann Sie zu Ihrem sekundären Arbeitsbereich wechseln und wann Sie zu Ihrem primären Arbeitsbereich zurückkehren.
Bei Ihrem Plan für den Switchover sind mehrere Punkte zu berücksichtigen, die in den folgenden Unterabschnitten beschrieben werden.
Typ und Umfang des Problems
Der Switchoverprozess leitet Erfassungs- und Abfrageanforderungen an Ihre sekundäre Region weiter, die in der Regel alle fehlerhaften Komponenten umgeht, die in Ihrer primären Region Latenz oder Ausfälle verursachen. Folglich ist Switchover wahrscheinlich nicht hilfreich, wenn:
- Es sich um ein überregionales Problem mit einer zugrunde liegenden Ressource handelt. Zum Beispiel, wenn dieselben Ressourcentypen sowohl in der primären als auch in der sekundären Region ausfallen.
- Sie ein Problem im Zusammenhang mit der Arbeitsbereichsverwaltung, z. B. die Änderung der Arbeitsbereichsspeicherung, haben. Die Verwaltung des Arbeitsbereichs wird immer in Ihrer primären Region durchgeführt. Während der Umstellung werden Arbeitsbereichsverwaltungsvorgänge blockiert.
Problemdauer
Der Switchover erfolgt nicht sofort. Der Prozess der Umleitung von Anforderungen beruht auf DNS-Aktualisierungen, die einige Clients innerhalb von Minuten abrufen, während andere mehr Zeit benötigen könnten. Daher ist es hilfreich zu wissen, ob das Problem innerhalb weniger Minuten behoben werden kann. Wenn das beobachtete Problem beständig oder dauerhaft ist, sollten Sie mit dem Switchover nicht warten. Im Folgenden finden Sie einige Beispiele:
Erfassung: Probleme mit der Erfassungspipeline in Ihrer primären Region können sich auf die Datenreplikation auf Ihren sekundären Arbeitsbereich auswirken. Beim Switchover werden die Protokolle stattdessen an die Erfassungspipeline in der sekundären Region gesendet.
Abfrage: Wenn Abfragen in Ihrem primären Arbeitsbereich fehlschlagen oder eine Zeitüberschreitung vorliegt, können die Warnmeldungen der Protokollsuche davon betroffen sein. Wechseln Sie in diesem Fall zu Ihrem sekundären Arbeitsbereich, um sicherzustellen, dass alle Ihre Warnmeldungen korrekt ausgelöst werden.
Daten im sekundären Arbeitsbereich
Protokolle, die vor der Aktivierung der Replikation in den primären Arbeitsbereich erfasst wurden, werden nicht in den sekundären Arbeitsbereich kopiert. Wenn Sie die Arbeitsbereichsreplikation vor drei Stunden aktiviert haben und nun zu Ihrem sekundären Arbeitsbereich wechseln, können Ihre Abfragen nur Daten aus den letzten drei Stunden zurückgeben.
Bevor Sie während des Switchover die Region wechseln, muss Ihr sekundärer Arbeitsbereich eine sinnvolle Menge an Protokollen enthalten. Wir empfehlen, nach der Aktivierung der Replikation mindestens eine Woche zu warten, bevor Sie den Switchover auslösen. Die sieben Tage reichen aus, um genügend Daten in Ihrer Sekundärregion zur Verfügung zu stellen.
Switchover auslösen
Vergewissern Sie sich vor dem Switchover, dass der Arbeitsbereichreplikationsvorgang erfolgreich abgeschlossen wurde. Der Switchover ist nur erfolgreich, wenn der sekundäre Arbeitsbereich ordnungsgemäß konfiguriert ist.
Verwenden Sie den Befehl POST, um zum sekundären Arbeitsbereich zu wechseln:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2023-01-01-preview
Hierbei gilt:
<subscription_id>: Die Abonnement-ID, die sich auf Ihren Arbeitsbereich bezieht.<resourcegroup_name>: Die Ressourcengruppe, die Ihre Arbeitsbereichressource enthält.<secondary_region>: Die Region, zu der im Rahmen des Switchovers gewechselt werden soll.<workspace_name>: Der Name des Arbeitsbereichs, zu dem im Rahmen des Switchovers gewechselt werden soll.
Der Befehl POST ist ein zeitintensiver Vorgang, der einige Zeit in Anspruch nehmen kann. Ein erfolgreicher Aufruf gibt einen 202-Statuscode zurück. Sie können den Bereitstellungsstatus Ihrer Anforderung nachverfolgen, wie im Überprüfen des Anforderungsbereitstellungsstatus beschrieben.
Zurück zu Ihrem primären Arbeitsbereich wechseln
Der Switchbackvorgang hebt die Umleitung von Abfragen und Anforderungen an die Protokollaufnahme auf den sekundären Arbeitsbereich auf. Wenn Sie zurückwechseln, leitet Azure Monitor die Abfragen und Anforderungen für die Protokollaufnahme wieder an Ihren primären Arbeitsbereich weiter.
Wenn Sie zu Ihrer sekundären Region wechseln, repliziert Azure Monitor die Protokolle von Ihrem sekundären Arbeitsbereich in Ihren primären Arbeitsbereich. Wenn ein Ausfall den Protokollerfassungsprozess in der primären Region beeinträchtigt, kann es einige Zeit dauern, bis Azure Monitor die Erfassung der replizierten Protokolle in Ihrem primären Arbeitsbereich abschließt.
Wann sollte ich zurückwechseln?
Bei Ihrem Plan für den Switchback sind mehrere Punkte zu berücksichtigen, die in den folgenden Unterabschnitten beschrieben werden.
Protokollreplikationsstatus
Überprüfen Sie vor dem Zurückwechseln, ob Azure Monitor die Replikation aller während des Switchover erfassten Protokolle in der primären Region abgeschlossen hat. Wenn Sie zurückwechseln, bevor alle Protokolle in den primären Arbeitsbereich repliziert wurden, geben Ihre Abfragen möglicherweise nur Teilergebnisse zurück, bis die Aufnahme der Protokolle abgeschlossen ist.
Sie können Ihren primären Arbeitsbereich im Azure-Portal für die inaktive Region abfragen, wie unter Überwachen des inaktiven Arbeitsbereichs beschrieben.
Integrität des primären Arbeitsbereichs
Es gibt zwei wichtige Punkte, die bei der Vorbereitung auf die Rückkehr zu Ihrem primären Arbeitsbereich überprüft werden müssen:
- Bestätigen Sie, dass es keine ausstehenden Service Health-Benachrichtigungen für den primären Arbeitsbereich und die Region gibt.
- Stellen Sie sicher, dass Ihr primärer Arbeitsbereich Protokolle erfasst und Abfragen wie erwartet verarbeitet.
Beispiele dafür, wie Sie Ihren primären Arbeitsbereich abfragen, wenn Ihr sekundärer Arbeitsbereich aktiv ist, und die Umleitung von Anforderungen an Ihren sekundären Arbeitsbereich umgehen können, finden Sie unter Überwachen des inaktiven Arbeitsbereichs.
Switchback auslösen
Bevor Sie zurückwechseln, bestätigen Sie die Integrität des primären Arbeitsbereichs und die vollständige Replikation von Protokollen.
Der Switchbackprozess aktualisiert Ihre DNS-Einträge. Nach der Aktualisierung der DNS-Einträge kann es einige Zeit dauern, bis alle Clients die aktualisierten DNS-Einstellungen erhalten und die Weiterleitung zum primären Arbeitsbereich wieder aufnehmen.
Verwenden Sie den Befehl POST, um zurück zum primären Arbeitsbereich zu wechseln:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2023-01-01-preview
Hierbei gilt:
<subscription_id>: Die Abonnement-ID, die sich auf Ihren Arbeitsbereich bezieht.<resourcegroup_name>: Die Ressourcengruppe, die Ihre Arbeitsbereichressource enthält.<workspace_name>: Der Name des Arbeitsbereichs, zu dem während des Switchbacks gewechselt werden soll.
Der Befehl POST ist ein zeitintensiver Vorgang, der einige Zeit in Anspruch nehmen kann. Ein erfolgreicher Aufruf gibt einen 202-Statuscode zurück. Sie können den Bereitstellungsstatus Ihrer Anforderung nachverfolgen, wie im Überprüfen des Anforderungsbereitstellungsstatus beschrieben.
Überwachen des inaktiven Arbeitsbereichs
Standardmäßig ist die aktive Region Ihres Arbeitsbereichs diejenige, in der Sie den Arbeitsbereich erstellen. Bei der inaktiven Region handelt es sich um die sekundäre Region, in der Azure Monitor den replizierten Arbeitsbereich erstellt.
Wenn Sie ein Failover auslösen, kehrt sich dies um: Die sekundäre Region wird aktiviert, und die primäre Region wird inaktiv. Der Zustand wird „inaktiv“ genannt, da die Region nicht das direkte Ziel der Protokollerfassung und der Abfrageanforderungen ist.
Es ist hilfreich, die inaktive Region abzufragen, bevor Sie zwischen Regionen wechseln, um zu überprüfen, ob der Arbeitsbereich in der inaktiven Region die Protokolle enthält, die dort angezeigt werden sollen.
Abfragen der Inaktiven Region
Verwenden Sie den folgenden GET-Befehl, um Protokolldaten in der inaktiven Region abzufragen:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
Wenn Sie beispielsweise eine einfache Abfrage wie Perf | count für den vergangenen Tag in Ihrer sekundären Region ausführen möchten, verwenden Sie Folgendes:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
Sie können bestätigen, dass Azure Monitor Ihre Abfrage in der vorgesehenen Region ausführt, indem Sie diese Felder in der Tabelle LAQueryLogs überprüfen, die erstellt wird, wenn Sie die Abfrageüberwachung in Ihrem Log Analytics-Arbeitsbereich aktivieren:
isWorkspaceInFailover: Gibt an, ob sich der Arbeitsbereich während der Abfrage im Switchovermodus befand. Der Datentyp ist boolesch (True, False).workspaceRegion: Der Bereich des Arbeitsbereichs, der von der Abfrage adressiert wird. Der Datentyp ist „Zeichenfolge“.
Überwachen der Arbeitsbereichleistung mithilfe von Abfragen
Wir empfehlen, die Abfragen in diesem Abschnitt zu verwenden, um Warnregeln zu erstellen, die Sie über mögliche Probleme im Arbeitsbereich oder bei der Leistung informieren. Die Entscheidung für einen Switchover muss jedoch sorgfältig überlegt werden und sollte nicht automatisch getroffen werden.
In der Abfrageregel können Sie eine Bedingung definieren, um nach einer bestimmten Anzahl von Verstößen zum sekundären Arbeitsbereich zu wechseln. Weitere Informationen finden Sie unter Erstellen oder Bearbeiten einer Warnungsregel für die Protokollsuche.
Zwei wichtige Messgrößen für die Leistung des Arbeitsbereichs sind die Erfassungslatenz und das Erfassungsvolumen. In den folgenden Abschnitten werden diese Überwachungsoptionen erläutert.
Überwachen der End-to-End-Erfassungslatenz
Die Erfassungslatenz misst die Zeit, die für die Erfassung von Protokollen im Arbeitsbereich benötigt wird. Die Zeitmessung beginnt, wenn das erste protokollierte Ereignis eintritt, und endet, wenn das Protokoll in Ihrem Arbeitsbereich gespeichert wird. Die gesamte Erfassungslatenz setzt sich aus zwei Teilen zusammen:
- Agentlatenz: Die vom Agent erforderliche Zeit, um ein Ereignis zu melden.
- Latenz der Erfassungsepipeline (Back-End): Die für die Erfassungsepipeline erforderliche Zeit zum Verarbeiten der Protokolle und Schreiben in Ihren Arbeitsbereich.
Unterschiedliche Datentypen weisen unterschiedliche Erfassungslatenz auf. Sie können die Erfassung für jeden Datentyp separat messen oder eine allgemeine Abfrage für alle Typen und eine feinere Abfrage für bestimmte Typen, die für Sie von größerer Bedeutung sind, erstellen. Wir empfehlen Ihnen, das 90. Perzentil der Erfassungslatenz zu messen, das empfindlicher auf Veränderungen reagiert als der Durchschnitt oder das 50. Perzentil (Median).
In den folgenden Abschnitten wird gezeigt, wie Sie die Erfassungslatenz für Ihren Arbeitsbereich mithilfe von Abfragen überprüfen können.
Bewerten der geplanten Erfassungslatenz bestimmter Tabellen
Beginnen Sie mit der Ermittlung der geplanten Latenz bestimmter Tabellen über mehrere Tage.
Diese Beispielabfrage erstellt ein Diagramm des 90. Perzentils der Erfassungslatenz in der Tabelle „Perf“:
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
Nachdem Sie die Abfrage ausgeführt haben, überprüfen Sie die Ergebnisse und das gerenderte Diagramm, um die erwartete Latenzzeit für diese Tabelle zu ermitteln.
Überwachung und Warnung bei aktueller Erfassungslatenz
Nachdem Sie die grundlegende Erfassungslatenz für eine bestimmte Tabelle ermittelt haben, erstellen Sie eine Warnregel für die Protokollsuche für die Tabelle, die auf Änderungen der Latenz über einen kurzen Zeitraum basiert.
Diese Abfrage berechnet die Erfassungslatenz der letzten 20 Minuten:
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
Da mit gewissen Schwankungen zu rechnen ist, sollten Sie eine Warnregelbedingung erstellen, um zu überprüfen, ob die Abfrage einen Wert liefert, der deutlich über der Basislinie liegt.
Ermitteln der Quelle der Erfassungslatenz
Wenn Sie feststellen, dass die Erfassungslatenz insgesamt zunimmt, können Sie mithilfe von Abfragen feststellen, ob die Quelle der Latenz die Agenten oder die Erfassungspipeline sind.
Diese Abfrage stellt die Latenzzeit des 90. Perzentils der Agenten und der Pipeline getrennt dar:
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
Hinweis
Obwohl das Diagramm die 90-Perzentil-Daten als gestapelte Spalten anzeigt, entspricht die Summe der Daten in den beiden Diagrammen nicht der gesamten Erfassung des 90-Perzentils.
Überwachen des Erfassungsvolumens
Messungen des Erfassungsvolumens können dabei helfen, unerwartete Änderungen des gesamten oder tabellenspezifischen Erfassungsvolumens für Ihren Arbeitsbereich zu erkennen. Die Messungen des Abfragevolumens können Ihnen helfen, Leistungsprobleme bei der Erfassung von Protokollen zu erkennen. Einige nützliche Volumenmessungen umfassen:
- Gesamterfassungsvolumen pro Tabelle
- Konstante Erfassungsmenge (Stillstand)
- Erfassungsanomalien – Spitzen und Abfälle im Erfassungsvolumen
In den folgenden Abschnitten wird gezeigt, wie Sie das Erfassungsvolumen für Ihren Arbeitsbereich mithilfe von Abfragen überprüfen können.
Überwachen des Gesamterfassungsvolumens pro Tabelle
Sie können eine Abfrage definieren, um das Erfassungsvolumen pro Tabelle in Ihrem Arbeitsbereich zu überwachen. Die Abfrage kann eine Warnung enthalten, die auf unerwartete Änderungen des Gesamtvolumens oder der tabellenspezifischen Volumina prüft.
Diese Abfrage berechnet das gesamte Erfassungsvolumen der letzten Stunde pro Tabelle in Megabyte pro Sekunde (MBs):
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
Überprüfen des Stillstands bei der Erfassung
Wenn Sie Protokolle über Agenten erfassen, können Sie den Heartbeat des Agenten zur Erkennung der Konnektivität verwenden. Ein stillstehender Heartbeat kann eine Unterbrechung der Erfassung von Protokollen in Ihrem Arbeitsbereich aufzeigen. Wenn die Abfragedaten einen Erfassungsstopp ergeben, können Sie eine Bedingung definieren, um eine gewünschte Reaktion auszulösen.
Die folgende Abfrage überprüft den Heartbeat des Agenten, um Konnektivitätsprobleme zu erkennen:
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
Überwachen von Erfassungsanomalien
Sie können Spitzen und Abfälle in den Daten Ihres Erfassungsvolumens im Arbeitsbereich auf verschiedene Weise erkennen. Verwenden Sie die Funktion series_decompose_anomalies(), um Anomalien aus den Erfassungsvolumina zu extrahieren, die Sie in Ihrem Arbeitsbereich überwachen, oder erstellen Sie Ihren eigenen Anomaliedetektor, um Ihre speziellen Arbeitsbereichsszenarien zu unterstützen.
Identifizierung von Anomalien mit series_decompose_anomalies
Die Funktion series_decompose_anomalies() identifiziert Anomalien in einer Reihe von Datenwerten. Diese Abfrage berechnet das stündliche Erfassungsvolumen jeder Tabelle in Ihrem Log Analytics-Arbeitsbereich und verwendet series_decompose_anomalies(), um Anomalien zu erkennen:
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
Weitere Informationen über die Verwendung von series_decompose_anomalies() zur Erkennung von Anomalien in Protokolldaten finden Sie unter Erkennen und Analysieren von Anomalien mithilfe der KQL-Maschinenlernfunktionen in Azure Monitor.
Erstellen Eines eigenen Anomalieerkennungsmodul
Sie können ein benutzerdefiniertes Anomalieerkennungsmodul erstellen, um die Szenarioanforderungen für Ihre Arbeitsbereichskonfiguration zu unterstützen. Dieser Abschnitt enthält ein Beispiel zum Veranschaulichen des Prozesses.
Die folgende Abfrage berechnet:
- Erwartetes Erfassungsvolumen: Pro Stunde, nach Tabelle (basierend auf dem Median der Mediane, aber Sie können die Logik anpassen)
- Tatsächliches Erfassungsvolumen: Pro Stunde, nach Tabelle
Um unbedeutende Unterschiede zwischen dem erwarteten und dem tatsächlichen Erfassungsvolumen herauszufiltern, wendet die Abfrage zwei Filter an:
- Änderungsrate: Über 150 % oder unter 66 % des erwarteten Volumens pro Tabelle
- Änderungsvolumen: Gibt an, ob das erhöhte oder verringerte Volumen mehr als 0,1 % des monatlichen Volumens dieser Tabelle beträgt
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
Überwachen von erfolgreichen und fehlgeschlagenen Abfragen
Jede Abfrage gibt einen Antwortcode zurück, der den Erfolg oder Fehler anzeigt. Wenn die Abfrage fehlschlägt, enthält die Antwort auch die Fehlerarten. Eine hohe Anzahl von Fehlern kann auf ein Problem mit der Verfügbarkeit des Arbeitsbereichs oder der Leistung des Dienstes hinweisen.
Diese Abfrage zählt, bei wie vielen Abfragen ein Serverfehlercode zurückgegeben wurde:
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count
Einschränkungen
Die Replikation von Log Analytics-Arbeitsbereichen, die mit einem dedizierten Cluster verbunden sind, wird derzeit nicht unterstützt.
Der Bereinigungsvorgang, der Datensätze aus einem Arbeitsbereich löscht, entfernt die betreffenden Datensätze sowohl aus dem primären als auch aus dem sekundären Arbeitsbereich. Der Bereinigungsvorgang schlägt fehl, wenn eine der Arbeitsbereichsinstanzen nicht verfügbar ist.
Die Replikation von Warnregeln über Regionen hinweg wird derzeit nicht unterstützt. Da Azure Monitor die Abfrage der inaktiven Region unterstützt, funktionieren abfragebasierte Warnungen weiterhin, wenn Sie zwischen den Regionen wechseln, es sei denn, der Dienst „Alerts“ in der aktiven Region funktioniert nicht richtig oder die Warnregeln sind nicht verfügbar.
Wenn Sie die Replikation für Arbeitsbereiche aktivieren, die mit Sentinel interagieren, kann es bis zu 12 Tage dauern, bis Watchlist- und Threat Intelligence-Daten vollständig auf den sekundären Arbeitsbereich repliziert sind.
Während des Switchover werden die Operationen der Arbeitsbereichsverwaltung nicht unterstützt, einschließlich:
- Ändern der Arbeitsbereichaufbewahrung, der Preisstufe, der täglichen Obergrenze usw.
- Ändern von Netzwerkeinstellungen
- Ändern des Schemas über neue benutzerdefinierte Protokolle oder Verbinden von Plattformprotokollen von neuen Ressourcenanbietern, z. B. Senden von Diagnoseprotokollen aus einem neuen Ressourcentyp
Die Fähigkeit des früheren Log Analytics-Agenten, auf eine Lösung abzuzielen, wird beim Switchover nicht unterstützt. Daher werden während des Switchovers Lösungsdaten von allen Agenten erfasst.
Der Failoverprozess aktualisiert Ihre DNS-Einträge (Domain Name System), um alle Anforderungen zur Erfassung an Ihre sekundäre Region zur Verarbeitung umzuleiten. Einige HTTP-Clients haben „fixierte Verbindungen“ und brauchen möglicherweise länger, um den aktualisierten DNS zu empfangen. Während des Switchover versuchen diese Clients möglicherweise eine Zeit lang, Protokolle über die Primärregion zu erfassen. Möglicherweise erfassen Sie Protokolle in Ihrem primären Arbeitsbereich mit verschiedenen Clients, darunter der alte Log Analytics-Agent, der Azure Monitor-Agent, Code (mit der Logs Ingestion API oder der alten HTTP-Datenerfassungs-API) und andere Dienste wie Sentinel.
Diese Features werden derzeit nicht oder nur teilweise unterstützt:
Funktion Unterstützung Hilfstabellenpläne Nicht unterstützt. Azure Monitor repliziert keine Daten in Tabellen mit dem Hilfsprotokollplan in Ihrem sekundären Arbeitsbereich. Daher sind diese Daten bei einem regionalen Ausfall nicht vor Datenverlust geschützt und stehen nicht zur Verfügung, wenn Sie zu Ihrem sekundären Arbeitsbereich wechseln. Suchaufträge, Wiederherstellung Teilweise unterstützt – Suchaufträge und Wiederherstellungsoperationen erstellen Tabellen und füllen sie mit Suchergebnissen oder wiederhergestellten Daten. Nachdem Sie die Arbeitsbereichsreplikation aktiviert haben, werden neue Tabellen, die für diese Operationen erstellt wurden, in Ihren sekundären Arbeitsbereich repliziert. Tabellen, die vor der Aktivierung der Replikation aufgefüllt wurden, werden nicht repliziert. Wenn diese Vorgänge noch laufen, wenn Sie umschalten, ist das Ergebnis unerwartet. Der Vorgang kann erfolgreich abgeschlossen werden, aber nicht repliziert werden, oder er kann fehlschlagen, je nach Zustand Ihres Arbeitsbereichs und dem genauen Zeitpunkt. Application Insights über Log Analytics-Arbeitsbereiche Nicht unterstützt VM Insights Nicht unterstützt Container Insights Nicht unterstützt Private Links Während des Failovers nicht unterstützt