Überwachen von VMs mit Azure Monitor: Warnungen
Dieser Artikel ist Teil des Szenarios Überwachen von VMs und der zugehörigen Workloads in Azure Monitor. Warnungen in Azure Monitor informieren Sie proaktiv über interessante Daten und Muster in Ihren Überwachungsdaten. Es gibt keine vorkonfigurierten Warnungsregeln für virtuelle Computer (VMs), aber Sie können auf Grundlage der mit dem Azure Monitor-Agent gesammelten Daten eigene Regeln erstellen. In diesem Artikel werden Warnungskonzepte speziell für VMs sowie allgemeine Warnungsregeln vorgestellt, die von anderen Azure Monitor-Kunden verwendet werden.
In diesem Szenario wird beschrieben, wie Sie die vollständige Überwachung Ihrer Azure- und Hybrid-VM-Umgebung implementieren:
Informationen zum Einstieg in die Überwachung Ihres ersten virtuellen Azure-Computers finden Sie unter Überwachen virtueller Azure-Computer.
Informationen zur schnellen Aktivierung eines empfohlenen Satzes von Warnungen finden Sie unter Aktivieren empfohlener Warnungsregeln für virtuelle Azure-Computer.
Wichtig
Für die meisten Warnungsregeln fallen Kosten an, deren Höhe von der Art der Regel, der Anzahl einbezogener Dimensionen und der Häufigkeit der Ausführung abhängt. Lesen Sie vor dem Erstellen von Warnungsregeln den Abschnitt Warnungsregeln unter Azure Monitor – Preise.
Datensammlung
Warnungsregeln untersuchen Daten, die bereits in Azure Monitor erfasst wurden. Bevor Sie eine Warnungsregel erstellen können, müssen Sie sicherstellen, dass Daten für ein bestimmtes Szenario gesammelt werden. Eine Anleitung zum Konfigurieren der Datensammlung für verschiedene Szenarien (einschließlich aller Warnungsregeln in diesem Artikel) finden Sie unter Überwachen von VMs mit Azure Monitor: Sammeln von Daten.
Empfohlene Warnungsregeln
Azure Monitor bietet eine Reihe von empfohlenen Warnungsregeln, die Sie schnell für eine beliebige Azure-VM aktivieren können. Diese Regeln sind ein guter Ausgangspunkt für die grundlegende Überwachung. Allein bieten sie jedoch aus den folgenden Gründen keine ausreichenden Warnungen für die meisten Unternehmensimplementierungen:
- Die empfohlenen Warnungen gelten nur für Azure-VMs und nicht für Hybridcomputer.
- Die empfohlenen Warnungen schließen nur Hostmetriken und keine Gastmetriken oder Protokolle ein. Diese Metriken sind nützlich, um die Integrität des Computers selbst zu überwachen. Sie bieten jedoch nur minimale Einblicke in das Workload und die Anwendungen, die auf dem Computer laufen.
- Die empfohlenen Warnungen sind einzelnen Computern zugeordnet, wodurch eine übermäßige Anzahl von Warnungsregeln erstellt wird. Anstatt sich auf diese Methode für die einzelnen Computer zu verlassen, finden Sie unter Skalieren von Warnungsregeln Strategien für die Verwendung einer minimalen Anzahl von Warnungsregeln für mehrere Computer.
Warnungstypen
Die gängigsten Typen von Warnungsregeln in Azure Monitor sind Metrikwarnungen und Protokollsuchwarnungen. Der Typ der für ein bestimmtes Szenario erstellten Warnungsregel hängt vom Standort der Daten ab, für die Sie Warnungen erstellen.
Es kann vorkommen, dass Daten für ein bestimmtes Warnungsszenario sowohl in Form von Metriken als auch in Protokollen verfügbar sind. Wenn ja, müssen Sie ermitteln, welcher Regeltyp verwendet werden soll. Vielleicht sind Sie auch flexibel in Bezug auf die Art und Weise der Sammlung bestimmter Daten und legen die Methode für die Datenerfassung basierend auf dem gewünschten Typ der Warnungsregel fest.
Metrikwarnungen
Metrikwarnungen werden häufig zu folgenden Zwecken verwendet:
- Warnung, wenn eine bestimmte Metrik einen Schwellenwert überschreitet. Ein Beispiel hierfür wäre eine hohe CPU-Auslastung eines Computers.
Datenquellen für Metrikwarnungen:
- Hostmetriken für Azure-VMs, die automatisch erfasst werden
- Metriken, die vom Azure Monitor-Agent zum Gastbetriebssystem gesammelt werden
Protokollsuchwarnungen
Häufige Anwendungsfälle für Protokollsuchwarnungen:
- Warnung, wenn ein bestimmtes Ereignis oder ein Ereignismuster im Windows-Ereignisprotokoll oder Syslog gefunden wird. Diese Warnungsregeln messen typischerweise die von der Abfrage zurückgegebenen Tabellenzeilen.
- Warnung basierend auf einer Berechnung numerischer Daten für mehrere Computer. Diese Warnungsregeln messen typischerweise die Berechnung einer numerischen Spalte in den Abfrageergebnissen.
Datenquellen für Protokollsuchwarnungen:
- Alle Daten, die in einem Log Analytics-Arbeitsbereich gesammelt werden
Skalieren von Warnungsregeln
Da Sie möglicherweise über zahlreiche VMs mit den gleichen Überwachungsanforderungen verfügen, möchten Sie nicht für jede VM eine eigene Warnregel erstellen. Außerdem möchten Sie sicherstellen, dass es je nach Art der Regel verschiedene Strategien gibt, um die Anzahl der von Ihnen zu verwaltenden Warnungsregeln zu begrenzen. Jede dieser Strategien hängt vom Verständnis der Zielressource der Warnungsregel ab.
Metrikwarnungsregeln
VMs unterstützen Warnungsregeln für verschiedene Ressourcenmetriken, wie beschrieben unter Überwachen mehrerer Ressourcen. So können Sie eine einzige Metrikwarnungsregel erstellen, die für alle VMs in einer Ressourcengruppe oder einem Abonnement innerhalb derselben Region gilt.
Beginnen Sie mit den empfohlenen Warnungen, und erstellen Sie für jede eine entsprechende Regel, die Ihr Abonnement oder eine Ressourcengruppe als Zielressource verwendet. Sie müssen die Regeln für jede Region duplizieren, wenn Sie über Computer in mehreren Regionen verfügen.
Wenn Sie Anforderungen für weitere Metrikwarnungsregeln identifizieren, befolgen Sie die gleiche Strategie, indem Sie ein Abonnement oder eine Ressourcengruppe als Zielressource verwenden:
- Minimieren Sie die Anzahl von Warnungsregeln, die Sie verwalten müssen.
- Stellen Sie sicher, dass sie automatisch auf alle neuen Computer angewendet werden.
Warnungsregeln für die Protokollsuche
Wenn Sie die Zielressource einer Warnungsregel für die Protokollsuche auf einen bestimmten Computer festlegen, beschränken sich die Abfragen auf Daten im Zusammenhang mit diesem Computer, und Sie erhalten individuelle Warnmeldungen für diesen Computer. Dadurch ist für jeden Computer eine eigene Warnungsregel erforderlich.
Wenn Sie die Zielressource einer Warnungsregel für die Protokollsuche auf einen Log Analytics-Arbeitsbereich festlegen, haben Sie Zugriff auf alle Daten in diesem Arbeitsbereich. Aus diesem Grund können Sie Warnungen zu Daten von allen Computern in der Arbeitsgruppe mit einer einzigen Regel erhalten. Auf diese Weise können Sie eine einzige Warnung für alle Computer erstellen. Mithilfe von Dimensionen können Sie dann eine separate Warnung für die einzelnen Computer erstellen.
Angenommen, Sie möchten eine Warnung ausgeben, wenn im Windows-Ereignisprotokoll ein Ereignis von einem beliebigen Computer erzeugt wird. Sie müssen zuerst eine Datensammlungsregel erstellen, wie in Sammeln von Daten mit Azure Monitor Agent beschrieben, um diese Ereignisse an die EventTabelle im Log Analytics-Arbeitsbereich zu senden. Anschließend könnten Sie eine Warnungsregel erstellen, die diese Tabelle unter Verwendung des Arbeitsbereichs als Zielressource und der in der folgenden Abbildung dargestellten Bedingung abfragt.
Die Abfrage gibt einen Datensatz für alle Fehlermeldungen auf einem beliebigen Computer zurück. Verwenden Sie die Option Nach Dimension teilen, und geben Sie _ResourceId an, um die Regel anzuweisen, für jeden Computer eine Warnung zu erstellen, wenn mehrere Computer in den Ergebnissen zurückgegeben werden.
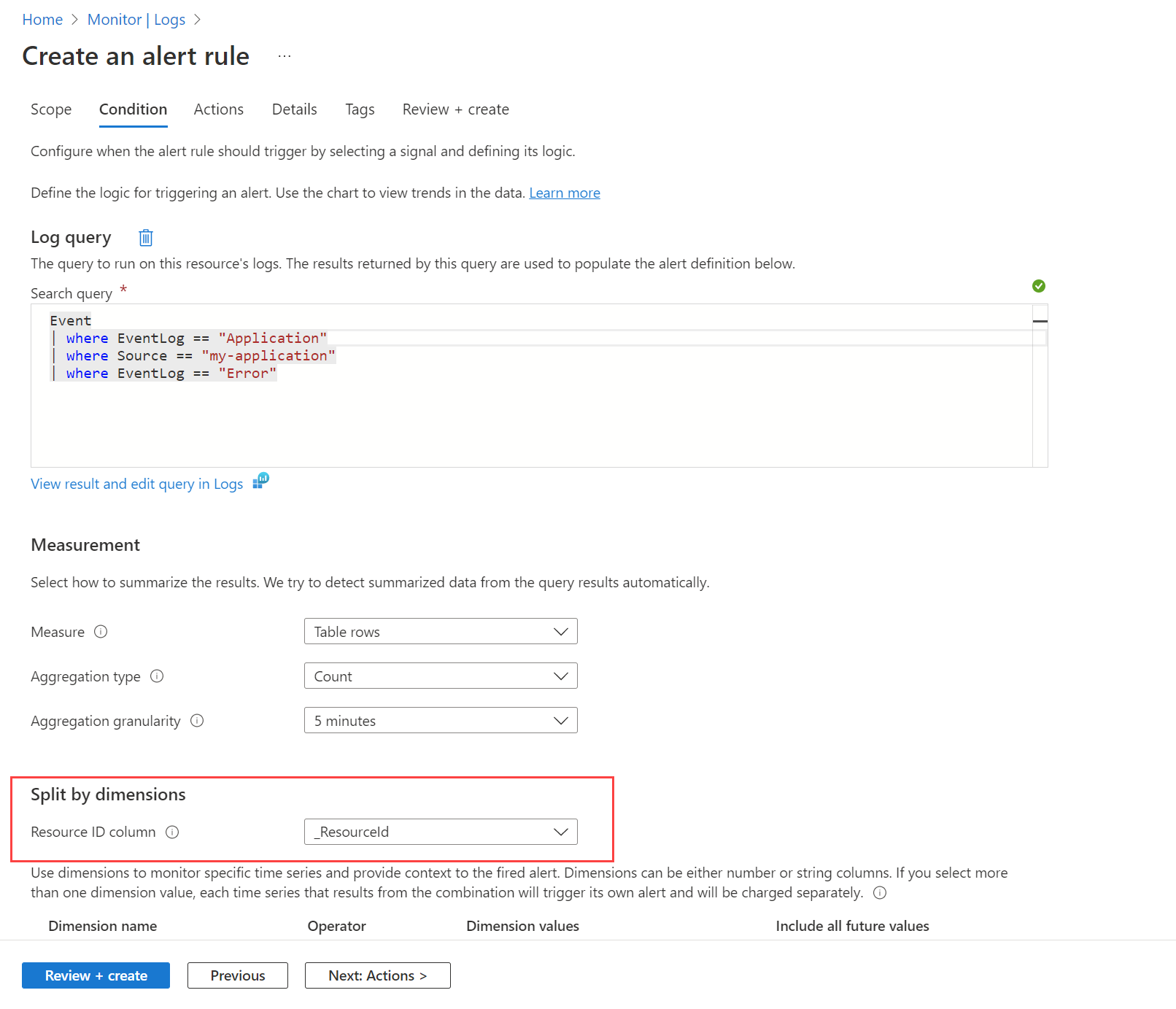
Abmessungen
Abhängig von den Informationen, die Sie in die Warnung aufnehmen möchten, müssen Sie möglicherweise eine Aufteilung mit anderen Dimensionen vornehmen. Stellen Sie in diesem Fall sicher, dass die erforderlichen Dimensionen in der Abfrage mit den Operatoren project oder extend projiziert werden. Legen Sie das Feld Spalte mit Ressourcen-ID auf Nicht aufteilen fest, und schließen Sie alle sinnvollen Dimensionen in die Liste ein. Stellen Sie sicher, dass das Kontrollkästchen Alle zukünftigen Werte einbeziehen aktiviert ist, damit alle von der Abfrage zurückgegebenen Werte einbezogen werden.
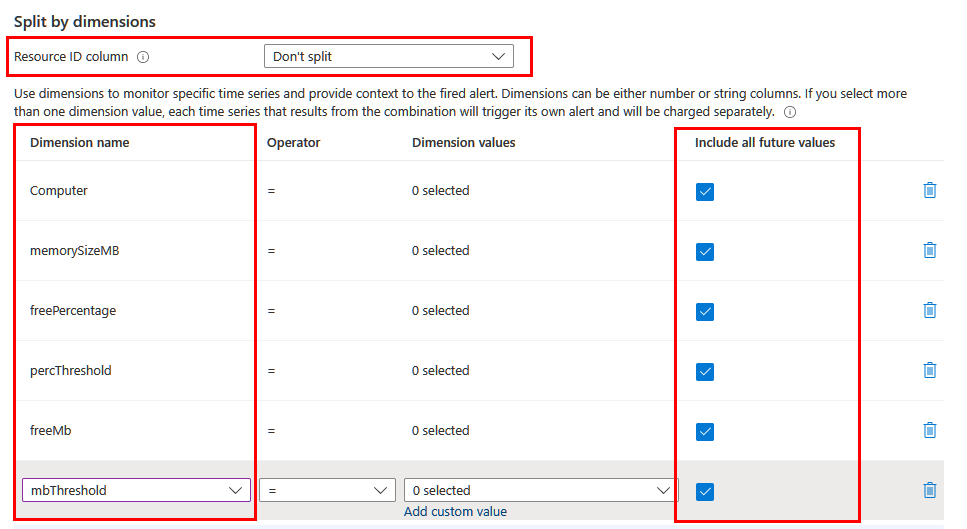
Dynamische Schwellwerte
Ein weiterer Vorteil bei der Verwendung von Warnungsregeln für die Protokollsuche ist die Möglichkeit, eine komplexe Logik zur Bestimmung des Schwellenwerts in die Abfrage aufzunehmen. Sie können den Schwellenwert hartcodieren, auf alle Ressourcen anwenden oder ihn dynamisch basierend auf einem Feld oder einem berechneten Wert berechnen. Der Schwellenwert wird nur unter bestimmten Bedingungen auf Ressourcen angewendet. Sie könnten beispielsweise eine Warnung auf Grundlage des verfügbaren Arbeitsspeichers erstellen, aber nur für Computer mit einer bestimmten Menge an Gesamtarbeitsspeicher.
Gängige Warnungsregeln
Im folgenden Abschnitt werden gängige Warnungsregeln für VMs in Azure Monitor aufgelistet. Für jede Regel werden Details zu Metrikwarnungen und Protokollsuchwarnungen bereitgestellt. Eine Orientierungshilfe zur Auswahl des Warnungstyps finden Sie unter Warnungstypen. Wenn Sie mit dem Prozess zum Erstellen von Warnungsregeln in Azure Monitor nicht vertraut sind, lesen Sie die Anweisungen zum Erstellen einer neuen Warnungsregel.
Hinweis
Die hier aufgeführten Details zu Protokollsuchwarnungen basieren auf Daten, die mit VM Insights gesammelt wurden, das eine Reihe allgemeiner Leistungsindikatoren für das Clientbetriebssystem bereitstellt. Dieser Name ist unabhängig vom Betriebssystemtyp.
Computerverfügbarkeit
Eine der häufigsten Überwachungsanforderungen für einen virtuellen Computer besteht darin, eine Warnung für den Fall zu erstellen, dass seine Ausführung beendet wird. Die beste Methode ist die Erstellung einer Metrikwarnungsregel in Azure Monitor unter Verwendung der VM-Verfügbarkeitsmetrik, die sich derzeit in der öffentlichen Vorschau befindet. Eine vollständige exemplarische Vorgehensweise zu dieser Metrik finden Sie unter Erstellen einer Verfügbarkeitswarnungsregel für einen virtuellen Azure-Computer.
Eine Warnungsregel ist auf ein Aktivitätsprotokollsignal beschränkt. Für jede Bedingung muss also eine Warnungsregel erstellt werden. Für „Startet oder stoppt die VM“ sind beispielsweise zwei Warnungsregeln erforderlich. Um jedoch benachrichtigt zu werden, wenn die VM neu gestartet wird, ist nur eine Warnungsregel erforderlich.
Erstellen Sie wie unter Skalieren von Warnungsregeln beschrieben eine Verfügbarkeitswarnungsregel, indem Sie ein Abonnement oder eine Ressourcengruppe als Zielressource verwenden. Die Regel gilt für mehrere virtuelle Computer, einschließlich neuer Computer, die Sie nach der Warnungsregel erstellen.
Agent-Takt
Der Agent-Takt und die Warnung, dass ein Computer nicht verfügbar ist, unterscheiden sich geringfügig voneinander, da der Azure Monitor-Agent benötigt wird, um ein Taktsignal zu senden. Durch den Agent-Takt können Sie eine Warnung erhalten, wenn der Computer ausgeführt wird, der Agent jedoch nicht reagiert.
Metrikwarnungsregeln
Jeder Log Analytics-Arbeitsbereich umfasst eine Metrik namens Heartbeat. Jede VM, die mit diesem Arbeitsbereich verbunden ist, sendet jede Minute einen Wert für die Heartbeatmetrik. Da es sich bei dem Computer um eine Dimension der Metrik handelt, können Sie eine Warnung senden, wenn ein beliebiger Computer keinen Heartbeat sendet. Legen Sie den Aggregationstyp auf Anzahl und den Schwellenwert auf die entsprechende Granularität der Auswertung fest.
Warnungsregeln für die Protokollsuche
Protokollsuchwarnungen verwenden die Tabelle Heartbeat, die für jede Minute einen Heartbeatdatensatz von jedem Computer enthalten sollte.
Verwenden Sie eine Regel mit folgender Abfrage:
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
CPU-Warnungen
In diesem Abschnitt werden CPU-Warnungen beschrieben.
Metrikwarnungsregeln
| Ziel | Metrik |
|---|---|
| Host | „CPU-Auslastung in Prozent“ (in empfohlenen Warnungen enthalten) |
| Windows-Gast | \Prozessorinformationen(_Gesamt)%Prozessorzeit |
| Linux-Gast | cpu/usage_active |
Warnungsregeln für die Protokollsuche
CPU-Auslastung
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Arbeitsspeicherwarnungen
In diesem Abschnitt werden Speicherwarnungen beschrieben.
Metrikwarnungsregeln
| Ziel | Metrik |
|---|---|
| Host | „Verfügbarer Arbeitsspeicher in Byte“ (Vorschau, in empfohlenen Warnungen enthalten) |
| Windows-Gast | \ArbeitsspeicherZugesicherte verwendete Bytes (%) \Memory\Verfügbare Bytes |
| Linux-Gast | mem/available mem/available_percent |
Warnungsregeln für die Protokollsuche
Hinweis
Wenn Sie die Warnung zu einem Datenträger angeben müssen, können Sie diese der folgenden Abfrage hinzufügen: | where parse_json(Tags).["vm.azm.ms/mountId"] == "C:"Verfügbarer Speicher in MB.
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Verfügbarer Arbeitsspeicher in Prozent
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
Datenträgerwarnungen
In diesem Abschnitt werden Festplattenwarnungen beschrieben.
Metrikwarnungsregeln
| Ziel | Metrik |
|---|---|
| Windows-Gast | \Logischer Datenträger(_Gesamt)Freier Speicherplatz (%) \Logischer Datenträger(_Gesamt)\MB frei |
| Linux-Gast | disk/free disk/free_percent |
Warnungsregeln für die Protokollsuche
Nutzung von logischem Datenträger – alle Datenträger auf jedem Computer
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Nutzung von logischem Datenträger – einzelne Datenträger
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
IOPS des logischen Datenträgers
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Datenrate des logischen Datenträgers
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Netzwerkwarnungen
Metrikwarnungsregeln
| Ziel | Metrik |
|---|---|
| Host | „Eingehender Netzwerkverkehr gesamt“, „Ausgehender Netzwerkverkehr gesamt“ (in empfohlenen Warnungen enthalten) |
| Windows-Gast | \Network Interface\Bytes Sent/sec \Logischer Datenträger(_Gesamt)\MB frei |
| Linux-Gast | disk/free disk/free_percent |
Warnungsregeln für die Protokollsuche
An Netzwerkschnittstellen empfangene Bytes – alle Schnittstellen
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
An Netzwerkschnittstellen empfangene Bytes – einzelne Schnittstellen
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
An Netzwerkschnittstellen gesendete Bytes – alle Schnittstellen
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
An Netzwerkschnittstellen gesendete Bytes – einzelne Schnittstellen
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Windows- und Linux-Ereignisse
Im folgenden Beispiel wird eine Warnung erstellt, wenn ein bestimmtes Windows-Ereignis auftritt. Dabei wird eine Warnungsregel für metrische Messungen verwendet, damit für jeden Computer eine eigene Warnung zu erstellt wird.
Erstellen Sie eine Warnungsregel bei einem bestimmten Windows-Ereignis. In diesem Beispiel ist ein Ereignis im Anwendungsprotokoll dargestellt. Geben Sie für den Schwellenwert den Wert 0 an, und legen Sie für aufeinanderfolgende Sicherheitsverletzungen einen Wert größer 0 fest.
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)Erstellen Sie eine Warnungsregel für Syslog-Ereignisse mit einem bestimmten Schweregrad. Im folgenden Beispiel sind Ereignisse im Zusammenhang mit Autorisierungsfehlern dargestellt. Geben Sie für den Schwellenwert den Wert 0 an, und legen Sie für aufeinanderfolgende Sicherheitsverletzungen einen Wert größer 0 fest.
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
Benutzerdefinierte Leistungsindikatoren
Erstellen Sie eine Warnung für den maximal zulässigen Wert eines Zählers.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by ComputerErstellen Sie eine Warnung für den Durchschnittswert eines Zählers.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer