Entwerfen von global verfügbaren Diensten mit Azure SQL-Datenbank
Gilt für:: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Beim Erstellen und Bereitstellen von Clouddiensten mit Azure SQL-Datenbank verwenden Sie aktive Georeplikation oder Failovergruppen, um bei regionalen Ausfällen und schwerwiegenden Fehlern für Resilienz zu sorgen. Mit demselben Feature können Sie global verteilte Anwendungen erstellen, die für den lokalen Zugriff auf die Daten optimiert sind. In diesem Artikel werden gängige Anwendungsmuster beschrieben, einschließlich der Vor- und Nachteile der einzelnen Optionen.
Hinweis
Wenn Sie Premium-Datenbanken, unternehmenskritische Datenbanken oder Pools für elastische Datenbanken verwenden, können Sie sie resistent gegenüber regionalen Ausfällen machen, indem Sie sie auf die Konfiguration der zonenredundanten Bereitstellung umstellen. Informationen finden Sie unter Hochverfügbarkeit und Azure SQL-Datenbank.
Szenario 1: Verwenden von zwei Azure-Regionen für die Geschäftskontinuität mit minimalen Ausfallzeiten
In diesem Szenario weist die Anwendung die folgenden Merkmale auf:
- Die Anwendung ist in einer Azure-Region aktiv.
- Alle Datenbanksitzungen erfordern Lese- und Schreibzugriff (RW) auf Daten
- Die Webebene und die Datenebene müssen verbunden werden, um Latenzzeiten und Datenverkehrskosten zu reduzieren
- Im Wesentlichen stellen Ausfallzeiten für diese Anwendungen ein höheres Unternehmensrisiko dar als Datenverluste
In diesem Fall wird die Topologie für die Anwendungsbereitstellung für den Umgang mit regionalen Notfällen optimiert, bei denen das Failover für alle Anwendungskomponenten gleichzeitig ausgeführt werden muss. Diese Topologie ist im folgenden Diagramm dargestellt. Um geografische Redundanz zu erzielen, werden die Ressourcen der Anwendung in Region A und Region B bereitgestellt. Die Ressourcen in Region B werden jedoch erst genutzt, wenn in Region A Fehler auftreten. Zwischen den beiden Regionen wird eine Failovergruppe konfiguriert, um die Datenbankkonnektivität, die Replikation und das Failover zu verwalten. Der Webdienst in beiden Regionen wird so konfiguriert, dass der Zugriff auf die Datenbank über den Lese-/Schreiblistener <Name der Failovergruppe>.database.windows.net erfolgt (1). Azure Traffic Manager ist für die Verwendung der prioritätsbasierten Routingmethode eingerichtet (2).
Hinweis
Azure Traffic Manager wird in diesem Artikel ausschließlich zur Veranschaulichung verwendet. Sie können jede Lastenausgleichslösung einsetzen, die die prioritätsbasierte Routingmethode unterstützt.
Das folgende Diagramm zeigt diese Konfiguration vor einem Ausfall:
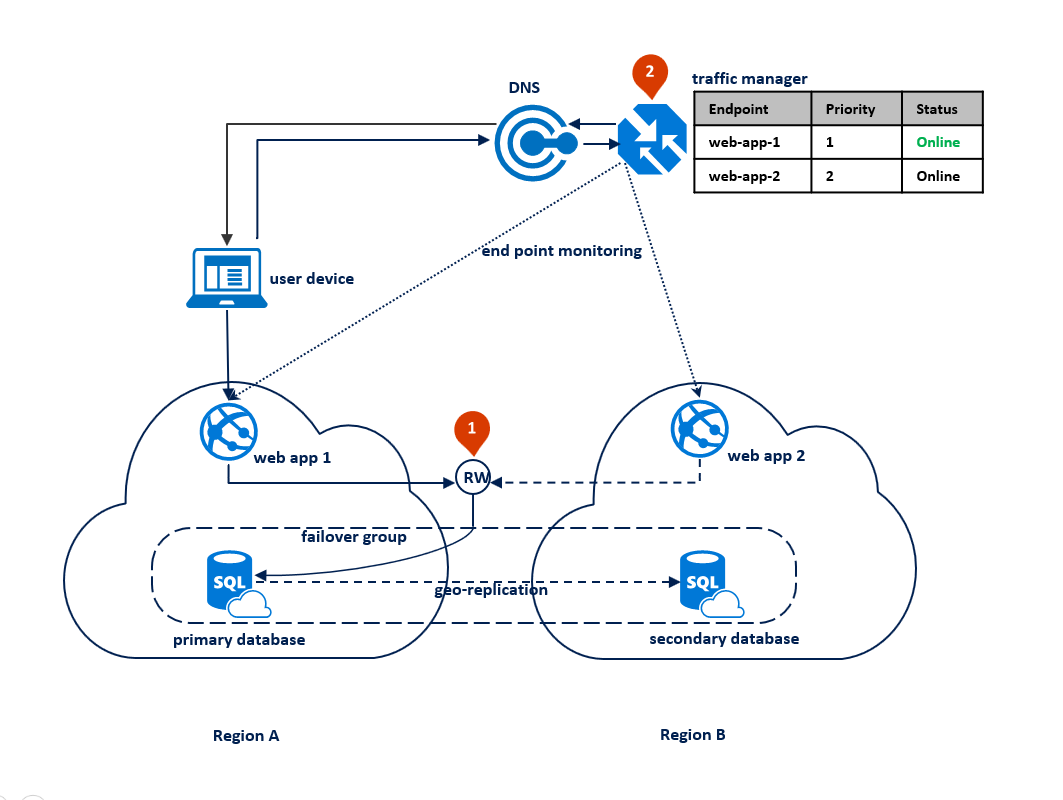
Nach einem Ausfall in der primären Region erkennt SQL-Datenbank, dass auf die primäre Datenbank nicht zugegriffen werden kann, und löst basierend auf den Parametern der Richtlinie für automatisches Failover ein Failover auf die sekundäre Region aus (1). Abhängig von Ihrer Anwendungs-SLA können Sie eine Toleranzperiode konfigurieren, die die Zeit zwischen der Erkennung des Ausfalls und dem Failover selbst steuert. Es ist möglich, dass Azure Traffic Manager das Endpunktfailover initiiert, bevor die Failovergruppe das Failover der Datenbank auslöst. In diesem Fall kann die Webanwendung die Verbindung mit der Datenbank nicht sofort wiederherstellen. Die Verbindungswiederherstellungen sind jedoch automatisch erfolgreich, sobald das Datenbankfailover abgeschlossen ist. Wenn die fehlerhafte Region wiederhergestellt und wieder online ist, stellt die alte primäre Datenbank automatisch wieder eine Verbindung als neue sekundäre Datenbank her. Das folgende Diagramm veranschaulicht die Konfiguration nach dem Failover.
Hinweis
Alle committeten Transaktionen nach dem Failover gehen bei der Verbindungswiederherstellung verloren. Nach Abschluss des Failovers kann die Anwendung in Region B die Verbindung wiederherstellen und die Verarbeitung der Benutzeranforderungen erneut starten. Sowohl die Webanwendung als auch die primäre Datenbank befinden sich nun in Region B und bleiben verbunden.
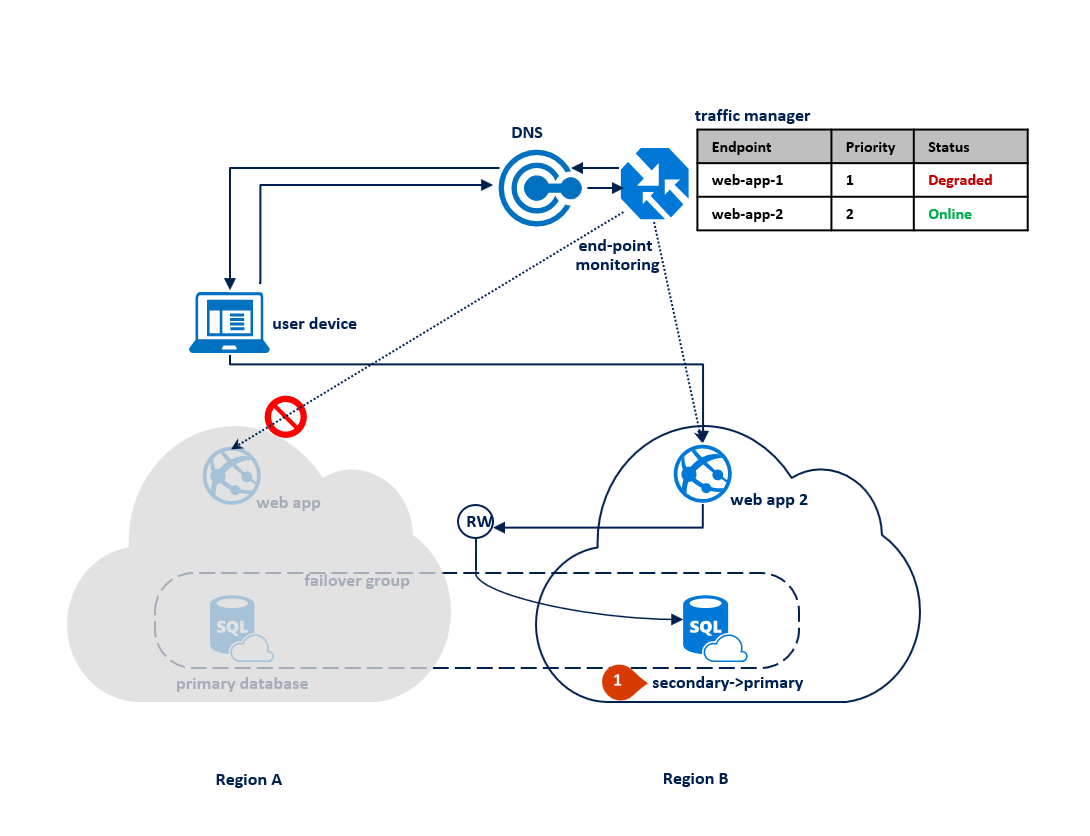
Bei einem Ausfall in Region B wird der Replikationsprozess zwischen der primären und der sekundären Datenbank unterbrochen, die Verbindung zwischen beiden bleibt jedoch erhalten (1). Traffic Manager erkennt, dass die Verbindung mit Region B unterbrochen ist und markiert den Endpunkt „web-app-2“ als beeinträchtigt (2). Dies hat keine Auswirkung auf die Leistung der Anwendung, die Datenbank ist jedoch ungeschützt, und es besteht ein höheres Risiko eines Datenverlusts für den Fall, dass Region A auch ausfällt.
Hinweis
Für die Notfallwiederherstellung empfehlen wir eine Konfiguration, bei der die Anwendungsbereitstellung auf zwei Regionen beschränkt ist. Der Grund ist, dass die meisten Azure-Gebiete nur zwei Regionen aufweisen. Diese Konfiguration bietet keinen Schutz Ihrer Anwendung vor einem gleichzeitigen schwerwiegenden Ausfall beider Regionen. Im unwahrscheinlichen Fall eines solchen Ausfalls können Sie Ihre Datenbanken mithilfe eines Geowiederherstellungsvorgangs in einer dritten Region wiederherstellen. Weitere Informationen finden Sie in der Anleitung zur Azure SQL-Datenbank-Notfallwiederherstellung.
Nach Behebung der Ausfallursache wird die sekundäre Datenbank automatisch mit der primären synchronisiert. Während der Synchronisierung kann die Leistung der primären Datenbank beeinträchtigt werden. Die spezifischen Auswirkungen hängen von der in der neuen primären Datenbank erfassten Datenmenge seit dem Failover ab.
Hinweis
Nachdem der Ausfall behoben wurde, beginnt der Traffic Manager mit dem Routing der Verbindungen an die Anwendung in Region A als Endpunkt mit höherer Priorität. Wenn Sie beabsichtigen, die primäre Datenbank für eine Weile in Region B beizubehalten, sollten Sie die Prioritätstabelle im Traffic Manager-Profil entsprechend ändern.
Das folgende Diagramm zeigt einen Ausfall in der sekundären Region:
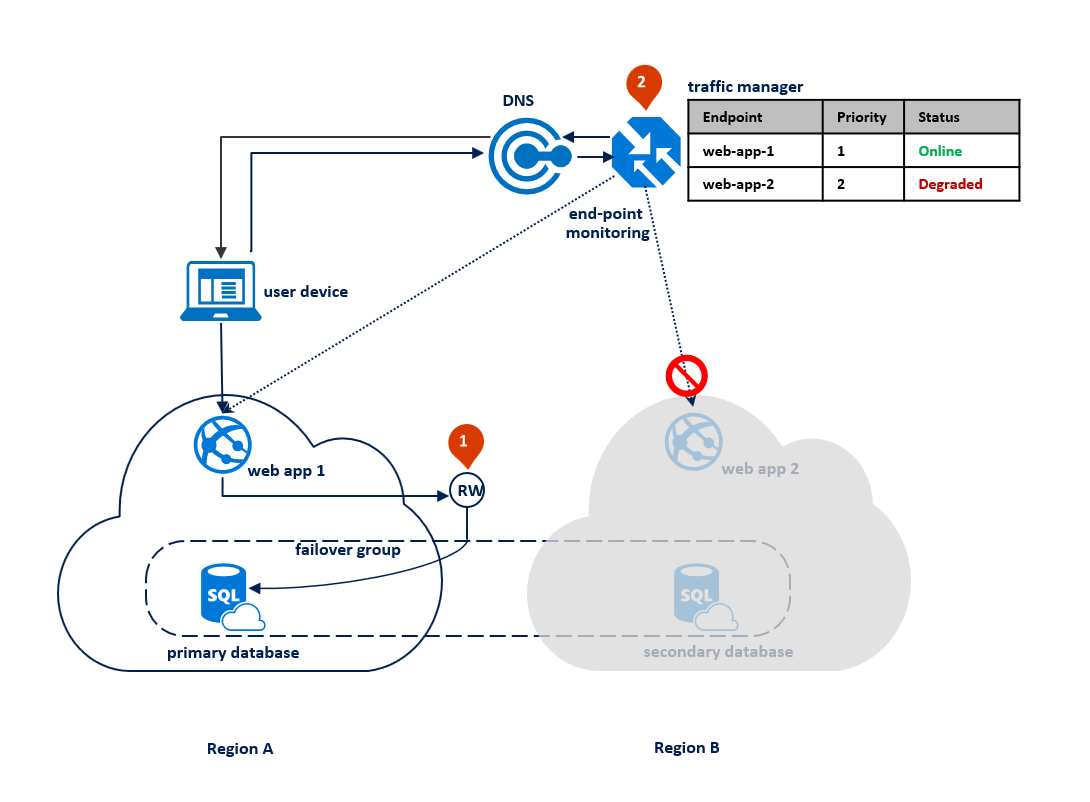
Die Hauptvorteile dieses Entwurfsmusters sind:
- Die gleiche Webanwendung wird in beiden Regionen ohne regionsspezifische Konfiguration bereitgestellt und erfordert keine zusätzliche Logik zum Verwalten des Failovers.
- Die Leistung der Anwendung ist vom Failover nicht betroffen, da die Webanwendung und die Datenbank stets verbunden sind.
Der Hauptnachteil besteht darin, dass die Anwendungsressourcen in Region B die meiste Zeit zu gering ausgelastet sind.
Szenario 2: Azure-Regionen für die Geschäftskontinuität mit maximaler Beibehaltung von Daten
Diese Option eignet sich am besten für Anwendungen mit den folgenden Merkmalen:
- Jeder Datenverlust stellt ein hohes Geschäftsrisiko dar. Das Datenbankfailover darf nur als letzte Möglichkeit in Frage kommen, falls der Ausfall durch einen schwerwiegenden Fehler verursacht wird.
- Die Anwendung unterstützt schreibgeschützte Betriebsmodi und Betriebsmodi mit Lese-/Schreibzugriff und kann für gewisse Zeit im „schreibgeschützten Modus“ betrieben werden.
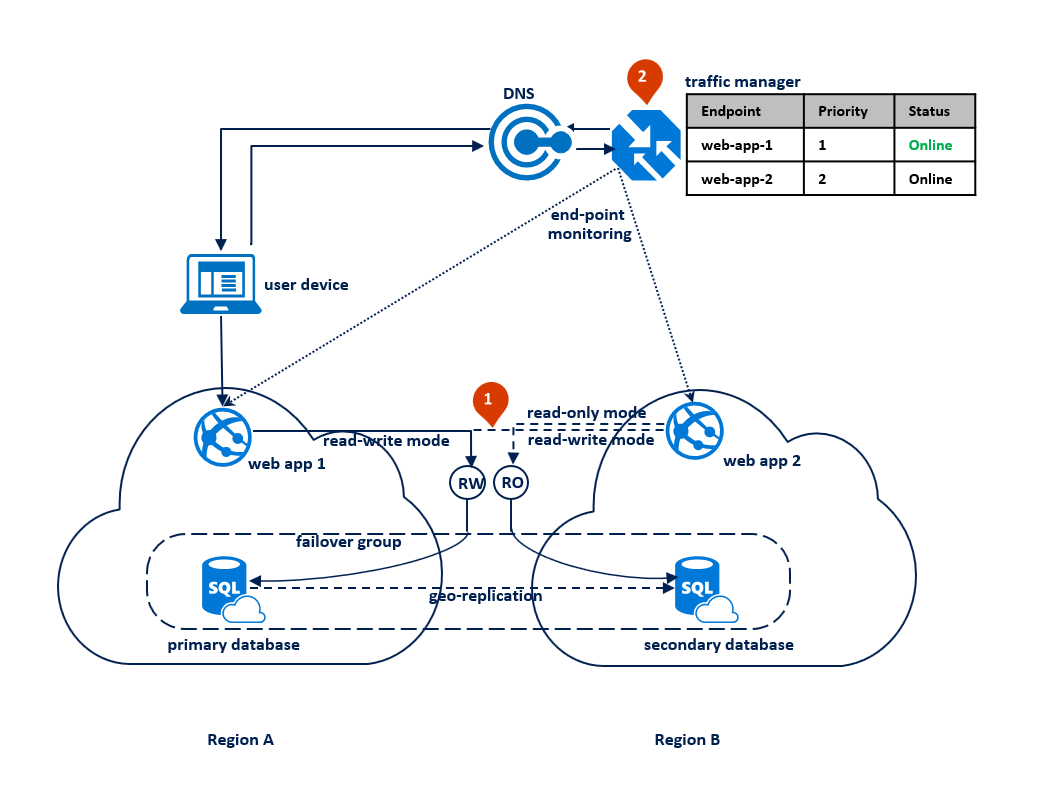
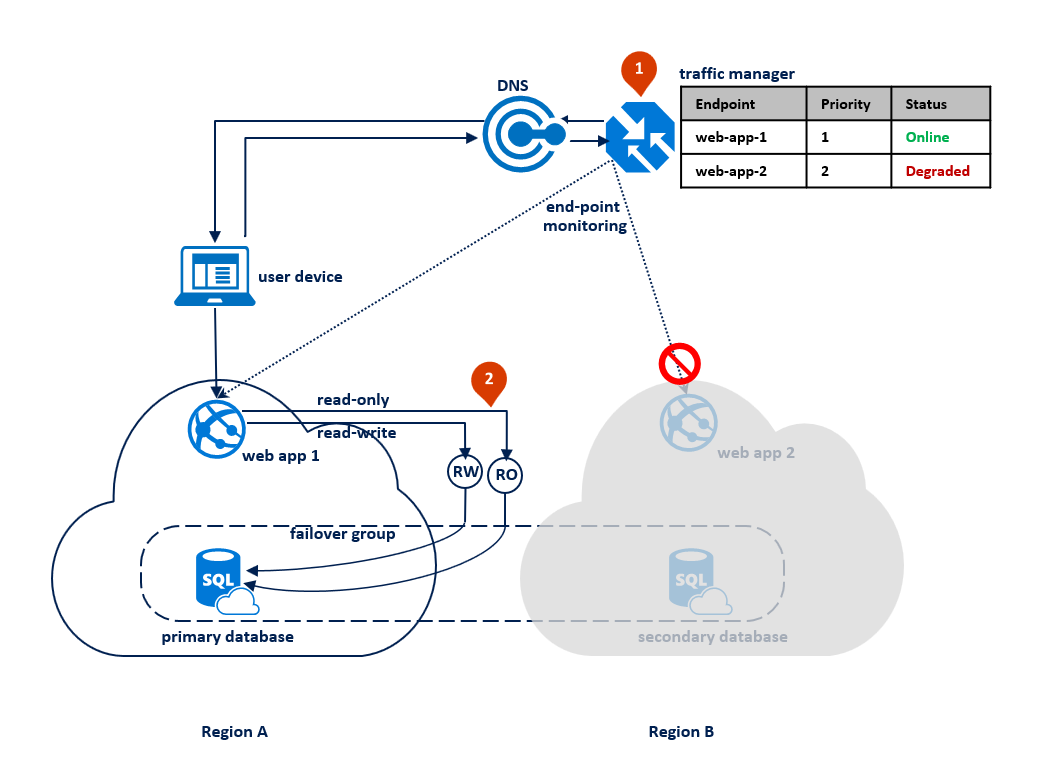
In diesem Muster wechselt die Anwendung in den schreibgeschützten Modus, sobald bei Lese-/Schreibverbindungen Timeoutfehler auftreten. Die Webanwendung wird in beiden Regionen bereitgestellt und enthält eine Verbindung mit dem Lese-/Schreib-Listenerendpunkt und eine andere Verbindung mit dem schreibgeschützten Listenerendpunkt (1). Das Traffic Manager-Profil sollte die prioritätsbasierte Routingmethode verwenden. Die Endpunktüberwachung sollte für den Anwendungsendpunkt in jeder Region aktiviert sein (2).
Das folgende Diagramm veranschaulicht diese Konfiguration vor einem Ausfall:
Wenn Traffic Manager einen Fehler bei der Verbindung mit Region A erkennt, leitet er den Benutzerdatenverkehr automatisch zur Anwendungsinstanz in Region B um. Bei diesem Muster ist es wichtig, dass Sie die Toleranzperiode mit Datenverlust auf einen ausreichend hohen Wert festlegen, z. B. 24 Stunden. Dies garantiert, dass Datenverluste verhindert werden, wenn der Ausfall innerhalb dieser Zeit behoben wird. Wenn die Webanwendung in Region B aktiviert wird, treten bei den Lese-/ Schreibvorgängen Fehler auf. An diesem Punkt sollte sie in den schreibgeschützten Modus wechseln (1). In diesem Modus werden die Anforderungen automatisch an die sekundäre Datenbank weitergeleitet. Wenn der Ausfall durch einen schwerwiegenden Fehler verursacht wird, kann er sehr wahrscheinlich nicht innerhalb der Toleranzperiode behoben werden. Nach Ablauf der Toleranzperiode löst die Failovergruppe das Failover aus. Danach ist der Lese-/Schreiblistener verfügbar, und die Verbindungen mit ihm sind erfolgreich (2). Das folgende Diagramm veranschaulicht die zwei Phasen des Wiederherstellungsprozesses.
Hinweis
Wenn die Ausfallursache in der primären Region innerhalb der Toleranzperiode beseitigt wird, erkennt Traffic Manager die Wiederherstellung der Konnektivität in der primären Region und leitet den Datenverkehr der Benutzer wieder zur Anwendungsinstanz in Region A. Diese Anwendungsinstanz nimmt den Betrieb im Lese-/Schreibmodus unter Verwendung der primären Datenbank in Region A wie im vorherigen Diagramm veranschaulicht wieder auf.
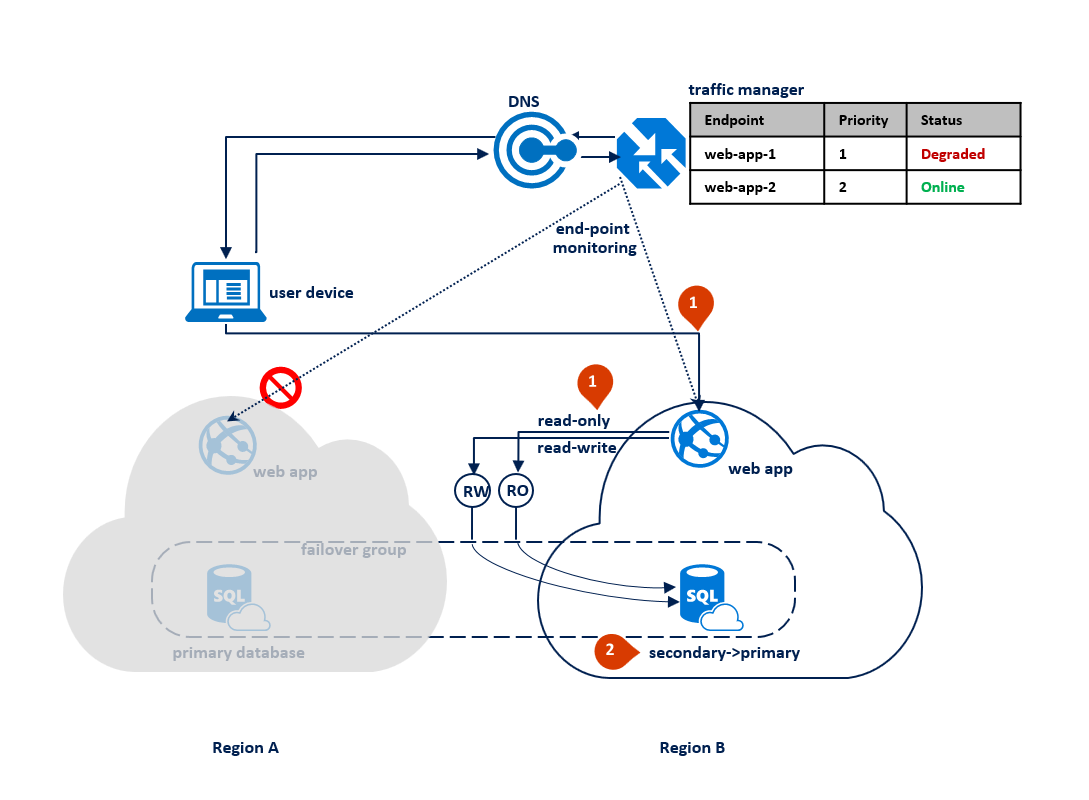
Bei einem Ausfall in Region B erkennt Traffic Manager den Ausfall des Endpunkts „web-app-2“ in Region B und markiert ihn als beeinträchtigt (1). In der Zwischenzeit leitet die Failovergruppe den schreibgeschützten Listener nach Region A um (2). Der Endbenutzer wird durch diesen Ausfall nicht beeinträchtigt, aber die primäre Datenbank wird während des Ausfalls verfügbar gemacht. Das folgende Diagramm zeigt einen Fehler in der sekundären Region:
Nach Behebung des Ausfalls wird die sekundäre Datenbank sofort mit der primären synchronisiert, und der schreibgeschützte Listener wird wieder zur sekundären Datenbank in Region B umgeleitet. Während der Synchronisierung könnte die Leistung der primären Datenbank abhängig vom Umfang der zu synchronisierenden Daten leicht beeinträchtigt werden.
Dieses Entwurfsmuster bietet mehrere Vorteile:
- Datenverluste während temporärer Ausfälle werden verhindert.
- Ausfallzeiten hängen nur davon ab, wie schnell Traffic Manager den Verbindungsausfall erkennt, was konfigurierbar ist.
Der Nachteil besteht darin, dass die Anwendung im schreibgeschützten Modus betrieben werden können muss.
Planen der Geschäftskontinuität: Auswählen eines Anwendungsentwurfs für die cloudbasierte Notfallwiederherstellung
Für Ihre spezifische Strategie einer cloudbasierten Notfallwiederherstellung können diese Muster kombiniert oder erweitert werden, um die Anforderungen Ihrer Anwendung bestmöglich zu erfüllen. Wie bereits erwähnt, basiert die von Ihnen gewählte Strategie auf der SLA, die Sie Ihren Kunden anbieten möchten, und auf der Topologie der Anwendungsbereitstellung. Um Ihnen die Entscheidung zu erleichtern, werden in der folgenden Tabelle die Optionen basierend auf der RPO (Recovery Point Objective) und der geschätzten Wiederherstellungszeit verglichen.
| Muster | RPO | Geschätzte Wiederherstellungszeit |
|---|---|---|
| Aktiv-/Passiv-Bereitstellung für Notfallwiederherstellung mit zusammengestelltem Datenbankzugriff | Lese-/Schreibzugriff < 5 Sek | Zeitpunkt der Fehlererkennung + DNS-TTL |
| Aktiv-/Aktiv-Bereitstellung für den Anwendungslastenausgleich | Lese-/Schreibzugriff < 5 Sek. | Zeitpunkt der Fehlererkennung + DNS-TTL |
| Aktiv-/Passiv-Bereitstellung für die Beibehaltung von Daten | Schreibgeschützter Zugriff < 5 Sek | Schreibgeschützter Zugriff = 0 |
| Lese-/Schreibzugriff = 0 | Lese-/Schreibzugriff = Zeitpunkt der Fehlererkennung + Toleranzperiode mit Verlust von Daten |
Nächste Schritte
- Eine Übersicht und verschiedene Szenarien zum Thema Geschäftskontinuität finden Sie unter Übersicht über die Geschäftskontinuität
- Informationen zur aktiven Georeplikation finden Sie unter Aktive Georeplikation.
- Informationen zu Failovergruppen finden Sie unter Failovergruppen.
- Informationen zur Verwendung der aktiven Georeplikation mit Pools für elastische Datenbanken finden Sie unter Strategien zur Notfallwiederherstellung mit Pools für elastische Datenbanken.