Erstellen von Berichten für horizontal hochskalierte Clouddatenbanken (Vorschau)
Gilt für:: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
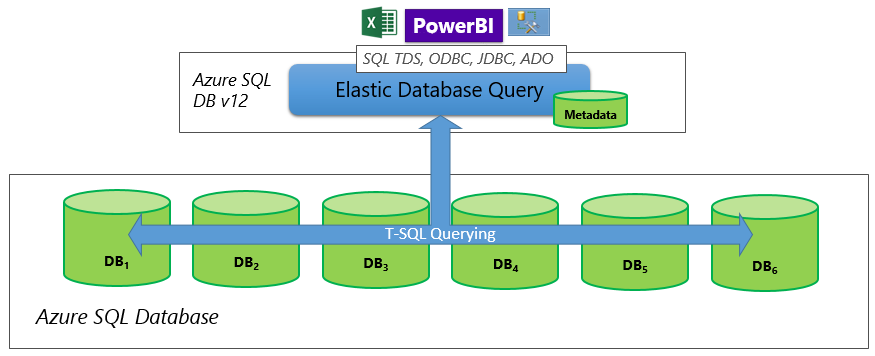
Horizontal partitionierte Datenbanken verteilen Zeilen auf einer horizontal hochskalierten Datenebene. Das Schema ist auf allen teilnehmenden Datenbanken identisch, auch bekannt als horizontale Partitionierung. Mit einer flexiblen Abfrage können Sie Berichte erstellen, die alle Datenbanken in einer horizontal partitionierten Datenbank umfassen.
Eine Schnellstartanleitung finden Sie unter Erstellen von Berichten für horizontal hochskalierte Clouddatenbanken.
Informationen zu nicht partitionierten Datenbanken finden Sie unter Ausführen von Abfragen über Clouddatenbanken mit unterschiedlichen Schemas hinweg.
Voraussetzungen
- Erstellen Sie mithilfe der Clientbibliothek für elastische Datenbanken eine Shardzuordnung. Informationen dazu finden Sie unter Verwalten der Shardzuordnung. Sie können auch die Beispiel-App in Erste Schritte mit Tools für elastische Datenbanken verwenden.
- Alternativ dazu können Sie Migrate existing databases to scaled-out databases(Migrieren vorhandener Datenbanken zu horizontal hochskalierten Datenbanken) lesen.
- Der Benutzer muss über die Berechtigung ALTER ANY EXTERNAL DATA SOURCE verfügen. Diese Berechtigung ist in der Berechtigung ALTER DATABASE enthalten.
- ALTER ANY EXTERNAL DATA SOURCE-Berechtigungen sind erforderlich, um auf die zu Grunde liegende Datenquelle zu verweisen.
Übersicht
Diese Anweisungen erstellen die Metadatendarstellung Ihrer Shardingdatenebene in der elastischen Abfragedatenbank.
- CREATE MASTER KEY
- CREATE DATABASE SCOPED CREDENTIAL
- CREATE EXTERNAL DATA SOURCE
- CREATE EXTERNAL TABLE
1.1 Erstellen des Datenbankhauptschlüssels und der Anmeldeinformationen
Die Anmeldeinformationen werden von der elastischen Abfrage für die Verbindung mit Ihren Remotedatenbanken verwendet.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
CREATE DATABASE SCOPED CREDENTIAL [<credential_name>] WITH IDENTITY = '<username>',
SECRET = '<password>';
Hinweis
Stellen Sie sicher, dass der „<Benutzername>“ kein „@Servername“-Suffix enthält.
1.2 Erstellen externer Datenquellen
Syntax:
<External_Data_Source> ::=
CREATE EXTERNAL DATA SOURCE <data_source_name> WITH
(TYPE = SHARD_MAP_MANAGER,
LOCATION = '<fully_qualified_server_name>',
DATABASE_NAME = '<shardmap_database_name>',
CREDENTIAL = <credential_name>,
SHARD_MAP_NAME = '<shardmapname>'
) [;]
Beispiel
CREATE EXTERNAL DATA SOURCE MyExtSrc
WITH
(
TYPE=SHARD_MAP_MANAGER,
LOCATION='myserver.database.windows.net',
DATABASE_NAME='ShardMapDatabase',
CREDENTIAL= SMMUser,
SHARD_MAP_NAME='ShardMap'
);
Rufen Sie die Liste der aktuellen externen Datenquellen ab:
select * from sys.external_data_sources;
Die externe Datenquelle verweist auf Ihre Shardzuordnung. Eine elastische Abfrage verwendet anschließend die externe Datenquelle und zugrunde liegende Shardzuordnung zum Auflisten der Datenbanken, die zur Datenebene gehören. Die gleichen Anmeldeinformationen werden während der Verarbeitung der elastischen Abfrage zum Lesen der Shardzuordnung und für den Zugriff auf die Daten in den Shards verwendet .
1.3 Erstellen externer Tabellen
Syntax:
CREATE EXTERNAL TABLE [ database_name . [ schema_name ] . | schema_name. ] table_name
( { <column_definition> } [ ,...n ])
{ WITH ( <sharded_external_table_options> ) }
) [;]
<sharded_external_table_options> ::=
DATA_SOURCE = <External_Data_Source>,
[ SCHEMA_NAME = N'nonescaped_schema_name',]
[ OBJECT_NAME = N'nonescaped_object_name',]
DISTRIBUTION = SHARDED(<sharding_column_name>) | REPLICATED |ROUND_ROBIN
Beispiel
CREATE EXTERNAL TABLE [dbo].[order_line](
[ol_o_id] int NOT NULL,
[ol_d_id] tinyint NOT NULL,
[ol_w_id] int NOT NULL,
[ol_number] tinyint NOT NULL,
[ol_i_id] int NOT NULL,
[ol_delivery_d] datetime NOT NULL,
[ol_amount] smallmoney NOT NULL,
[ol_supply_w_id] int NOT NULL,
[ol_quantity] smallint NOT NULL,
[ol_dist_info] char(24) NOT NULL
)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'orders',
OBJECT_NAME = 'order_details',
DISTRIBUTION=SHARDED(ol_w_id)
);
Rufen Sie die Liste der externen Tabellen aus der aktuellen Datenbank ab:
SELECT * from sys.external_tables;
So löschen Sie externe Tabellen:
DROP EXTERNAL TABLE [ database_name . [ schema_name ] . | schema_name. ] table_name[;]
Bemerkungen
Die DATA_SOURCE-Klausel definiert die externe Datenquelle (eine Shardzuordnung), die für die externe Tabelle verwendet wird.
Die Klauseln SCHEMA_NAME und OBJECT_NAME ordnen die Definition der externen Tabelle einer Tabelle in einem anderen Schema zu. Falls nicht angegeben, wird davon ausgegangen, dass das Schema des Remoteobjekts dbo und sein Name mit dem definierten Namen der externen Tabelle identisch ist. Dies ist nützlich, wenn der Name der Remotetabelle bereits in der Datenbank verwendet wird, in der Sie die externe Tabelle erstellen möchten. Sie möchten z. B. eine externe Tabelle zum Abrufen einer aggregierten Sicht von Katalogsichten oder DMVs für Ihre horizontal hochskalierte Datenebene definieren. Da Katalogsichten und DMVs bereits lokal vorhanden sind, können Sie ihre Namen nicht für die Definition der externen Tabelle verwenden. Verwenden Sie stattdessen in den Klauseln SCHEMA_NAME und/oder OBJECT_NAME einen anderen Namen und den Namen der Katalogsicht oder DMV. (Betrachten Sie das folgende Beispiel.)
Die DISTRIBUTION-Klausel gibt die Datenverteilung für diese Tabelle an: Der Abfrageprozessor nutzt die Informationen in der DISTRIBUTION-Klausel, um die effizientesten Abfragepläne zu erstellen.
- SHARDED bedeutet, dass Daten Datenbanken übergreifend horizontal partitioniert werden. Der Partitionierungsschlüssel für die Datenverteilung ist der Parameter <sharding_column_name>.
- REPLICATED bedeutet, dass identische Kopien der Tabelle in jeder Datenbank vorhanden sind. Sie müssen sicherstellen, dass die Replikate in allen Datenbanken identisch sind.
- ROUND_ROBIN bedeutet, dass die Tabelle mit einer anwendungsabhängigen Verteilungsmethode horizontal partitioniert wird.
Datenschichtverweis: Die DDL für externe Tabellen verweist auf eine externe Datenquelle. Die externe Datenquelle gibt eine Shardzuordnung an, die der externen Tabelle die Informationen bereitstellt, die benötigt werden, um alle Datenbanken in Ihrer Datenebene zu finden.
Sicherheitshinweise
Benutzer mit Zugriff auf die externe Tabelle erhalten automatisch Zugriff auf die zugrunde liegenden Remotetabellen gemäß den Anmeldeinformationen, die in der externen Datenquellendefinition angegeben sind. Vermeiden Sie eine unerwünschte Erhöhung von Berechtigungen durch die Anmeldeinformationen der externen Datenquelle. Verwenden Sie GRANT oder REVOKE für eine externe Tabelle, als handele es sich um eine normale Tabelle.
Nachdem Sie die externe Datenquelle und die externen Tabellen definiert haben, können Sie jetzt vollständiges T-SQL in den externen Tabellen verwenden.
Beispiel: Abfragen von horizontal partitionierten Datenbanken
Die folgende Abfrage führt eine Verknüpfung in drei Richtungen zwischen Lagern, Bestellungen und Auftragspositionen aus. Sie nutzt mehrere Aggregate und einen selektiven Filter. Es wird Folgendes vorausgesetzt: 1.) eine horizontale Partitionierung (Sharding), 2.) dass für Lager, Aufträge und Auftragspositionen ein Sharding anhand der Spalte „warehouse ID“ erfolgt ist, und 3.) dass die elastische Abfrage die Verknüpfungen für die Shards anordnen und den aufwendigen Teil der Abfrage in den Shards parallel verarbeiten kann.
select
w_id as warehouse,
o_c_id as customer,
count(*) as cnt_orderline,
max(ol_quantity) as max_quantity,
avg(ol_amount) as avg_amount,
min(ol_delivery_d) as min_deliv_date
from warehouse
join orders
on w_id = o_w_id
join order_line
on o_id = ol_o_id and o_w_id = ol_w_id
where w_id > 100 and w_id < 200
group by w_id, o_c_id
Gespeicherte Prozedur für T-SQL-Remoteausführung: sp_execute_remote
Mit der elastischen Abfrage wurde auch eine gespeicherte Prozedur eingeführt, die einen Direktzugriff auf die Shards bietet. Die gespeicherte Prozedur heißt sp_execute_remote und kann verwendet werden, um gespeicherte Remoteprozeduren oder T-SQL-Code in den Remotedatenbanken auszuführen. Hierfür werden die folgenden Parameter verwendet:
- Datenquellenname (nvarchar): Name der externen Datenquelle vom Typ RDBMS.
- Abfrage (nvarchar): T-SQL-Abfrage, die für die einzelnen Shards ausgeführt wird.
- Parameterdeklaration (nvarchar) – optional: Zeichenfolge mit Datentypdefinitionen für die Parameter, die im Query-Parameter verwendet werden (wie sp_executesql).
- Parameterwertliste – optional: Durch Trennzeichen getrennte Liste von Parameterwerten (wie sp_executesql).
Die Prozedur „sp_execute_remote“ verwendet die externe Datenquelle, die in den Aufrufparametern angegeben ist, um die jeweilige T-SQL-Anweisung in den Remotedatenbanken auszuführen. Die Anmeldeinformationen der externen Datenquelle werden verwendet, um die Verbindung mit der ShardMapManager-Datenbank und den Remotedatenbanken herzustellen.
Beispiel:
EXEC sp_execute_remote
N'MyExtSrc',
N'select count(w_id) as foo from warehouse'
Konnektivität für Tools
Verwenden Sie herkömmliche SQL Server-Verbindungszeichenfolgen, um Ihre Anwendung sowie Ihre BI- und Datenintegrationstools für die Datenbank mit Ihren Definitionen externer Tabellen zu verbinden. Stellen Sie sicher, dass SQL Server als Datenquelle für das Tool unterstützt wird. Verweisen Sie dann auf die elastische Abfragedatenbank wie auf beliebige andere mit dem Tool verbundenen SQL Server-Datenbanken, und nutzen Sie externe Tabellen in Ihren Tools oder Anwendungen, als wären es lokale Tabellen.
Bewährte Methoden
- Stellen Sie sicher, dass die Endpunktdatenbank für elastische Abfragen durch die Firewalls von SQL-Datenbank hindurch Zugriff auf die Datenbank mit der Shardzuordnung und alle Shards hat.
- Überprüfen oder erzwingen Sie die in der externen Tabelle definierte Verteilung der Daten. Wenn Ihre tatsächliche Datenverteilung sich von der Verteilung in der Tabellendefinition unterscheidet, können Ihre Abfragen zu unerwarteten Ergebnissen führen.
- Die elastische Abfrage führt derzeit keine Shardlöschung durch, wenn Prädikate für Shardingschlüssel ein gefahrloses Ausschließen der Verarbeitung bestimmter Shards zulassen würden.
- Eine elastische Abfrage funktioniert am besten für Abfragen, in denen der größte Teil der Berechnung in den Shards erfolgt. In der Regel erhalten Sie optimale Abfrageleistung mit benutzerdefinierten Filterprädikaten, die in den Shards oder Verknüpfungen über die Partitionierungsschlüssel ausgewertet werden können, die auf partitionsbezogene Weise auf allen Shards ausgeführt werden können. Für andere Abfragemuster müssen möglicherweise große Mengen von Daten aus den Shards auf den Hauptknoten geladen werden, wodurch Leistungseinbußen auftreten.
Nächste Schritte
- Eine Übersicht über elastische Abfragen finden Sie unter Übersicht über elastische Abfragen in Azure SQL-Datenbank.
- Ein Tutorial zur vertikalen Partitionierung finden Sie unter Erste Schritte mit datenbankübergreifenden Abfragen (vertikale Partitionierung).
- Die Syntax und Beispiele für Abfragen von vertikal partitionierten Daten finden Sie unter Abfragen von vertikal partitionierten Daten.
- Ein Tutorial zur horizontalen Partitionierung (Sharding) finden Sie unter Erste Schritte mit elastischen Abfragen für horizontale Partitionierung (Sharding).
- Unter sp_execute_remote finden Sie eine gespeicherte Prozedur, mit der eine Transact-SQL-Anweisung für eine einzelne Remoteinstanz von Azure SQL-Datenbank oder für eine Gruppe von Datenbanken ausgeführt wird, die als Shards in einem Schema mit horizontaler Partitionierung dienen.