Machine Learning-Vorgänge
Machine Learning-Vorgänge (auch als MLOps bezeichnet) sind die Anwendung von DevOps-Prinzipien auf KI-bezogene Anwendungen. Um Machine Learning-Vorgänge in einer Organisation zu implementieren, müssen bestimmte Qualifikationen, Prozesse und Technologien vorhanden sein. Das Ziel besteht darin, bei der Bereitstellung von Machine Learning-Lösungen eine bessere Stabilität, Skalierbarkeit, Zuverlässigkeit und Automatisierung zu erreichen.
In diesem Artikel erfahren Sie, wie Sie Ressourcen planen, um Machine Learning-Vorgänge auf Organisationsebene zu unterstützen. Informieren Sie sich über bewährte Methoden und Empfehlungen, die auf der Verwendung von Azure Machine Learning basieren, um Machine Learning-Vorgänge im Unternehmen einzuführen.
Was sind Machine Learning-Vorgänge?
Moderne Machine Learning (ML)-Algorithmen und -Frameworks machen es immer einfacher, Modelle zu entwickeln, die genaue Vorhersagen treffen können. Machine Learning-Vorgänge sind eine strukturierte Möglichkeit, maschinelles Lernen in die Anwendungsentwicklung eines Unternehmens einzubeziehen.
In einem Beispielszenario haben Sie bereits ein ML-Modell entwickelt, das alle Ihre Genauigkeitserwartungen übertrifft und Ihren Investoren imponiert. Jetzt ist es an der Zeit, das Modell in der Produktion einzusetzen, aber das ist möglicherweise nicht so einfach wie erwartet. Die Organisation muss wahrscheinlich über Personal, Prozesse und Technologie verfügen, bevor sie Ihr Machine Learning-Modell in der Produktion einsetzen kann.
Und es ist möglich, dass Sie oder einer Ihrer Kolleg*innen im Laufe der Zeit ein neues, noch besseres Modell entwickeln. Beim Ersetzen eines Machine Learning-Modells, das in der Produktion verwendet wird, sind einige Aspekte zu berücksichtigen, die für die Organisation wichtig sind:
- Sie möchten das neue Modell implementieren, ohne den Betriebsablauf zu stören, der auf dem bereitgestellten Modell beruht.
- Für regulatorische Zwecke kann es erforderlich sein, die Vorhersagen des Modells zu erklären oder das Modell neu zu erstellen, wenn sich aus den Daten des neuen Modells ungewöhnliche oder verfälschte Vorhersagen ergeben.
- Die Daten, die Sie in Ihrem Machine Learning-Training und -Modell verwenden, können sich im Laufe der Zeit ändern. Bei Änderungen der Daten müssen Sie das Modell möglicherweise regelmäßig neu trainieren, um die Vorhersagegenauigkeit zu erhalten. Eine Person oder eine Rolle muss die Verantwortung für die Dateneingabe, die Leistungsüberwachung des Modells, das erneute Training des Modells und Fehlerkorrekturen am Modell übernehmen.
Angenommen, Ihre Anwendung liefert die Vorhersagen eines Modells über eine REST-API. Selbst ein einfacher Anwendungsfall wie dieser kann zu Problemen in der Produktion führen. Die Implementierung einer Strategie für Machine Learning-Vorgänge kann Ihnen dabei helfen, Bereitstellungsprobleme zu lösen und Geschäftsabläufe zu unterstützen, die auf KI-gestützte Anwendungen angewiesen sind.
Einige Aufgaben von Machine Learning-Vorgängen passen gut in das allgemeine DevOps-Framework. Beispiele hierfür sind das Einrichten von Komponententests und Integrationstests sowie die Verfolgung von Änderungen mithilfe der Versionskontrolle. Andere Aufgaben von Machine Learning-Vorgängen sind eindeutiger und können Folgendes umfassen:
- Aktivieren von fortlaufenden Experimenten und Vergleichen mit einem Baselinemodell
- Überwachen der eingehenden Daten zum Erkennen von Datendrifts
- Auslösen von erneuten Modelltrainings und Einrichten eines Rollbacks für die Notfallwiederherstellung
- Erstellen wiederverwendbarer Datenpipelines für Training und Bewertung
Das Ziel von Machine Learning-Vorgängen besteht darin, die Lücke zwischen Entwicklung und Produktion zu schließen und Kunden eine schnellere Wertschöpfung zu ermöglichen. Damit dies erreicht werden kann, ist es erforderlich, die Entwicklungs- und Produktionsprozesse zu überdenken.
Die Anforderungen von Machine Learning-Vorgängen sind nicht in jeder Organisation gleich. Die Architektur für Machine Learning-Vorgänge eines großen, internationalen Unternehmens entspricht wahrscheinlich nicht der Infrastruktur, die ein kleines Startup-Unternehmen einrichtet. Normalerweise beginnen Unternehmen in einem eher kleinen Rahmen, den sie mit zunehmendem Reifegrad und Modellkatalog sowie wachsender Erfahrung erweitern.
Das Reifemodell für Machine Learning-Vorgänge kann Ihnen helfen, zu sehen, bei welchem Reifegrad sich die Machine Learning-Vorgänge Ihrer Organisation befinden, sodass Sie zukünftiges Wachstum besser planen können.
Machine Learning-Vorgänge im Vergleich zu DevOps
Machine Learning-Vorgänge (MLOps) unterscheiden sich von DevOps in mehreren wichtigen Bereichen. Machine Learning-Vorgänge haben folgende Merkmale:
- Vor Entwicklung und Betrieb gibt es eine Analysephase.
- Der Data Science-Lebenszyklus erfordert eine adaptive Arbeitsweise.
- Beschränkungen der Datenqualität und -verfügbarkeit begrenzen den Fortschritt.
- Ein größerer Betriebsaufwand ist erforderlich als in DevOps.
- Arbeitsteams müssen aus Spezialist*innen und Domänenexpert*innen bestehen.
Eine Zusammenfassung finden Sie in den sieben Prinzipien der Machine Learning-Vorgänge.
Vor Entwicklung und Betrieb gibt es eine Analysephase
Data Science-Projekte unterscheiden sich von Anwendungsentwicklungs- oder Datentechnikprojekten. Ein Data Science-Projekt kann es bis in die Produktion schaffen, aber oft sind mehr Schritte erforderlich als bei einer herkömmlichen Bereitstellung. Nach einer ersten Analyse wird möglicherweise deutlich, dass das Geschäftsergebnis mit den verfügbaren Datasets nicht erreicht werden kann. Eine eingehende Analysephase ist in der Regel der erste Schritt in einem Data Science-Projekt.
Ziel der Analysephase ist es, das Problem zu definieren und zu konkretisieren. In dieser Phase führen technische Fachkräfte für Daten explorative Datenanalysen aus. Sie verwenden Statistiken und Visualisierungen, um die Problemhypothesen zu bestätigen oder zu widerlegen. Den Beteiligten muss bewusst sein, dass das Projekt möglicherweise nicht über diese Phase hinausgeht. Gleichzeitig ist diese Phase so reibungslos wie möglich zu gestalten, um eine schnelle Bearbeitung zu ermöglichen. Sofern das zu lösende Problem keine Sicherheitskomponente enthält, sollte die Analysephase nicht durch Prozesse und Verfahren beschränkt werden. Technische Fachkräfte für Daten sollten mit den Tools und Daten arbeiten dürfen, die sie bevorzugen. Für diese explorative Arbeit werden echte Daten benötigt.
Das Projekt kann in die Experimentier- bzw. Entwicklungsphase wechseln, wenn die Beteiligten sicher sind, dass das Data Science-Projekt machbar ist und einen echten Mehrwert bieten kann. In dieser Phase werden Entwicklungsmethoden immer wichtiger. Es hat sich bewährt, Metriken für alle Experimente aufzuzeichnen, die in dieser Phase durchgeführt werden. Darüber hinaus ist es wichtig, eine Quellcodeverwaltung zu integrieren, um Modelle vergleichen und zwischen verschiedenen Versionen des Codes umschalten zu können.
Entwicklungsaktivitäten umfassen das Refactoring, Tests und die Automatisierung von Explorationscode in wiederholbaren Experimentierpipelines. Die Organisation muss Anwendungen und Pipelines erstellen, um die Modelle zu bedienen. Durch das Refactoring von Code in modulare Komponenten und Bibliotheken kann die Wiederverwendbarkeit und Testfähigkeit erhöht und die Leistung optimiert werden.
Schließlich werden die Anwendungs- oder Batchrückschlusspipelines, die die Modelle bedienen, in Staging- oder Produktionsumgebungen bereitgestellt. Neben der Überwachung der Infrastruktursicherheit und -leistung wie bei einer Standardanwendung in einer Machine Learning-Modellimplementierung müssen Sie die Qualität der Daten, des Datenprofils und des Modells für Verschlechterung oder Drift kontinuierlich überwachen. Zudem erfordern ML-Modelle im Laufe der Zeit ein erneutes Training, um auch in sich ändernden Umgebungen relevant zu bleiben.
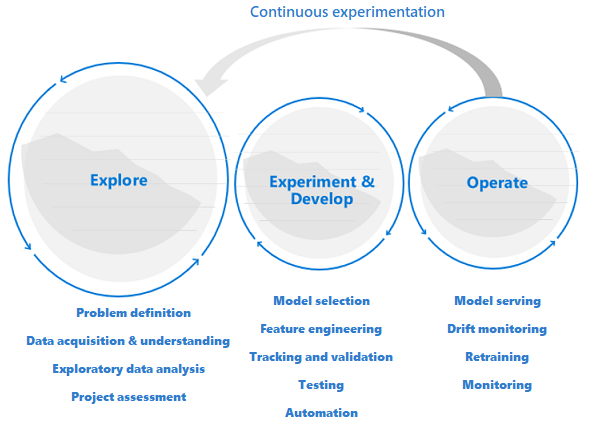
Der Data Science-Lebenszyklus erfordert eine adaptive Arbeitsweise
Da die Art und Qualität der Daten anfangs ungewiss ist, erreichen Sie Ihre Geschäftsziele möglicherweise nicht, wenn Sie einen klassischen DevOps-Prozess für ein Data Science-Projekt übernehmen. Bei Analysen und Experimenten handelt es sich um wiederkehrende Aktivitäten und Anforderungen, die im Rahmen eines Machine Learning-Prozesses auftreten. Teams bei Microsoft verwenden einen Projektlebenszyklus und einen Arbeitsprozess, der die Art der datenwissenschaftlichen Aktivitäten widerspiegelt. Der Team Data Science-Prozess und der Data Science Lifecycle-Prozess sind Beispiele für Referenzimplementierungen.
Beschränkungen der Datenqualität und -verfügbarkeit begrenzen den Fortschritt
Damit ein ML-Team effektiv Machine Learning-gestützte Anwendungen entwickeln kann, wird der Zugang zu Produktionsdaten für alle relevanten Arbeitsumgebungen bevorzugt. Wenn der Zugriff auf Produktionsdaten aufgrund von Complianceanforderungen oder technischen Einschränkungen nicht möglich ist, sollten Sie über die Implementierung der rollenbasierten Zugriffssteuerung (Azure RBAC) von Azure mit Azure Machine Learning, von Just-In-Time-Zugriff oder von Datenverschiebungspipelines nachdenken, mit deren Hilfe Replikate der Produktionsdaten erstellt und die Produktivität der Benutzer*innen gewährleistet werden kann.
Maschinelles Lernen erfordert einen größeren operativen Aufwand
Im Gegensatz zu herkömmlicher Software ist die Leistung einer Machine Learning-Lösung ständig gefährdet, da die Lösung von der Datenqualität abhängig ist. Um eine qualitativ hochwertige Lösung in der Produktion aufrechtzuerhalten, müssen Sie sowohl die Daten- als auch die Modellqualität kontinuierlich überwachen und neu bewerten. Es ist zu erwarten, dass ein Produktionsmodell rechtzeitig erneut trainiert und bereitgestellt bzw. optimiert werden muss. Diese Aufgaben kommen zu den täglichen Sicherheits-, Infrastrukturüberwachungs- oder Complianceanforderungen hinzu und erfordern besondere Kenntnisse.
ML-Teams müssen aus Spezialist*innen und Domänenexpert*innen bestehen
Zwar gibt es einige Rollen, die bei Data Science-Projekten und IT-Projekten ähnlich sind, der Erfolg eines ML-Projekts hängt allerdings vordergründig von den ML-Technologiespezialist*innen und Domänenexpert*innen ab. Ein*e Technologiespezialist*in hat den richtigen Hintergrund, um End-to-End-Experimente für Machine Learning-Projekte durchzuführen. Domänenexpert*innen können die Spezialist*innen unterstützen, indem Sie Daten analysieren und synthetisieren oder durch qualifizierte Daten zur Verwendung qualifizieren.
Die folgenden technischen Rollen werden üblicherweise nur bei Data Science-Projekten benötigt: Domänenexpert*innen, Technische Fachkräfte für Daten, Wissenschaftliche Fachkräfte für Daten, Technische Fachkräfte für KI, Fachkräfte für die Modellvalidierung und Technische Fachkräfte für maschinelles Lernen. Weitere Informationen zu Rollen und Aufgaben in einem typischen Data Science-Team finden Sie unter Team Data Science-Prozess.
Sieben Prinzipien von Machine Learning-Vorgängen
Wenn Sie Machine Learning-Vorgänge in Ihrer Organisation einführen möchten, sollten Sie die folgenden Kernprinzipien als Grundlage anwenden:
Verwenden Sie die Versionskontrolle für Code-, Daten- und Experimentierausgaben. Anders als bei der traditionellen Softwareentwicklung haben die Daten einen direkten Einfluss auf die Qualität der Machine Learning-Modelle. Sie sollten nicht nur Ihre Experimentcodebasis, sondern auch Ihre Datasets versionieren, um sicherzustellen, dass Sie Experimente oder Rückschlussergebnisse reproduzieren können. Auch durch die Versionsverwaltung von Experimentausgaben (wie z. B. Modellen) kann viel Aufwand und Rechenzeit für die spätere Nachbildung eingespart werden.
Verwenden Sie mehrere Umgebungen. Replizieren Sie Ihre Infrastruktur in mindestens zwei Umgebungen, um die Entwicklungs- und Testarbeiten von der Produktionsumgebung zu trennen. Die Zugriffssteuerung für Benutzer kann für jede Umgebung unterschiedlich sein.
Verwalten Sie Ihre Infrastruktur und Konfigurationen als Code. Wenn Sie Infrastrukturkomponenten in Ihren Arbeitsumgebungen erstellen und aktualisieren, verwenden Sie Infrastructure-as-Code, um Inkonsistenzen zwischen den Umgebungen zu verhindern. Verwalten Sie die Auftragsspezifikationen von ML-Experimenten als Code, damit Sie eine beliebige Version Ihres Experiments problemlos erneut ausführen und in mehreren Umgebungen wiederverwenden können.
Verfolgen und verwalten Sie Machine Learning-Experimente. Verfolgen Sie KPIs und andere Artefakte für Ihre Machine Learning-Experimente. Wenn Sie den Leistungsverlauf aufzeichnen, ermöglicht dies eine quantitative Analyse des Experimenterfolgs sowie eine bessere Zusammenarbeit und Agilität des Teams.
Testen Sie den Code und überprüfen Sie die Datenintegrität und Modellqualität. Testen Sie Ihre Experimentcodebasis auf die Richtigkeit der Datenvorbereitungs- und der Merkmalsextraktionfunktionen sowie die Datenintegrität und die Modellleistung.
Continuous Integration und Continuous Delivery von Machine Learning-Projekten Verwenden Sie Continuous Integration (CI), um Tests für Ihr Team zu automatisieren. Schließen Sie Modelltrainings als Teil der fortlaufenden Trainingspipelines ein. Nehmen Sie A/B-Tests in Ihr Release auf, um sicherzustellen, dass nur ein hochwertiges Modell in der Produktion verwendet wird.
Überwachen Sie Dienste, Modelle und Daten. Wenn Sie Modelle in einer Umgebung mit Machine Learning-Vorgängen einsetzen, ist es wichtig, die Verfügbarkeit und Compliance der Infrastruktur sowie die Modellqualität zu überwachen. Richten Sie Überwachungsmechanismen ein, um Daten- und Modelldrifts zu identifizieren, um zu ermitteln, ob ein erneutes Training erforderlich ist. Ziehen Sie das Einrichten von Triggern für ein automatisches erneutes Training in Betracht.
Bewährte Methoden von Azure Machine Learning
Azure Machine Learning bietet Ressourcenverwaltungs-, Orchestrierungs- und Automatisierungsdienste, mit deren Hilfe Sie den Lebenszyklus Ihrer Modelltrainings- und Bereitstellungsworkflows für das maschinelle Lernen verwalten können. Informieren Sie sich über die bewährten Methoden und Empfehlungen zur Anwendung von Machine Learning-Vorgängen in den Ressourcenbereichen Personal, Prozesse und Technologie, die alle von Azure Machine Learning unterstützt werden.
Personen
Arbeiten Sie in Projektteams zusammen, um das Fachwissen und das Domänenwissen in Ihrem Unternehmen optimal zu nutzen. Organisieren und richten Sie Azure Machine Learning-Arbeitsbereiche auf Projektbasis ein, um die Trennungsanforderungen für verschiedene Anwendungsfälle zu erfüllen.
Definieren Sie verschiedene Verantwortlichkeiten und Aufgaben als Rolle, sodass jedes Teammitglied eines Projektteams für Machine Learning-Vorgänge mehrere Rollen zuweisen und erfüllen kann. Verwenden Sie benutzerdefinierte Azure-Rollen, um präzise Azure RBAC-Vorgängen für Azure Machine Learning festzulegen, die von jeder Rolle ausgeführt werden können.
Standardisieren Sie einen Projektlebenszyklus und eine agile Methodik. Der Team Data Science-Prozess stellt Ihnen eine Referenzimplementierung für einen Lebenszyklus zur Verfügung.
Ausgewogene Teams können alle Phasen der Machine Learning-Vorgänge ausführen, einschließlich Analyse, Entwicklung und Betrieb.
Prozess
Standardisieren Sie eine Codevorlage, um die Wiederverwendung von Code zu ermöglichen und die Vorbereitungszeit bei neuen Projekten oder beim Beitritt eines neuen Teammitglieds zum Projekt zu verkürzen. Verwenden Sie Azure Machine Learning-Pipelines, Auftragsübermittlungsskripts und CI/CD-Pipelines als Basis für neue Vorlagen.
Nutzen Sie die Versionskontrolle. Bei Aufträgen, die aus einem Git-basierten Ordner übermittelt werden, werden mit Azure Machine Learning automatisch die Repository-Metadaten nachverfolgt, wodurch eine Reproduzierbarkeit gewährleistet wird.
Verwenden Sie die Versionsverwaltung für Experimenteingaben und -ausgaben für die Reproduzierbarkeit. Erleichtert wird die Versionsverwaltung durch die Nutzung von Azure Machine Learning-Datasets sowie von Modellverwaltungs- und Umgebungsverwaltungsfunktionen.
Erstellen Sie einen Ausführungsverlauf für die Experimentausführungen, um Vergleiche sowie eine bessere Planung und Zusammenarbeit zu ermöglichen. Nutzen Sie ein Framework zur Experimentnachverfolgung wie MLflow für die Metriksammlung.
Messen und bewerten Sie die Arbeitsqualität Ihres Teams auf kontinuierliche Weise mithilfe einer CI der vollständigen Experimentcodebasis.
Beenden Sie das Training früh im Prozess, wenn ein Modell nicht konvergiert. Nutzen Sie ein Framework zur Experimentnachverfolgung und den Ausführungsverlauf in Azure Machine Learning, um die Auftragsausführung zu überwachen.
Definieren Sie eine Experiment- und Modellverwaltungsstrategie. Ziehen Sie in Erwägung, das aktuelle Basismodell mit einem Namen wie Champion zu bezeichnen. Ein Challenger-Modell ist ein Kandidatenmodell, das das Champion-Modell in der Produktion auslöst. Nutzen Sie Tags in Azure Machine Learning, um Experimente und Modelle zu markieren. In einigen Szenarien, z. B. bei Umsatzprognosen, kann es Monate dauern, bis ermittelt werden kann, ob die Vorhersagen des Modells korrekt sind.
Erhöhen Sie die CI für kontinuierliche Trainings, indem Sie Modelltrainings im Build einschließen. Beginnen Sie z. B. mit jedem Pull Request das Modelltraining für das gesamte Dataset.
Verkürzen Sie die Zeit bis Sie ein Qualitätsfeedback der ML-Pipeline erhalten, indem Sie einen automatisierten Build auf Grundlage eines Datenbeispiels ausführen. Verwenden Sie Azure Machine Learning-Pipelineparameter, um Eingabe-Datasets zu parametrisieren.
Verwenden Sie Continuous Deployment (CD) für Machine Learning-Modelle, um die Bereitstellung und das Testen von Echtzeit-Bewertungsdiensten in Ihren Azure-Umgebungen zu automatisieren.
In einigen regulierten Branchen sind möglicherweise Modellvalidierungsschritte erforderlich, bevor ein ML-Modell in einer Produktionsumgebung verwendet werden kann. Durch die Automatisierung dieser Validierungsschritte können Sie die Zeit bis zur Bereitstellung verkürzen. Wenn manuelle Überprüfungs- oder Validierungsschritte weiterhin ein Problem darstellen, sollten Sie überlegen, ob die automatisierte Modellvalidierungspipeline zertifiziert werden kann. Verwenden Sie Ressourcentags in Azure Machine Learning, um Angaben zu Ressourcenkonformität und Kandidaten für die Überprüfung oder als Trigger für die Bereitstellung festzulegen.
Führen Sie in der Produktionsumgebung keine erneuten Trainings durch, sondern ersetzen Sie das Produktionsmodell direkt ohne Integrationstest. Auch wenn die Leistung des Modells gut ist und funktionale Anforderungen eingehalten werden, gibt es mehrere potenzielle Probleme. Es kann beispielsweise sein, dass ein Modell so groß wird, dass es die Serverumgebung stört.
Wenn der Zugriff auf Produktionsdaten nur in der Produktion gestattet ist, verwenden Sie Azure RBAC und benutzerdefinierte Rollen, um einer ausgewählten Anzahl von ML-Anwendern den Lesezugriff zu ermöglichen. Einige Rollen müssen möglicherweise zum Zweck der Datenanalyse die Daten lesen. Alternativ lassen sich außerhalb der Produktionsumgebungen auch Kopien der Daten zur Verfügung stellen.
Vereinbaren Sie Benennungskonventionen und Tags für Azure Machine Learning-Experimente, um das erneute Training von ML-Basispipelines von den experimentellen Arbeiten zu unterscheiden.
Technologie
Wenn Sie derzeit Aufträge über die Azure Machine Learning Studio-Oberfläche oder die Befehlszeilenschnittstelle übermitteln, verwenden Sie die Befehlszeilenschnittstelle oder Azure DevOps Machine Learning-Aufgaben, um Schritte der Automatisierungspipeline zu konfigurieren, anstatt Aufträge über das SDK zu übermitteln. Dieser Prozess kann den Codeumfang verringern, indem die Auftragsübermittlungen direkt aus den Automatisierungspipelines wiederverwendet werden.
Verwenden Sie ereignisbasierte Programmierung. Nutzen Sie beispielsweise Azure Functions, um automatisch eine Offline-Pipeline für einen Modelltest zu triggern, sobald ein neues Modell registriert wird. Oder senden Sie eine Benachrichtigung an einen designierten E-Mail-Alias, falls es nicht möglich ist, eine wichtige Pipeline auszuführen. Azure Machine Learning erstellt Ereignisse in Azure Event Grid. Mehrere Rollen können über ein Ereignis benachrichtigt werden.
Wenn Sie Azure DevOps für die Automatisierung verwenden, können Sie die Azure DevOps Tasks für maschinelles Lernen nutzen, um ML-Modelle als Pipelinetrigger zu verwenden.
Wenn Sie Python-Pakete für Ihre ML-Anwendung entwickeln, können Sie diese als Artefakte in einem Azure DevOps-Repository hosten und als Feed veröffentlichen. So können Sie den DevOps-Workflow zum Erstellen von Paketen in Ihren Azure Machine Learning-Arbeitsbereich integrieren.
Verwenden Sie ggf. eine Stagingumgebung, um die Systemintegration von ML-Pipelines mit Upstream- oder Downstream-Anwendungskomponenten zu testen.
Entwickeln Sie Komponenten- und Integrationstests für Ihre Rückschlussendpunkte, um den Debugging-Prozess zu verbessern und die Bereitstellungszeit zu beschleunigen.
Verwenden Sie zum Auslösen eines erneuten Trainings Datasetmonitore und ereignisgesteuerte Workflows. Abonnieren Sie Datendriftereignisse, und automatisieren Sie das Auslösen von ML-Pipelines für ein erneutes Training.
KI-Factory für die Organisation von Machine Learning-Vorgängen
Ein Data Science-Team ist ggf. in der Lage, mehrere ML-Anwendungsfälle intern zu verwalten. Die Einführung von Machine Learning-Vorgängen hilft einer Organisation, es Projektteams zu ermöglichen, die Qualität, Zuverlässigkeit und Wartungsfreundlichkeit von Lösungen zu verbessern. Durch ausgewogene Teams, unterstützte Prozesse und Technologieautomatisierung kann ein Team, das Machine Learning-Vorgänge einführt, skalieren und sich auf die Entwicklung neuer Anwendungsfälle konzentrieren.
Wenn die Anzahl von Anwendungsfällen in einer Organisation zunimmt, wächst der Verwaltungsaufwand für die Unterstützung dieser Anwendungsfälle linear oder sogar noch mehr. Die Herausforderung für die Organisation besteht darin, die Produkteinführungszeit zu verkürzen, eine schnellere Bewertung der Durchführbarkeit von Anwendungsfällen zu unterstützen, Reproduzierbarkeit zu gewährleisten und die verfügbaren Ressourcen und Qualifikationen für verschiedene Projekte optimal zu nutzen. Für viele Organisationen ist die Entwicklung einer KI-Factory die Lösung.
Eine KI-Factory ist ein System von reproduzierbaren Geschäftsprozessen und standardisierten Artefakten, die die Entwicklung und Bereitstellung zahlreicher Machine Learning-Anwendungsfälle erleichtern. Mit einer KI-Factory lassen sich Teams optimal zusammenstellen sowie empfohlene Methoden, Strategien für Machine Learning-Vorgänge, Architekturmuster und wiederverwendbare Vorlagen, die auf Geschäftsanforderungen zugeschnitten sind, bestmöglich umsetzen.
Eine erfolgreiche KI-Factory basiert auf wiederholbaren Prozessen und wiederverwendbaren Ressourcen, die einer Organisation die effiziente Skalierung von dutzenden Anwendungsfällen auf tausende Anwendungsfälle ermöglichen.
In der folgenden Abbildung sind die wichtigsten Elemente einer KI-Factory zusammengefasst:

Standardisieren nach wiederholbaren Architekturmustern
Die Wiederholbarkeit ist eine wichtige Eigenschaft einer KI-Factory. Data Science-Teams können die Projektentwicklung beschleunigen und die Projektkonsistenz verbessern, indem sie einige wiederholbare Architekturmuster entwickeln, die die meisten Anwendungsfälle für maschinelles Lernen in ihrem Unternehmen abdecken. Sobald diese entwickelt wurden, können diese Muster für die meisten Projekte verwendet werden, um die folgenden Vorteile zu nutzen:
- Kürzere Entwurfsphase
- Genehmigungen von IT- und Sicherheitsteams können durch eine projektübergreifende Wiederverwendung von Tools beschleunigt werden
- Die Entwicklung kann durch eine wiederverwendbare Infrastruktur in Form von Code- und Projektvorlagen beschleunigt werden
Die Architekturmuster können unter anderem die folgenden Inhalte umfassen:
- Bevorzugte Dienste für jede Projektphase
- Datenkonnektivität und Governance
- Eine Strategie für Machine Learning-Vorgänge, die auf die Anforderungen der Branchen-, Geschäfts- oder Datenklassifizierung zugeschnitten ist
- Experimentverwaltung der Champion- und Challenger-Modelle
Vereinfachte teamübergreifende Zusammenarbeit und Freigabe
Repositorys und Hilfsprogramme für freigegebenen Code können die Entwicklung von ML-Lösungen beschleunigen. Coderepositorys können im Rahmen des Projektverlaufs modular entwickelt werden, sodass sie generisch genug sind, um auch für andere Projekte genutzt zu werden. Sie können in einem zentralen Repository zur Verfügung gestellt werden, auf das alle Data Science-Teams zugreifen können.
Freigeben und Wiederverwenden von geistigem Eigentum
Damit der Code möglichst oft wiederverwendet werden kann, sollten Sie zu Beginn eines Projekts das folgende geistige Eigentum überprüfen:
- Interner Code, der für die Wiederverwendung in der Organisation konzipiert wurde. Beispiele wie Pakete und Module.
- Datasets, die im Rahmen von anderen ML-Projekten erstellt wurden oder im Azure-Ökosystem verfügbar sind.
- Vorhandene Data Science-Projekte mit ähnlicher Architektur und ähnlichen zugrundeliegenden Problemen.
- GitHub- oder Open Source-Repositorys, die das Projekt beschleunigen können.
Jede Projektretrospektive sollte einen Handlungsschritt enthalten, der feststellt, ob Elemente des Projekts für eine allgemeine Wiederverwendung genutzt werden können. Die Liste der Ressourcen, die die Organisation im Laufe der Zeit freigeben und wiederverwenden kann.
Um die Freigabe und Ermittlung zu erleichtern, haben viele Organisationen gemeinsame Repositorys eingeführt, um Codeschnipsel und Machine Learning-Artefakte zu speichern. Artifacts in Azure Machine Learning kann als Code definiert werden. Dies umfasst ebenfalls Datasets, Modelle, Umgebungen und Pipelines, die Sie projekt- und arbeitsbereichsübergreifend effizient gemeinsam nutzen können.
Projektvorlagen
Für einen schnelleren Migrationsprozess bestehender Lösungen und für eine größtmögliche Wiederverwendung von Code verwenden viele Unternehmen standardmäßig eine Projektvorlage als Ausgangspunkt für neue Projekte. Beispiele für Projektvorlagen, die für die Verwendung mit Azure Machine Learning empfohlen werden, sind Azure Machine Learning-Beispiele, der Data Science Lifecycle-Prozess und der Team Data Science-Prozess.
Zentrale Datenverwaltung
Der Zugriffsprozess auf Daten für die Analysephase oder für die Nutzung in der Produktion kann sehr zeitaufwändig sein. Viele Organisationen zentralisieren ihre Datenverwaltung, um Datenproduzenten und Datenconsumer zusammenzubringen und den Datenzugriff für ML-Experimente zu vereinfachen.
Freigegebene Hilfsprogramme
Ihre Organisation kann unternehmensweite zentralisierte Dashboards verwenden, um Protokollierungs- und Überwachungsinformationen zu konsolidieren. Die Dashboards können Angaben zur Fehlerprotokollierung, Dienstverfügbarkeit und Telemetrie sowie Leistungsüberwachung des Modells enthalten.
Verwenden Sie Azure Monitor-Metriken, um ein Dashboard für Azure Machine Learning und zugehörige Dienste wie Azure Storage zu erstellen. Ein Dashboard hilft Ihnen dabei, den Fortschritt der Experimente, die Integrität der Infrastruktur und die GPU-Kontingentauslastung zu verfolgen.
Spezialisiertes ML-Entwicklungsteam
Viele Organisationen haben die Rolle der technischen Fachkraft für Machine Learning eingeführt. Eine technische Fachkraft für Machine Learning spezialisiert sich auf das Erstellen und Ausführen stabiler Machine Learning-Pipelines, Workflows für Driftüberwachung und erneutes Training sowie Überwachungsdashboards. Die technische Fachkraft trägt die Gesamtverantwortung für die Umsetzung der Machine Learning-Lösung, von der Entwicklung bis zur Produktion. Sie arbeitet eng mit technischen Fachkräften für Daten, IT-Architekt*innen sowie den Abteilungen Sicherheit und Betrieb zusammen, um sicherzustellen, dass alle erforderlichen Kontrollen umgesetzt werden.
Während im Bereich Data Science umfassende Domänenkenntnisse erforderlich sind, stehen beim maschinellen Lernen eher technische Aspekte im Vordergrund. Aufgrund dieses Unterschieds muss die technische Fachkraft für Machine Learning flexibler sein, damit sie an verschiedenen Projekten und mit verschiedenen Geschäftsabteilungen arbeiten kann. Große Data Science-Projekte können von einem spezialisierten ML-Entwicklungsteam profitieren, das die Wiederholbarkeit und Wiederverwendung von Automatisierungsworkflows über verschiedene Anwendungsfälle und Geschäftsbereiche hinweg ermöglicht.
Aktivierung und Dokumentation
Es ist wichtig, sowohl neuen als auch älteren Teams und Benutzern klare Anweisungen zum KI-Factoryprozess zu geben. Durch die Anweisungen wird eine konsistente Arbeit sichergestellt und der Aufwand reduziert, der für das ML-Team erforderlich ist, wenn es ein Projekt industrialisiert. Überlegen Sie, ob es sinnvoll ist, Inhalte speziell für die verschiedenen Rollen in Ihrem Unternehmen zu entwerfen.
Jeder hat einen einzigartigen Lernstil, sodass eine Mischung der folgenden Arten von Leitfäden dazu beitragen kann, die Einführung des KI-Factoryframeworks zu beschleunigen:
- Ein zentraler Hub mit Verknüpfungen zu allen Artefakten. Dieser Hub kann z. B. ein Kanal in Microsoft Teams oder eine Microsoft SharePoint-Website sein.
- Ein Trainings- und Aktivierungsplan für jede Rolle
- Eine zusammenfassende Präsentation des Ansatzes mit einem Begleitvideo
- Eine detaillierte Dokumentation oder ein detailliertes Playbook
- Anleitungsvideos
- Bewertungen der Bereitschaft
Videoreihe über Machine Learning-Vorgängen in Azure
Eine Videoreihe über Machine Learning-Vorgängen in Azure zeigt Ihnen, wie Sie Machine Learning-Vorgängen für Ihre ML-Lösung einrichten – angefangen bei der Entwicklung bis hin zur Produktion.
Ethische Grundsätze
Ethische Grundsätze spielen eine wichtige Rolle bei der Entwicklung einer KI-Lösung. Wenn keine ethischen Prinzipien implementiert werden, können trainierte Modelle die gleichen Verzerrungen aufweisen, wie die Daten, mit denen sie trainiert wurden. Dies kann dazu führen, dass das Projekt nicht weitergeführt wird. Vor allem aber steht der Ruf der Organisation auf dem Spiel.
Um sicherzustellen, dass die wichtigsten ethischen Prinzipien, für die die Organisation steht, projektübergreifend implementiert werden, sollte bereits während der Testphase eine Liste dieser Prinzipien zusammen mit Methoden zur technischen Überprüfung bereitgestellt werden. Verwenden Sie die ML-Features in Azure Machine Learning, um zu erfahren, was verantwortungsvolles maschinelles Lernen ist und wie Sie es in ihren Machine Learning-Vorgängen praktisch umsetzen können.
Nächste Schritte
Erfahren Sie mehr über das Organisieren und Einrichten von Azure Machine Learning-Umgebungen, oder sehen Sie sich eine praxisnahe Videoreihe über Machine Learning-Vorgänge in Azure an.
Erfahren Sie mehr über die Verwaltung von Budgets, Kontingenten und Kosten auf Organisationsebene mithilfe von Azure Machine Learning: