Dapr-Komponentenresilienz
Resilienzrichtlinien verhindern, erkennen und beheben proaktiv Fehler Ihrer Container-App. In diesem Artikel erfahren Sie, wie Sie Resilienzrichtlinien für Anwendungen anwenden, die Dapr für die Integration in verschiedene Clouddienste verwenden, z. B. Statusspeicher, Pub/Sub-Nachrichtenbroker, Geheimnisspeicher und vieles mehr.
Sie können Resilienzrichtlinien wie Wiederholungsversuche, Timeouts und Trennschalter für die folgenden ausgehenden und eingehenden Vorgangsrichtungen über eine Dapr-Komponente konfigurieren:
- Ausgehende Vorgänge: Aufrufe vom Dapr-Seitenwagen zu einer Komponente, z. B.:
- Beibehalten oder Abrufen des Zustands
- Veröffentlichen einer Nachricht
- Aufrufen einer Ausgabebindung
- Eingehende Vorgänge: Aufrufe vom Dapr-Seitenwagen zu Ihrer Container-App, z. B.:
- Abonnements beim Übermitteln einer Nachricht
- Eingabebindungen, die ein Ereignis bereitstellen
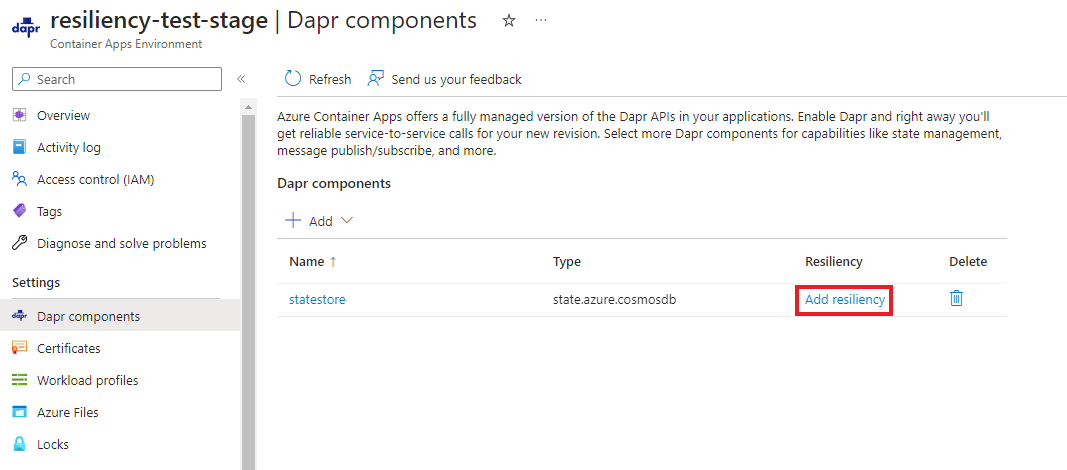
Der folgende Screenshot zeigt, wie eine Anwendung eine Wiederholungsrichtlinie verwendet, um zu versuchen, aus fehlgeschlagenen Anforderungen wiederherzustellen.

Unterstützte Resilienzrichtlinien
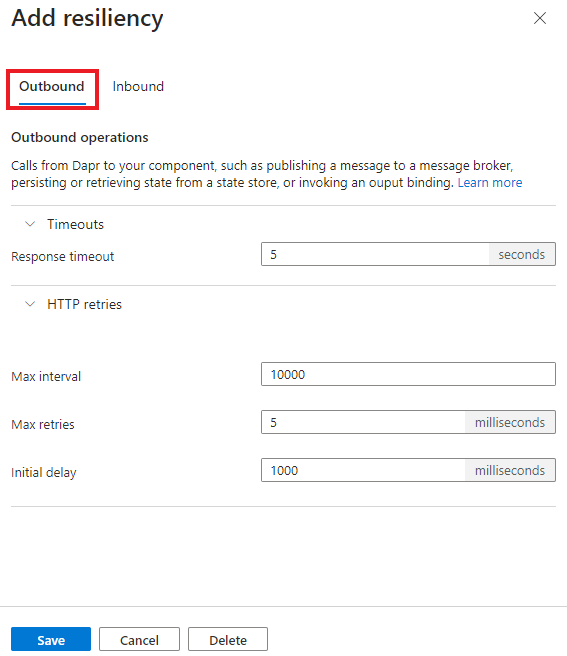
Konfigurieren von Resilienzrichtlinien
Sie können auswählen, ob Resilienzrichtlinien mithilfe von Bicep, der CLI oder dem Azure-Portal erstellt werden sollen.
Im folgenden Beispiel zur Resilienz werden alle verfügbaren Konfigurationen veranschaulicht.
resource myPolicyDoc 'Microsoft.App/managedEnvironments/daprComponents/resiliencyPolicies@2023-11-02-preview' = {
name: 'my-component-resiliency-policies'
parent: '${componentName}'
properties: {
outboundPolicy: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
}
inboundPolicy: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
}
}
}
Wichtig
Nachdem Sie alle Resilienzrichtlinien angewendet haben, müssen Sie Ihre Dapr-Anwendungen neu starten.
Richtlinienspezifikationen
Zeitlimits
Timeouts werden verwendet, um lang laufende Vorgänge frühzeitig zu beenden. Die Timeoutrichtlinie enthält die folgenden Eigenschaften.
properties: {
outbound: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
}
inbound: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
}
}
| Metadaten | Erforderlich | Beschreibung | Beispiel |
|---|---|---|---|
responseTimeoutInSeconds |
Ja | Timeout, das auf eine Antwort der Dapr-Komponente wartet. | 15 |
Retries
Definieren Sie eine httpRetryPolicy-Strategie für fehlgeschlagene Vorgänge. Die Wiederholungsrichtlinie enthält die folgenden Konfigurationen.
properties: {
outbound: {
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
}
inbound: {
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
}
}
| Metadaten | Erforderlich | Beschreibung | Beispiel |
|---|---|---|---|
maxRetries |
Ja | Maximale Wiederholungsversuche, die für eine fehlgeschlagene HTTP-Anforderung ausgeführt werden sollen. | 5 |
retryBackOff |
Ja | Überwachen Sie die Anforderungen, und beenden Sie den gesamten Datenverkehr für den betroffenen Dienst, wenn Timeout- und Wiederholungskriterien erfüllt sind. | Nicht zutreffend |
retryBackOff.initialDelayInMilliseconds |
Ja | Verzögerung zwischen dem ersten Fehler und dem ersten Wiederholungsversuch. | 1000 |
retryBackOff.maxIntervalInMilliseconds |
Ja | Maximale Verzögerung zwischen Wiederholungsversuchen. | 10000 |
Trennschalter
Definieren Sie circuitBreakerPolicy, um Anforderungen zu überwachen, die erhöhte Fehlerraten verursachen, und beenden Sie den gesamten Datenverkehr für den betroffenen Dienst, wenn ein bestimmtes Kriterium erfüllt ist.
properties: {
outbound: {
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
},
inbound: {
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
}
}
| Metadaten | Erforderlich | Beschreibung | Beispiel |
|---|---|---|---|
intervalInSeconds |
Nein | Zyklischer Zeitraum (in Sekunden), der vom Schaltkreisschalter verwendet wird, um seine internen Zählungen zu löschen. Wenn nicht angegeben, wird das Intervall auf denselben Wert festgelegt wie für timeoutInSeconds. |
15 |
consecutiveErrors |
Ja | Anzahl der Anforderungen, die auftreten dürfen, bevor der Schaltkreis ausgelöst und geöffnet wird. | 10 |
timeoutInSeconds |
Ja | Zeitdauer (in Sekunden) des offenen Zustands unmittelbar nach dem Ausfall. | 5 |
Trennschalterprozess
Durch die Angabe von consecutiveErrors (die Auslösebedingung des Schaltkreises als consecutiveFailures > $(consecutiveErrors)-1) wird die Anzahl der Fehler festgelegt, die auftreten dürfen, bevor der Schaltkreis ausgelöst und zur Hälfte geöffnet wird.
Der Schaltkreis wartet halboffen für die Zeit timeoutInSeconds, in der consecutiveErrors aufeinanderfolgende Anforderungen erfolgreich sein müssen.
- Wenn die Anforderungen erfolgreich sind, wird der Schaltkreis geschlossen.
- Wenn die Anforderungen fehlschlagen, verbleibt der Schaltkreis in einem halboffenen Zustand.
Wenn Sie keinen intervalInSeconds-Wert eingestellt haben, wird der Schaltkreis nach der Zeit, die Sie für timeoutInSeconds eingestellt haben, in den geschlossenen Zustand zurückgesetzt, unabhängig davon, ob die Anforderung erfolgreich war oder nicht. Wenn Sie intervalInSeconds auf 0 setzen, wird der Schaltkreis nie automatisch zurückgesetzt, sondern wechselt nur dann vom halboffenen in den geschlossenen Zustand, wenn consecutiveErrors Anforderungen hintereinander erfolgreich abgeschlossen werden.
Wenn Sie einen intervalInSeconds-Wert festgelegt haben, bestimmt dieser die Zeitspanne, nach welcher der Schaltkreis wieder in den geschlossenen Zustand versetzt wird, unabhängig davon, ob die im halboffenen Zustand gesendeten Anforderungen erfolgreich waren oder nicht.
Resilienzprotokolle
Wählen Sie im Abschnitt Überwachung Ihrer Container-App die Option Protokolle aus.
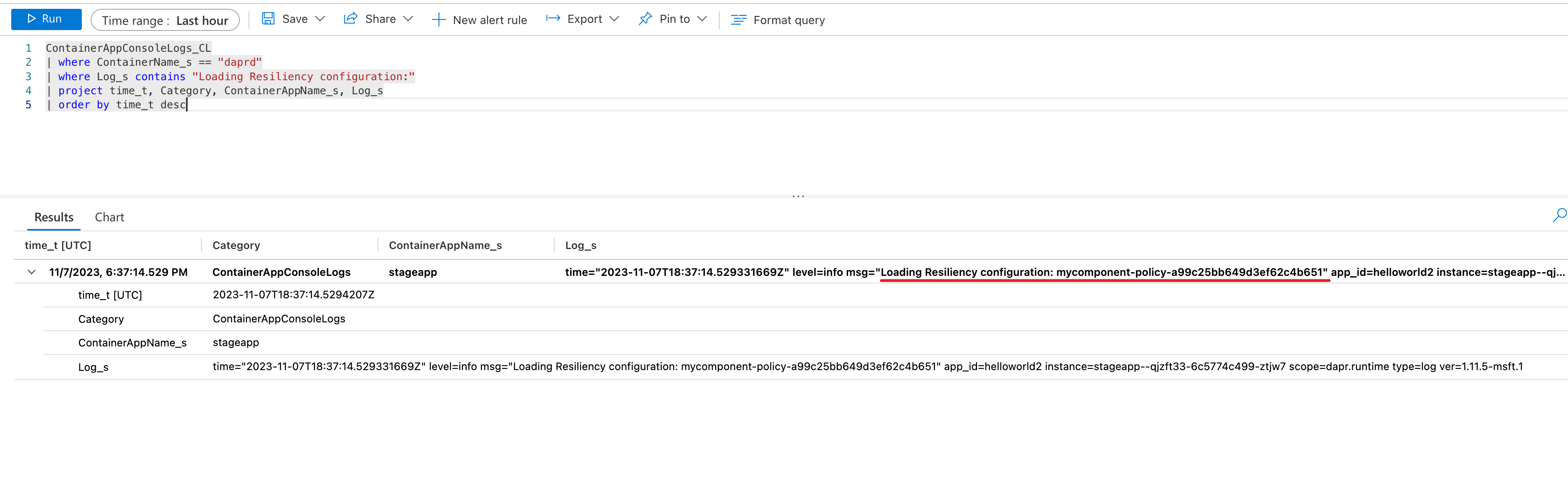
Schreiben Sie im Protokollbereich eine Abfrage und führen diese aus, um Resilienz über Ihre Container-App-Systemprotokolle zu finden. So können Sie beispielsweise ermitteln, ob eine Resilienzrichtlinie geladen wurde:
ContainerAppConsoleLogs_CL
| where ContainerName_s == "daprd"
| where Log_s contains "Loading Resiliency configuration:"
| project time_t, Category, ContainerAppName_s, Log_s
| order by time_t desc
Klicken Sie auf Ausführen, um die Abfrage auszuführen und das Ergebnis mit der Protokollmeldung anzuzeigen, die angibt, dass die Richtlinie geladen wird.
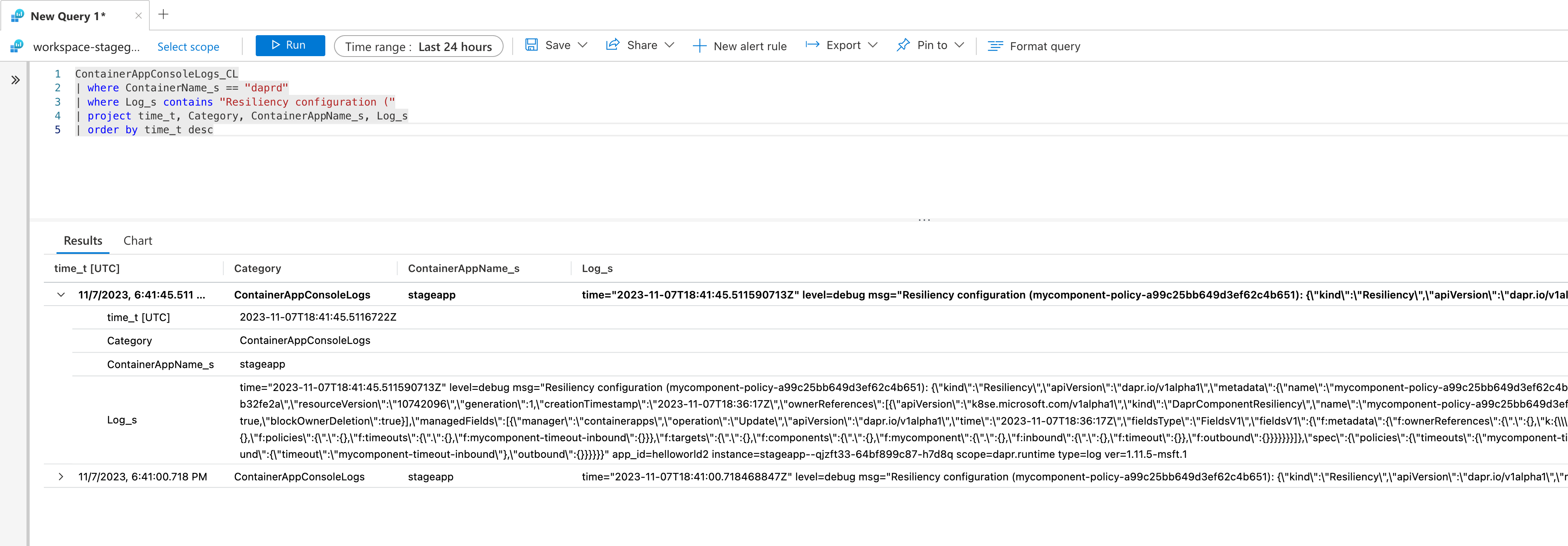
Sie können auch die tatsächliche Resilienzrichtlinie suchen, indem Sie das Debuggen für Ihre Komponente aktivieren und eine Abfrage ähnlich wie im folgenden Beispiel verwenden:
ContainerAppConsoleLogs_CL
| where ContainerName_s == "daprd"
| where Log_s contains "Resiliency configuration ("
| project time_t, Category, ContainerAppName_s, Log_s
| order by time_t desc
Klicken Sie auf Ausführen, um die Abfrage auszuführen und die resultierende Protokollmeldung mit der Richtlinienkonfiguration anzuzeigen.
Zugehöriger Inhalt
Erfahren Sie, wie Resilienz funktioniert für die Dienst-zu-Dienst-Kommunikation mithilfe von Azure Container Apps, die in der Dienstermittlung erstellt wurden