Erste Schritte mit Change Data Capture im Analysespeicher für Azure Cosmos DB
GILT FÜR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB
Verwenden Sie Change Data Capture (CDC) im Azure Cosmos DB-Analysespeicher als Quelle für Azure Data Factory oder Azure Synapse Analytics, um bestimmte Änderungen an Ihren Daten zu erfassen.
Hinweis
Beachten Sie, dass die verknüpfte Dienstschnittstelle für die Azure Cosmos DB for MongoDB-API für Dataflow noch nicht verfügbar ist. Sie können jedoch den Dokumentendpunkt Ihres Kontos mit der verknüpften Dienstschnittstelle „Azure Cosmos DB for NoSQL“ als Umgehung verwenden, bis der verknüpfte Mongo-Dienst unterstützt wird. Wählen Sie in einem verknüpften NoSQL-Dienst „Manuell eingeben“ aus, um die Informationen zum Cosmos DB-Konto bereitzustellen und den Dokumentendpunkt des Kontos (z. B. https://[your-database-account-uri].documents.azure.com:443/) anstelle des MongoDB-Endpunkts (z. B. mongodb://[your-database-account-uri].mongo.cosmos.azure.com:10255/) zu verwenden.
Voraussetzungen
- Ein vorhandenes Azure Cosmos DB-Konto
- Falls Sie bereits über ein Azure-Abonnement verfügen, erstellen Sie ein neues Konto.
- Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Alternativ können Sie Azure Cosmos DB kostenlos testen, bevor Sie sich festlegen.
Aktivieren des Analysespeichers
Aktivieren Sie zunächst Azure Synapse Link auf der Kontoebene und dann den Analysespeicher für die Container, die für Ihre Workload geeignet sind.
Aktivieren von Azure Synapse Link: Aktivieren von Azure Synapse Link für ein Azure Cosmos DB-Konto
Aktivieren Sie den Analysespeicher für Ihre Container:
Option Handbuch Aktivieren für einen bestimmten neuen Container Aktivieren von Azure Synapse Link für neue Container Aktivieren für einen bestimmten vorhandenen Container Aktivieren von Azure Synapse Link für vorhandene Container
Erstellen einer Azure-Zielressource mithilfe von Datenflüssen
Das Feature Change Data Capture des Analysespeichers ist über die Datenflussfunktion von Azure Data Factory oder Azure Synapse Analytics verfügbar. Verwenden Sie für diese Anleitung Azure Data Factory.
Wichtig
Alternativ können Sie Azure Synapse Analytics verwenden. Zunächst erstellen Sie einen Azure Synapse-Arbeitsbereich, sofern Sie noch keinen haben. Wählen Sie im neu erstellten Arbeitsbereich die Registerkarte Entwickeln aus, wählen Sie Neue Ressource hinzufügen und anschließend Datenfluss aus.
Erstellen Sie eine Azure Data Factory, falls Sie noch keine haben.
Tipp
Erstellen Sie nach Möglichkeit die Data Factory in derselben Region, in der sich Ihr Azure Cosmos DB-Konto befindet.
Starten Sie die neu erstellte Data Factory.
Wählen Sie in der Data Factory die Registerkarte Datenflüsse und dann Neuer Datenfluss aus.
Geben Sie dem neu erstellten Datenfluss einen eindeutigen Namen. In diesem Beispiel heißt der Datenfluss
cosmoscdc.

Konfigurieren von Quelleinstellungen für den Analysespeichercontainer
Erstellen und konfigurieren Sie nun eine Quelle für den Datenfluss aus dem Analysespeicher des Azure Cosmos DB-Kontos.
Wählen Sie Quelle hinzufügen aus.
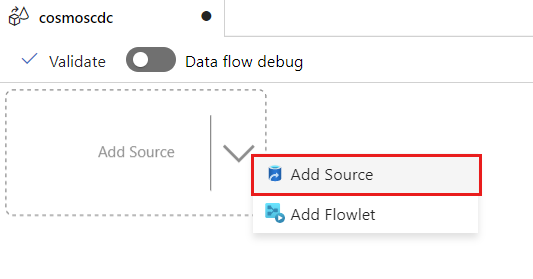
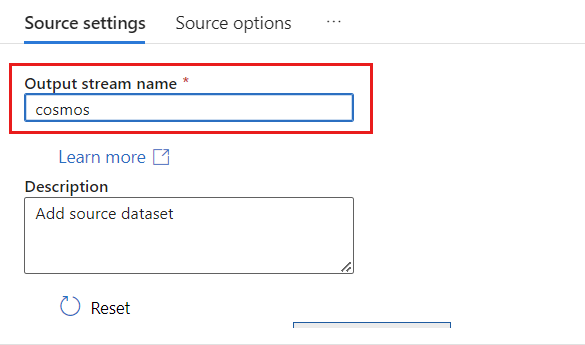
Geben Sie im Feld Ausgabedatenstromname den Namen cosmos an.
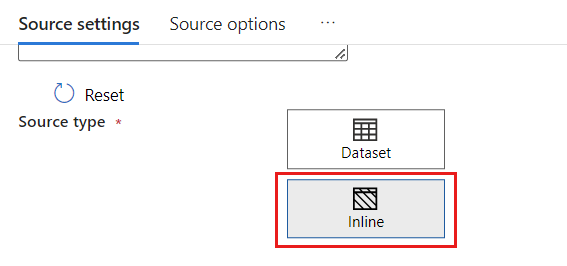
Wählen Sie im Abschnitt Quelltypdie Option Inline aus.
Wählen Sie im Feld Datasetdie Option Azure – Azure Cosmos DB for NoSQL aus.
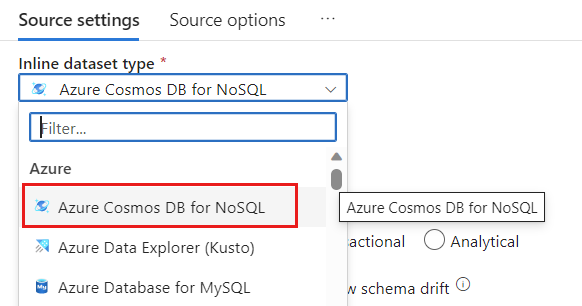
Erstellen Sie einen neuen verknüpften Dienst namens cosmoslinkedservice für Ihr Konto. Wählen Sie im Popupdialogfeld Neuer verknüpfter Dienst Ihr vorhandenes Azure Cosmos DB for NoSQL-Konto aus, und wählen Sie anschließend OK aus. In diesem Beispiel wählen wir ein bereits vorhandenes Azure Cosmos DB for NoSQL-Konto namens
msdocs-cosmos-sourceund eine Datenbank namenscosmicworksaus.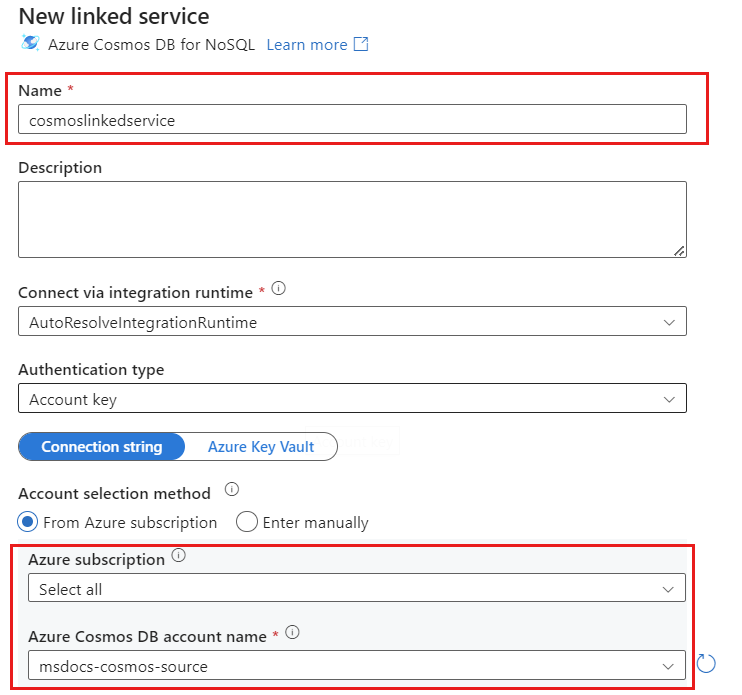
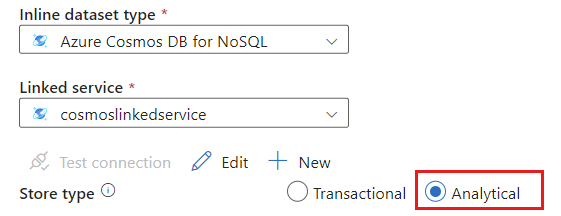
Wählen Sie für den Speichertyp die Option Analytisch aus.
Wählen Sie die Registerkarte Quelloptionen aus.
Wählen Sie in den Quelloptionen Ihren Zielcontainer aus, und aktivieren Sie Datenfluss debuggen. In diesem Beispiel hat der Container den Namen
products.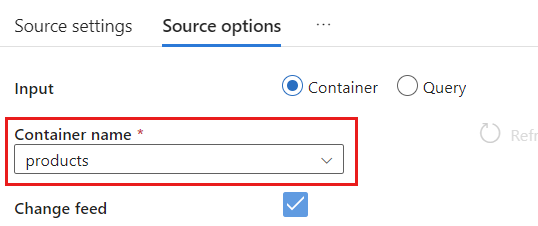
Wählen Sie Datenfluss debuggen aus. Behalten Sie im Popupdialog Datenfluss debuggen die Standardoptionen bei, und wählen Sie dann OK aus.
Die Registerkarte Quelloptionen enthält weitere Optionen, die Sie möglicherweise aktivieren sollten. In dieser Tabelle werden diese Optionen beschrieben:
| Option | Beschreibung |
|---|---|
| Zwischenaktualisierungen erfassen | Aktivieren Sie diese Option, wenn Sie den Verlauf der Änderungen an Elementen erfassen möchten, einschließlich der zwischenzeitlichen Änderungen zwischen Change Data Capture-Lesevorgängen. |
| Erfassen von Löschvorgänge erfassen | Aktivieren Sie diese Option, um vom Benutzer gelöschte Datensätze zu erfassen und sie auf die Senke anzuwenden. Löschvorgänge können nicht auf Azure Data Explorer- und Azure Cosmos DB-Senken angewendet werden. |
| Transaktionsspeicher-TTLs erfassen | Aktivieren Sie diese Option, um in der Azure Cosmos DB-Transaktionsspeicher-Gültigkeitsdauer (TTL, Time-to-Live) gelöschte Datensätze zu erfassen und auf die Senke anzuwenden. TTL-Löschvorgänge können nicht auf Azure Data Explorer- und Azure Cosmos DB-Senken angewendet werden. |
| Batchgröße in Byte | Bei dieser Einstellung handelt es sich tatsächlich um eine Angabe in Gigabyte. Geben Sie die Größe in Gigabyte an, wenn Sie die Change Data Capture-Feeds als Batch verarbeiten möchten. |
| Zusätzliche Konfigurationen | Zusätzliche Azure Cosmos DB-Analysespeicherkonfigurationen und deren Werte. (Beispiel: spark.cosmos.allowWhiteSpaceInFieldNames -> true) |
Arbeiten mit Quelloptionen
Wenn Sie eine der Optionen Capture intermediate updates, Capture Deltes und Capture Transactional store TTLs überprüfen, erstellt Ihr CDC-Prozess das Feld „__usr_opType“ in der Senke und füllt es mit den folgenden Werten auf:
| Wert | BESCHREIBUNG | Option |
|---|---|---|
| 1 | UPDATE | Zwischenaktualisierungen erfassen |
| 2 | INSERT | Es gibt keine Option für Einfügungen. Sie ist standardmäßig aktiviert. |
| 3 | USER_DELETE | Erfassen von Löschvorgänge erfassen |
| 4 | TTL_DELETE | Transaktionsspeicher-TTLs erfassen |
Wenn Sie die gelöschten TTL-Datensätze von Dokumenten unterscheiden müssen, die von Benutzern oder Anwendungen gelöscht wurden, müssen Sie sowohl die Option Capture intermediate updates als auch die Option Capture Transactional store TTLs überprüfen. Anschließend müssen Sie Ihre CDC-Prozesse, -Anwendungen oder -Abfragen so anpassen, dass sie __usr_opType entsprechend Ihren Geschäftsanforderungen verwenden.
Tipp
Wenn die nachgeschalteten Consumer die Reihenfolge der Updates wiederherstellen müssen, wobei die Option „Zwischenaktualisierungen erfassen“ aktiviert ist, kann das Systemzeitstempelfeld „_ts“ als Bestellfeld verwendet werden.
Erstellen und Konfigurieren von Senkeneinstellungen für Aktualisierungs- und Löschvorgänge
Erstellen Sie zunächst eine einfache Azure Blob Storage-Senke, und konfigurieren Sie dann die Senke so, dass sie Daten nur für bestimmte Vorgänge filtert.
Erstellen Sie ein Azure Blob Storage- Konto und einen Container, sofern Sie noch keine haben. In den nächsten Beispielen verwenden wir ein Konto namens
msdocsblobstorageund einen Container namensoutput.Tipp
Erstellen Sie nach Möglichkeit das Speicherkonto in derselben Region, in der sich Ihr Azure Cosmos DB-Konto befindet.
Erstellen Sie in Azure Data Factory eine neue Senke für die Änderungsdaten, die von Ihrer
cosmos-Quelle erfasst wurden.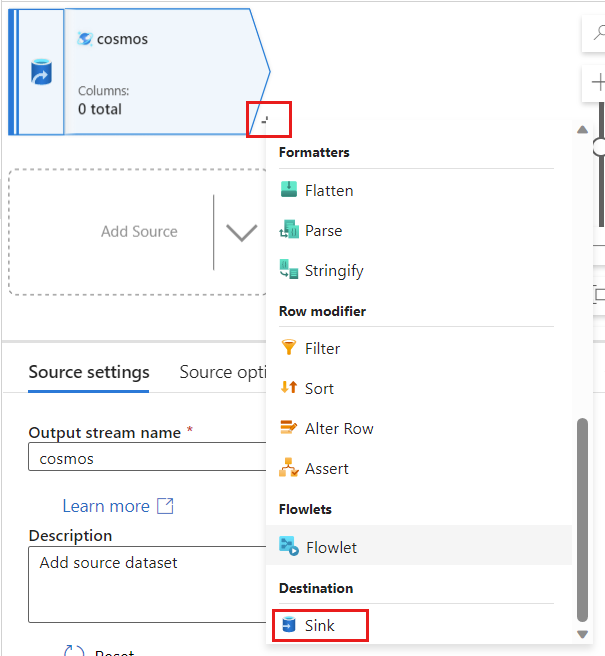
Geben Sie der Senke einen eindeutigen Namen. In diesem Beispiel heißt die Senke
storage.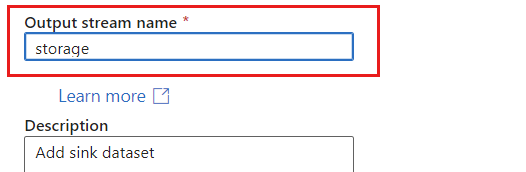
Wählen Sie im Abschnitt Quelltyp die Option Inline aus. Wählen Sie im Feld DataSet die Option Delta aus.
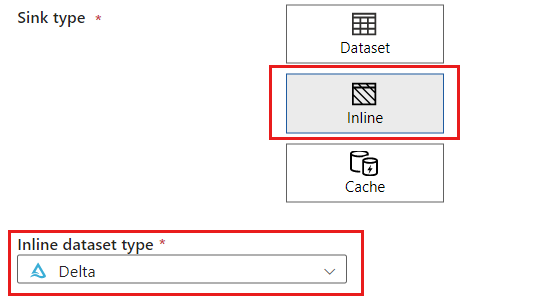
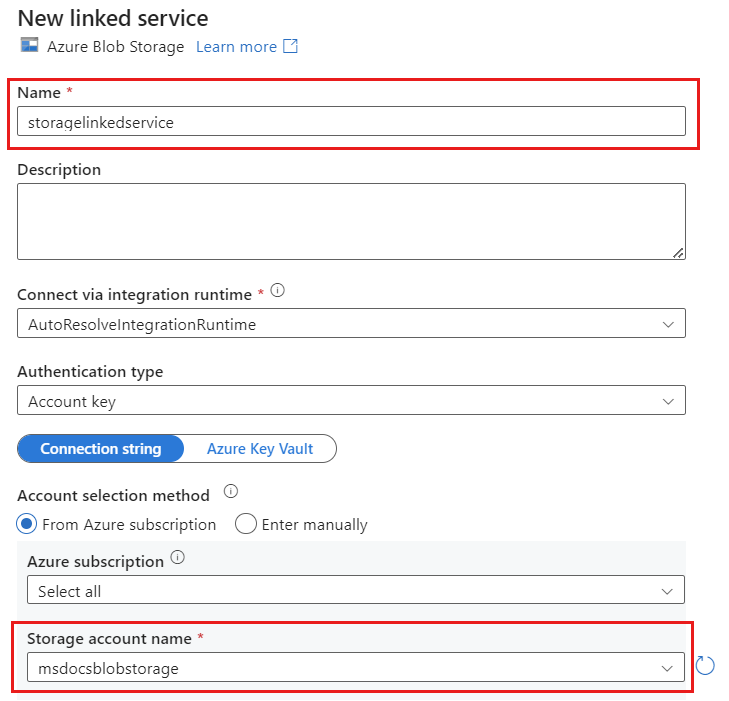
Erstellen Sie mithilfe Azure Blob Storage namens storagelinkedservice einen neuen verknüpften Dienst für Ihr Konto. Wählen Sie im Popupdialogfeld Neuer verknüpfter Dienst Ihr vorhandenes Azure Blob Storage-Konto aus, und wählen Sie anschließend OK aus. In diesem Beispiel wählen wir ein bereits vorhandenes Azure Blob Storage-Konto namens
msdocsblobstorage.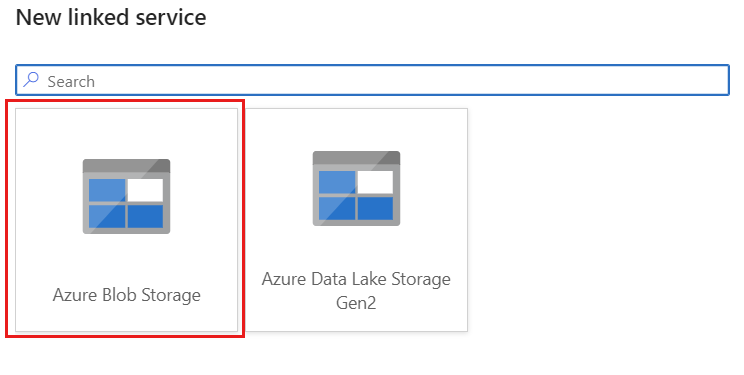
Wählen Sie die Registerkarte Einstellungen aus.
Legen Sie in den Einstellungen den Ordnerpfad auf den Namen des Blobcontainers fest. In diesem Beispiel lautet der Name des Containers
output.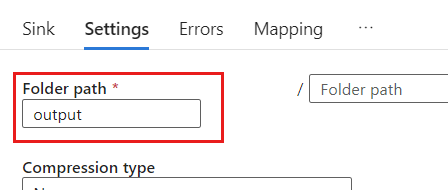
Suchen Sie den Abschnitt Update-Methode, und ändern Sie die Auswahl so, dass nur die Vorgänge Löschen und Aktualisieren zulässig sind. Geben Sie außerdem die Schlüsselspalten als Liste mit Spalten an, indem Sie das Feld
{_rid}als eindeutigen Bezeichner verwenden.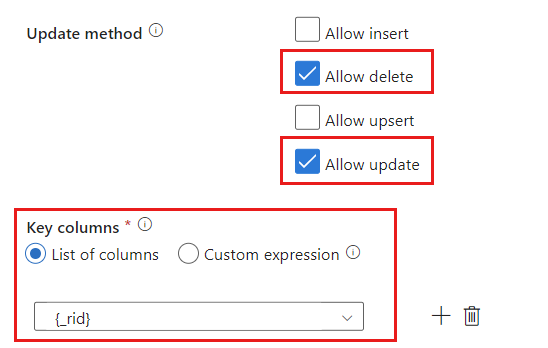
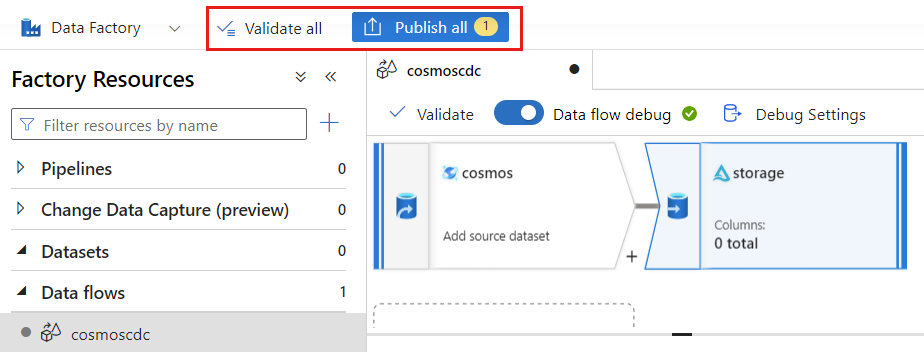
Wählen Sie Überprüfen aus, um sicherzustellen, dass Sie keine Fehler gemacht oder nichts ausgelassen haben. Wählen Sie anschließend Veröffentlichen aus, um den Datenfluss zu veröffentlichen.
Planen der Change Data Capture-Ausführung
Nachdem ein Datenfluss veröffentlicht wurde, können Sie eine neue Pipeline hinzufügen, um Ihre Daten zu verschieben und zu transformieren.
Erstellen einer neuen Pipeline Geben Sie der Pipeline einen eindeutigen Namen. In diesem Beispiel hat die Pipeline den Namen
cosmoscdcpipeline.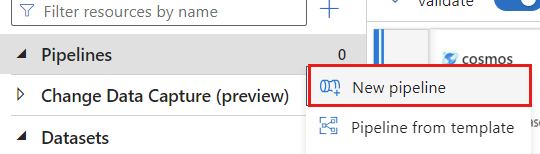
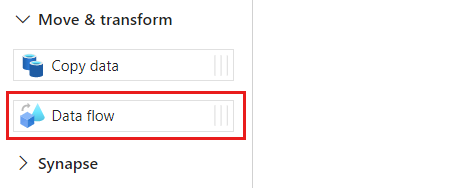
Erweitern Sie im Abschnitt Aktivitäten die Option Verschieben und transformieren, und wählen Sie dann Datenfluss aus.
Geben Sie der Datenflussaktivität einen eindeutigen Namen. In diesem Beispiel heißt die Aktivität
cosmoscdcactivity.Wählen Sie auf der Registerkarte Einstellungen den Datenfluss mit dem Namen
cosmoscdcaus, den Sie zuvor in dieser Anleitung erstellt haben. Wählen Sie dann eine Computegröße basierend auf dem Datenvolumen und der erforderlichen Latenz für Ihre Workload aus.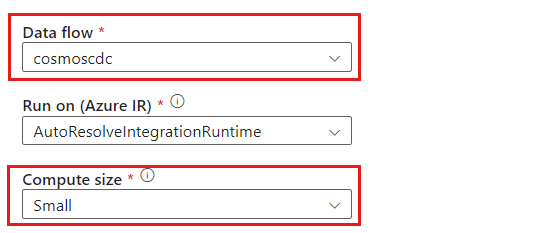
Tipp
Für inkrementelle Datengrößen über 100 GB wird eine benutzerdefinierte Größe mit einer Kernanzahl von 32 (+16 Treiberkerne) empfohlen.
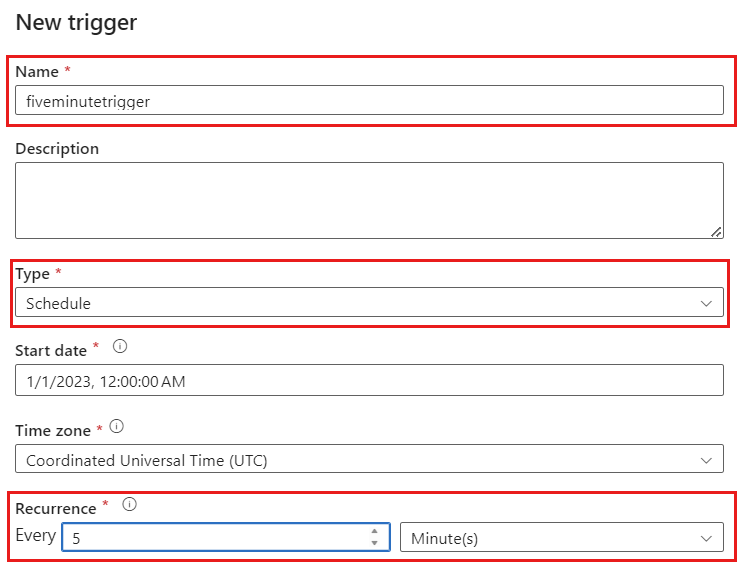
Wählen Sie Trigger hinzufügen aus. Planen Sie die Pipeline so, dass sie in einem für Ihre Workload sinnvollen Rhythmus ausgeführt wird. In diesem Beispiel wird die Pipeline so konfiguriert, dass sie alle fünf Minuten ausgeführt wird.
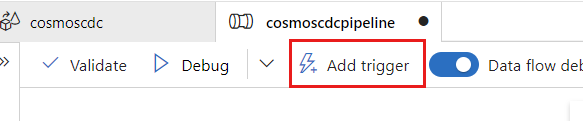
Hinweis
Das minimale Wiederholungsfenster für die Ausführung von Change Data Capture beträgt eine Minute.
Wählen Sie Überprüfen aus, um sicherzustellen, dass Sie keine Fehler gemacht oder nichts ausgelassen haben. Wählen Sie anschließend Veröffentlichen aus, um die Pipeline zu veröffentlichen:
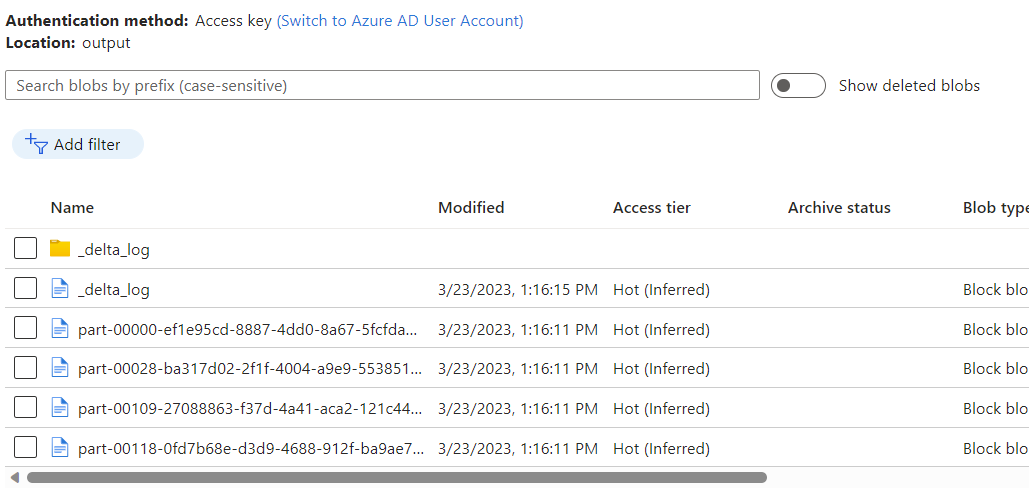
Beobachten Sie die Daten, die im Azure Blob Storage-Container als Ausgabe des Datenflusses mithilfe von Change Data Capture des Azure Cosmos DB-Analysespeichers platziert werden.
Hinweis
Die anfängliche Startzeit des Clusters kann bis zu drei Minuten dauern. Um die Startzeit des Clusters in den nachfolgenden Ausführungen von Change Data Capture zu vermeiden, konfigurieren Sie den Wert für die Gültigkeitsdauer des Datenflusses. Weitere Informationen zu Integration Runtime und TTL finden Sie unter Integration Runtime in Azure Data Factory.
Gleichzeitige Aufträge
Die Verwendung der Batchgröße in den Quelloptionen oder Situationen, in denen die Senke den Datenstrom von Änderungen langsam erfasst, können dazu führen, dass mehrere Aufträge gleichzeitig ausgeführt werden. Um dies zu vermeiden, legen Sie die Option Parallelität in den Pipelineeinstellungen auf 1 fest, um sicherzustellen, dass neue Ausführungen erst ausgelöst werden, wenn die aktuelle Ausführung abgeschlossen ist.
Nächste Schritte
- Sehen Sie sich die Übersicht über den Azure Cosmos DB-Analysespeicher an.