Erweiterung „pg_azure_storage“
GILT FÜR: ![]() Azure Cosmos DB for PostgreSQL (unterstützt von der Citus-Datenbankerweiterung auf PostgreSQL)
Azure Cosmos DB for PostgreSQL (unterstützt von der Citus-Datenbankerweiterung auf PostgreSQL)
Mit der Erweiterung „pg_azure_storage“ können Sie Daten in mehreren Dateiformaten direkt aus Azure Blob Storage in Ihren Azure Cosmos DB for PostgreSQL-Cluster laden. Durch aktivieren der Erweiterung werden auch neue Funktionen des COPY-Befehls freigeschaltet. Container mit der Zugriffsebene „Privat“ oder „Blob“ erfordern das Hinzufügen eines privaten Zugriffsschlüssels.
Sie können die Erweiterung erstellen, indem Sie Folgendes ausführen:
SELECT create_extension('azure_storage');
azure_storage.account_add
Die Funktion ermöglicht das Hinzufügen des Zugriffs auf ein Speicherkonto.
azure_storage.account_add
(account_name_p text
,account_key_p text);
Argumente
account_name_p
Ein Azure Blob Storage (ABS)-Konto enthält alle Ihre ABS-Objekte: Blobs, Dateien, Warteschlangen und Tabellen. Das Speicherkonto stellt einen eindeutigen Namespace für Ihr ABS bereit, auf den von jedem Ort der Welt aus über HTTPS zugegriffen werden kann.
account_key_p
Ihre Azure Blob Storage (ABS)-Zugriffsschlüssel ähneln einem Stammkennwort für das Speicherkonto. Achten Sie darauf, die Zugriffsschlüssel immer gut zu schützen. Verwenden Sie Azure Key Vault zum sicheren Verwalten und Rotieren Ihrer Schlüssel. Der Kontoschlüssel wird in einer Tabelle gespeichert, auf die der postgres-Superuser, azure_storage_admin und alle Rolle, denen diese Administratorberechtigungen gewährt werden, zugreifen können. Um zu ermitteln, welche Speicherkonten vorhanden sind, verwenden Sie die Funktion „account_list“.
azure_storage.account_remove
Die Funktion ermöglicht das Aufheben des Kontozugriffs auf das Speicherkonto.
azure_storage.account_remove
(account_name_p text);
Argumente
account_name_p
Das Azure Blob Storage (ABS)-Konto enthält alle Ihre ABS-Objekte: Blobs, Dateien, Warteschlangen und Tabellen. Das Speicherkonto stellt einen eindeutigen Namespace für Ihr ABS bereit, auf den von jedem Ort der Welt aus über HTTPS zugegriffen werden kann.
azure_storage.account_user_add
Die Funktion ermöglicht das Hinzufügen des Zugriffs für eine Rolle zu einem Speicherkonto.
azure_storage.account_user_add
( account_name_p text
, user_p regrole);
Argumente
account_name_p
Ein Azure Blob Storage (ABS)-Konto enthält alle Ihre ABS-Objekte: Blobs, Dateien, Warteschlangen und Tabellen. Das Speicherkonto stellt einen eindeutigen Namespace für Ihr ABS bereit, auf den von jedem Ort der Welt aus über HTTPS zugegriffen werden kann.
user_p
Eine Rolle, die vom Benutzer erstellt wurde, der im Cluster sichtbar ist.
Hinweis
account_user_add-,account_add-,account_remove- und account_user_remove-Funktionen erfordern das Festlegen von Berechtigungen für jeden einzelnen Knoten im Cluster.
azure_storage.account_user_remove
Die Funktion ermöglicht das Entfernen des Zugriffs für eine Rolle auf ein Speicherkonto.
azure_storage.account_user_remove
(account_name_p text
,user_p regrole);
Argumente
account_name_p
Ein Azure Blob Storage (ABS)-Konto enthält alle Ihre ABS-Objekte: Blobs, Dateien, Warteschlangen und Tabellen. Das Speicherkonto stellt einen eindeutigen Namespace für Ihr ABS bereit, auf den von jedem Ort der Welt aus über HTTPS zugegriffen werden kann.
user_p
Eine Rolle, die vom Benutzer erstellt wurde, der im Cluster sichtbar ist.
azure_storage.account_list
Die Funktion listet das Konto und die Rolle auf, das Zugriff auf Azure Blob Storage hat.
azure_storage.account_list
(OUT account_name text
,OUT allowed_users regrole[]
)
Returns TABLE;
Argumente
account_name
Das Azure Blob Storage (ABS)-Konto enthält alle Ihre ABS-Objekte: Blobs, Dateien, Warteschlangen und Tabellen. Das Speicherkonto stellt einen eindeutigen Namespace für Ihr ABS bereit, auf den von jedem Ort der Welt aus über HTTPS zugegriffen werden kann.
allowed_users
Listet die Benutzer auf, die Zugriff auf den Azure-Blobspeicher haben.
Rückgabetyp
TABLE
azure_storage.blob_list
Die Funktion listet die verfügbaren Blobdateien in einem Benutzercontainer mit ihren Eigenschaften auf.
azure_storage.blob_list
(account_name text
,container_name text
,prefix text DEFAULT ''::text
,OUT path text
,OUT bytes bigint
,OUT last_modified timestamp with time zone
,OUT etag text
,OUT content_type text
,OUT content_encoding text
,OUT content_hash text
)
Returns SETOF record;
Argumente
account_name
Das storage account name stellt einen eindeutigen Namespace für Ihre Azure Storage-Daten bereit, auf den von jedem Ort der Welt aus über HTTPS zugegriffen werden kann.
container_name
Ein Container dient zum Organisieren einer Gruppe von Blobs (ähnlich wie ein Verzeichnis in einem Dateisystem). Ein Speicherkonto kann eine unbegrenzte Anzahl von Containern enthalten, und in einem Container kann eine unbegrenzte Anzahl von Blobs gespeichert werden. Ein Containername muss ein gültiger DNS-Name sein, da er Teil des eindeutigen URI ist, der für die Adressierung des Containers oder seiner Blobs verwendet wird. Befolgen Sie diese Regeln, wenn Sie einen Container benennen:
- Containernamen können zwischen 3 und 63 Zeichen lang sein.
- Containernamen müssen mit einem Buchstaben oder einer Zahl beginnen und dürfen nur Kleinbuchstaben, Zahlen und Bindestriche (-) enthalten.
- Zwei oder mehr aufeinanderfolgende Bindestriche sind in Containernamen nicht zulässig.
Der URI für einen Container ähnelt https://myaccount.blob.core.windows.net/mycontainer.
prefix
Gibt eine Datei aus dem Blobcontainer mit übereinstimmenden Zeichenfolgeninitialen zurück.
path
Vollständig qualifizierter Pfad des Azure-Blobverzeichnisses.
Byte
Größe des Dateiobjekts in Bytes.
last_modified
Letzte Änderung der Dateiinhalte am:
etag
Eine ETag-Eigenschaft wird für die optimistische Parallelität während Updates verwendet. Es handelt sich nicht um einen Zeitstempel, da es eine andere Eigenschaft namens „Timestamp“ gibt, die die letzte Aktualisierung eines Datensatzes speichert. Wenn Sie beispielsweise eine Entität laden und sie aktualisieren möchten, muss das ETag mit dem übereinstimmen, was derzeit gespeichert ist. Das Festlegen des entsprechenden ETags ist wichtig, denn wenn mehrere Benutzer dasselbe Element bearbeiten, sollen sie die Änderungen der anderen nicht überschreiben.
content_type
Das Blobobjekt stellt ein Blob dar, bei dem es sich um ein dateiähnliches Objekt mit unveränderlichen Rohdaten handelt. Sie können als Text- oder Binärdaten gelesen oder in einen ReadableStream konvertiert werden, sodass die Methoden für die Verarbeitung der Daten verwendet werden können. Blobs können Daten darstellen, die nicht unbedingt in einem nativen JavaScript-Format vorliegen.
content_encoding
Mit Azure Storage können Sie die Eigenschaft „Content-Encoding“ für ein Blob definieren. Für komprimierte Inhalte können Sie die Eigenschaft auf „GZIP“ festlegen. Wenn der Browser auf den Inhalt zugreift, dekomprimiert er den Inhalt automatisch.
content_hash
Mithilfe des Hash wird die Integrität des BLOB während der Übertragung überprüft. Bei Angabe dieses Headers überprüft der Speicherdienst den Hash, der zusammen mit dem gesendeten eingegangen ist. Wenn die beiden Hashs nicht übereinstimmen, schlägt der Vorgang mit Fehlercode 400 (Ungültige Anforderung) fehl.
Rückgabetyp
SETOF-Datensatz
Hinweis
citus userBerechtigungenazure_storage_admin Jetzt können Sie Container auflisten, die für diesen Speicher auf die Zugriffsebenen „Privat“ und „Blob“ festlegt sind, aber nur als , dem die -Rolle zugewiesen wurde. Wenn Sie einen neuen Benutzer mit Namen support erstellen, ist es standardmäßig nicht zulässig, auf Containerinhalte zuzugreifen.
azure_storage.blob_get
Die Funktion ermöglicht das Laden des Inhalts der Datei\Dateien aus dem Container, wobei Unterstützung für das Filtern oder Bearbeiten von Daten vor dem Import hinzugefügt wurde.
azure_storage.blob_get
(account_name text
,container_name text
,path text
,decoder text DEFAULT 'auto'::text
,compression text DEFAULT 'auto'::text
,options jsonb DEFAULT NULL::jsonb
)
RETURNS SETOF record;
Es gibt eine überladene Version der Funktion, die den Rec-Parameter enthält, mit dem Sie den Ausgabeformatdatensatz bequem definieren können.
azure_storage.blob_get
(account_name text
,container_name text
,path text
,rec anyelement
,decoder text DEFAULT 'auto'::text
,compression text DEFAULT 'auto'::text
,options jsonb DEFAULT NULL::jsonb
)
RETURNS SETOF anyelement;
Argumente
account
Das Speicherkonto stellt einen eindeutigen Namespace für Ihre Azure Storage-Daten bereit, auf den von jedem Ort der Welt aus über HTTPS zugegriffen werden kann.
Container
Ein Container dient zum Organisieren einer Gruppe von Blobs (ähnlich wie ein Verzeichnis in einem Dateisystem). Ein Speicherkonto kann eine unbegrenzte Anzahl von Containern enthalten, und in einem Container kann eine unbegrenzte Anzahl von Blobs gespeichert werden. Ein Containername muss ein gültiger DNS-Name sein, da er Teil des eindeutigen URI ist, der für die Adressierung des Containers oder seiner Blobs verwendet wird.
path
Ein Blobname, der im Container vorhanden ist.
rrec
Definieren Sie die Datensatzausgabestruktur.
Decoder
Geben Sie an, ob der Blobformat-Decoder auf „auto (Standard)“ oder auf einen der folgenden Werte festgelegt werden kann
Decoderbeschreibung
| Format | Beschreibung |
|---|---|
| csv | Durch Komma getrenntes Format für Werte, das von PostgreSQL COPY verwendet wird |
| tsv | Durch Tabstopp getrennte Werte – das Standardformat PostgreSQL COPY |
| BINARY | Format Binary PostgreSQL COPY |
| text | Datei mit einem einzelnen Textwert (z. B. große JSON oder XML) |
compression
Definiert das Komprimierungsformat. Verfügbare Optionen sind auto, gzip & none. Option „auto (Standard)“ errät die Komprimierung basierend auf der Dateierweiterung (.gz == gzip). Die Option „none“ erzwingt, die Erweiterung zu ignorieren und nicht zu decodieren. gzip hingegen erzwingt die Verwendung des gzip-Decoders (wenn Sie eine gzipped-Datei mit einer nicht standardmäßigen Erweiterung haben). Derzeit werden keine anderen Komprimierungsformate für die Erweiterung unterstützt.
Optionen
Für die Verarbeitung von benutzerdefinierten Kopfzeilen, benutzerdefinierten Trennzeichen, Escapezeichen usw. funktioniert options auf ähnliche Weise wie der Befehl „COPY“ in PostgreSQL, wobei der Parameter für die Funktion „blob_get“ verwendet wird.
Rückgabetyp
SETOF Record / anyelement
Hinweis
Es gibt vier Hilfsfunktionen, die als Parameter in blob_get aufgerufen werden, um Werte dafür zu erstellen. Jede Hilfsfunktion ist für den Decoder vorgesehen, der seinem Namen entspricht.
azure_storage.options_csv_get
Die Funktion fungiert als Hilfsfunktion, die als Parameter in blob_get aufgerufen wird, was nützlich für das Decodieren des CSV-Inhalts ist.
azure_storage.options_csv_get
(delimiter text DEFAULT NULL::text
,null_string text DEFAULT NULL::text
,header boolean DEFAULT NULL::boolean
,quote text DEFAULT NULL::text
,escape text DEFAULT NULL::text
,force_not_null text[] DEFAULT NULL::text[]
,force_null text[] DEFAULT NULL::text[]
,content_encoding text DEFAULT NULL::text
)
Returns jsonb;
Argumente
Trennzeichen
Gibt das Zeichen an, das Spalten innerhalb jeder Zeile (Linie) der Datei trennt. Die Standardeinstellung ist ein Tabulatorzeichen im Textformat, ein Komma im CSV-Format. Es muss ein einzelnes Ein-Byte-Zeichen sein.
null_string
Gibt die Zeichenfolge an, die einen NULL-Wert darstellt. Der Standardwert ist \N (umgekehrter Schrägstrich-N) im Textformat und eine leere Zeichenfolge ohne Anführungszeichen im CSV-Format. Möglicherweise bevorzugen Sie eine leere Zeichenfolge auch im Textformat, wenn Sie Null nicht von leeren Zeichenfolgen unterscheiden möchten.
header
Gibt an, dass die Datei eine Kopfzeile mit den Namen jeder Spalte in der Datei enthält. Bei der Ausgabe enthält die erste Zeile die Spaltennamen aus der Tabelle.
Quote
Gibt das Anführungszeichen an, das verwendet werden soll, wenn ein Datenwert in Anführungszeichen gesetzt wird. Standardmäßig sind dies doppelte Anführungszeichen. Es muss ein einzelnes Ein-Byte-Zeichen sein.
Escape
Gibt das Zeichen an, das vor einem Datenzeichen angezeigt werden soll, das dem QUOTE-Wert entspricht. Der Standardwert ist identisch mit dem QUOTE-Wert (sodass das Anführungszeichen verdoppelt werden, wenn es in den Daten angezeigt wird). Es muss ein einzelnes Ein-Byte-Zeichen sein.
force_not_null
Die Werte der angegebenen Spalten werden nicht mit der NULL-Zeichenfolge abgestimmt. Im Standardfall, in dem die NULL-Zeichenfolge leer ist, bedeutet dies, dass leere Werte als Zeichenfolgen der Länge null und nicht als NULLEN gelesen werden, auch wenn sie nicht in Anführungszeichen stehen.
force_null
Die Werte der angegebenen Spalten werden mit der NULL-Zeichenfolge abgestimmt, auch wenn sie in Anführungszeichen angegeben wurde, und der Wert wird auf NULL festgelegt, wenn eine Übereinstimmung gefunden wird. Im Standardfall, in dem die NULL-Zeichenfolge leer ist, konvertiert sie eine leere Zeichenfolge in Anführungszeichen in NULL.
content_encoding
Gibt an, dass die Datei als „encoding_name“ codiert ist. Wenn die Option ausgelassen wird, wird die aktuelle Clientcodierung verwendet.
Rückgabetyp
jsonb
azure_storage.options_copy
Die Funktion fungiert als Hilfsfunktion, die als Parameter innerhalb von blob_get aufgerufen wird.
azure_storage.options_copy
(delimiter text DEFAULT NULL::text
,null_string text DEFAULT NULL::text
,header boolean DEFAULT NULL::boolean
,quote text DEFAULT NULL::text
,escape text DEFAULT NULL::text
,force_quote text[] DEFAULT NULL::text[]
,force_not_null text[] DEFAULT NULL::text[]
,force_null text[] DEFAULT NULL::text[]
,content_encoding text DEFAULT NULL::text
)
Returns jsonb;
Argumente
Trennzeichen
Gibt das Zeichen an, das Spalten innerhalb jeder Zeile (Linie) der Datei trennt. Die Standardeinstellung ist ein Tabulatorzeichen im Textformat, ein Komma im CSV-Format. Es muss ein einzelnes Ein-Byte-Zeichen sein.
null_string
Gibt die Zeichenfolge an, die einen NULL-Wert darstellt. Der Standardwert ist \N (umgekehrter Schrägstrich-N) im Textformat und eine leere Zeichenfolge ohne Anführungszeichen im CSV-Format. Möglicherweise bevorzugen Sie eine leere Zeichenfolge auch im Textformat, wenn Sie Null nicht von leeren Zeichenfolgen unterscheiden möchten.
header
Gibt an, dass die Datei eine Kopfzeile mit den Namen jeder Spalte in der Datei enthält. Bei der Ausgabe enthält die erste Zeile die Spaltennamen aus der Tabelle.
Quote
Gibt das Anführungszeichen an, das verwendet werden soll, wenn ein Datenwert in Anführungszeichen gesetzt wird. Standardmäßig sind dies doppelte Anführungszeichen. Es muss ein einzelnes Ein-Byte-Zeichen sein.
Escape
Gibt das Zeichen an, das vor einem Datenzeichen angezeigt werden soll, das dem QUOTE-Wert entspricht. Der Standardwert ist identisch mit dem QUOTE-Wert (sodass das Anführungszeichen verdoppelt werden, wenn es in den Daten angezeigt wird). Es muss ein einzelnes Ein-Byte-Zeichen sein.
force_quote
Erzwingt die Verwendung von Anführungszeichen für alle Nicht-NULL-Werte in jeder angegebenen Spalte. Die NULL-Ausgabe wird nie in Anführungszeichen gesetzt. Wenn * angegeben ist, werden in allen Spalten Werte ohne NULL in Anführungszeichen gesetzt.
force_not_null
Die Werte der angegebenen Spalten werden nicht mit der NULL-Zeichenfolge abgestimmt. Im Standardfall, in dem die NULL-Zeichenfolge leer ist, bedeutet dies, dass leere Werte als Zeichenfolgen der Länge null und nicht als NULLEN gelesen werden, auch wenn sie nicht in Anführungszeichen stehen.
force_null
Die Werte der angegebenen Spalten werden mit der NULL-Zeichenfolge abgestimmt, auch wenn sie in Anführungszeichen angegeben wurde, und der Wert wird auf NULL festgelegt, wenn eine Übereinstimmung gefunden wird. Im Standardfall, in dem die NULL-Zeichenfolge leer ist, konvertiert sie eine leere Zeichenfolge in Anführungszeichen in NULL.
content_encoding
Gibt an, dass die Datei als „encoding_name“ codiert ist. Wenn die Option ausgelassen wird, wird die aktuelle Clientcodierung verwendet.
Rückgabetyp
jsonb
azure_storage.options_tsv
Die Funktion fungiert als Hilfsfunktion, die als Parameter innerhalb von blob_get aufgerufen wird. Sie ist nützlich, um den TSV-Inhalt zu decodieren.
azure_storage.options_tsv
(delimiter text DEFAULT NULL::text
,null_string text DEFAULT NULL::text
,content_encoding text DEFAULT NULL::text
)
Returns jsonb;
Argumente
Trennzeichen
Gibt das Zeichen an, das Spalten innerhalb jeder Zeile (Linie) der Datei trennt. Die Standardeinstellung ist ein Tabulatorzeichen im Textformat, ein Komma im CSV-Format. Es muss ein einzelnes Ein-Byte-Zeichen sein.
null_string
Gibt die Zeichenfolge an, die einen NULL-Wert darstellt. Der Standardwert ist \N (umgekehrter Schrägstrich-N) im Textformat und eine leere Zeichenfolge ohne Anführungszeichen im CSV-Format. Möglicherweise bevorzugen Sie eine leere Zeichenfolge auch im Textformat, wenn Sie Null nicht von leeren Zeichenfolgen unterscheiden möchten.
content_encoding
Gibt an, dass die Datei als „encoding_name“ codiert ist. Wenn die Option ausgelassen wird, wird die aktuelle Clientcodierung verwendet.
Rückgabetyp
jsonb
azure_storage.options_binary
Die Funktion fungiert als Hilfsfunktion, die als Parameter innerhalb von blob_get aufgerufen wird. Sie ist nützlich, um den binären Inhalt zu decodieren.
azure_storage.options_binary
(content_encoding text DEFAULT NULL::text)
Returns jsonb;
Argumente
content_encoding
Gibt an, dass die Datei als „encoding_name“ codiert ist. Wenn diese Option weggelassen wird, wird die aktuelle Clientcodierung verwendet.
Rückgabetyp
jsonb
Hinweis
citus userBerechtigungenazure_storage_admin Jetzt können Sie Container auflisten, die für diesen Speicher auf die Zugriffsebenen „Privat“ und „Blob“ festlegt sind, aber nur als , dem die -Rolle zugewiesen wurde. Wenn Sie einen neuen Benutzer names „Support“ erstellen, ist es standardmäßig nicht zulässig, auf Containerinhalte zuzugreifen.
Beispiele
In den verwendeten Beispielen wird das Azure-Beispielspeicherkonto „(pgquickstart)“ mit benutzerdefinierten Dateien verwendet, die zur Abdeckung verschiedener Anwendungsfälle hochgeladen wurden. Sie können damit beginnen, eine Tabelle zu erstellen, die für den gesamten Satz von Beispielen verwendet wird.
CREATE TABLE IF NOT EXISTS public.events
(
event_id bigint
,event_type text
,event_public boolean
,repo_id bigint
,payload jsonb
,repo jsonb
,user_id bigint
,org jsonb
,created_at timestamp without time zone
);
Hinzufügen des Zugriffsschlüssels des Speicherkontos (obligatorisch für Zugriffsebene = privat)
Das Beispiel veranschaulicht das Hinzufügen eines Zugriffsschlüssels für das Speicherkonto, um Zugriff auf Abfragen aus einer Sitzung im Azure Cosmos DB for Postgres-Cluster zu erhalten.
SELECT azure_storage.account_add('pgquickstart', 'SECRET_ACCESS_KEY');
Tipp
Öffnen Sie in Ihrem Speicherkonto Zugriffsschlüssel. Kopieren Sie den Namen des Speicherkontos und den Schlüssel aus Abschnitt Schlüssel1 (Sie müssen zuerst Show neben dem Schlüssel auswählen).
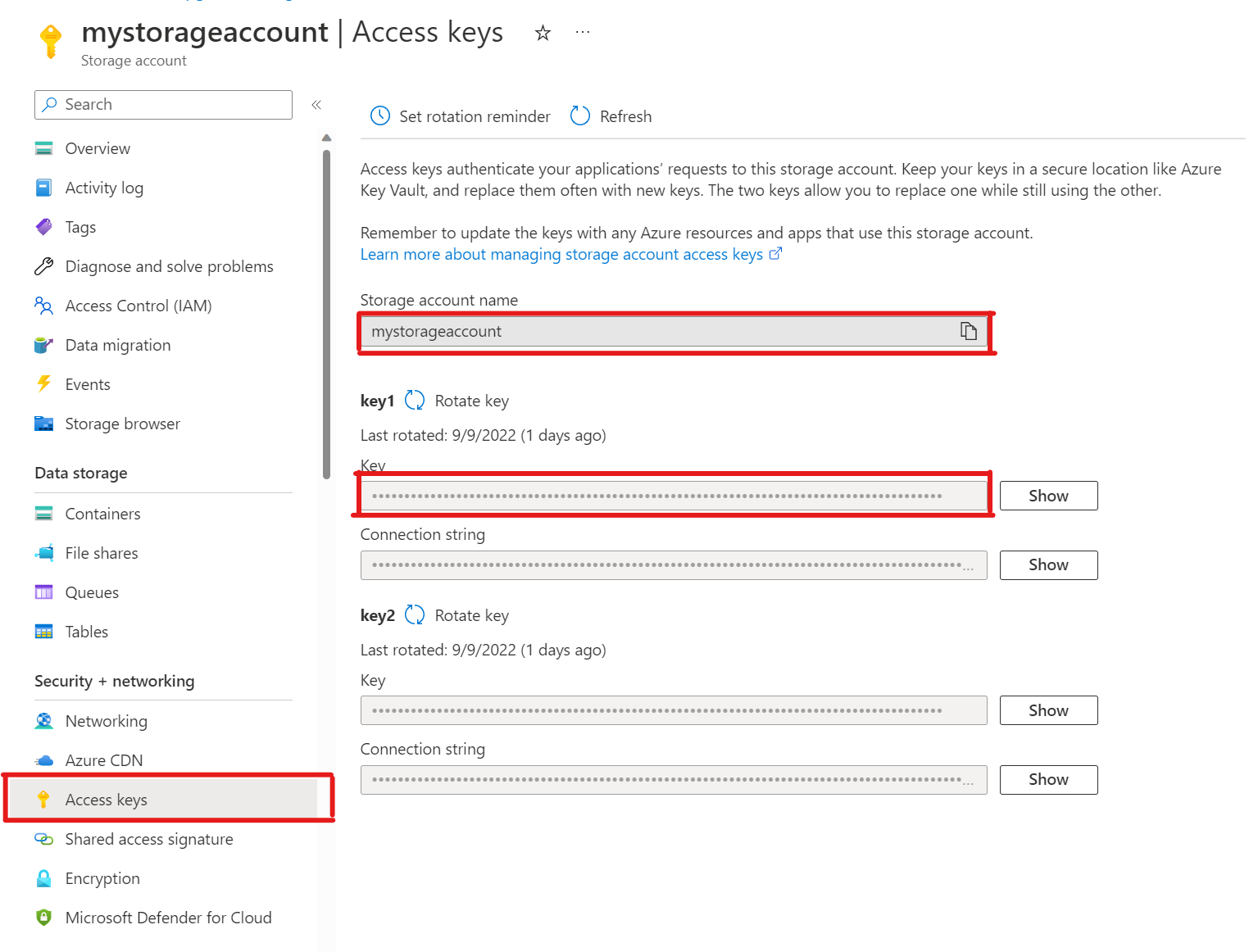
Entfernen des Zugriffsschlüssels des Speicherkontos
Das Beispiel veranschaulicht das Entfernen des Zugriffsschlüssels für ein Speicherkonto. Diese Aktion führt dazu, dass der Zugriff auf Dateien entfernt wird, die im privaten Bucket im Container gehostet werden.
SELECT azure_storage.account_remove('pgquickstart');
Hinzufügen des Zugriffs für eine Rolle zu Azure Blob-Speicher
SELECT * FROM azure_storage.account_user_add('pgquickstart', 'support');
Auflisten aller Rollen mit Zugriff auf Azure Blob-Speicher
SELECT * FROM azure_storage.account_list();
Entfernen der Rollen mit Zugriff auf Azure Blob-Speicher
SELECT * FROM azure_storage.account_user_remove('pgquickstart', 'support');
Auflisten der Objekte in einem public-Container
SELECT * FROM azure_storage.blob_list('pgquickstart','publiccontainer');
Auflisten der Objekte in einem private-Container
SELECT * FROM azure_storage.blob_list('pgquickstart','privatecontainer');
Hinweis
Das Hinzufügen des Zugriffsschlüssels ist obligatorisch.
Auflisten der Objekte mit bestimmten Zeichenfolgeninitialen im öffentlichen Container
SELECT * FROM azure_storage.blob_list('pgquickstart','publiccontainer','e');
Alternativ
SELECT * FROM azure_storage.blob_list('pgquickstart','publiccontainer') WHERE path LIKE 'e%';
Lesen von Inhalten aus einem Objekt in einem Container
Die Funktion „blob_get“ ruft eine Datei aus dem Blobspeicher ab. Damit blob_get weiß, wie die Daten analysiert werden, können Sie einen Wert (NULL::table_name) übergeben, der dasselbe Format wie die Datei hat.
SELECT * FROM azure_storage.blob_get
('pgquickstart'
,'publiccontainer'
,'events.csv.gz'
, NULL::events)
LIMIT 5;
Alternativ können wir die Spalten in der FROM-Klausel explizit definieren.
SELECT * FROM azure_storage.blob_get('pgquickstart','publiccontainer','events.csv')
AS res (
event_id BIGINT
,event_type TEXT
,event_public BOOLEAN
,repo_id BIGINT
,payload JSONB
,repo JSONB
,user_id BIGINT
,org JSONB
,created_at TIMESTAMP WITHOUT TIME ZONE)
LIMIT 5;
Verwenden von Decoderoption
Dieses Beispiel beschreibt die Verwendung der decoder-Option. Normalerweise wird das Format aus der Erweiterung der Datei abgeleitet, aber wenn die Dateiinhalte keine übereinstimmende Erweiterung aufweisen, können Sie das Decoderargument übergeben.
SELECT * FROM azure_storage.blob_get
('pgquickstart'
,'publiccontainer'
,'events'
, NULL::events
, decoder := 'csv')
LIMIT 5;
Verwenden der Komprimierung mit Decoderoption
Das Beispiel zeigt, wie Sie die Verwendung der gzip-Komprimierung für eine gzip-komprimierte Datei ohne gz-Standarderweiterung erzwingen.
SELECT * FROM azure_storage.blob_get
('pgquickstart'
,'publiccontainer'
,'events-compressed'
, NULL::events
, decoder := 'csv'
, compression := 'gzip')
LIMIT 5;
Importieren gefilterter Inhalte und Ändern vor dem Laden aus dem CSV-Formatobjekt
Das Beispiel veranschaulicht die Möglichkeit, den Inhalt zu filtern und zu ändern, der aus einem Objekt im Container importiert wird, bevor er in eine SQL-Tabelle geladen wird.
SELECT concat('P-',event_id::text) FROM azure_storage.blob_get
('pgquickstart'
,'publiccontainer'
,'events.csv'
, NULL::events)
WHERE event_type='PushEvent'
LIMIT 5;
Abfragen von Inhalten aus einer Datei mit Kopfzeilen, benutzerdefinierten Trennzeichen, Escapezeichen
Sie können benutzerdefinierte Trennzeichen und Escapezeichen verwenden, indem Sie das Ergebnis von azure_storage.options_copy an das options-Argument übergeben.
SELECT * FROM azure_storage.blob_get
('pgquickstart'
,'publiccontainer'
,'events_pipe.csv'
,NULL::events
,options := azure_storage.options_csv_get(delimiter := '|' , header := 'true')
);
Aggregationsabfrage zum Inhalt eines Objekts im Container
Auf diese Weise können Sie Daten abfragen, ohne sie zu importieren.
SELECT event_type,COUNT(1) FROM azure_storage.blob_get
('pgquickstart'
,'publiccontainer'
,'events.csv'
, NULL::events)
GROUP BY event_type
ORDER BY 2 DESC
LIMIT 5;