Microservices
In diesem Tutorial verwenden Sie Azure Cosmos DB for PostgreSQL als Speicher-Back-End für mehrere Microservices und demonstrieren eine Beispieleinrichtung und den grundlegenden Vorgang eines solchen Clusters. In diesem Artikel werden folgende Themen erläutert:
- Erstellen eines Clusters
- Erstellen von Rollen für Ihre Microservices
- Verwenden des psql-Hilfsprogramms für das Erstellen von Rollen und verteilten Schemas
- Erstellen der Tabellen für die Beispieldienste
- Konfigurieren von -Diensten
- Ausführen der Dienste
- Untersuchen der Datenbank
GILT FÜR: ![]() Azure Cosmos DB for PostgreSQL (unterstützt von der Citus-Datenbankerweiterung auf PostgreSQL)
Azure Cosmos DB for PostgreSQL (unterstützt von der Citus-Datenbankerweiterung auf PostgreSQL)
Voraussetzungen
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Erstellen eines Clusters
Melden Sie sich beim Azure-Portal an, und führen Sie die folgenden Schritte aus, um einen Azure Cosmos DB for PostgreSQL-Cluster zu erstellen:
Rufen Sie im Azure-Portal Azure Cosmos DB for PostgreSQL-Cluster erstellen auf.
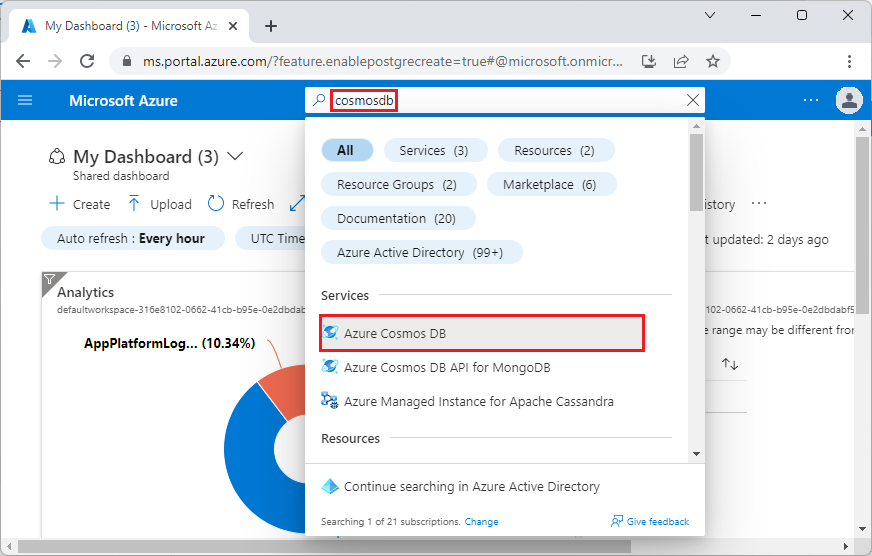
Gehen Sie im Formular Azure Cosmos DB for PostgreSQL-Cluster erstellen wie folgt vor:
Geben Sie die Informationen auf der Registerkarte Grundlagen ein.
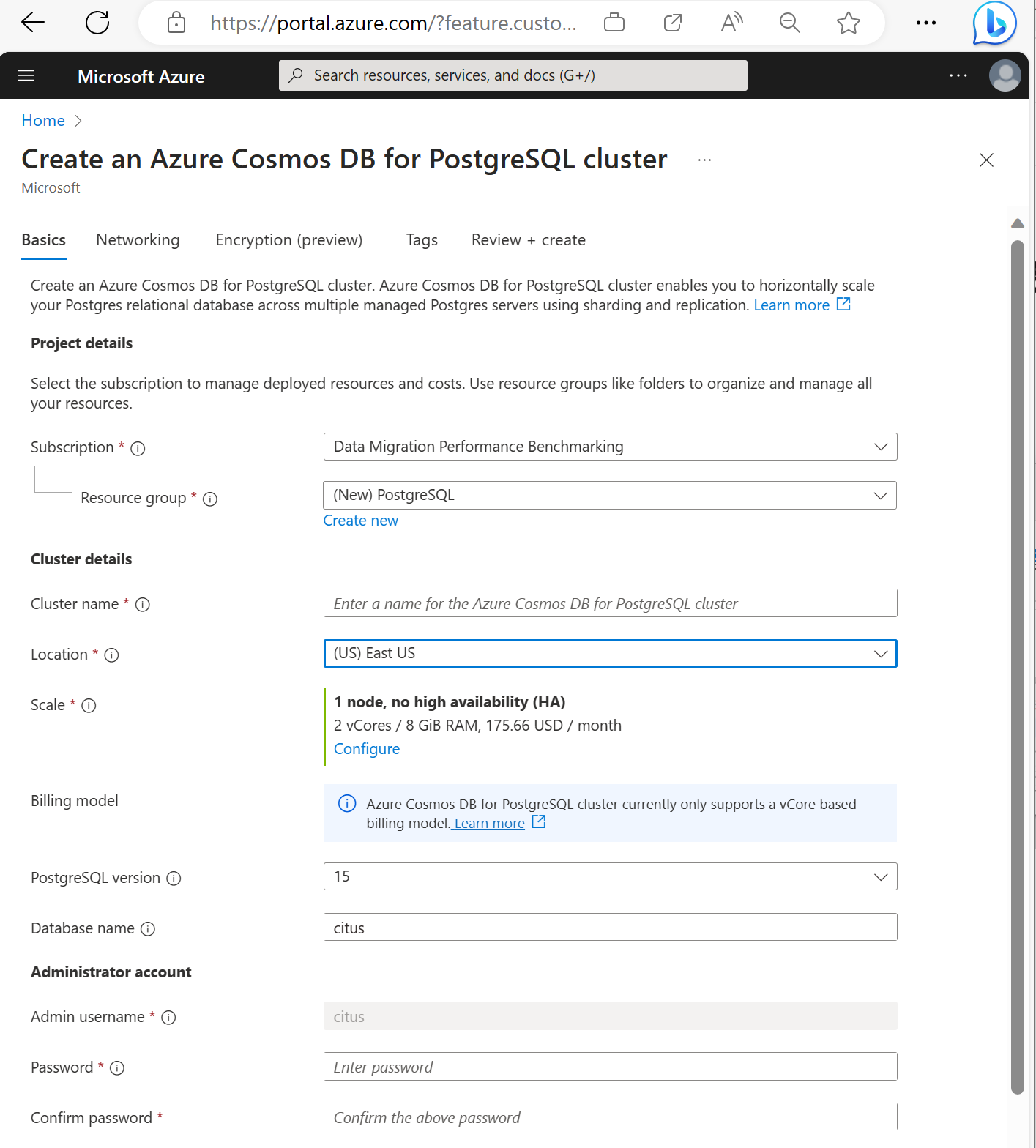
Die meisten Optionen sind selbsterklärend, denken Sie jedoch an Folgendes:
- Der Clustername bestimmt den DNS-Namen, den Ihre Anwendungen zum Herstellen einer Verbindung verwenden. Geben Sie den Namen im Format
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.coman. - Sie können eine höhere PostgreSQL-Version wie 15 auswählen. Azure Cosmos DB für PostgreSQL unterstützt immer die neueste Citus-Version für die ausgewählte Postgres-Hauptversion.
- Der Administratorbenutzername muss den Wert
citusaufweisen. - Sie können den Datenbanknamen auf dem Standardwert „citus“ belassen oder einen eigenen Datenbanknamen festlegen. Nach der Clusterbereitstellung können Sie den Namen der Datenbank nicht mehr ändern.
- Der Clustername bestimmt den DNS-Namen, den Ihre Anwendungen zum Herstellen einer Verbindung verwenden. Geben Sie den Namen im Format
Wählen Sie am unteren Rand des Bildschirms Weiter: Netzwerk aus.
Wählen Sie auf dem Bildschirm Netzwerk die Option Von Azure-Diensten und -Ressourcen in Azure aus öffentlichen Zugriff auf diesen Cluster gestatten aus.
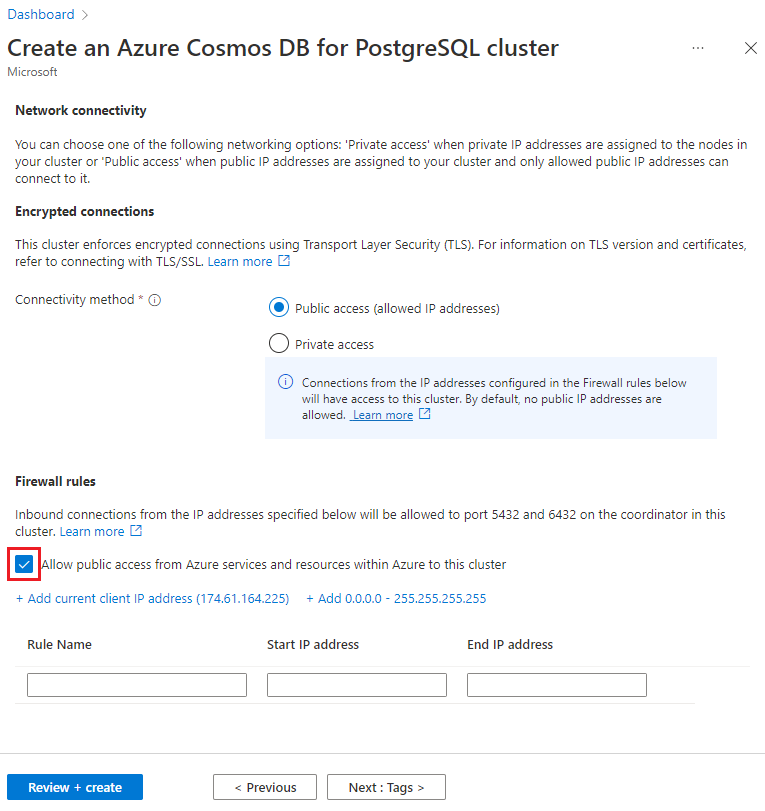
Wählen Sie Überprüfen und erstellen und nach bestandener Überprüfung Erstellen aus, um den Cluster zu erstellen.
Die Bereitstellung dauert einige Minuten. Die Seite leitet Sie zur Überwachung der Bereitstellung weiter. Wählen Sie Zu Ressource wechseln aus, wenn sich der Status von Bereitstellung wird ausgeführt in Ihre Bereitstellung wurde abgeschlossen. ändert.
Erstellen von Rollen für Ihre Microservices
Verteilte Schemas sind innerhalb eines Azure Cosmos DB for PostgreSQL-Clusters verschiebbar. Das System kann sie als ganze Einheit über die verfügbaren Knoten hinweg neu ausgleichen, sodass Ressourcen ohne manuelle Zuteilung effizient freigegeben werden können.
Microservices besitzen ihre eigene Speicherebene. Wir machen keine Annahmen über die Art der Tabellen und Daten, die sie erstellen und speichern. Wir stellen ein Schema für jeden Dienst bereit und nehmen an, dass sie eine eindeutige ROLLE verwenden, um eine Verbindung mit der Datenbank herzustellen. Wenn ein Benutzer eine Verbindung herstellt, wird sein Rollenname am Anfang des „search_path“ platziert. Wenn die Rolle also mit dem Schemanamen übereinstimmt, müssen Sie keine Anwendungsänderungen vornehmen, um den richtigen „search_path“ festzulegen.
Wir verwenden drei Dienste in unserem Beispiel:
- user
- time
- ping
Führen Sie die Schritte für das Erstellen von Benutzerrollen aus und erstellen Sie die folgenden Rollen für jeden Dienst:
userservicetimeservicepingservice
Verwenden des psql-Hilfsprogramms für das Erstellen von verteilten Schemas
Nachdem Sie mithilfe von psql eine Verbindung mit Azure Cosmos DB for PostgreSQL hergestellt haben, können Sie einige einfache Aufgaben ausführen.
Es gibt zwei Möglichkeiten, wie ein Schema in Azure Cosmos DB for PostgreSQL verteilt werden kann:
Manuell durch citus_schema_distribute(schema_name) Funktionsaufruf:
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
SELECT citus_schema_distribute('userservice');
SELECT citus_schema_distribute('timeservice');
SELECT citus_schema_distribute('pingservice');
Mit dieser Methode können Sie auch vorhandene reguläre Schemas in verteilte Schemas konvertieren.
Hinweis
Sie können nur Schemas verteilen, die keine Verweistabellen oder verteilte Tabellen enthalten.
Ein alternativer Ansatz besteht darin, die Konfigurationsvariable „citus.enable_schema_based_sharding“ zu aktivieren:
SET citus.enable_schema_based_sharding TO ON;
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
Die Variable kann für die aktuelle Sitzung oder dauerhaft in den Parametern für Koordinatorknoten geändert werden. Wenn der Parameter auf EIN festgelegt ist, werden alle erstellten Schemas standardmäßig verteilt.
Sie können die derzeit verteilten Schemas auflisten, indem Sie Folgendes ausführen:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 5 | 0 bytes | userservice
timeservice | 6 | 0 bytes | timeservice
pingservice | 7 | 0 bytes | pingservice
(3 rows)
Erstellen der Tabellen für die Beispieldienste
Sie müssen jetzt für jeden Microservice eine Verbindung mit der Azure Cosmos DB for PostgreSQL herstellen. Sie können den Befehl \c verwenden, um den Benutzer innerhalb einer vorhandenen psql-Instanz zu tauschen.
\c citus userservice
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL
);
\c citus timeservice
CREATE TABLE query_details (
id SERIAL PRIMARY KEY,
ip_address INET NOT NULL,
query_time TIMESTAMP NOT NULL
);
\c citus pingservice
CREATE TABLE ping_results (
id SERIAL PRIMARY KEY,
host VARCHAR(255) NOT NULL,
result TEXT NOT NULL
);
Konfigurieren von -Diensten
In diesem Tutorial verwenden wir eine einfache Reihe von Diensten. Sie können diese abrufen, indem Sie dieses öffentliche Repository klonen:
git clone https://github.com/citusdata/citus-example-microservices.git
$ tree
.
├── LICENSE
├── README.md
├── ping
│ ├── app.py
│ ├── ping.sql
│ └── requirements.txt
├── time
│ ├── app.py
│ ├── requirements.txt
│ └── time.sql
└── user
├── app.py
├── requirements.txt
└── user.sql
Bevor Sie jedoch die Dienste ausführen, bearbeiten Sie user/app.py, ping/app.py und time/app.py Dateien, die die Verbindungskonfiguration für Ihren Azure Cosmos DB for PostgreSQL-Cluster bereitstellen:
# Database configuration
db_config = {
'host': 'c-EXAMPLE.EXAMPLE.postgres.cosmos.azure.com',
'database': 'citus',
'password': 'SECRET',
'user': 'pingservice',
'port': 5432
}
Nachdem Sie die Änderungen vorgenommen haben, speichern Sie alle geänderten Dateien und fahren Sie mit dem Ausführen der Dienste fort.
Ausführen der Dienste
Wechseln Sie in jedes App-Verzeichnis und führen Sie sie in ihrer eigenen Python-Umg. aus.
cd user
pipenv install
pipenv shell
python app.py
Wiederholen Sie die Befehle für den Zeit- und Ping-Dienst. Anschließend können Sie die API verwenden.
Erstellen von einigen Benutzern:
curl -X POST -H "Content-Type: application/json" -d '[
{"name": "John Doe", "email": "john@example.com"},
{"name": "Jane Smith", "email": "jane@example.com"},
{"name": "Mike Johnson", "email": "mike@example.com"},
{"name": "Emily Davis", "email": "emily@example.com"},
{"name": "David Wilson", "email": "david@example.com"},
{"name": "Sarah Thompson", "email": "sarah@example.com"},
{"name": "Alex Miller", "email": "alex@example.com"},
{"name": "Olivia Anderson", "email": "olivia@example.com"},
{"name": "Daniel Martin", "email": "daniel@example.com"},
{"name": "Sophia White", "email": "sophia@example.com"}
]' http://localhost:5000/users
Auflisten der erstellten Benutzer:
curl http://localhost:5000/users
Abrufen der aktuellen Zeit:
Get current time:
Ausführen des Pings für example.com:
curl -X POST -H "Content-Type: application/json" -d '{"host": "example.com"}' http://localhost:5002/ping
Untersuchen der Datenbank
Nachdem Sie nun einige API-Funktionen aufgerufen haben, wurden Daten gespeichert und Sie können überprüfen, ob citus_schemas das Erwartete wiedergibt:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 1 | 112 kB | userservice
timeservice | 2 | 32 kB | timeservice
pingservice | 3 | 32 kB | pingservice
(3 rows)
Als Sie die Schemas erstellt haben, haben Sie Azure Cosmos DB for PostgreSQL nicht mitgeteilt, auf welchen Computern die Schemas erstellt werden sollen. Dies ist automatisch erfolgt. Mit der folgenden Abfrage können Sie sehen, wo sich jedes Schema befindet:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9702 | userservice.users | 112 kB
localhost | 9702 | pingservice.ping_results | 32 kB
Aus Platzgründen der Beispielausgabe auf dieser Seite ersetzen wir nodename, wie in Azure Cosmos DB for PostgreSQL angezeigt, durch localhost. Angenommen, localhost:9701 ist Worker 1 und localhost:9702 ist Worker 2. Knotennamen im verwalteten Dienst sind länger und enthalten zufällige Elemente.
Sie können sehen, dass der Zeit-Dienst auf Knoten localhost:9701 gelandet ist, während der Benutzer- und der Ping-Dienst Speicherplatz auf dem zweiten Worker localhost:9702 teilen. Die Beispiel-Apps sind vereinfacht, und die Datengrößen können ignoriert werden, aber nehmen wir an, dass Sie von der ungleichen Speicherplatznutzung zwischen den Knoten genervt sind. Es wäre sinnvoller, wenn sich die beiden kleineren Zeit- und Ping-Dienste auf einem Computer befinden, während sich der große Benutzer-Dienst alleine auf einem Computer befindet.
Sie können den Cluster ganz einfach anhand der Datenträgergröße neu ausgleichen:
select citus_rebalance_start();
NOTICE: Scheduled 1 moves as job 1
DETAIL: Rebalance scheduled as background job
HINT: To monitor progress, run: SELECT * FROM citus_rebalance_status();
citus_rebalance_start
-----------------------
1
(1 row)
Wenn Sie fertig sind, können Sie überprüfen, wie unser neues Layout aussieht:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9701 | pingservice.ping_results | 32 kB
localhost | 9702 | userservice.users | 112 kB
(3 rows)
Erwartungen zufolge wurden die Schemas verschoben und wir haben einen ausgeglicheneren Cluster. Dieser Vorgang ist für die Anwendungen transparent. Sie müssen sie nicht einmal neu starten, sie stellen weiterhin Abfragen bereit.
Nächste Schritte
In diesem Tutorial haben Sie gelernt, wie Sie verteilte Schemas erstellen und Microservices ausführen, die diese als Speicher nutzen. Außerdem haben Sie gelernt, wie Sie einen schemabasierten Azure Cosmos DB for PostgreSQL mit Shards erkunden und verwalten.
- Weitere Informationen zu Clusterknotentypen