Soziale Medien mit Azure Cosmos DB
GILT FÜR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabelle
Tabelle
Da Sie in einer hochgradig vernetzten Welt leben, werden Sie irgendwann Teil sozialer Netzwerke. Sie verwenden diese Netzwerke, um mit Freunden, Kollegen und der Familie in Kontakt zu bleiben oder auch, um das, was Sie bewegt, mit Menschen mit den gleichen Interessen zu teilen.
Als Techniker oder Entwickler fragen Sie sich vielleicht, wie Ihre Daten für diese Netzwerke gespeichert und verknüpft werden. Es kann auch sein, dass Sie mit dem Erstellen oder Entwerfen eines neuen sozialen Netzwerks für einen bestimmten Nischenmarkt beauftragt wurden. Spätestens dann stellt sich die entscheidende Frage: Wie werden all diese Daten gespeichert?
Angenommen, Sie erschaffen ein nagelneues soziales Netzwerk, in dem die Benutzer Artikel mit den dazugehörigen Medien wie Bildern, Videos oder sogar Musik posten können. Die Benutzer sollen Beiträge darüber hinaus kommentieren und durch Punktvergabe bewerten können. Über einen Feed auf der Hauptseite sollen Benutzer Beiträge lesen und damit interagieren. Diese Methode klingt erst einmal nicht komplex, aber um die Einfachheit zu wahren, stoppen wir hier. (Sie können sich weiter über benutzerdefinierte Benutzerfeeds und die Beeinflussung durch Beziehungen informieren, aber dieses Thema würde den Rahmen dieses Artikels sprengen.)
Wie und wo speichern Sie diese Daten also?
Unter Umständen verfügen Sie über Erfahrung mit SQL-Datenbanken oder kennen sich mit der relationalen Modellierung von Daten aus. Beispielsweise können Sie damit beginnen, etwas wie folgt aufzuzeichnen:
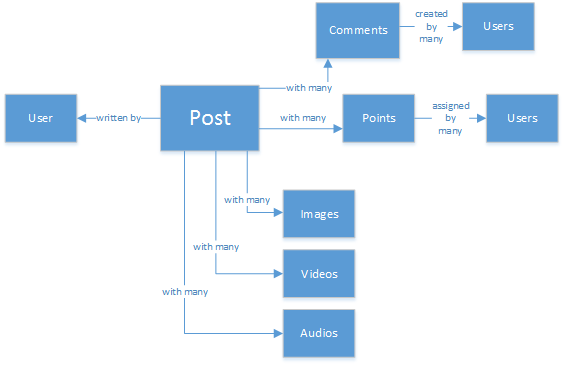
Eine vollständig normalisierte und ordentliche Datenstruktur – die nicht skaliert werden kann.
Verstehen Sie mich nicht falsch: Ich habe schon immer mit SQL-Datenbanken gearbeitet. Diese Datenbanken haben viele Vorteile, aber wie bei jedem Muster, jeder Vorgehensweise und jeder Softwareplattform gilt, dass sie nicht für jedes Szenario perfekt geeignet sind.
Warum ist SQL in diesem Szenario nicht die beste Option? Lassen Sie uns einen Blick auf die Struktur eines einzelnen Beitrags werfen. Wenn ich den Beitrag auf einer Website oder in einer Anwendung anzeigen möchte, muss ich eine Abfrage durchführen – indem ich acht Tabellen (!) verknüpfe, um einen einzigen Beitrag anzuzeigen. Wenn Sie sich jetzt einen Datenstrom mit Beiträgen vorstellen, die dynamisch geladen und auf dem Bildschirm angezeigt werden, ahnen Sie, worauf ich hinauswill.
Sie können eine riesige SQL-Instanz mit ausreichender Leistung einsetzen, um Tausende von Abfragen mit vielen Verknüpfungen (Joins) zum Bereitstellen Ihrer Inhalte zu verwenden. Aber warum sollten Sie dies tun, wenn es eine einfachere Lösung gibt?
Der Weg mit NoSQL
In diesem Artikel wird beschrieben, wie Sie die Daten Ihrer sozialen Plattform mit der NoSQL-Datenbank Azure Cosmos DB von Azure kostengünstig modellieren. Darüber hinaus erfahren Sie, wie Sie andere Azure Cosmos DB-Features nutzen, z. B. die API für Gremlin. Mithilfe eines NoSQL-Ansatzes, der Datenspeicherung im JSON-Format und der Denormalisierung kann der zuvor komplizierte Beitrag in ein einziges Dokument transformiert werden:
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
Und dies erfolgt mit einer einzigen Abfrage und keinerlei Joins. Diese Abfrage ist sehr viel unkomplizierter und erfordert auch von Budgetseite weniger Ressourcen, um ein besseres Ergebnis zu erzielen.
Mit Azure Cosmos DB wird sichergestellt, dass alle Eigenschaften mit der automatischen Indizierung indiziert werden. Die automatische Indizierung kann sogar angepasst werden. Beim schemalosen Ansatz können wir Dokumente mit unterschiedlichen und dynamischen Strukturen speichern. Es kann beispielsweise sein, dass Sie morgen schon erreichen möchten, dass Beiträgen eine Liste mit Kategorien oder Hashtags zugeordnet ist. Azure Cosmos DB verarbeitet die neuen Dokumente mit den hinzugefügten Attributen, ohne dass für uns zusätzlicher Aufwand anfällt.
Kommentare zu einem Beitrag können als weitere Beiträge mit einer übergeordneten Eigenschaft behandelt werden. (Mit dieser Vorgehensweise wird Ihre Objektzuordnung vereinfacht.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
Des Weiteren können alle sozialen Interaktionen in einem separaten Objekt als Zähler gespeichert werden:
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
Die Erstellung von Feeds ist nunmehr lediglich eine Frage der Erstellung von Dokumenten, die eine Liste mit Beitrags-IDs mit einer bestimmten Relevanzreihenfolge aufnehmen können:
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
Sie können einen Datenstrom „Aktuell“ mit den Beiträgen verwenden, die nach dem Erstellungsdatum sortiert sind. Oder Sie können den Datenstrom „Am beliebtesten“ mit den Beiträgen verwenden, die in den letzten 24 Stunden die meisten „Gefällt mir“-Markierungen erhalten haben. Sie können sogar für jeden Benutzer basierend auf einer Logik, z.B. Follower und Interessen, einen benutzerdefinierten Datenstrom implementieren. Es handelt sich dabei dann immer noch um eine Liste mit Beiträgen. Relevant ist an dieser Stelle, wie diese Listen erstellt werden. Die Leseleistung bleibt davon unberührt. Sobald Sie eine dieser Listen erhalten, schicken Sie mit dem IN-Schlüsselwort eine einzelne Abfrage an Azure Cosmos DB, um Seiten mit Beiträgen gleichzeitig abzurufen.
Die Feeddatenströme könnten mithilfe von Azure App Services-Hintergrundprozessen erstellt werden: WebJobs. Nach der Erstellung eines Beitrags kann die Hintergrundverarbeitung mit Azure Storage-Warteschlangen und WebJobs mithilfe des Azure WebJobs-SDK ausgelöst werden. Diese Funktionen implementieren die Verteilung der Beiträge innerhalb der Streams, basierend auf Ihrer eigenen benutzerdefinierten Logik.
Punkte und Likes zu einem Beitrag können mithilfe dieser Technik verzögert verarbeitet werden, um eine letztendlich konsistente Umgebung zu erstellen.
Follower sind komplizierter. Azure Cosmos DB verfügt über eine Beschränkung für die Dokumentgröße. Zudem kann das Lesen und Schreiben umfangreicher Dokumente die Skalierbarkeit Ihrer Anwendung beeinträchtigen. Daher sollten Sie gegebenenfalls erwägen, Follower als Dokument mit dieser Struktur zu speichern:
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Diese Struktur funktioniert ggf. für einen Benutzer mit einigen Tausend Followern. Bei Prominenten führt dieser Ansatz aber zu großen Dokumenten, und es kann sein, dass früher oder später der Grenzwert erreicht wird.
Um dieses Problem zu lösen, können Sie einen kombinierten Ansatz wählen. Die Anzahl der Follower können Sie als Teil des Dokuments mit der Benutzerstatistik speichern:
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
Sie können den eigentlichen Graph mit den Followern mithilfe der API für Gremlin von Azure Cosmos DB speichern, um Scheitelpunkte für jeden Benutzer und Kanten zu erstellen, die „A-folgt-B“-Beziehungen verwalten. Mit der API für Gremlin können Sie die Follower eines bestimmten Benutzers abrufen und komplexere Abfragen erstellen, um passende Personen vorzuschlagen. Wenn Sie dem Graph die bei Benutzern beliebten Inhaltskategorien hinzufügen, können Sie weitere Funktionen einbinden, z.B. die intelligente Inhaltsermittlung, das Vorschlagen der beliebten Inhalte von Personen, denen Sie folgen, oder das Suchen von Personen, mit denen Sie viele Gemeinsamkeiten aufweisen.
Das Dokument „User Statistics“ kann weiterhin zum Erstellen von Karten auf der Benutzeroberfläche oder für schnelle Profilvorschauen verwendet werden.
Das „Leiter-Muster“ und Datenduplizierung
Wie Sie vielleicht bemerkt haben, kommt ein Benutzer in dem JSON-Dokument, das auf einen Beitrag verweist, häufig vor. Natürlich haben Sie mit der Annahme recht, dass diese Duplikate Folgendes bedeuten: Informationen zu einem Benutzer können aufgrund der Denormalisierung an mehr als einem Ort vorhanden sein.
Um schnellere Abfragen zu ermöglichen, verursachen Sie also eine Datenduplizierung. Das Problem dieses Nebeneffekts besteht darin, dass eine Änderung der Benutzerdaten das Auffinden aller Aktivitäten, die dieser Benutzer je ausgeführt hat, und ihre Aktualisierung notwendig macht. Das klingt nicht sehr praktisch, nicht wahr?
Sie werden das Problem lösen, indem Sie die Schlüsselattribute eines Benutzers identifizieren, die Sie in Ihrer Anwendung für jede Aktivität anzeigen. Wenn bei der visuellen Darstellung eines Beitrags in Ihrer Anwendung nur der Name und das Bild des Erstellers angezeigt werden, warum sollten Sie dann alle Daten des Benutzers im „createdBy“-Attribut speichern? Wenn bei jedem Kommentar allein das Bild des Benutzers angezeigt wird, benötigen Sie die restlichen Benutzerinformationen eigentlich nicht. Hier kommt das so genannte „Leiter-Muster“ ins Spiel.
Nehmen wir die Benutzerinformationen als Beispiel:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
Anhand dieser Informationen können Sie schnell erkennen, welche Informationen wichtig sind und welche nicht. Dadurch können wir sie „leiterhaft“ hierarchisieren:

Die oberste Ebene ist der sogenannte UserChunk, die minimale Information, die einen Benutzer identifiziert und die für die Datenduplizierung verwendet wird. Durch die Reduzierung der doppelt vorhandenen Daten auf ausschließlich jene Informationen, die Sie auch „anzeigen“, minimieren Sie die Gefahr sehr umfangreicher Aktualisierungen.
Der mittlere Schritt verfügt über die Bezeichnung „Benutzer“. Hierbei handelt es sich um die gesamten Daten, die für die meisten leistungsabhängigen Abfragen an Azure Cosmos DB verwendet werden: die wichtigsten Daten also, auf die am häufigsten zugegriffen wird. Diese Informationen enthalten auch den UserChunk.
Die umfangreichste Ebene ist der „Erweiterte Benutzer“. Sie enthält auch die wichtigen Benutzerinformationen und andere Daten, die nicht schnell gelesen werden müssen oder erst später verwendet werden, z.B. beim Anmeldevorgang. Diese Daten können außerhalb von Azure Cosmos DB, in Azure SQL-Datenbank oder Azure Storage-Tabellen gespeichert werden.
Warum empfiehlt es sich, die Benutzerinformationen aufzuteilen und sogar an verschiedenen Orten zu speichern? Weil die Abfragen von der Leistungsseite aus betrachtet immer kostenaufwendiger werden, je größer die Dokumente sind. Halten Sie den Umfang von Dokumenten gering, und sorgen Sie dafür, dass diese die richtigen Informationen enthalten, mit denen Sie alle leistungsabhängigen Abfragen für Ihr soziales Netzwerk durchführen können. Speichern Sie die zusätzlichen Informationen für die nachfolgenden Szenarien, z.B. vollständige Profilbearbeitungen, Anmeldungen und Data Mining für die Nutzungsanalyse und Big Data-Initiativen. Ihnen kann es egal sein, ob die Datenerfassung für das Data Mining langsamer verläuft, weil die Ausführung unter Azure SQL-Datenbank erfolgt. Aber es ist Ihnen wichtig, dass Ihre Benutzer über eine schnelle und schlanke Benutzeroberfläche verfügen. Ein in Azure Cosmos DB gespeicherter Benutzer würde im Code wie folgt aussehen:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
Und ein Beitrag würde wie folgt aussehen:
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
Wenn eine Bearbeitung ansteht, bei der ein Blockattribut betroffen ist, können Sie die entsprechenden Dokumente leicht finden. Verwenden Sie einfach Abfragen, die auf die indizierten Attribute verweisen, z.B. SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id", und aktualisieren Sie anschließend die Blöcke.
Das Suchfeld
Benutzer generieren (glücklicherweise) viel Inhalt. Sie sollten daher auch in der Lage sein, Inhalte zu suchen, die nicht direkt in ihrem Stream erscheinen, da Sie vielleicht dem jeweiligen Ersteller nicht folgen oder einen eigenen, sechs Monate alten Beitrag suchen.
Da Sie Azure Cosmos DB nutzen, können Sie ein Suchmodul mit Azure KI Search leicht in wenigen Minuten implementieren, ohne Code eingeben zu müssen (bis auf den Suchprozess und die Benutzeroberfläche).
Warum ist dieser Prozess so einfach?
Azure KI Search implementiert sogenannte Indexer. Das sind Hintergrundprozesse, die sich in Ihre Datenrepositorys einklinken und Ihre Objekte automatisch den Indizes hinzufügen, sie aktualisieren oder daraus entfernen. Unterstützt werden Azure SQL-Datenbank-Indexer, Azure-Blobindexer und auch Azure Cosmos DB-Indexer. Die Übergabe von Informationen von Azure Cosmos DB an Azure KI Search ist einfach. Bei beiden Technologien werden Informationen im JSON-Format gespeichert, sodass Sie nur Ihren Index erstellen und die Attribute aus Ihren Dokumenten zuordnen müssen, die indiziert werden sollen. Fertig! Ihr gesamter Inhalt ist verfügbar, um innerhalb weniger Minuten (je nach Umfang Ihrer Daten) mit der besten Search-as-a-Service-Lösung der Cloudinfrastruktur durchsucht zu werden.
Weitere Informationen zu Azure KI Search finden Sie im Hitchhiker’s Guide to Search(Per Anhalter durch Search).
Die verborgenen Informationen
Nachdem all diese täglich wachsenden Inhalte gespeichert wurden, stellen Sie sich womöglich die Frage: Wie kann ich den Informationsstrom meiner Benutzer verwenden?
Die Antwort ist einfach: Nutzen Sie ihn, und lernen Sie aus daraus.
Aber was können Sie lernen? Einige einfache Beispiele sind die Stimmungsanalyse, die Empfehlung von Inhalten auf Grundlage der Interessen eines Benutzers oder sogar ein automatischer Inhaltsmoderator, der sicherstellt, dass alle in Ihrem sozialen Netzwerk veröffentlichten Inhalte für Familien geeignet sind.
Nun, da ich Ihr Interesse geweckt habe, glauben Sie wahrscheinlich, dass Sie eine Promotion in Mathematik benötigen, um einfachen Datenbanken und Dateien diese Muster und Informationen zu entlocken. Aber da liegen Sie falsch.
Azure Machine Learning ist ein vollständig verwalteter Clouddienst, mit dem Sie Workflows mithilfe von Algorithmen in einer einfachen Drag & Drop-Schnittstelle erstellen, Ihre eigenen Algorithmen in R programmieren oder einige der bereits erstellten und einsatzbereiten APIs verwenden können (z. B. Textanalyse, Content Moderator oder Empfehlungen).
Für die Umsetzung dieser Machine Learning-Szenarien können Sie Azure Data Lake nutzen, um die Informationen aus unterschiedlichen Quellen zu erfassen. Sie können auch U-SQL verwenden, um die Informationen zu verarbeiten und eine Ausgabe zu generieren, die mit Azure Machine Learning verarbeitet werden kann.
Eine andere Option ist die Verwendung von Azure KI Services zum Analysieren der Benutzerinhalte. So können Sie diese nicht nur besser verstehen (durch die Analyse der Benutzertexte mit der Textanalyse-API), sondern auch unerwünschte oder nicht jugendfreie Inhalte erkennen und mithilfe der Maschinelles Sehen-API entsprechende Maßnahmen ergreifen. Azure KI Services bietet viele Standardlösungen, für deren Nutzung keinerlei Machine Learning-Kenntnisse erforderlich sind.
Eine soziale Erfahrung im globalen Maßstab
Es gibt ein letztes, aber wichtiges Thema, das angesprochen werden muss : Skalierbarkeit. Beim Entwerfen einer Architektur sollte jede Komponente separat skaliert werden. Letztendlich müssen Sie mehr Daten verarbeiten, oder Sie benötigen eine größere geografische Abdeckung. Glücklicherweise ist die Erreichung beider Aufgaben mit Azure Cosmos DB so einfach wie der schlüsselfertige Bezug eines Hauses.
Azure Cosmos DB unterstützt standardmäßig die dynamische Partitionierung. Partitionen werden automatisch basierend auf einem bestimmten Partitionsschlüssel erstellt, der in Ihren Dokumenten als Attribut definiert ist. Das Definieren des richtigen Partitionsschlüssels muss zur Entwurfszeit durchgeführt werden. Weitere Informationen finden Sie unter Partitionierung in Azure Cosmos DB.
Im Fall von sozialen Anwendungen muss Ihre Partitionierungsstrategie an der Art Ihrer Abfragen und Schreibvorgänge ausgerichtet sein. (Beispielsweise sollten Lesevorgänge möglichst innerhalb der gleichen Partition erfolgen und „Hotspots“ durch das Verteilen von Schreibvorgängen auf mehrere Partitionen vermieden werden.) Beispiele für Optionen sind: Auf einem temporalen Schlüssel (Tag/Monat/Woche) basierende Partitionen, nach Inhaltskategorie, nach geografischer Region oder nach Benutzer. Alles hängt davon ab, wie Sie die Daten abfragen und in Ihrer sozialen Anwendung anzeigen.
Azure Cosmos DB führt Ihre Abfragen (einschließlich Aggregaten) transparent über Ihre gesamten Partitionen aus, sodass Sie bei wachsendem Datenbestand keinerlei Logik hinzufügen müssen.
Im Laufe der Zeit werden der Datenverkehr und der Ressourcenverbrauch (in Anforderungseinheiten (Request Units, RUs) gemessen) zunehmen. Sie werden mehr Lese- und Schreibvorgänge durchführen, wenn Ihre Benutzerbasis an Größe zunimmt. Die Benutzerbasis erstellt und liest mehr Inhalte. Daher ist es von entscheidender Bedeutung, dass Sie den Durchsatz skalieren können. Die Erhöhung Ihrer RUs ist einfach. Sie müssen lediglich einige Klicks im Azure-Portal oder Befehle über die API ausführen.
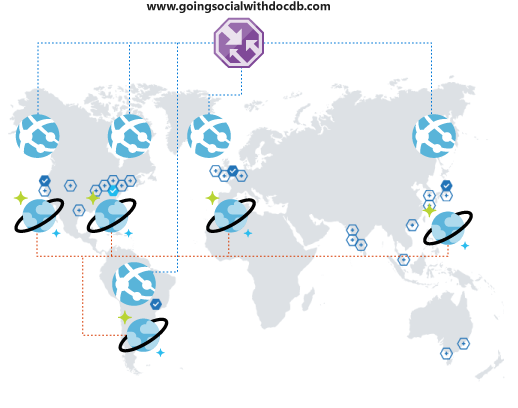
Was passiert, wenn sich Erfolg einstellt? Angenommen, Benutzer aus anderen Regionen, Ländern oder Kontinenten entdecken Ihre Plattform und beginnen, sie zu nutzen. Was für eine schöne Überraschung!
Aber halt! Sie merken schnell, dass die Benutzerfreundlichkeit Ihrer Plattform nicht optimal ist. Die Benutzer sind so weit von Ihrer Betriebsregion entfernt, dass die Latenz viel zu hoch ist. Sie möchten natürlich nicht, dass die Benutzer sich abwenden. Wenn es doch nur eine einfache Möglichkeit zum Erweitern Ihrer globalen Reichweite gäbe. Es gibt sie!
Mithilfe von Azure Cosmos DB können Sie Ihre Daten global replizieren, das auch noch transparent und mit nur ein paar Mausklicks; und die Auswahl der verfügbaren Regionen erfolgt automatisch anhand des Clientcodes. Dieser Prozess bedeutet zugleich, dass Sie mit mehreren Failoverregionen arbeiten können.
Wenn Sie Ihre Daten global replizieren, müssen Sie zugleich sicherstellen, dass dies allen Ihren Kunden zugute kommt. Wenn Sie ein Web-Front-End verwenden oder von mobilen Clients aus auf APIs zugreifen, können Sie Azure Traffic Manager bereitstellen und Ihre Azure App Service-Instanz in allen gewünschten Regionen klonen. Verwenden Sie eine Leistungskonfiguration zur Unterstützung Ihrer erweiterten globalen Abdeckung. Wenn Ihre Clients auf Ihr Front-End oder Ihre APIs zugreifen, werden sie zum nächstgelegenen App Service weitergeleitet, der seinerseits eine Verbindung mit dem lokalen Azure Cosmos DB-Replikat herstellt.
Zusammenfassung
In diesem Artikel wurden die Alternativen vorgestellt, die Ihnen in Bezug auf die Erstellung von sozialen Netzwerken ausschließlich in Azure mit kostengünstigen Diensten zur Verfügung stehen. Die Ergebnisse werden erreicht, indem eine Speicherlösung mit mehreren Ebenen und eine Datenverteilung nach dem „Leiterprinzip“ genutzt werden.
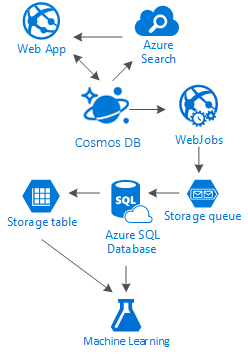
In Wahrheit gibt es keine Patentlösung für diese Art von Szenarien. Vielmehr sind es die Synergieeffekte aus einer Kombination hervorragender Dienste, die zu einem großartigen Nutzererlebnis verhelfen: die Geschwindigkeit und die Freiheit von Azure Cosmos DB, die eine hervorragende soziale Anwendung ermöglichen, die Intelligenz hinter einer erstklassigen Suchlösung wie Azure KI Search und die Flexibilität von Azure App Services, nicht nur sprachunabhängige Anwendungen zu hosten, sondern sogar leistungsfähige Hintergrundprozesse. Dazu kommen erweiterbarer Azure Storage, die Azure SQL-Datenbank zum Speichern riesiger Datenmengen und die analytische Leistungsfähigkeit von Azure Machine Learning zur Gewinnung von Wissen und Intelligenz, was als Feedback für Ihre Prozesse dienen und helfen kann, den richtigen Benutzern die richtigen Inhalte zur Verfügung zu stellen.
Nächste Schritte
Weitere Informationen zu den Anwendungsfällen für Azure Cosmos DB finden Sie unter Häufige Azure Cosmos DB-Anwendungsfälle.