Übersicht über Business Continuity & Disaster Recovery
Business Continuity & Disaster Recovery in Azure Data Explorer ermöglicht es Ihrem Unternehmen, den Geschäftsbetrieb im Falle einer Störung aufrechtzuerhalten. Dieser Artikel beschäftigt sich mit der Verfügbarkeit (innerhalb der Region) und der Notfallwiederherstellung. Er enthält Informationen zu nativen Funktionen und sowie zu Architekturaspekten für eine robuste Azure Data Explorer-Bereitstellung. Des Weiteren finden Sie hier Informationen zur Wiederherstellung nach menschlichen Fehlern, zu Hochverfügbarkeit und zu verschiedenen Notfallwiederherstellungskonfigurationen. Diese Konfigurationen sind abhängig von Resilienzanforderungen wie Recovery Point Objective (RPO) und Recovery Time Objective (RTO) sowie vom Aufwand und den Kosten.
Behandeln von Störereignissen
- Menschlicher Fehler
- Hochverfügbarkeit von Azure Data Explorer
- Ausfall einer Azure-Verfügbarkeitszone
- Ausfall eines Azure-Rechenzentrums
- Ausfall einer Azure-Region
Menschlicher Fehler
Menschliche Fehler sind unvermeidlich. Benutzer können versehentlich einen Cluster, eine Datenbank oder eine Tabelle löschen.
Versehentliches Löschen eines Clusters oder einer Datenbank
Versehentlich gelöschte Cluster oder Datenbanken können nicht wiederhergestellt werden. Als Azure Data Explorer-Ressourcenbesitzer können Sie Datenverluste verhindern, indem Sie die auf der Azure-Ressourcenebene zur Verfügung stehende Sperrfunktion für Löschvorgänge aktivieren.
Versehentliches Löschen einer Tabelle
Benutzer, die mindestens über Tabellenadministratorberechtigungen verfügen, können Tabellen löschen. Sollte einer dieser Benutzer versehentlich eine Tabelle löschen, können Sie sie mithilfe des Befehls .undo drop table wiederherstellen. Dieser Befehl funktioniert allerdings nur, wenn zuvor die Wiederherstellbarkeitseigenschaft (Recoverability) in der Aufbewahrungsrichtlinie aktiviert wurde.
Versehentliches Löschen einer externen Tabelle
Externe Tabellen sind Entitäten des Kusto-Abfrageschemas, die auf Daten verweisen, die außerhalb der Datenbank gespeichert sind. Beim Löschen einer externen Tabelle werden lediglich die Tabellenmetadaten gelöscht. Sie können durch erneutes Ausführen des Tabellenerstellungsbefehls wiederhergestellt werden. Verwenden Sie die Funktion Vorläufiges Löschen, um sich vor dem versehentlichen Löschen oder Überschreiben einer Datei/eines Blobs zu schützen. Der Zeitraum kann dabei vom Benutzer konfiguriert werden.
Hochverfügbarkeit von Azure Data Explorer
Hochverfügbarkeit bezieht sich auf die Fehlertoleranz von Azure Data Explorer, der zugehörigen Komponenten und der zugrunde liegenden Abhängigkeiten innerhalb einer Azure-Region. Diese Fehlertoleranz vermeidet Single Points of Failure (SPOFs) in der Implementierung. In Azure Data Explorer umfasst Hochverfügbarkeit die Persistenzebene, die Computeebene und eine Leader-Follower-Konfiguration.
Persistenzebene
Azure Data Explorer nutzt Azure Storage als permanente Persistenzebene. Azure Storage sorgt automatisch für Fehlertoleranz und bietet in der Standardeinstellung lokal redundanten Speicher (LRS) in einem Rechenzentrum. Drei Replikate werden persistent gespeichert. Sollte ein Replikat während der Verwendung verloren gehen, wird ohne Unterbrechung ein weiteres bereitgestellt. Noch mehr Resilienz lässt sich mit zonenredundantem Speicher (ZRS) erreichen. Hierbei werden Replikate intelligent auf verschiedene regionale Azure-Verfügbarkeitszonen verteilt, um die Fehlertoleranz zu maximieren. Dies ist allerdings mit zusätzlichen Kosten verbunden. ZRS wird automatisch konfiguriert, wenn der Azure Data Explorer-Cluster in Verfügbarkeitszonen bereitgestellt wird.
Computeebene
Bei Azure Data Explorer handelt es sich um eine Plattform für verteiltes Computing, die je nach Skalierung und Knotenrollentyp über zwei oder mehr Knoten verfügen kann. Wählen Sie zur Bereitstellungszeit Verfügbarkeitszonen aus, um die Knotenbereitstellung über mehrere Zonen zu verteilen und so eine möglichst hohe Resilienz innerhalb der Region zu erreichen. Der Ausfall einer Verfügbarkeitszone hat keinen vollständigen Ausfall zur Folge. Stattdessen verschlechtert sich lediglich die Leistung, bis die Zone wiederhergestellt wurde.
Leader-Follower-Clusterkonfiguration
Azure Data Explorer bietet eine optionale Follower-Funktion. Dadurch können Follower-Cluster einem Leader-Cluster folgen, um schreibgeschützten Zugriff auf die Daten und Metadaten des Leaders zu erhalten. Leader-Änderungen wie create, append und drop werden automatisch mit dem Follower synchronisiert. Leader können sich über mehrere Azure-Regionen erstrecken. Die Follower-Cluster müssen dagegen in der gleichen Region bzw. in den gleichen Regionen gehostet werden wie der Leader. Wenn der Leader-Cluster ausfällt oder Datenbanken/Tabellen versehentlich gelöscht werden, haben Follower-Cluster keinen Zugriff mehr, bis der Zugriff im Leader wiederhergestellt wurde.
Ausfall einer Azure-Verfügbarkeitszone
Azure-Verfügbarkeitszonen sind individuelle physische Standorte innerhalb der gleichen Azure-Region. Sie dienen dazu, die Computeressourcen und Daten eines Azure Data Explorer-Clusters vor einem partiellen Regionsausfall zu schützen. Ein Zonenausfall ist ein Verfügbarkeitsszenario, da er sich innerhalb einer Region ereignet.
Heften Sie einen Azure Data Explorer-Cluster an die gleiche Zone an wie andere verbundene Azure-Ressourcen. Weitere Informationen zur Aktivierung von Verfügbarkeitszonen finden Sie unter Erstellen eines Clusters.
Hinweis
Die Bereitstellung für Verfügbarkeitszonen ist beim Erstellen eines Clusters möglich oder kann später migriert werden.
Ausfall eines Azure-Rechenzentrums
Da Azure-Verfügbarkeitszonen mit Kosten verbunden sind, entscheiden sich manche Kunden für eine Bereitstellung ohne Zonenredundanz. Bei einer solchen Azure Data Explorer-Bereitstellung zieht der Ausfall eines Azure-Rechenzentrums einen Clusterausfall nach sich. Der Ausfall eines Azure-Rechenzentrums muss daher auf die gleiche Weise behandelt werden wie der Ausfall einer Azure-Region.
Ausfall einer Azure-Region
Azure Data Explorer bietet keinen automatischen Schutz vor dem Ausfall einer gesamten Azure-Region. Um die geschäftlichen Auswirkungen bei einem solchen Ausfall zu minimieren, sollten mehrere Azure Data Explorer-Cluster in Azure-Regionspaaren verwendet werden. Es gibt verschiedene Notfallwiederherstellungskonfiguration, die jeweils von Recovery Time Objective (RTO), Recovery Point Objective (RPO), Aufwand und Kosten abhängig sind. Kosten- und Leistungsoptimierungen sind mit Azure Advisor-Empfehlungen und durch eine Konfiguration mit Autoskalierung möglich.
Notfallwiederherstellungskonfigurationen
In diesem Abschnitt werden mehrere Notfallwiederherstellungskonfigurationen beschrieben, die jeweils von den Resilienzanforderungen (RPO und RTO) sowie vom Aufwand und von den Kosten abhängen.
Recovery Time Objective (RTO) bezieht sich auf die Zeit bis zur Wiederherstellung nach einer Störung. So bedeutet beispielsweise ein RTO-Wert von zwei Stunden, dass die Anwendung nach einer Störung innerhalb von zwei Stunden wieder verfügbar sein muss. Recovery Point Objective (RPO) bezieht sich auf die Zeit, die bei einer Störung vergehen kann, bis der Datenverlust den zulässigen Schwellenwert übersteigt. Wenn der RPO-Wert also beispielsweise 24 Stunden beträgt und eine Anwendung Daten aus den letzten 15 Jahren enthält, sind die Parameter des vereinbarten RPO-Werts weiterhin erfüllt.
Erfassungs-, Verarbeitungs- und Zusammenstellungsprozesse müssen bereits im Vorfeld der Notfallwiederherstellungsplanung sorgfältig entworfen werden. Erfassung bezieht sich auf Daten, die aus verschiedenen Quellen in Azure Data Explorer integriert werden. Verarbeitung bezieht sich auf Transformationen und ähnliche Aktivitäten. Zusammenstellung bezieht sich auf materialisierte Sichten, Exporte in den Data Lake und Ähnliches.
Hier finden Sie gängige Notfallwiederherstellungskonfigurationen, die im Anschluss jeweils ausführlich beschrieben werden:
- Aktiv/Aktiv/Aktiv-Konfiguration (Always On)
- Aktiv/Aktiv-Konfiguration
- Konfiguration mit einem aktiven und einem unmittelbar betriebsbereiten Cluster
- Konfiguration mit bedarfsgesteuertem Datenwiederherstellungscluster
Aktiv/Aktiv/Aktiv-Konfiguration
Diese Konfiguration wird auch als „Always On“ bezeichnet. Bei kritischen Anwendungsbereitstellungen ohne Toleranz für Ausfälle empfiehlt sich die Verwendung mehrerer Azure Data Explorer-Cluster in verschiedenen Azure-Regionspaaren. Richten Sie die Erfassung, Verarbeitung und Zusammenstellung parallel zu allen Clustern ein. Die Cluster-SKU muss regionsübergreifend gleich sein. Von Azure wird sichergestellt, dass Updates in Azure-Regionspaaren angewendet und gestaffelt werden. Der Ausfall einer Azure-Region führt nicht zu einem Anwendungsausfall. Es kommt jedoch möglicherweise zu Wartezeiten oder Leistungseinbußen.
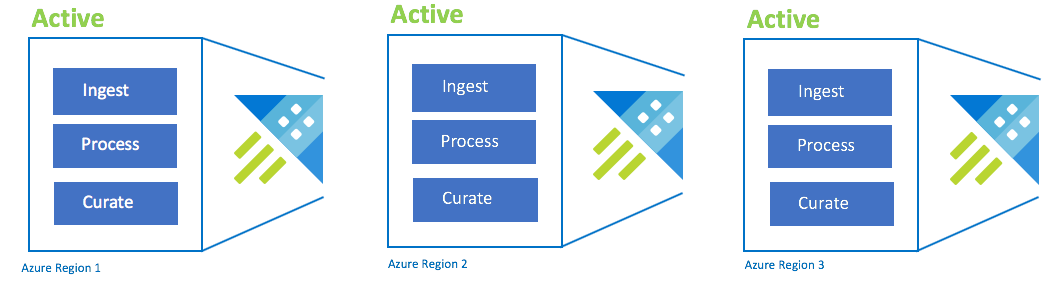
| Configuration | RPO | RTO | Aufwand | Kosten |
|---|---|---|---|---|
| Aktiv/Aktiv/Aktiv/-n | 0 Stunden | 0 Stunden | Geringer | Am höchsten |
Aktiv/Aktiv-Konfiguration
Diese Konfiguration ist mit der Aktiv/Aktiv/Aktiv-Konfiguration identisch, umfasst jedoch nur zwei Azure-Regionspaare. Konfigurieren Sie eine duale Erfassung, Verarbeitung und Zusammenstellung. Benutzer werden an die nächstgelegene Region weitergeleitet. Die Cluster-SKU muss regionsübergreifend gleich sein.
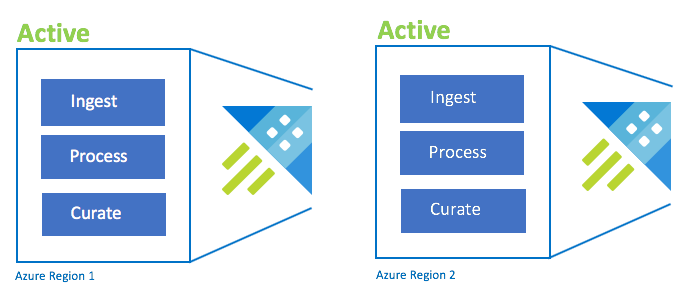
| Configuration | RPO | RTO | Aufwand | Kosten |
|---|---|---|---|---|
| Aktiv/Aktiv | 0 Stunden | 0 Stunden | Geringer | Hoch |
Konfiguration mit einem aktiven und einem unmittelbar betriebsbereiten Cluster
Die Konfiguration mit einem aktiven und einem unmittelbar betriebsbereiten Cluster ähnelt der Aktiv/Aktiv-Konfiguration hinsichtlich der dualen Erfassung, Verarbeitung und Zusammenstellung. Während der Standbycluster für Aufnahme, Prozess und Curation online ist, steht er nicht zur Abfrage zur Verfügung. Der Standbycluster muss sich nicht in derselben SKU wie der primäre Cluster befinden. Es kann eine kleinere SKU und eine kleinere Skalierung sein, was dazu führen kann, dass sie weniger leistungsfähig ist. In einem Notfallszenario werden Benutzer an den Standbycluster umgeleitet, der optional skaliert werden kann, um die Leistung zu erhöhen.
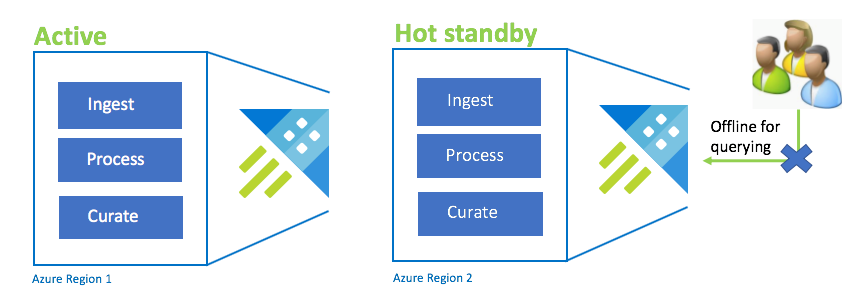
| Configuration | RPO | RTO | Aufwand | Kosten |
|---|---|---|---|---|
| Ein aktiver und ein unmittelbar betriebsbereiter Cluster | 0 Stunden | Niedrig | Medium | Medium |
Konfiguration mit bedarfsgesteuerter Datenwiederherstellung
Diese Lösung bietet die geringste Resilienz (höchster RPO- und RTO-Wert) und die niedrigsten Kosten, ist aber mit dem höchsten Aufwand verbunden. In dieser Konfiguration gibt es keinen Datenwiederherstellungscluster. Konfigurieren Sie den fortlaufenden Export zusammengestellter Daten (es sei denn, es werden auch Roh- und Zwischendaten benötigt) für ein Speicherkonto mit GRS-Konfiguration (georedundanter Speicher). Ein Datenwiederherstellungscluster wird im Falle eines Notfallwiederherstellungsszenarios hochgefahren. Zu diesem Zeitpunkt werden DDLs, die Konfiguration, Richtlinien und Prozesse angewendet. Daten werden aus dem Speicher mit der Erfassungseigenschaft kustoCreationTime erfasst, um die Erfassungszeit zu überschreiben, die standardmäßig auf die Systemzeit festgelegt ist.
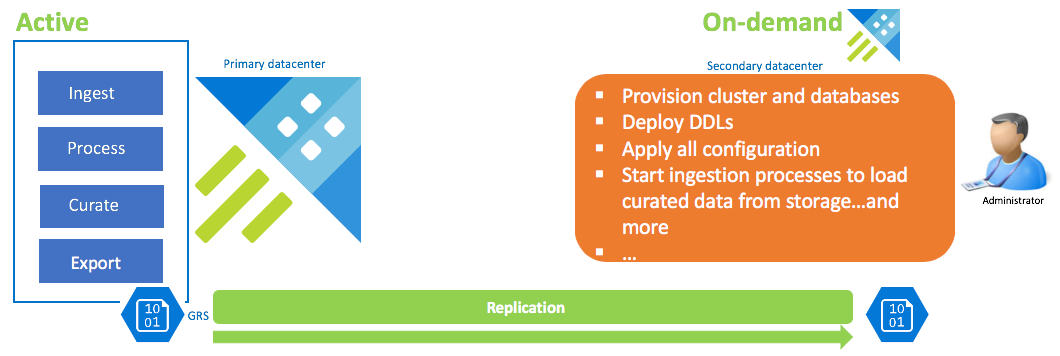
| Configuration | RPO | RTO | Aufwand | Kosten |
|---|---|---|---|---|
| Bedarfsgesteuerter Datenwiederherstellungscluster | Am höchsten | Am höchsten | Am höchsten | Niedrigste |
Zusammenfassung der Optionen für die Notfallwiederherstellungskonfiguration
| Configuration | Resilienz | RPO | RTO | Aufwand | Kosten |
|---|---|---|---|---|---|
| Aktiv/Aktiv/Aktiv/-n | Am höchsten | 0 Stunden | 0 Stunden | Geringer | Am höchsten |
| Aktiv/Aktiv | Hoch | 0 Stunden | 0 Stunden | Geringer | Hoch |
| Ein aktiver und ein unmittelbar betriebsbereiter Cluster | Medium | 0 Stunden | Niedrig | Medium | Medium |
| Bedarfsgesteuerter Datenwiederherstellungscluster | Niedrigste | Am höchsten | Am höchsten | Am höchsten | Niedrigste |
Bewährte Methoden
Die folgenden bewährten Methoden sollten unabhängig von der gewählten Notfallwiederherstellungskonfiguration angewendet werden:
- Alle Datenbankobjekte, -richtlinien und -konfigurationen sollten in der Quellcodeverwaltung gespeichert werden, um sie per Releaseautomatisierungstool für den Cluster veröffentlichen zu können. Weitere Informationen finden Sie unter Azure DevOps-Aufgabe für Azure Data Explorer.
- Entwerfen, entwickeln und implementieren Sie Validierungsroutinen, um sicherzustellen, dass die Daten aller Cluster synchronisiert sind. Von Azure Data Explorer werden clusterübergreifende Verknüpfungen unterstützt. Eine einfache tabellenübergreifende Zeilenzählung kann zur Validierung beitragen.
- Die Releaseprozeduren sollten Governanceüberprüfungen enthalten, die die Spiegelung der Cluster sicherstellen.
- Machen Sie sich umfassend mit den Anforderungen für die Neuerstellung eines Clusters vertraut.
- Erstellen Sie eine Prüfliste mit Bereitstellungseinheiten. Diese Liste variiert zwar abhängig von Ihren individuellen Anforderungen, sollte aber Folgendes enthalten: Bereitstellungsskripts, Erfassungsverbindungen, BI-Tools und andere wichtige Konfigurationen.