Notfallwiederherstellung
Ein klares Muster für die Notfallwiederherstellung ist für eine cloudnativ basierte Datenanalyseplattform wie Azure Databricks. Es ist es wichtig, dass Ihre Datenteams die Azure Databricks-Plattform auch im seltenen Fall eines Ausfalls eines regionalen dienstweiten Clouddienstanbieters verwenden können, unabhängig davon, ob dies durch eine regionale Katastrophe wie einen Hurrikan oder ein Erdbeben oder eine andere Quelle verursacht wird.
Azure Databricks ist häufig ein zentraler Bestandteil eines gesamten Datenökosystems, das viele Dienste umfasst, einschließlich Upstream-Datenerfassungsdiensten (Batch/Streaming), nativem Cloudspeicher wie ADLS Gen2 (für Arbeitsbereiche, die vor dem 6. März 2023 erstellt wurden, Azure Blob Storage), Downstreamtools und -diensten wie Business Intelligence-Apps und Orchestrierungstools. Einige Ihrer Anwendungsfälle sind möglicherweise besonders anfällig für einen regionalen dienstweiten Ausfall.
In diesem Artikel werden Konzepte und bewährte Methoden für eine erfolgreiche überregionale Notfallwiederherstellungslösung für die Databricks-Plattform beschrieben.
Garantien zur Hochverfügbarkeit innerhalb der Region
Während sich der restliche Teil dieses Artikels auf die Implementierung der überregionalen Notfallwiederherstellung konzentriert, ist es wichtig, die Garantien zur Hochverfügbarkeit zu verstehen, die Azure Databricks innerhalb der einzelnen Region bietet. Garantien zur Hochverfügbarkeit innerhalb der Region decken die folgenden Komponenten ab:
Verfügbarkeit der Azure Databricks-Steuerungsebene
- Die meisten Dienste der Steuerungsebene werden auf Kubernetes-Clustern ausgeführt und behandeln den Verlust von VMs in der spezifischen AZ automatisch.
- Daten den Arbeitsbereichs werden in Datenbanken mit Storage Premium gespeichert und in der gesamten Region repliziert. Der Speicher der Datenbank (einzelner Server) wird nicht über verschiedene AZs oder Regionen repliziert. Wenn sich der Zonenausfall auf den Speicher der Datenbank auswirkt, wird die Datenbank wiederhergestellt, indem eine neue Instanz aus der Sicherung erstellt wird.
- Speicherkonten, die für die Bereitstellung von DBR-Images verwendet werden, sind auch innerhalb der Region redundant, und alle Regionen verfügen über sekundäre Speicherkonten, die verwendet werden, wenn das primäre Konto ausgefallen ist. Weitere Informationen finden Sie unter Azure Databricks-Regionen.
- Im Allgemeinen sollte die Steuerungsebenenfunktion innerhalb von ca. 15 Minuten nach der Wiederherstellung der Verfügbarkeitszone wiederhergestellt sein.
Verfügbarkeit der Computeebene
- Die Verfügbarkeit des Arbeitsbereichs hängt (wie oben beschrieben) von der Verfügbarkeit der Steuerungsebene ab.
- Daten im DBFS-Stamm sind nicht betroffen, wenn das Speicherkonto für DBFS Root mit ZRS oder GZRS (Standard ist GRS) konfiguriert ist.
- Knoten für Cluster werden aus den verschiedenen Verfügbarkeitszonen abgerufen, indem Knoten vom Azure-Computeanbieter angefordert werden (ausreichende Kapazität in den verbleibenden Zonen vorausgesetzt, um die Anforderung zu erfüllen). Wenn ein Knoten verloren geht, fordert der Cluster-Manager Ersatzknoten vom Azure-Computeanbieter an, der sie aus den verfügbaren AZs abruft. Die einzige Ausnahme ist, wenn der Treiberknoten verloren geht. In diesem Fall startet der Auftrags- oder Cluster-Manager sie neu.
Übersicht über die Notfallwiederherstellung
Die Notfallwiederherstellung umfasst eine Reihe von Richtlinien, Tools und Verfahren, die die Wiederherstellung oder Fortsetzung wichtiger Technologieinfrastrukturen und Systeme nach einem natürlichen oder von Menschen verursachten Notfall ermöglichen. Ein großer Clouddienst wie Azure bedient viele Kunden und verfügt über integrierte Wächter vor einem einzelnen Fehler. Beispielsweise ist eine Region eine Gruppe von Gebäuden, die mit verschiedenen Stromquellen verbunden sind, um zu gewährleisten, dass ein einzelner Stromausfall eine Region nicht herunterfährt. Es kann jedoch zu Ausfällen in der Cloudregion kommen, und der Grad der Unterbrechung und die Auswirkungen auf Ihre Organisation können variieren.
Vor der Implementierung eines Plans für die Notfallwiederherstellung ist es wichtig, den Unterschied zwischen Notfallwiederherstellung (DR) und Hochverfügbarkeit zu verstehen.
Hochverfügbarkeit ist eine Resilienzeigenschaft eines Systems. Hochverfügbarkeit stellt ein Minimum an Betriebsleistung sicher, das in der Regel in Bezug auf konsistente Betriebszeit oder Prozentsatz der Betriebszeit definiert ist. Hochverfügbarkeit wird (in derselben Region wie Ihr primäres System) implementiert, indem es als Funktion des primären Systems konzipiert wird. Clouddienste wie Azure verfügen beispielsweise über Hochverfügbarkeitsdienste wie ADLS Gen2 (für Arbeitsbereiche, die vor dem 6. März 2023 erstellt wurden, Azure Blob Storage). Hochverfügbarkeit erfordert keine erhebliche explizite Vorbereitung durch den Azure Databricks-Kunden.
Im Gegensatz dazu erfordert ein Notfallwiederherstellungsplan Entscheidungen und Lösungen, die für Ihre spezifische Organisation funktionieren, um einen größeren regionalen Ausfall für kritische Systeme zu bewältigen. In diesem Artikel werden allgemeine Terminologie zur Notfallwiederherstellung, gängige Lösungen und einige bewährte Methoden für Notfallwiederherstellungspläne mit Azure Databricks besprochen.
Begriff
Terminologie der Region
In diesem Artikel werden die folgenden Definitionen für Regionen verwendet:
Primäre Region: Die geografische Region, in der Benutzer typische tägliche interaktive und automatisierte Datenanalyseworkloads ausführen.
Sekundäre Region: Die geografische Region, in der IT-Teams Datenanalyseworkloads während eines Ausfalls in der primären Region vorübergehend verschieben.
Georedundanter Speicher: Azure verfügt über regionsübergreifenden georedundanten Speicher für persistenten Speicher mithilfe eines asynchronen Speicherreplikationsprozesses.
Wichtig
Für Notfallwiederherstellungsprozesse empfiehlt Databricks, sich nicht auf georedundanten Speicher für die regionsübergreifende Duplizierung von Daten wie Ihrem ADLS Gen2 (für Arbeitsbereiche, die vor dem 6. März 2023 erstellt wurden, Azure Blob Storage) zu verlassen, den Azure Databricks für jeden Arbeitsbereich in Ihrem Azure-Abonnement erstellt. Verwenden Sie im Allgemeinen Deep Clone für Delta-Tabellen, und konvertieren Sie Daten in das Delta-Format, um Deep Clone nach Möglichkeit für andere Datenformate zu verwenden.
Terminologie zum Bereitstellungsstatus
In diesem Artikel werden die folgenden Definitionen des Bereitstellungsstatus verwendet:
Aktive Bereitstellung: Benutzer können eine Verbindung mit einer aktiven Bereitstellung eines Azure Databricks-Arbeitsbereichs herstellen und Workloads ausführen. Aufträge werden in regelmäßigen Abständen mit Azure Databricks Planer oder einem anderen Mechanismus geplant. Datenströme können auch für diese Bereitstellung ausgeführt werden. Einige Dokumente verweisen möglicherweise auf eine aktive Bereitstellung als heiße Bereitstellung.
Passive Bereitstellung: Prozesse werden nicht in einer passiven Bereitstellung ausgeführt. IT-Teams können automatisierte Verfahren einrichten, um Code, Konfiguration und andere Azure Databricks für die passive Bereitstellung bereitzustellen. Eine Bereitstellung wird nur aktiv, wenn eine aktuelle aktive Bereitstellung nicht verfügbar ist. Einige Dokumente verweisen möglicherweise auf eine passive Bereitstellung als kalte Bereitstellung.
Wichtig
Ein Projekt kann optional mehrere passive Bereitstellungen in verschiedenen Regionen enthalten, um zusätzliche Optionen zum Beheben regionaler Ausfälle bereitzustellen.
Im Allgemeinen verfügt ein Team in einer so genannten Aktiv/Passiv-Notfallwiederherstellungsstrategie nur über eine aktive Bereitstellung gleichzeitig. Es gibt eine weniger gängige Lösungsstrategie für die Notfallwiederherstellung mit dem Namen Aktiv/Aktiv, bei der zwei gleichzeitig aktive Bereitstellungen ausgeführt werden.
Terminologie der Notfallwiederherstellungsbranche
Es gibt zwei wichtige Branchenbegriffe, die Sie für Ihr Team verstehen und definieren müssen:
Recovery Point Objective: Ein Recovery Point Objective (RPO) ist der maximale Zielzeitraum, in dem Daten (Transaktionen) aufgrund eines größeren Incidents von einem IT-Dienst verloren gehen können. Ihre Azure Databricks-Bereitstellung enthält keine Hauptkundendaten. Dies wird in separaten Systemen wie ADLS Gen2 (für Arbeitsbereiche, die vor dem 6. März 2023 erstellt wurden, Azure Blob Storage) oder in anderen Datenquellen gespeichert, die Sie kontrollieren. Auf Azure Databricks-Steuerungsebene werden einige Objekte teilweise oder vollständig gespeichert, z. B. Aufträge und Notebooks. Beispielsweise ist Azure Databricks RPO als der maximale Zielzeitraum definiert, in dem Objekte wie Auftrags- und Notebookänderungen verloren gehen können. Darüber hinaus sind Sie für die Definition des RPO für Ihre eigenen Kundendaten in ADLS Gen2 (für Arbeitsbereiche, die vor dem 6. März 2023 erstellt wurden, Azure Blob Storage) oder anderen Datenquellen unter Ihrer Kontrolle verantwortlich.
Recovery Time Objective ( RTO): Das Recovery Time Objective (RTO) ist die zielorientierte Dauer und ein Servicelevel, innerhalb dessen ein Geschäftsprozess nach einem Notfall wiederhergestellt werden muss.
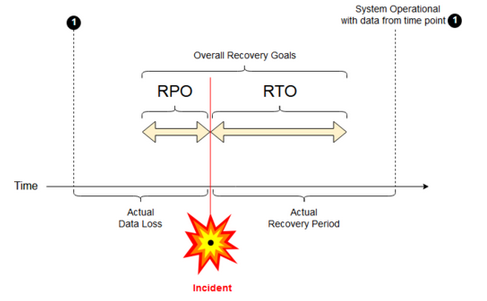
Notfallwiederherstellung und Datenbeschädigung
Eine Notfallwiederherstellungslösung mindert keine Datenbeschädigungen. Beschädigte Daten in der primären Region werden aus der primären Region in eine sekundäre Region repliziert und sind in beiden Regionen beschädigt. Es gibt andere Möglichkeiten, diese Art von Ausfällen zu minimieren, z. B. Delta-Zeitreise.
Typischer Wiederherstellungsworkflow
Ein Azure Databricks-Notfallwiederherstellungsszenario läuft in der Regel folgendermaßen ab:
Ein Fehler tritt in einem kritischen Dienst auf, den Sie in Ihrer primären Region verwenden. Dies kann ein Datenquellendienst oder ein Netzwerk sein, das Auswirkungen sich auf die Azure Databricks-Bereitstellung hat.
Sie untersuchen die Situation mit dem Cloudanbieter.
Wenn Sie zu dem Schluss kommen, dass Ihr Unternehmen nicht warten kann, bis das Problem in der primären Region behoben wurde, können Sie entscheiden, dass Sie ein Failover auf eine sekundäre Region benötigen.
Stellen Sie sicher, dass sich das gleiche Problem nicht auch auf die sekundäre Region auswirken kann.
Führen Sie ein Failover in eine sekundäre Region aus.
- Beenden Sie alle Aktivitäten im Arbeitsbereich. Benutzer beenden Workloads. Benutzer oder Administratoren werden nach Möglichkeit angewiesen, eine Sicherung der letzten Änderungen vorzunehmen. Aufträge werden heruntergefahren, wenn sie aufgrund des Ausfalls noch nicht fehlgeschlagen sind.
- Starten Sie die Wiederherstellungsprozedur in der sekundären Region. Das Wiederherstellungsverfahren aktualisiert das Routing und die Umbenennung der Verbindungen und des Netzwerkdatenverkehrs in die sekundäre Region.
- Deklarieren Sie nach dem Testen die sekundäre Region als betriebsbereit. Produktionsworkloads können jetzt fortgesetzt werden. Benutzer können sich bei der jetzt aktiven Bereitstellung anmelden. Sie können geplante oder verzögerte Aufträge erneut auslösen.
Ausführliche Schritte in einem Azure Databricks-Kontext finden Sie unter Testfailover.
Zu einem bestimmten Zeitpunkt wird das Problem in der primären Region behoben, und Sie bestätigen dies.
Stellen Sie ihn (Failback) in Ihrer primären Region wieder her.
- Beenden Sie alle Arbeiten in der sekundären Region.
- Starten Sie die Wiederherstellungsprozedur in der sekundären Region. Das Wiederherstellungsverfahren übernimmt das Routing und die Umbenennung der Verbindung und des Netzwerkdatenverkehrs zurück in die primäre Region.
- Replizieren Sie Daten nach Bedarf zurück in die primäre Region. Um die Komplexität zu reduzieren, minimieren Sie möglicherweise, wie viele Daten repliziert werden müssen. Wenn einige Aufträge beispielsweise schreibgeschützt sind, wenn sie in der sekundären Bereitstellung ausgeführt werden, müssen Sie diese Daten möglicherweise nicht wieder in Ihre primäre Bereitstellung in der primären Region replizieren. Möglicherweise verfügen Sie jedoch über einen Produktionsauftrag, der ausgeführt werden muss und möglicherweise eine Datenreplikation zurück in die primäre Region benötigt.
- Testen Sie die Bereitstellung in der primären Region.
- Deklarieren Sie Ihre primäre Region als betriebsbereit, und dass es sich um Ihre aktive Bereitstellung handelt. Setzen Sie Produktionsworkloads fort.
Weitere Informationen zum Wiederherstellen in Ihrer primären Region finden Sie unter Testwiederherstellung (Failback).
Wichtig
Während dieser Schritte kann es zu Datenverlusten kommen. Ihre Organisation muss definieren, wie viel Datenverlust akzeptabel ist und wie Sie diesen Verlust minimieren können.
Schritt 1: Verstehen Ihrer Geschäftsanforderungen
Der erste Schritt besteht im Definieren und Verstehen Ihrer Geschäftsanforderungen. Definieren Sie, welche Datendienste von entscheidender Bedeutung sind und welche RPO und RTO erwartet werden.
Recherchieren Sie die reale Toleranz der einzelnen Systeme, und denken Sie daran, dass Failover und Failback für die Notfallwiederherstellung kostspielig sein können und andere Risiken mit sich bringt. Andere Risiken können Datenbeschädigung, datenduplizierte Daten sein, wenn Sie an den falschen Speicherort schreiben, und Benutzer, die sich anmelden und Änderungen an falschen Stellen vornehmen.
Ordnen Sie alle Azure Databricks-Integrationspunkte zu, die sich auf Ihr Unternehmen auswirken:
- Muss Ihre Notfallwiederherstellungslösung interaktive Prozesse, automatisierte Prozesse oder beides unterstützen?
- Welche Datendienste nutzen Sie? Einige sind möglicherweise lokal.
- Wie kommen Eingabedaten in die Cloud?
- Wer nutzt diese Daten? Welche Prozesse verbrauchen es nachgelagert?
- Gibt es Integrationen von Drittanbietern, die Änderungen an der Notfallwiederherstellung beachten müssen?
Bestimmen Sie die Tools oder Kommunikationsstrategien, die Ihren Notfallwiederherstellungsplan unterstützen können:
- Welche Tools verwenden Sie, um Netzwerkkonfigurationen schnell zu ändern?
- Können Sie Ihre Konfiguration vordefiniert und modular machen, um Notfallwiederherstellungslösungen auf natürliche und wartungsfreundliche Weise zu unterstützen?
- Welche Kommunikationstools und Kanäle benachrichtigen interne Teams und Drittanbieter (Integrationen, Downstream-Consumer) über Failover- und Failbackänderungen bei der Notfallwiederherstellung? Und wie werden Sie deren Kenntnisnahme bestätigen?
- Welche Tools oder spezielle Unterstützung sind erforderlich?
- Welche Dienste werden heruntergefahren, bis die Wiederherstellung abgeschlossen ist?
Schritt 2: Auswählen eines Prozesses, der Ihre Geschäftsanforderungen erfüllt
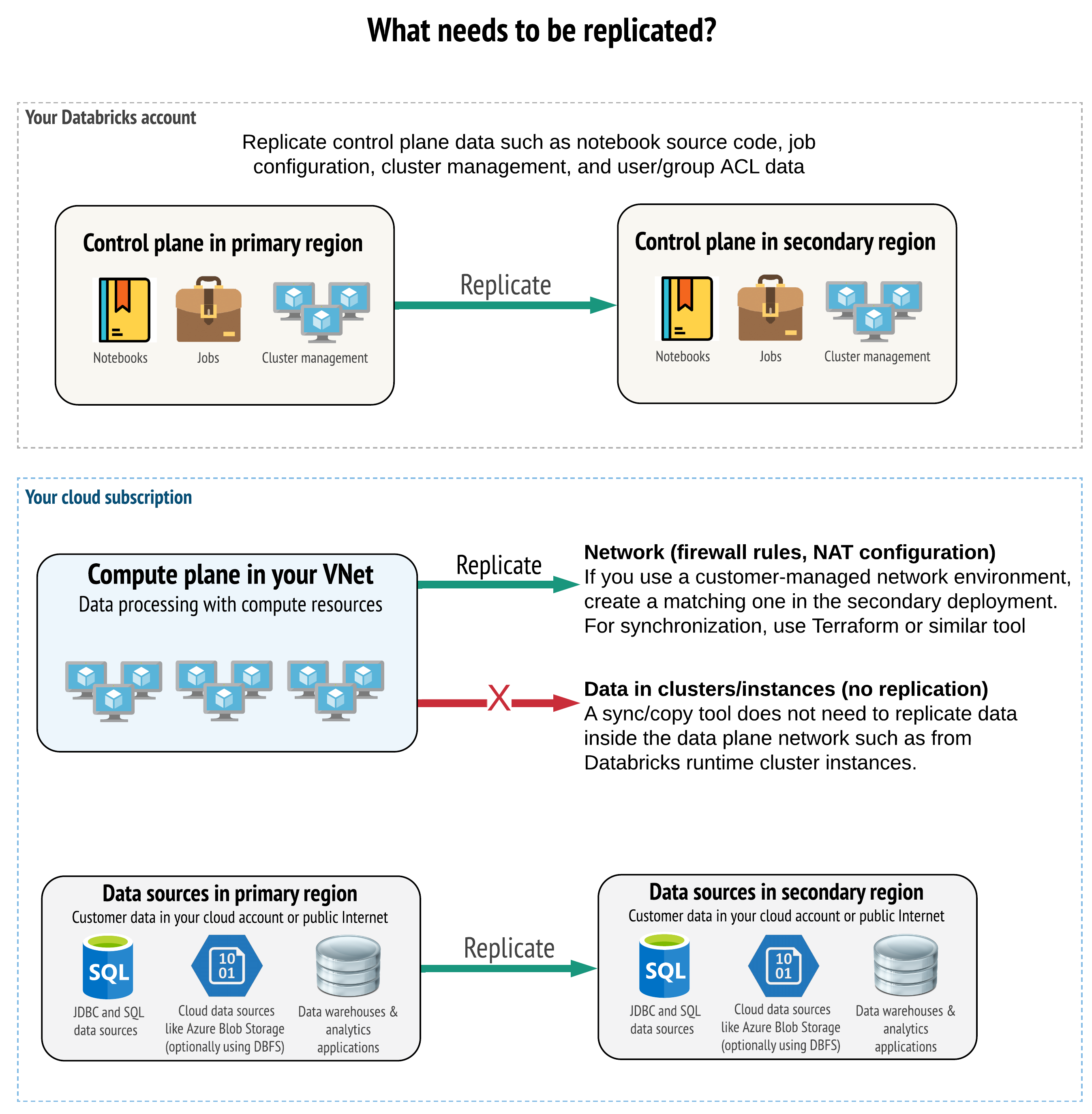
Ihre Lösung muss die richtigen Daten auf Steuerungsebene, Computeebene und Datenquellen replizieren. Redundante Arbeitsbereiche für die Notfallwiederherstellung müssen unterschiedliche Steuerungsebenen in verschiedenen Regionen zuordnen. Sie müssen diese Daten regelmäßig mithilfe einer skriptbasierten Lösung synchronisieren, entweder mit einem Synchronisierungstool oder einem CI/CD-Workflow. Es ist nicht notwendig, Daten aus dem Computeebenennetzwerk selbst zu synchronisieren, z. B. von Databricks Runtime Workers.
Wenn Sie die VNet-Injektionsfunktion verwenden (nicht bei allen Abonnement- und Bereitstellungstypen verfügbar), können Sie diese Netzwerke mithilfe von vorlagenbasierten Tools wie Terraform in beiden Regionen konsistent bereitstellen.
Darüber hinaus müssen Sie sicherstellen, dass Ihre Datenquellen nach Bedarf regionsübergreifend repliziert werden.
Allgemeine bewährte Methoden
Zu den allgemeinen bewährten Methoden für einen erfolgreichen Notfallwiederherstellungsplan gehören:
Verstehen, welche Prozesse für das Unternehmen von entscheidender Bedeutung sind und bei der Notfallwiederherstellung ausgeführt werden müssen.
Eindeutig identifizieren, welche Dienste beteiligt sind, welche Daten verarbeitet werden, was der Datenfluss ist und wo er gespeichert wird.
Isolieren Sie die Dienste und Daten so weit wie möglich. Erstellen Sie beispielsweise einen speziellen Cloudspeichercontainer für die Daten für die Notfallwiederherstellung, oder verschieben Sie Azure Databricks-Objekte, die während eines Notfalls benötigt werden, in einen separaten Arbeitsbereich.
Es liegt in Ihrer Verantwortung, die Integrität zwischen primären und sekundären Bereitstellungen für andere Objekte zu gewährleisten, die nicht auf der Databricks-Steuerungsebene gespeichert sind.
Warnung
Es hat sich bewährt, Daten nicht im ADLS Gen2-Stammspeicher (für Arbeitsbereiche, die vor dem 6. März 2023 erstellt wurden: Azure Blob Storage) zu speichern, der für den DBFS-Stammzugriff für den Arbeitsbereich verwendet wird. Dieser DBFS-Stammspeicher wird für Produktionskundendaten nicht unterstützt. Databricks empfiehlt außerdem, keine Bibliotheken, Konfigurationsdateien oder Initialisierungsskripts an diesem Ort zu speichern.
Für Datenquellen wird empfohlen, nach Möglichkeit native Azure-Tools für Replikation und Redundanz zu verwenden, um Daten in die Notfallwiederherstellungsregionen zu replizieren.
Auswählen einer Wiederherstellungslösungsstrategie
Typische Lösungen für die Notfallwiederherstellung umfassen zwei (oder möglicherweise mehr) Arbeitsbereiche. Es gibt mehrere Strategien, die Sie auswählen können. Berücksichtigen Sie die potenzielle Dauer der Unterbrechung (Stunden oder vielleicht sogar einen Tag), den Aufwand, sicherzustellen, dass der Arbeitsbereich voll funktionsfähig ist, und den Aufwand für die Wiederherstellung (Failback) in der primären Region.
Aktiv/Passiv-Lösungsstrategie
Eine Aktiv/Passiv-Lösung ist die gängigste und einfachste Lösung, und diese Art von Lösung steht im Mittelpunkt dieses Artikels. Eine Aktiv/Passiv-Lösung synchronisiert Daten- und Objektänderungen von Ihrer aktiven Bereitstellung mit Ihrer passiven Bereitstellung. Wenn Sie es vorziehen, können Sie mehrere passive Bereitstellungen in verschiedenen Regionen verwenden, aber dieser Artikel konzentriert sich auf den Ansatz der einzelnen passiven Bereitstellung. Während eines Notfallwiederherstellungsereignis wird die passive Bereitstellung in der sekundären Region zu Ihrer aktiven Bereitstellung.
Es gibt zwei Hauptvarianten dieser Strategie:
- Einheitliche (unternehmensweite) Lösung: Genau eine Gruppe aktiver und passiver Bereitstellungen, die die gesamte Organisation unterstützen.
- Lösung nach Abteilung oder Projekt: Jede Abteilung oder Projektdomäne verwaltet eine separate Notfallwiederherstellungslösung. Einige Organisationen möchten Details zur Notfallwiederherstellung zwischen Abteilungen entkoppeln und basierend auf den individuellen Anforderungen der einzelnen Teams unterschiedliche primäre und sekundäre Regionen für jedes Team verwenden.
Es gibt andere Varianten, z. B. die Verwendung einer passiven Bereitstellung für schreibgeschützte Anwendungsfälle. Wenn Sie über schreibgeschützte Workloads verfügen, z. B. Benutzerabfragen, können diese jederzeit in einer passiven Lösung ausgeführt werden, wenn sie keine Daten ändern oder Azure Databricks-Objekte wie Notebooks oder Aufträgen.
Aktiv/Aktiv-Lösungsstrategie
In einer Aktiv/Aktiv-Lösung führen Sie alle Datenprozesse in beiden Regionen jederzeit parallel aus. Ihr Betriebsteam muss sicherstellen, dass ein Datenprozess wie ein Auftrag nur dann als abgeschlossen markiert wird, wenn er in beiden Regionen erfolgreich abgeschlossen wurde. Objekte können in der Produktion nicht geändert werden und müssen einer strikten CI/CD-Förderung von der Entwicklung/Staging-Bereitstellung in die Produktion folgen.
Eine Aktiv/Aktiv-Lösung ist die komplexeste Strategie, und da Aufträge in beiden Regionen ausgeführt werden, entstehen zusätzliche finanzielle Kosten.
Genau wie bei der Aktiv/Passiv-Strategie können Sie dies als einheitliche Organisationslösung oder nach Abteilung implementieren.
Je nach Workflow benötigen Sie möglicherweise keinen gleichwertigen Arbeitsbereich im sekundären System für alle Arbeitsbereiche. Beispielsweise kann es sein, dass ein Entwicklungs- oder Stagingarbeitsbereich möglicherweise kein Duplikat benötigt. Mit einer gut entworfenen Entwicklungspipeline können Sie diese Arbeitsbereiche bei Bedarf problemlos rekonstruieren.
Auswählen Ihrer Tools
Es gibt zwei Hauptansätze für Tools, um Daten zwischen Arbeitsbereichen in Ihrer primären und sekundären Region so ähnlich wie möglich zu halten:
- Synchronisierungsclient, der Daten vom primären zum sekundären Replikat kopiert: Ein Synchronisierungsclient pusht Produktionsdaten und Ressourcen aus der primären Region in die sekundäre Region. In der Regel erfolgt dies nach einem festen Zeitplan.
- CI/CD-Tools für die parallele Bereitstellung: Verwenden Sie für Produktionscode und Ressourcen CI/CD-Tools, die Änderungen gleichzeitig an Produktionssysteme in beide Regionen pushen. Wenn Sie z. B. Code und Ressourcen aus Staging/Entwicklung in die Produktion pushen, stellt ein CI/CD-System ihn gleichzeitig in beiden Regionen zur Verfügung. Der Kerngedanke besteht darin, alle Artefakte in einem Azure Databricks Arbeitsbereich als Infrastructure-as-Code zu behandeln. Die meisten Artefakte können in primären und sekundären Arbeitsbereichen gemeinsam bereitgestellt werden, während einige Artefakte möglicherweise erst nach einem Notfallwiederherstellungsereignis bereitgestellt werden müssen. Tools finden Sie unter Automatisierungsskripts, Beispiele und Prototypen.
Im folgenden Diagramm werden diese beiden Ansätze gegenüber dargestellt.
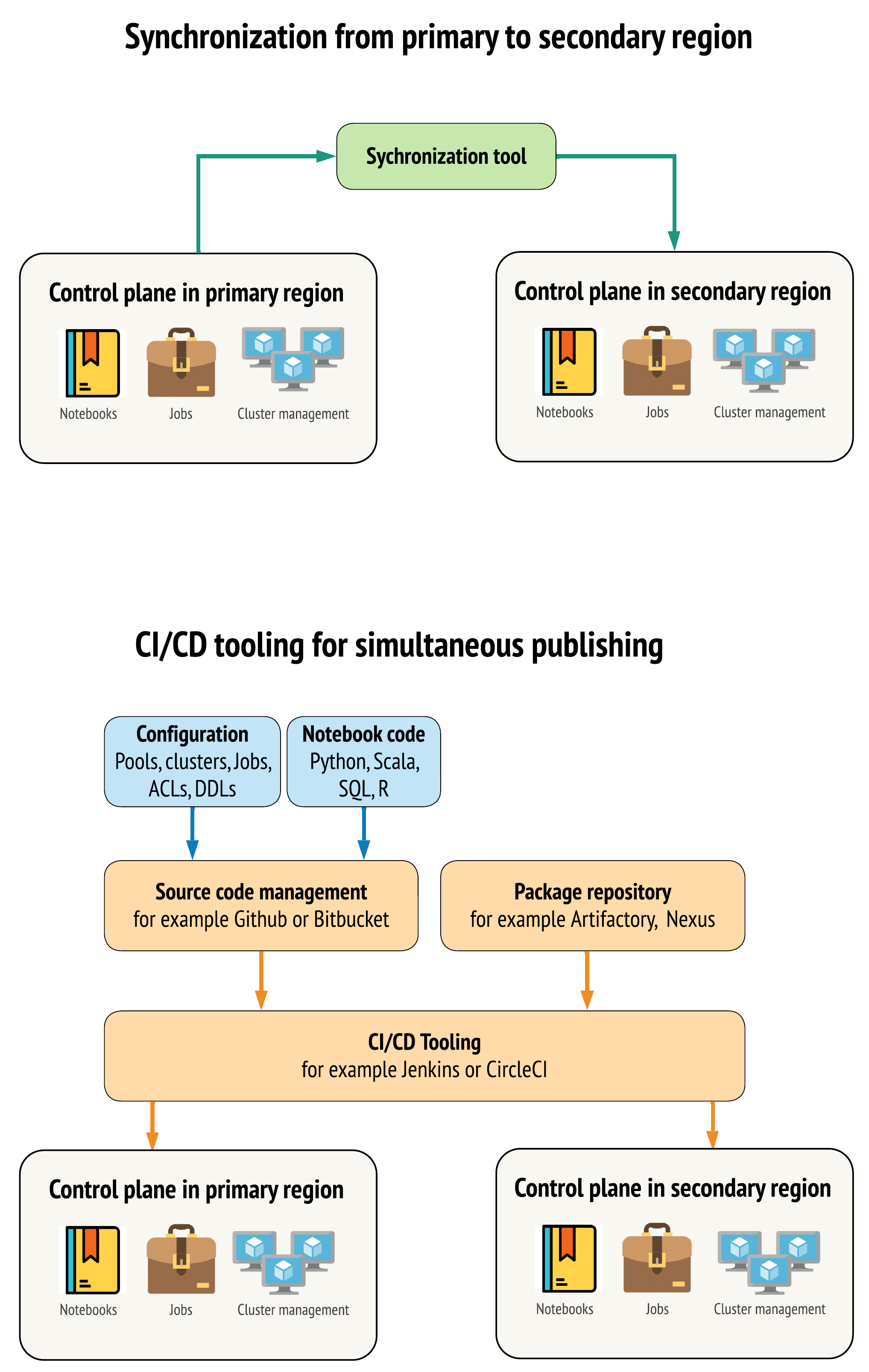
Je nach Ihren Anforderungen können Sie die Ansätze kombinieren. Verwenden Sie z. B. CI/CD für Notebook-Quellcode, aber verwenden Sie die Synchronisierung für Konfigurationen wie Pools und Zugriffssteuerungen.
In der folgenden Tabelle wird beschrieben, wie verschiedene Datentypen mit jeder Tooloption behandelt werden.
| BESCHREIBUNG | Behandeln von CI/CD-Tools | Behandeln von Synchronisierungstool |
|---|---|---|
| Quellcode: Notebook-Quellcodeexporte und Quellcode für gepackte Bibliotheken | Co-Bereitstellung für primäre und sekundäre Replikate. | Synchronisieren des Quellcodes vom primären zum sekundären Replikat. |
| Benutzer und Gruppen | Verwalten von Metadaten als Konfiguration in Git. Alternativ können Sie für beide Arbeitsbereiche denselben Identitätsanbieter (IdP) verwenden. Co-Bereitstellung von Benutzer- und Gruppendaten in primären und sekundären Bereitstellungen. | Verwenden Sie SCIM oder eine andere Automatisierung für beide Regionen. Die manuelle Erstellung wird nicht empfohlen, aber wenn sie verwendet wird, muss für beide gleichzeitig durchgeführt werden. Wenn Sie eine manuelle Einrichtung verwenden, erstellen Sie einen geplanten automatisierten Prozess, um die Liste der Benutzer und die Gruppe zwischen den beiden Bereitstellungen zu vergleichen. |
| Poolkonfigurationen | Können Vorlagen in Git sein. Co-Bereitstellung für primäre und sekundäre Replikate. min_idle_instances im sekundären Replikat muss jedoch bis zum Notfallwiederherstellungsereignis null sein. |
Pools, die mit einem beliebigen min_idle_instances erstellt werden, wenn sie mithilfe der API oder CLI mit dem sekundären Arbeitsbereich synchronisiert werden. |
| Job configurations (Auftragskonfigurationen) | Können Vorlagen in Git sein. For primary deployment, deploy the job definition as is. Stellen Sie für die sekundäre Bereitstellung den Auftrag ein, und legen Sie die Währungen auf null fest. Dadurch wird der Auftrag in dieser Bereitstellung deaktiviert und zusätzliche Läufe verhindert. Ändern Sie den Währungswert, nachdem die sekundäre Bereitstellung aktiv wurde. | Wenn die Aufträge aus irgendeinem Grund auf vorhandenen <interactive> Clustern ausgeführt werden, muss der Synchronisierungsclient den entsprechenden cluster_id im sekundären Arbeitsbereich zuordnen. |
| Zugriffssteuerungslisten (ACLs) | Können Vorlagen in Git sein. Co-Bereitstellung in primären und sekundären Bereitstellungen für Notebooks, Ordner und Cluster. Halten Sie jedoch die Daten für Aufträge bis zum Wiederherstellungsereignis zurück. | Die Berechtigungs-API kann Zugriffssteuerungen für Cluster, Aufträge, Pools, Notebooks und Ordner festlegen. Ein Synchronisierungsclient muss die entsprechenden Objekt-IDs für jedes Objekt im sekundären Arbeitsbereich zuordnen. Databricks empfiehlt, eine Zuordnung von Objekt-IDs vom primären zum sekundären Arbeitsbereich zu erstellen, während diese Objekte vor dem Replizieren der Zugriffssteuerung synchronisiert werden. |
| Bibliotheken | Fügen Sie in Quellcode und Cluster-/Auftragsvorlagen ein. | Synchronisieren Sie benutzerdefinierte Bibliotheken aus zentralisierten Repositorys, DBFS oder dem Cloudspeicher (kann eingebunden werden). |
| Clusterinitialisierungsskript | Fügen Sie in den Quellcode ein, wenn Sie möchten. | Um die Synchronisierung zu vereinfachen, speichern Sie Init-Skripts im primären Arbeitsbereich in einem gemeinsamen Ordner oder nach Möglichkeit in einem kleinen Satz von Ordnern. |
| Bereitstellungspunkte | Schließen Sie den Quellcode ein, wenn er nur über notebookbasierte Aufträge oder die Befehls-API erstellt wird. | Verwenden Sie Aufträge, die als ADF-Aktivitäten (Azure Data Factory-Aktivitäten) ausgeführt werden können. Beachten Sie, dass sich die Speicherendpunkte ändern können, da sich Arbeitsbereiche in unterschiedlichen Regionen befinden. Dies hängt auch stark von Ihrer Strategie für die Notfallwiederherstellung von Daten ab. |
| Tabellenmetadaten | Schließen Sie sie mit dem Quellcode ein, wenn sie nur über notebookbasierte Aufträge oder die Befehls-API erstellt werden. Dies gilt sowohl für den Azure Databricks-Metastore als auch für den extern konfigurierten Metastore. | Vergleichen Sie die Metadatendefinitionen zwischen den Metastores mithilfe der Spark-Katalog-API oder Anzeigen der Tabellenerstellung über ein Notebook oder Skripts. Beachten Sie, dass die Tabellen für den zugrunde liegenden Speicher regionsbasiert sein können und sich zwischen Metastore-Instanzen unterscheiden. |
| Geheimnisse | Fügen Sie in den Quellcode ein, wenn sie nur über die Befehls-API erstellt wurden. Beachten Sie, dass einige Geheimnisinhalte möglicherweise zwischen dem Primären und dem Sekundären geändert werden müssen. | Geheimnisse werden in beiden Arbeitsbereichen über die API erstellt. Beachten Sie, dass einige Geheimnisinhalte möglicherweise zwischen dem Primären und dem Sekundären geändert werden müssen. |
| Clusterkonfigurationen | Können Vorlagen in Git sein. Co-Bereitstellung für primäre und sekundäre Bereitstellungen, obwohl diejenigen in der sekundären Bereitstellung bis zum Notfallwiederherstellungsereignis beendet werden sollten. | Cluster werden erstellt, nachdem sie mithilfe der API oder CLI mit dem sekundären Arbeitsbereich synchronisiert wurden. Diese können je nach Denkeinstellungen für die automatische Beendigung explizit beendet werden. |
| Notebook-, Auftrags- und Ordnerberechtigungen | Können Vorlagen in Git sein. Co-Bereitstellung für primäre und sekundäre Bereitstellungen. | Verwenden Sie für die Replikation die Berechtigungs-API. |
Auswählen von Regionen und mehreren sekundären Arbeitsbereichen
Sie benötigen vollständige Kontrolle über Ihren Notfallwiederherstellungsauslöser. Sie können dies jederzeit oder aus beliebigem Grund auslösen. Sie müssen die Verantwortung für die Notfallwiederherstellungsstabilisierung übernehmen, bevor Sie den Failback-Modus für den Vorgang (normale Produktion) neu starten können. In der Regel bedeutet dies, dass Sie mehrere Azure Databricks-Arbeitsbereiche erstellen müssen, um Ihre Produktions- und Notfallwiederherstellungsanforderungen zu erfüllen, und Ihre sekundäre Failoverregion auswählen müssen.
Überprüfen Sie in Azure ihre Datenreplikation sowie die Verfügbarkeit der Produkt- und VM-Typen.
Schritt 3: Arbeitsbereiche vorbereiten und eine einmalige Kopie erstellen
Wenn sich ein Arbeitsbereich bereits in der Produktionsumgebung befindet, wird in der Regel ein einmaliger Kopiervorgang ausgeführt, um Ihre passive Bereitstellung mit Ihrer aktiven Bereitstellung zu synchronisieren. Diese einmalige Kopie verarbeitet Folgendes:
- Datenreplikation: Replizieren mithilfe einer Cloudreplikationslösung oder eines Delta-Deep Clone-Vorgangs.
- Tokengenerierung: Verwenden de Tokengenerierung, um die Replikation und zukünftige Workloads zu automatisieren.
- Arbeitsbereichsreplikation: Verwenden der Arbeitsbereichsreplikation mithilfe der Methoden beschriebenen in Schritt 4: Vorbereiten Ihrer Datenquellen.
- Arbeitsbereichsüberprüfung: testen, um sicherzustellen, dass der Arbeitsbereich und der Prozess erfolgreich ausgeführt werden können, und die erwarteten Ergebnisse zur Verfügung stellen.
Nach dem ersten einmaligen Kopiervorgang sind nachfolgende Kopier- und Synchronisierungsvorgänge schneller, und jede Protokollierung durch Ihre Tools ist auch ein Protokoll der Änderungen und des Zeitpunkts der Änderungen.
Schritt 4: Vorbereiten Ihrer Datenquellen
Azure Databricks kann eine Vielzahl von Datenquellen mithilfe von Batchverarbeitung oder Datenströmen verarbeiten.
Batchverarbeitung aus Datenquellen
Wenn Daten im Batch verarbeitet werden, befinden sie sich in der Regel in einer Datenquelle, die problemlos repliziert oder in eine andere Region übermittelt werden kann.
Beispielsweise können Daten regelmäßig an einen Cloudspeicherort hochgeladen werden. Im Notfallwiederherstellungsmodus für Ihre sekundäre Region müssen Sie sicherstellen, dass die Dateien in den Speicher der sekundären Region hochgeladen werden. Workloads müssen den Speicher der sekundären Region lesen und in den Speicher der sekundären Region schreiben.
Datenströme
Die Verarbeitung eines Datenstroms ist eine größere Herausforderung. Streamingdaten können aus verschiedenen Quellen aufgenommen und verarbeitet und an eine Streaminglösung gesendet werden:
- Nachrichtenwarteschlange wie Kafka
- Datenstrom für Datenbankänderungsdatenerfassung
- Dateibasierte fortlaufende Verarbeitung
- Dateibasierte geplante Verarbeitung, auch als Einmal-Auslöser bekannt
In all diesen Fällen müssen Sie Ihre Datenquellen so konfigurieren, dass sie den Notfallwiederherstellungsmodus verarbeiten und die sekundäre Bereitstellung in Ihrer sekundären Region verwenden.
Ein Datenstrom-Schreiber speichert einen Prüfpunkt mit Informationen über die verarbeiteten Daten. Dieser Prüfpunkt kann einen Datenspeicherort (normalerweise Cloudspeicher) enthalten, der zu einem neuen Speicherort geändert werden muss, um einen erfolgreichen Neustart des Datenstroms sicherzustellen. Beispielsweise kann der Unterordner source unter dem Prüfpunkt den dateibasierten Cloudordner speichern.
Dieser Prüfpunkt muss rechtzeitig repliziert werden. Erwägen Sie die Synchronisierung des Prüfpunktintervalls mit einer neuen Cloudreplikationslösung.
Das Prüfpunktupdate ist eine Funktion des Schreibers und gilt daher für die Datenerfassung oder -verarbeitung und -speicherung in einer anderen Datenstromquelle.
Stellen Sie für Streamingworkloads sicher, dass Prüfpunkte im vom Kunden verwalteten Speicher konfiguriert sind, damit sie für die Wiederaufnahme der Workload ab dem Zeitpunkt des letzten Fehlers in die sekundäre Region repliziert werden können. Sie können auch den sekundären Streamingprozess parallel zum primären Prozess ausführen.
Schritt 5: Implementieren und Testen Ihrer Lösung
Testen Sie die Einrichtung der Notfallwiederherstellung regelmäßig, um sicherzustellen, dass sie ordnungsgemäß funktioniert. Die Verwaltung einer Notfallwiederherstellungslösung hat keinen Nutzen, wenn Sie sie nicht verwenden können, wenn Sie sie benötigen. Einige Unternehmen wechseln alle paar Monate zwischen Regionen. Beim Wechseln von Regionen nach einem regelmäßigen Zeitplan werden Ihre Annahmen und Prozesse überprüft und sichergestellt, dass sie Ihre Wiederherstellungsanforderungen erfüllen. Dadurch wird auch sichergestellt, dass Ihre Organisation mit den Richtlinien und Verfahren für Notfälle vertraut ist.
Wichtig
Testen Sie Ihre Notfallwiederherstellungslösung regelmäßig unter realen Bedingungen.
Wenn Sie feststellen, dass ein Objekt oder eine Vorlage fehlt und Sie sich weiterhin auf die in Ihrem primären Arbeitsbereich gespeicherten Informationen verlassen müssen, ändern Sie Ihren Plan, um diese Hindernisse zu beseitigen, diese Informationen im sekundären System zu replizieren oder auf andere Weise verfügbar zu machen.
Testen Sie alle erforderlichen Organisationsänderungen an Ihren Prozessen und an der Konfiguration im Allgemeinen. Ihr Notfallwiederherstellungsplan wirkt sich auf Ihre Bereitstellungspipeline aus, und es ist wichtig, dass Ihr Team weiß, was synchronisiert werden muss. Nachdem Sie Ihre Arbeitsbereiche für die Notfallwiederherstellung eingerichtet haben, müssen Sie sicherstellen, dass Ihre Infrastruktur (manuell oder Code), Aufträge, Notebooks, Bibliotheken und andere Arbeitsbereichsobjekte in Ihrer sekundären Region verfügbar sind.
Sprechen Sie mit Ihrem Team darüber, wie Sie Standardarbeitsprozesse und Konfigurationspipelines erweitern können, um Änderungen in allen Arbeitsbereichen bereitzustellen. Verwalten sie Benutzeridentitäten in allen Arbeitsbereichen. Denken Sie daran, Tools wie Auftragsautomatisierung und Überwachung für neue Arbeitsbereiche zu konfigurieren.
Planen und Testen von Änderungen an Konfigurationstools:
- Erfassung: Verstehen Sie, wo sich Ihre Datenquellen befinden und wo diese Quellen ihre Daten erhalten. Parametrisieren Sie nach Möglichkeit die Quelle, und stellen Sie sicher, dass Sie über eine separate Konfigurationsvorlage für die Arbeit mit Ihren sekundären Bereitstellungen und sekundären Regionen verfügen. Bereiten Sie einen Plan für das Failover vor und testen Sie alle Annahmen.
- Ausführungsänderungen: Wenn Sie über einen Planer zum Auslösen von Aufträgen oder anderen Aktionen verfügen, müssen Sie möglicherweise einen separaten Planer konfigurieren, der mit der sekundären Bereitstellung oder deren Datenquellen funktioniert. Bereiten Sie einen Plan für das Failover vor und testen Sie alle Annahmen.
- Interaktive Konnektivität: Überlegen Sie, wie Konfiguration, Authentifizierung und Netzwerkverbindungen durch regionale Unterbrechungen bei der Verwendung von REST-APIs, CLI-Tools oder anderen Diensten wie JDBC/ODBC beeinträchtigt werden könnten. Bereiten Sie einen Plan für das Failover vor und testen Sie alle Annahmen.
- Automatisierungsänderungen: Bereiten Sie für alle Automatisierungstools einen Plan für das Failover vor, und testen Sie alle Annahmen.
- Ausgaben: Bereiten Sie für alle Tools, die Ausgabedaten oder Protokolle generieren, einen Plan für das Failover vor, und testen Sie alle Annahmen.
Testfailover
Die Notfallwiederherstellung kann durch viele verschiedene Szenarien ausgelöst werden. Sie kann durch eine unerwartete Unterbrechung ausgelöst werden. Einige Kernfunktionen sind möglicherweise nicht mehr möglich, z. B. das Cloudnetzwerk, der Cloudspeicher oder ein anderer Kerndienst. Sie haben keinen Zugriff zum ordnungsgemäßen Herunterfahren des Systems und müssen die Wiederherstellung versuchen. Der Prozess kann jedoch durch ein Herunterfahren oder einen geplanten Ausfall oder sogar durch regelmäßiges Wechseln Ihrer aktiven Bereitstellungen zwischen zwei Regionen ausgelöst werden.
Stellen Sie beim Testen des Failovers eine Verbindung mit dem System her, und führen Sie einen Vorgang zum Herunterfahren aus. Stellen Sie sicher, dass alle Aufträge abgeschlossen und die Cluster beendet werden.
Ein Synchronisierungsclient kann (oder CI/CD-Tools können) relevante Azure Databricks Objekte und Ressourcen in den sekundären Arbeitsbereich replizieren. Um Ihren sekundären Arbeitsbereich zu aktivieren, kann Ihr Prozess einige oder alle der folgenden Punkte umfassen:
- Führen Sie Tests aus, um sicherzustellen, dass die Plattform auf dem neuesten Stand ist.
- Deaktivieren Sie Pools und Cluster in der primären Region, sodass die primäre Region nicht mit der Verarbeitung neuer Daten beginnt, wenn der ausgefallene Dienst online geschaltet wird.
- Wiederherstellungsprozess:
- Überprüfen Sie das Datum der letzten synchronisierten Daten. Weitere Informationen finden Sie unter Terminologie der Notfallwiederherstellungsbranche. Die Details dieses Schritts hängen davon ab, wie Sie Daten und Ihre individuellen Geschäftsanforderungen synchronisieren.
- Stabilisieren Sie Ihre Datenquellen, und stellen Sie sicher, dass sie alle verfügbar sind. Schließen Sie alle externen Datenquellen wie Azure Cloud SQL sowie Ihre Delta Lake-, Parquet- oder andere Dateien ein.
- Suchen Sie Ihren Streamingwiederherstellungspunkt. Richten Sie den Prozess so ein, dass er von dort aus neu gestartet wird und über einen Prozess verfügen kann, um potenzielle Duplikate zu identifizieren und zu beseitigen (Delta Lake Lake erleichtert das).
- Schließen Sie den Datenflussprozess ab, und informieren Sie die Benutzer.
- Starten Sie relevante Pools (oder erhöhen Sie
min_idle_instancesauf die relevante Zahl). - Starten Sie relevante Cluster (falls sie nicht beendet werden).
- Ändern Sie die gleichzeitige Ausführung für Aufträge, und führen Sie relevante Aufträge aus. Das können einmalige Ausführungen oder regelmäßige Ausführungen sein.
- Aktualisieren Sie für alle externen Tools, die eine URL oder einen Domänennamen für Ihren Azure Databricks-Arbeitsbereich verwenden, die Konfigurationen, um die neue Steuerungsebene zu berücksichtigen. Aktualisieren Sie beispielsweise URLs für REST-APIs und JDBC-/ODBC-Verbindungen. Die kundenseitige URL der Azure Databricks-Webanwendung ändert sich, wenn sich die Steuerebene ändert, also informieren Sie die Benutzer Ihres Unternehmens über die neue URL.
Testwiederherstellung (Failback)
Das Failback ist einfacher zu steuern und kann in einem Wartungsfenster ausgeführt werden. Dieser Plan kann einige oder alle der folgenden Punkte umfassen:
- Erhalten Sie eine Bestätigung, dass die primäre Region wiederhergestellt wurde.
- Deaktivieren Sie Pools und Cluster in der sekundären Region, damit die Verarbeitung neuer Daten nicht gestartet wird.
- Synchronisieren Sie alle neuen oder geänderten Ressourcen im sekundären Arbeitsbereich mit der primären Bereitstellung. Abhängig vom Entwurf Ihrer Failoverskripts können Sie möglicherweise die gleichen Skripts ausführen, um die Objekte aus der sekundären Region (Notfallwiederherstellung) mit der primären Region (Produktionsregion) zu synchronisieren.
- Synchronisieren Sie alle neuen Datenupdates mit der primären Bereitstellung. Sie können die Überwachungspfade von Protokollen und Delta-Tabellen verwenden, um keinen Datenverlust zu gewährleisten.
- Fahren Sie alle Workloads in der Notfallwiederherstellungsregion herunter.
- Ändern Sie die URL der Aufträge und Benutzer in die primäre Region.
- Führen Sie Tests aus, um sicherzustellen, dass die Plattform auf dem neuesten Stand ist.
- Starten Sie relevante Pools (oder erhöhen Sie
min_idle_instancesauf eine relevante Zahl). - Starten Sie relevante Cluster (falls sie nicht beendet werden).
- Ändern Sie die gleichzeitige Ausführung für Aufträge und führen Sie relevante Aufträge aus. Das können einmalige Ausführungen oder regelmäßige Ausführungen sein.
- Richten Sie Ihre sekundäre Region bei Bedarf erneut für die zukünftige Notfallwiederherstellung ein.
Automatisierungsskripts, Beispiele und Prototypen
Automatisierungsskripts, die sie für Ihre Notfallwiederherstellungsprojekte berücksichtigen sollten:
- Databricks empfiehlt die Verwendung des Databricks Terraform-Anbieters, um ihren eigenen Synchronisierungsprozess zu entwickeln.
- Unter Databricks-Arbeitsbereichsmigrationstools finden Sie Beispiel- und Prototypskripts. Zusätzlich zu Azure Databricks-Objekten replizieren Sie alle relevanten Azure Data Factory Pipelines, sodass sie auf einen verknüpften Dienst verweisen, der dem sekundären Arbeitsbereich zugeordnet ist.
- Das Databricks Sync-Projekt (DBSync-Projekt) ist ein Objektsynchronisierungstool, das Databricks-Arbeitsbereiche sichern, wiederherstellen und synchronisieren kann.