Konfigurieren des AI Gateway auf Modellbereitstellungsendpunkten
In diesem Artikel wird beschrieben, wie Sie das Mosaic AI Gateway auf einem Modellbereitstellungsendpunkt konfigurieren.
Anforderungen
- Ein Databricks-Arbeitsbereich in einer Region mit Unterstützung für externe Modelle oder in einer Region mit Unterstützung für bereitgestellten Durchsatz
- Ein Modell, das Endpunkt bedient.
- Um einen Endpunkt für externe Modelle zu erstellen, führen Sie die Schritte 1 und 2 von Erstellen eines externen Modells für Endpunkteaus.
- Informationen zum Erstellen eines Endpunkts für den bereitgestellten Durchsatz finden Sie unter Foundation Model-APIs für bereitgestellten Durchsatz.
Konfigurieren des KI-Gateways mithilfe der Benutzeroberfläche
In diesem Abschnitt wird gezeigt, wie Sie das KI-Gateway während der Erstellung des Endpunkts mithilfe der Benutzeroberfläche zur Bereitstellung konfigurieren. Wenn Sie dies lieber programmgesteuert ausführen möchten, lesen Sie das Beispiel "Notizbuch".
Im Abschnitt AI Gateway auf der Endpunkterstellungsseite können Sie die AI-Gateway-Funktionen individuell konfigurieren. Weitere Informationen dazu, welche Features auf Endpunkten, die externe Modelle bereitstellen, und auf Endpunkten für bereitgestellten Durchsatz verfügbar sind, finden Sie unter Unterstützte Features.
| Funktion | Vorgehensweise zum Aktivieren | Details |
|---|---|---|
| Nutzungsverfolgung | Wählen Sie Nutzungsverfolgung aktivieren aus, um die Nachverfolgung und Überwachung von Datennutzungsmetriken zu aktivieren. | – Unity Catalog muss aktiviert sein. – Kontoadministratoren müssen das Systemtabellenschema für die Bereitstellung aktivieren, bevor sie die Systemtabellen verwenden: system.serving.endpoint_usage, womit die Tokenanzahl für jede Anforderung an den Endpunkt erfasst wird, und system.serving.served_entities, womit Metadaten für jedes Foundation Model gespeichert wird.– Siehe Tabellenschemata der Nutzungsverfolgung – Nur Kontoadministratoren verfügen über die Berechtigung zum Anzeigen oder Abfragen der served_entities-Tabelle oder der endpoint_usage-Tabelle, obwohl der Benutzer, der den Endpunkt verwaltet, die Nutzungsverfolgung aktivieren muss. Siehe Gewähren von Zugriff auf Systemtabellen– Die Anzahl der Eingabe- und Ausgabetoken wird als ( text_length+1)/4 geschätzt, wenn die Tokenanzahl nicht vom Modell zurückgegeben wird. |
| Nutzdatenprotokollierung | Wählen Sie Rückschlusstabellen aktivieren aus, um Anforderungen und Antworten von Ihrem Endpunkt automatisch in den von Unity Catalog verwalteten Delta-Tabellen zu protokollieren. | – Sie müssen Unity Katalog aktivieren und CREATE_TABLE-Zugriff im angegebenen Katalogschema haben.- Von KI-Gateway aktivierten Rückschlusstabellen weisen ein anderes Schema auf als Rückschlusstabellen, die für Modellbereitstellungsendpunkte erstellt wurden, die benutzerdefinierte Modelle bereitstellen. Siehe AI Gateway-fähiges Rückschlusstabellenschema. – Nutzdatenprotokollierung füllt diese Tabellen weniger als eine Stunde nach der Abfrage des Endpunkts aus. – Nutzdaten, die größer als 1 MB sind, werden nicht protokolliert. – Die Antwortnutzdaten aggregieren die Antwort aller zurückgesendeten Blöcke. – Streaming wird unterstützt. In Streamingszenarios aggregiert die Antwortpayload die Antwort der zurückgegebenen Blöcke. |
| KI-Schutzmaßnahmen (Guardrails) | Siehe Konfigurieren von KI-Schutzmaßnahmen in der Benutzeroberfläche. | – Schutzmaßnahmen verhindern, dass das Modell mit unsicheren und schädlichen Inhalten interagiert, die in Modelleingaben und -ausgaben erkannt werden. – Ausgabe-Schutzmaßnahmen werden für Einbettungsmodelle oder Streaming nicht unterstützt. |
| Ratenbegrenzungen | Sie können Ratenbegrenzungen erzwingen, um den Datenverkehr für Ihren Endpunkt pro Benutzer und pro Endpunkt zu verwalten. | – Ratenbegrenzungen sind als Abfragen pro Minute (QPM) definiert. – Der Standardwert ist keine Begrenzung pro Benutzer und pro Endpunkt. |
| Routing von Datenverkehr | Informationen zum Konfigurieren des Datenverkehrsrouting auf Ihrem Endpunkt finden Sie unter Bereitstellen mehrerer externer Modelle an einen Endpunkt. |
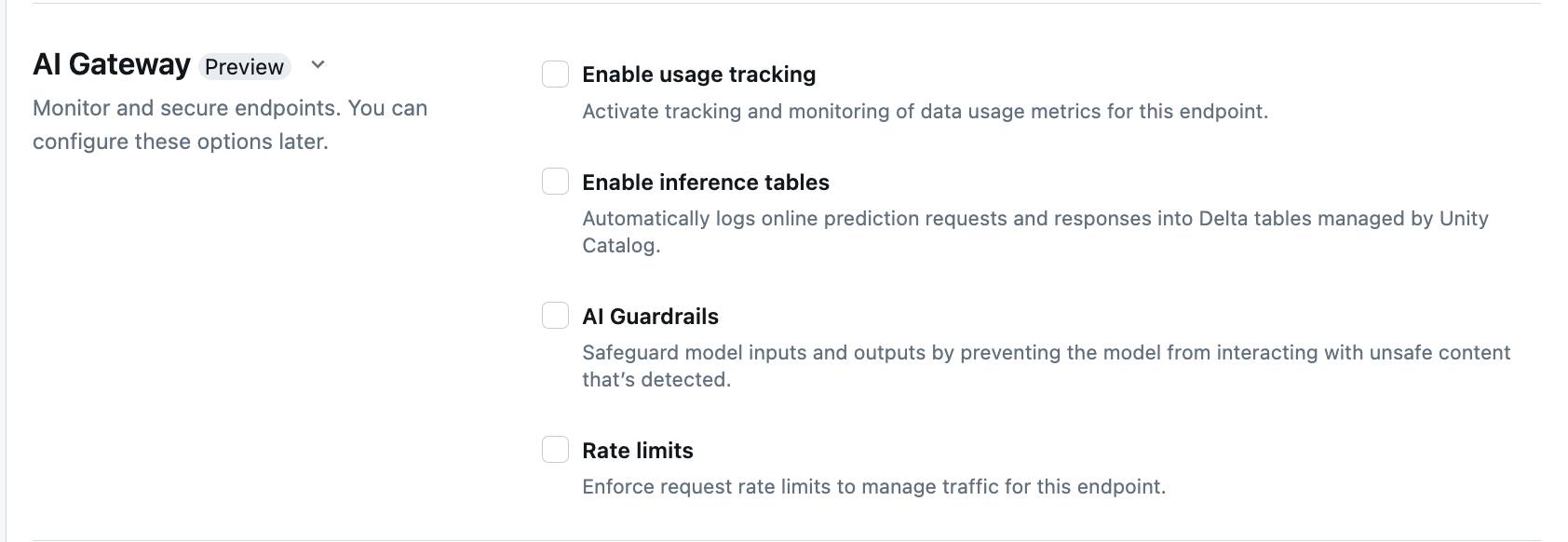
Konfigurieren von KI-Schutzmaßnahmen in der Benutzeroberfläche
In der folgenden Tabelle wird gezeigt, wie unterstützte Schutzmaßnahmen konfiguriert werden.
| Schutzmaßnahme | Vorgehensweise zum Aktivieren | Details |
|---|---|---|
| Sicherheit | Wählen Sie Sicherheit aus, um Schutzmaßnahmen zu ermöglichen, die verhindern, dass Ihr Modell mit unsicheren und schädlichen Inhalten interagiert. | |
| Erkennung personenbezogener Endbenutzerinformationen (Personally Identifiable Information, PII) | Wählen Sie PII-Erkennung aus, um PII-Daten wie Namen, Adressen und Kreditkartennummern zu erkennen. | |
| Gültige Themen | Sie können Themen direkt in dieses Feld eingeben. Wenn Sie mehrere Einträge haben, müssen Sie nach jedem Thema die Eingabetaste drücken. Alternativ können Sie eine .csv-Datei oder eine .txt-Datei hochladen. |
Es können bis zu 50 gültige Themen können angegeben werden. Jedes einzelne darf nicht länger als 100 Zeichen sein. |
| Ungültige Schlüsselwörter | Sie können Themen direkt in dieses Feld eingeben. Wenn Sie mehrere Einträge haben, müssen Sie nach jedem Thema die Eingabetaste drücken. Alternativ können Sie eine .csv-Datei oder eine .txt-Datei hochladen. |
Es können bis zu 50 ungültige Schlüsselwörter angegeben werden. Die Länge des Schlüsselworts darf 100 Zeichen nicht überschreiten. |
Tabellenschemata der Nutzungsverfolgung
Die system.serving.served_entities-Systemtabelle für Nutzungsverfolgung verwendet das folgende Schema:
| Spaltenname | Beschreibung | type |
|---|---|---|
served_entity_id |
Die eindeutige ID der bereitgestellten Entität | STRING |
account_id |
Die Debitorenkontokennung für Delta Sharing. | STRING |
workspace_id |
Die Kundenarbeitsbereichs-ID des Bereitstellungsendpunkts. | STRING |
created_by |
Die ID des Erstellers. | STRING |
endpoint_name |
Der Name des Bereitstellungsendpunkts. | STRING |
endpoint_id |
Die eindeutige ID des Bereitstellungsendpunkts. | STRING |
served_entity_name |
Der Name der bereitgestellten Entität. | STRING |
entity_type |
Typ der Entität, die bedient wird. Kann FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODEL oder CUSTOM_MODEL sein. |
STRING |
entity_name |
Der zugrunde liegende Name der Entität. Unterscheidet sich von served_entity_name, welches ein vom Benutzer bereitgestellter Name ist. entity_name ist beispielsweise der Name des Unity Catalog-Modells. |
STRING |
entity_version |
Die Version der bereitgestellten Entität. | STRING |
endpoint_config_version |
Die Version der Endpunktkonfiguration. | INT |
task |
Der Aufgabentyp. Kann llm/v1/chat, llm/v1/completions oder llm/v1/embeddings sein. |
STRING |
external_model_config |
Konfigurationen für externe Modelle. Beispiel: {Provider: OpenAI} |
STRUCT |
foundation_model_config |
Konfigurationen für Basismodelle. Beispiel: {min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
STRUCT |
custom_model_config |
Konfigurationen für benutzerdefinierte Modelle. Beispiel: { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
Konfigurationen für Featurespezifikationen. Beispiel: { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
Zeitstempel der Änderung für die bereitgestellte Entität. | timestamp |
endpoint_delete_time |
Zeitstempel des Löschens der Entität. Der Endpunkt ist der Container für die bereitgestellte Entität. Nachdem der Endpunkt gelöscht wurde, wird auch die bereitgestellte Entität gelöscht. | timestamp |
Die system.serving.endpoint_usage-Systemtabelle für Nutzungsverfolgung verwendet das folgende Schema:
| Spaltenname | Beschreibung | type |
|---|---|---|
account_id |
Die Debitorenkontokennung. | STRING |
workspace_id |
Die Kundenarbeitsbereichs-ID des Bereitstellungsendpunkts. | STRING |
client_request_id |
Der vom Benutzer angegebene Anforderungsbezeichner, der im Anforderungstext des Modells angegeben werden kann. | STRING |
databricks_request_id |
Ein von Azure Databricks generierter Anforderungsbezeichner, der an alle Modellbereitstellungsanforderungen angefügt ist | STRING |
requester |
Die ID des Benutzer- oder Dienstprinzipals, dessen Berechtigungen für die Aufrufanforderung des Bereitstellungsendpunkts verwendet werden. | STRING |
status_code |
Der HTTP-Statuscode, der vom Modell zurückgegeben wurde | INTEGER |
request_time |
Der Zeitstempel, zu dem die Anforderung eingegangen ist. | timestamp |
input_token_count |
Die Tokenanzahl der Eingabe. | LONG |
output_token_count |
Die Tokenanzahl der Ausgabe. | LONG |
input_character_count |
Die Zeichenanzahl der Eingabezeichenfolge oder der Eingabeaufforderung. | LONG |
output_character_count |
Die Zeichenanzahl der Ausgabezeichenfolge der Antwort. | LONG |
usage_context |
Der vom Benutzer bereitgestellte Zuordnung mit Bezeichnern des Endbenutzers oder der Kundenanwendung, die den Anruf an den Endpunkt tätigt. Siehe Weitere Definition der Verwendung mit usage_context.. | MAP |
request_streaming |
Zeigt an, ob sich die Anforderung im Streammodus befindet. | BOOLEAN |
served_entity_id |
Die eindeutige ID, die zum Verknüpfen mit der system.serving.served_entities Dimensionstabelle verwendet wird, um Informationen über den Endpunkt und die bereitgestellte Entität abzufragen. |
STRING |
Weitere Definition der Nutzung mit usage_context
Wenn Sie ein externes Modell mit aktivierter Verwendungsnachverfolgung abfragen, können Sie den usage_context-Parameter mit Typ Map[String, String] angeben. Die Zuordnung des Verwendungskontexts wird in der Tabelle zur Verwendungsnachverfolgung in der usage_context-Spalte angezeigt. Die usage_context Kartengröße darf 10 KiB nicht überschreiten.
Kontoadministratoren können unterschiedliche Zeilen basierend auf dem Verwendungskontext aggregieren, um Einblicke zu erhalten und diese Informationen mit den Informationen in der Nutzlastprotokollierungstabelle zu verknüpfen. Sie können z. B. end_user_to_charge zu usage_context für die Nachverfolgung der Kostenzuordnung für Endbenutzer hinzufügen.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Aktualisieren von AI Gateway-Funktionen auf Endpunkten
Sie können AI Gateway-Funktionen auf Modellbereitstellungsendpunkten aktualisieren, für die sie zuvor aktiviert waren, und Endpunkte, die nicht aktiviert waren. Aktualisierungen der AI Gateway-Konfigurationen werden innerhalb von 20 bis 40 Sekunden durchgeführt, Aktualisierungen der Ratenbegrenzung können jedoch bis zu 60 Sekunden dauern.
Im Folgenden wird gezeigt, wie Sie die AI Gateway-Funktionen auf einem Modellbereitstellungsendpunkt mithilfe der Serving-Benutzeroberfläche aktualisieren.
Im Abschnitt Gateway der Endpunktseite können Sie sehen, welche Funktionen aktiviert sind. Um diese Funktionen zu aktualisieren, klicken Sie auf AI Gateway bearbeiten.

Notebookbeispiel
Das folgende Notebook zeigt, wie Sie die Funktionen von Databricks Mosaic AI Gateway programmgesteuert aktivieren und nutzen können, um Modelle von Anbietern zu verwalten und zu steuern. Details zur REST-API finden Sie im Folgenden: