Streamverarbeitung mit Apache Kafka und Azure Databricks
In diesem Artikel wird beschrieben, wie Sie Apache Kafka entweder als Quelle oder als Senke verwenden können, wenn Sie Workloads für strukturiertes Streaming in Azure Databricks ausführen.
Mehr über Kafka finden Sie in der Kafka-Dokumentation.
Lesen von Daten aus Kafka
Im Folgenden finden Sie ein Beispiel für einen Streaming-Lesevorgang aus Kafka:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
Azure Databricks unterstützt auch die Semantik für Batchlesen für Kafka-Datenquellen, wie im folgenden Beispiel gezeigt:
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
Für das inkrementelle Batchladen empfiehlt Databricks die Verwendung von Kafka mit Trigger.AvailableNow. Weitere Informationen finden Sie unter Konfigurieren der inkrementellen Batchverarbeitung.
In Databricks Runtime 13.3 LTS und höher bietet Azure Databricks eine SQL-Funktion zum Lesen von Kafka-Daten. Streaming mit SQL wird nur in Delta Live Tables oder mit Streamingtabellen in Databricks SQL unterstützt. Siehe Tabellenwertfunktion „read_kafka“
Konfigurieren des strukturierter Kafka Streaming-Readers
Azure Databricks stellt das kafka-Schlüsselwort als Datenformat bereit, um Verbindungen mit Kafka 0.10+ zu konfigurieren.
Im Folgenden sind die häufigsten Konfigurationen für Kafka aufgeführt:
Die zu abonnierenden Themen können auf vielfältige Weise angegeben werden. Sie sollten nur einen der folgenden Parameter angeben:
| Option | Wert | BESCHREIBUNG |
|---|---|---|
| subscribe | Eine durch Trennzeichen getrennte Liste von Themen. | Die zu abonnierende Themenliste. |
| subscribePattern | Java RegEx-Zeichenfolge. | Das zum Abonnieren von Themen verwendete Muster. |
| zuweisen | JSON-Zeichenfolge {"topicA":[0,1],"topic":[2,4]}. |
Bestimmte zu verwendende Themenpartitionen. |
Weitere wichtige Konfigurationen:
| Option | Wert | Standardwert | BESCHREIBUNG |
|---|---|---|---|
| kafka.bootstrap.servers | Durch Trennzeichen getrennte Liste von Host:Port. | empty | [Erforderlich] Die bootstrap.servers-Konfiguration von Kafka. Wenn Sie feststellen, dass keine Daten von Kafka vorhanden sind, überprüfen Sie zunächst die Brokeradressliste. Wenn die Brokeradressliste falsch ist, treten möglicherweise keine Fehler auf. Dies liegt daran, dass der Kafka-Client davon ausgeht, dass die Broker irgendwann verfügbar sein werden, und im Fall von Netzwerkfehlern immer wieder einen erneuten Versuch unternimmt. |
| failOnDataLoss | true oder false |
true |
[Optional] Gibt an, ob die Abfrage einen Fehler auslösen soll, wenn möglicherweise Daten verloren gegangen sind. Abfragen können aufgrund vieler Szenarien (z. B. gelöschte Themen, vor der Verarbeitung abgeschnittene Themen usw.) beim Lesen von Daten aus Kafka dauerhaft einen Fehler auslösen. Es wird versucht abzuschätzen, ob Daten möglicherweise verloren gegangen sind oder nicht. Manchmal kann dies zu falschen Alarmen führen. Legen Sie diese Option auf false fest, wenn sie nicht wie erwartet funktioniert oder die Abfrage trotz Datenverlust weiter verarbeitet werden soll. |
| minPartitions | Ganze Zahl >= 0, 0 = deaktiviert. | 0 (deaktiviert) | [Optional] Mindestanzahl von Partitionen, die aus Kafka gelesen werden sollen. Sie können Spark mithilfe der Option minPartitions so konfigurieren, dass eine beliebige Mindestanzahl von Partitionen verwendet wird, um aus Kafka zu lesen. Normalerweise weist Spark eine 1:1-Zuordnung zwischen Kafka-Themenpartitionen und Spark-Partitionen auf, die aus Kafka gelesen werden. Wenn Sie die Option minPartitions auf einen höheren Wert als Ihre Kafka-Themenpartitionen festlegen, unterteilt Spark große Kafka-Partitionen in kleinere Teile. Diese Option kann in Zeiten von Spitzenlasten, Datenschiefe und bei Rückstand des Datenstroms festgelegt werden, um die Verarbeitungsrate zu erhöhen. Dafür müssen die Kafka-Consumer bei jedem Trigger initialisiert werden, was sich auf die Leistung auswirken kann, wenn Sie SSL beim Herstellen einer Verbindung mit Kafka verwenden. |
| kafka.group.id | Eine Kafka-Consumergruppen-ID. | nicht festgelegt | [Optional] Beim Lesen aus Kafka zu verwendende Gruppen-ID. Verwenden Sie diese Option mit Vorsicht. Standardmäßig generiert jede Abfrage eine eindeutige Gruppen-ID zum Lesen von Daten. Dadurch wird sichergestellt, dass jede Abfrage über eine eigene Consumergruppe verfügt, die nicht durch andere Consumer gestört wird und daher alle Partitionen der abonnierten Themen lesen kann. In einigen Szenarien (z. B. bei der gruppenbasierten Autorisierung von Kafka) sollten Sie bestimmte autorisierte Gruppen-IDs zum Lesen von Daten verwenden. Sie können die Gruppen-ID optional festlegen. Gehen Sie dabei jedoch äußerst vorsichtig vor, da dies zu unerwartetem Verhalten führen kann. – Gleichzeitig ausgeführte Abfragen (Batch und Streaming) mit derselben Gruppen-ID beeinträchtigen sich wahrscheinlich gegenseitig, sodass jede Abfrage nur einen Teil der Daten liest. – Dies kann auch auftreten, wenn Abfragen in schneller Folge gestartet/neu gestartet werden. Zum Minimieren solcher Probleme legen Sie die Kafka-Consumerkonfiguration session.timeout.ms auf einen sehr kleinen Wert fest. |
| startingOffsets | earliest, latest | latest | [Optional] Der Startpunkt einer Abfrage – entweder „earliest“ (also ab den frühestmöglichen Offsets) oder eine JSON-Zeichenfolge, die einen Startversatz für jede Themenpartition (TopicPartition) angibt. In der JSON-Zeichenfolge kann mit dem Offset „-2“ auf den frühestmöglichen und mit „-1“ auf den spätestmöglichen Offset verwiesen werden. Hinweis: Bei Batchabfragen ist „latest“ nicht zulässig (weder implizit noch in Form von „-1“ in JSON). Bei Streamingabfragen gilt das nur, wenn eine neue Abfrage gestartet wird. Außerdem gilt: Wenn die Abfrage fortgesetzt wird, wird sie an der Stelle fortgesetzt, an der sie unterbrochen wurde. Bei einer Abfrage neu entdeckte Partitionen beginnen beim frühestmöglichen Startpunkt. |
Informationen zu weiteren optionalen Konfigurationen finden Sie im Integrationsleitfaden für strukturiertes Streaming und Kafka.
Schema für Kafka-Datensätze
Das Schema der Kafka-Datensätze lautet:
| Column | Type |
|---|---|
| key | binary |
| value | binary |
| topic | Zeichenfolge |
| partition | int |
| offset | lang |
| timestamp | lang |
| timestampType | int |
key und value werden mit ByteArrayDeserializer immer als Bytearrays deserialisiert. Verwenden Sie DataFrame-Vorgänge (z. B. cast("string")), um die Schlüssel und Werte explizit zu deserialisieren.
Schreiben von Daten in Kafka
Im Folgenden finden Sie ein Beispiel für einen Streaming-Schreibvorgang auf Kafka:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Azure Databricks unterstützt auch die Semantik für Batchlesen für Kafka-Datenquellen, wie im folgenden Beispiel gezeigt:
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Konfigurieren des strukturierter Kafka Streaming-Writers
Wichtig
In Databricks Runtime 13.3 LTS und höher ist eine neuere Version der kafka-clients-Bibliothek enthalten, die standardmäßig idempotente Schreibvorgänge ermöglicht. Wenn eine Kafka-Senke Version 2.8.0 oder früher mit konfigurierten ACLs, aber ohne aktivierten IDEMPOTENT_WRITE verwendet, löst der Schreibvorgang die Fehlermeldung org.apache.kafka.common.KafkaException: Cannot execute transactional method because we are in an error state aus.
Sie können diesen Fehler beheben, indem Sie ein Upgrade auf Kafka Version 2.8.0 oder höher durchführen oder beim Konfigurieren des Writers für strukturiertes Streaming .option(“kafka.enable.idempotence”, “false”) festlegen.
Das dem DataStreamWriter bereitgestellte Schema interagiert mit der Kafka-Senke. Sie können die folgenden Felder verwenden:
| Spaltenname | Erforderlich oder optional | Type |
|---|---|---|
key |
optional | STRING oder BINARY |
value |
required | STRING oder BINARY |
headers |
optional | ARRAY |
topic |
optional (wird ignoriert, wenn topic als Writer-Option festgelegt ist) |
STRING |
partition |
optional | INT |
Im Folgenden finden Sie allgemeine Optionen, die beim Schreiben in Kafka festgelegt werden:
| Option | Wert | Standardwert | BESCHREIBUNG |
|---|---|---|---|
kafka.boostrap.servers |
Eine kommagetrennte Liste von <host:port> |
none | [Erforderlich] Die bootstrap.servers-Konfiguration von Kafka. |
topic |
STRING |
nicht festgelegt | [Optional] Legt das Thema für alle Zeilen fest, die geschrieben werden sollen. Diese Option überschreibt jede Themenspalte, die in den Daten vorhanden ist. |
includeHeaders |
BOOLEAN |
false |
[Optional] Gibt an, ob die Kafka-Header in die Zeile eingeschlossen werden sollen. |
Informationen zu weiteren optionalen Konfigurationen finden Sie im Integrationsleitfaden für strukturiertes Streaming und Kafka.
Abrufen von Kafka-Metriken
Mit den Metriken avgOffsetsBehindLatest, maxOffsetsBehindLatest und minOffsetsBehindLatest können Sie die durchschnittliche, minimale und maximale Anzahl von Offsets, um die die Streamingabfrage hinter dem neuesten verfügbaren Offset zurückliegt, für alle abonnierten Themen abrufen. Weitere Informationen finden Sie unter Interaktives Lesen von Metriken.
Hinweis
Verfügbar in Databricks Runtime 9.1 und höher
Ermitteln Sie die geschätzte Gesamtzahl der Bytes, die der Abfrageprozess noch nicht von den abonnierten Themen verbraucht hat, indem Sie den Wert von estimatedTotalBytesBehindLatest prüfen. Diese Schätzung basiert auf den Batches, die in den letzten 300 Sekunden verarbeitet wurden. Der Zeitrahmen, auf dem die Schätzung basiert, kann geändert werden, indem die Option bytesEstimateWindowLength auf einen anderen Wert gesetzt wird. Beispielsweise kann der Wert auf 10 Minuten gesetzt werden:
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
Wenn Sie den Stream in einem Notebook ausführen, können Sie diese Metriken auf der Registerkarte Rohdaten im Dashboard für den Fortschritt der Streamingabfrage sehen:
{
"sources" : [ {
"description" : "KafkaV2[Subscribe[topic]]",
"metrics" : {
"avgOffsetsBehindLatest" : "4.0",
"maxOffsetsBehindLatest" : "4",
"minOffsetsBehindLatest" : "4",
"estimatedTotalBytesBehindLatest" : "80.0"
},
} ]
}
Verwenden von SSL zum Verbinden von Azure Databricks mit Kafka
Befolgen Sie zum Aktivieren von SSL-Verbindungen mit Kafka die Anweisungen in der Confluent-Dokumentation Verschlüsselung und Authentifizierung mit SSL. Sie können die dort beschriebenen Konfigurationen mit dem Präfix kafka. als Optionen angeben. Beispielsweise geben Sie den Vertrauensspeicherort in der Eigenschaft kafka.ssl.truststore.location an.
Databricks empfiehlt Ihnen Folgendes:
- Speichern Sie Ihre Zertifikate im Cloudobjektspeicher. Sie können den Zugriff auf die Zertifikate nur auf Cluster beschränken, die auf Kafka zugreifen können. Weitere Informationen finden Sie unter Datengovernance mit Unity Catalog.
- Speichern Sie Ihre Zertifikatkennwörter als Geheimnisse in einem Geheimnisbereich.
Im folgenden Beispiel werden Objektspeicherorte und Databricks-Geheimnisse verwendet, um eine SSL-Verbindung zu aktivieren:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
Verbinden von Kafka in HDInsight mit Azure Databricks
Erstellen Sie einen Kafka-Cluster in HDInsight.
Anweisungen dazu finden Sie unter Herstellen einer Verbindung mit Kafka in HDInsight über ein virtuelles Azure-Netzwerk.
Konfigurieren Sie die Kafka-Broker so, dass sie die richtige Adresse ankündigen.
Befolgen Sie die Anweisungen unter Konfigurieren von Kafka zum Ankündigen der IP-Adresse. Wenn Sie Kafka selbst in Azure Virtual Machines verwalten, stellen Sie sicher, dass die Konfiguration von
advertised.listenersder Broker auf die interne IP-Adresse der Hosts festgelegt ist.Erstellen Sie einen Azure Databricks-Cluster.
Nehmen Sie ein Peering des Kafka-Clusters mit dem Azure Databricks-Cluster vor.
Befolgen Sie die Anweisungen unter Einrichten eines Peerings von virtuellen Netzwerken.
Dienstprinzipal-Authentifizierung mit Microsoft Entra ID und Azure Event Hubs
Azure Databricks unterstützt die Authentifizierung von Spark-Aufträgen mit Event Hubs-Diensten. Die Authentifizierung erfolgt über OAuth mit Microsoft Entra ID.

Azure Databricks unterstützt die Microsoft Entra ID-Authentifizierung mit einer Client-ID und einem Geheimnis in den folgenden Compute-Umgebungen:
- Databricks Runtime 12.2 LTS und höher auf Computeressourcen, die im Zugriffsmodus für Einzelbenutzer*innen konfiguriert sind.
- Databricks Runtime 14.3 LTS und höher auf Computeressourcen, die im Modus für den gemeinsamen Zugriff konfiguriert sind.
- Delta Live Tables-Pipelines, die ohne Unity Catalog konfiguriert sind.
Azure Databricks unterstützt die Microsoft Entra ID-Authentifizierung nicht mit einem Zertifikat in einer Compute-Umgebung oder in Delta Live Tables-Pipelines, die mit Unity Catalog konfiguriert sind.
Diese Authentifizierung funktioniert nicht für freigegebene Cluster oder für Unity Catalog Delta Live Tables.
Konfigurieren des Kafka-Connectors für strukturiertes Streaming
Um die Authentifizierung mit Microsoft Entra ID durchzuführen, benötigen Sie die folgenden Werte:
Eine Mandanten-ID. Diese finden Sie auf der Registerkarte der Microsoft Entra ID-Dienste.
Eine Client-ID (auch als Anwendungs-ID bezeichnet).
Einen geheimen Clientschlüssel. Sobald Sie diesen haben, sollten Sie ihn als Geheimnis zu Ihrem Databricks-Arbeitsbereich hinzufügen. Informationen zum Hinzufügen dieses Geheimnisses finden Sie unter Verwaltung von Geheimnissen.
Ein EventHubs-Thema. Eine Liste der Themen finden Sie im Abschnitt Event Hubs unter dem Abschnitt Entitäten auf einer bestimmten Seite des Event Hubs-Namespace. Um mit mehreren Themen zu arbeiten, können Sie die IAM-Rolle auf Event Hubs-Ebene festlegen.
Einen EventHubs-Server. Diesen finden Sie auf der Übersichtsseite Ihres bestimmten Event Hubs-Namespace:
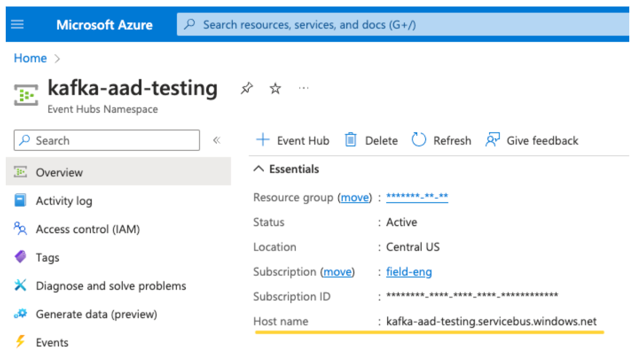
Um Entra ID zu verwenden, müssen wir Kafka außerdem anweisen, den OAuth-SASL-Mechanismus zu verwenden (SASL ist ein allgemeines Protokoll, und OAuth ist eine Art von SASL-„Mechanismus“):
kafka.security.protocolsollteSASL_SSLentsprechenkafka.sasl.mechanismsollteOAUTHBEARERentsprechenkafka.sasl.login.callback.handler.classsollte ein vollqualifizierter Name der Java-Klasse mit dem Wertkafkashadedfür den Anmelderückrufhandler unserer schattierten Kafka-Klasse sein. Das folgende Beispiel zeigt die genaue Klasse.
Beispiel
Als Nächstes sehen wir uns ein laufendes Beispiel an:
Python
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Scala
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
Behandeln potenzieller Fehler
Streaming-Optionen werden nicht unterstützt.
Wenn Sie versuchen, dieses Authentifizierungsverfahren in einer Delta Live Tables-Pipeline zu verwenden, die mit Unity Catalog konfiguriert ist, wird möglicherweise die folgende Fehlermeldung angezeigt:

Verwenden Sie eine unterstützte Computekonfiguration, um diesen Fehler zu beheben. Weitre Informationen finden Sie unter Dienstprinzipal-Authentifizierung mit Microsoft Entra ID und Azure Event Hubs.
Fehler beim Erstellen eines neuen
KafkaAdminClient.Dies ist ein interner Fehler, der von Kafka ausgelöst wird, wenn eine der folgenden Authentifizierungsoptionen falsch ist:
- Client-ID (auch als Anwendungs-ID bezeichnet)
- Mandanten-ID
- EventHubs-Server
Um den Fehler zu beheben, überprüfen Sie, ob die Werte für diese Optionen korrekt sind.
Außerdem kann dieser Fehler auftreten, wenn Sie die Konfigurationsoptionen ändern, die im Beispiel standardmäßig vorgesehen sind (und die Sie nicht ändern sollten), wie beispielsweise
kafka.security.protocol.Es werden keine Datensätze zurückgegeben
Wenn Sie versuchen, Ihren DataFrame anzuzeigen oder zu verarbeiten, aber keine Ergebnisse erhalten, wird in der Benutzeroberfläche Folgendes angezeigt.

Diese Meldung bedeutet, dass die Authentifizierung erfolgreich war, aber EventHubs keine Daten zurückgegeben hat. Einige mögliche (aber keineswegs vollständige) Gründe sind:
- Sie haben das falsche EventHubs-Thema angegeben.
- Die standardmäßige Kafka-Konfigurationsoption für
startingOffsetsistlatestund Sie erhalten derzeit keine Daten über das Thema. Sie könnenstartingOffsetstoearliestfestlegen, damit Sie mit dem Lesen von Daten starten, beginnend mit den frühesten Offsets von Kafka.