Erfassen und Anzeigen der Datenherkunft mit Unity Catalog
In diesem Artikel wird beschrieben, wie Sie die Datenherkunft mithilfe des Katalog-Explorers, der Herkunftssystemtabellen und der REST-API erfassen und visualisieren.
Sie können Unity Catalog verwenden, um die Runtime-Datenherkunft über Abfragen hinweg zu erfassen, die auf Azure Databricks ausgeführt werden. Datenherkunft wird für alle Sprachen unterstützt und wird bis auf die Spaltenebene herunter erfasst. Herkunftsdaten umfassen Notebooks, Aufträge und Dashboards, die zur Abfrage gehören. Die Herkunft kann im Katalog-Explorer nahezu in Echtzeit visualisiert und über die Herkunftssystemtabellen und die Databricks-REST-API programmgesteuert abgerufen werden.
Datenherkunft wird über alle Arbeitsbereiche hinweg aggregiert, die an einen Unity Catalog-Metastore angefügt sind. Dies bedeutet, dass die Datenherkunft, die in einem Arbeitsbereich erfasst wurde, in jedem Arbeitsbereich mit demselben Metastore sichtbar ist. Benutzer müssen über die richtigen Berechtigungen zum Anzeigen der Datenherkunftsdaten verfügen. Daten zur Datenherkunft werden 1 Jahr lang aufbewahrt.
Die folgende Abbildung ist ein Beispiel für ein Liniendiagramm. Spezifische Datenlinienfunktionen und Beispiele werden weiter unten in diesem Artikel behandelt.
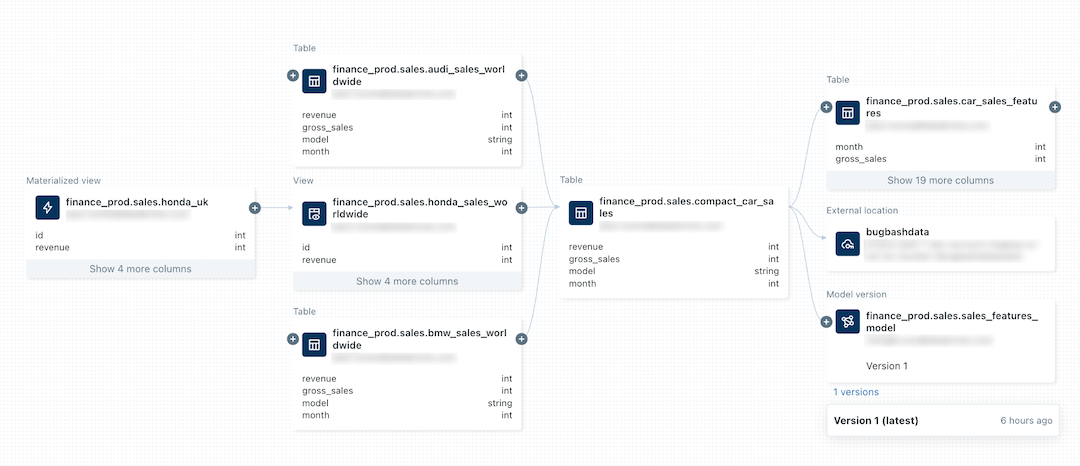
Informationen zum Nachverfolgen der Linien eines Machine Learning-Modells finden Sie unter Nachverfolgen der Datenlinie eines Modells im Unity-Katalog.
Anforderungen
Folgendes ist erforderlich, um die Datenherkunft mit Unity Catalog zu erfassen:
Ihr Arbeitsbereich muss für Unity Catalog aktiviert sein.
Tabellen müssen in einem Unity Catalog-Metastore registriert sein.
Abfragen müssen den Spark DataFrame (z. B. Spark SQL-Funktionen, die einen DataFrame zurückgeben) oder Databricks SQL-Schnittstellen verwenden. Beispiele für Databricks SQL- und PySpark-Abfragen finden Sie in den Beispielen.
Um die Datenherkunft einer Tabelle oder Ansicht anzuzeigen, müssen Benutzer über die Berechtigung
BROWSEfür den übergeordneten Katalog der Tabelle oder Ansicht verfügen. Der übergeordnete Katalog muss auch über den Arbeitsbereich zugänglich sein. Weitere Informationen finden Sie unter Einschränken des Katalogzugriffs auf bestimmte Arbeitsbereiche.Um Datenherkunftsinformationen für Notebooks, Aufträge oder Dashboards anzuzeigen, müssen Benutzer über Berechtigungen für diese Objekte verfügen, die in den Zugriffssteuerungseinstellungen des Arbeitsbereichs festgelegt sind. Siehe Datenherkunftsberechtigungen.
Um den Verlauf einer Unity Catalog-aktivierten Pipeline anzuzeigen, müssen Sie über
CAN_VIEW-Berechtigungen für die Pipeline verfügen.Lineage Tracking von Streaming zwischen Delta-Tabellen erfordert Databricks Runtime 11.3 LTS oder höher.
Die Nachverfolgung von Spalten für Delta Live Tables-Workloads erfordert Databricks Runtime 13.3 LTS oder höher.
Möglicherweise müssen Sie Ihre ausgehenden Firewallregeln aktualisieren, um die Konnektivität mit dem Event Hubs-Endpunkt auf der Azure Databricks-Steuerungsebene zu ermöglichen. Dies gilt in der Regel, wenn Ihr Azure Databricks-Arbeitsbereich in Ihrem eigenen VNet bereitgestellt wird (auch als VNet-Injektion bezeichnet). Weitere Informationen zum Abrufen des Event Hubs-Endpunkts für Ihre Arbeitsbereichsregion finden Sie unter IP-Adressen von Metastore, Artefaktblobspeicher, Systemtabellenspeicher, Protokollblobspeicher und Event Hubs-Endpunkt. Informationen zum Einrichten von benutzerdefinierten Routen (User-Defined Routes, UDR) für Azure Databricks finden Sie unter Benutzerdefinierte Routeneinstellungen für Azure Databricks.
Beispiele
Hinweis
In den folgenden Beispielen werden der Katalogname
lineage_dataund der Schemanamelineagedemoverwendet. Wenn Sie einen anderen Katalog und ein anderes Schema verwenden möchten, ändern Sie die Namen, die in den Beispielen verwendet werden.Um dieses Beispiel abzuschließen, müssen Sie über die Berechtigungen
CREATEundUSE SCHEMAfür ein Schema verfügen. Ein Metastore-Administrator, Katalogbesitzer oder Schemabesitzer kann diese Berechtigungen erteilen. Um beispielsweise allen Benutzer*innen in der Gruppe „data_engineers“ die Berechtigung zum Erstellen von Tabellen imlineagedemo-Schema imlineage_data-Katalog zu erteilen, kann ein*e Benutzer*in mit einer der oben genannten Berechtigungen oder Rollen die folgenden Abfragen ausführen:CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
Erfassen und Erkunden der Datenherkunft
So erfassen Sie die Datenherkunft:
Wechseln Sie zu Ihrer Landing Page von Azure Databricks, klicken Sie auf der Seitenleiste auf
 Neu, und wählen Sie aus dem Menü die Option Notebook aus.
Neu, und wählen Sie aus dem Menü die Option Notebook aus.Geben Sie einen Namen für das Notbook ein, und wählen Sie SQL in der Standardsprache aus.
Wählen Sie unter Cluster einen Cluster mit Zugriff auf Unity Catalog aus.
Klicken Sie auf Erstellen.
Geben Sie in der ersten Notebook-Zelle die folgenden Abfragen ein:
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menuUm die Abfragen auszuführen, klicken Sie in die Zelle und drücken Sie Umschalt+Eingabe oder klicken Sie auf
 und wählen Sie Zelle ausführen aus.
und wählen Sie Zelle ausführen aus.
So verwenden Sie den Katalog-Explorer, um die von diesen Abfragen generierte Datenherkunft anzuzeigen:
Suchen Sie im Feld Suchen in der oberen Leiste des Azure Databricks-Arbeitsbereichs nach der
lineage_data.lineagedemo.dinner-Tabelle, und wählen Sie sie aus.Wählen Sie die Registerkarte Herkunft aus. Der Herkunftsbereich wird angezeigt und zeigt zugehörige Tabellen an (in diesem Beispiel die Tabelle
menu).Wenn Sie ein interaktives Diagramm der Datenherkunft anzeigen möchten, klicken Sie auf Datenherkunftsdiagramm anzeigen. Standardmäßig wird eine Ebene im Diagramm angezeigt. Klicken Sie auf das Symbol
 auf einem Knoten, um weitere Verbindungen anzuzeigen, wenn sie verfügbar sind.
auf einem Knoten, um weitere Verbindungen anzuzeigen, wenn sie verfügbar sind.Klicken Sie auf einen Pfeil, der Knoten im Datenherkunftsgraph verbindet, um das Panel Datenherkunftsverbindung zu öffnen. Das Panel Datenherkunftsverbindung zeigt Details zur Verbindung, darunter Quell- und Zieltabellen, Notebooks und Aufträge.
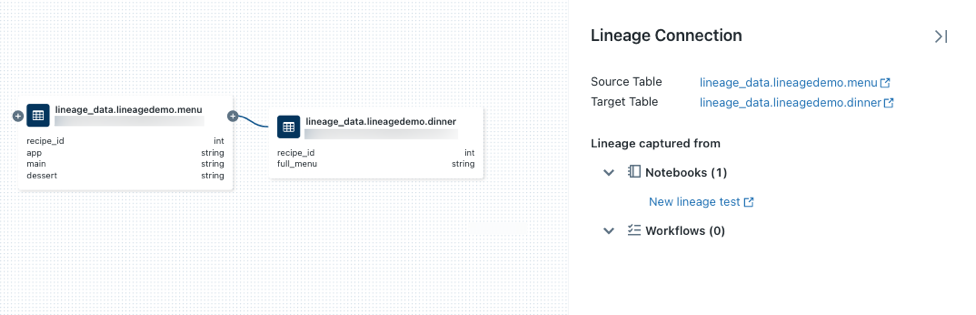
Wenn Sie das mit der
dinner-Tabelle verknüpfte Notizbuch anzeigen möchten, wählen Sie das Notizbuch im Bereich Datenherkunftsverbindung aus oder schließen Sie das Datenherkunftsdiagramm und klicken Sie auf Notebooks. Um das Notebook in einer neuen Registerkarte zu öffnen, klicken Sie auf den Namen des Notebooks.Klicken Sie zum Anzeigen der Datenherkunft auf Spaltenebene auf eine Spalte im Graph, um Links zu zugehörigen Spalten anzuzeigen. Wenn Sie beispielsweise auf die Spalte „full_menu“ klicken, werden die Upstreamspalten angezeigt, von denen die Spalte abgeleitet wurde:
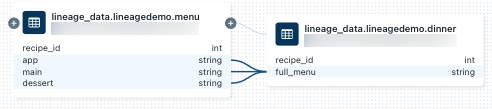
So zeigen Sie die Linien mit einer anderen Sprache an, z. B. in Python:
Öffnen Sie das zuvor erstellte Notebook, erstellen Sie eine neue Zelle und geben Sie den folgenden Python-Code ein:
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")Führen Sie die Zelle aus, indem Sie in die Zelle klicken und Umschalt+Eingabe drücken oder indem Sie auf
klicken und Zelle ausführen auswählen.Suchen Sie im Feld Suchen in der oberen Leiste des Azure Databricks-Arbeitsbereichs nach der
lineage_data.lineagedemo.price-Tabelle, und wählen Sie sie aus.Wechseln Sie zur Registerkarte Datenherkunft, und klicken Sie auf Datenherkunftsgraph anzeigen. Klicken Sie auf das Symbol
, um die von den Abfragen generierte Datenherkunft zu untersuchen.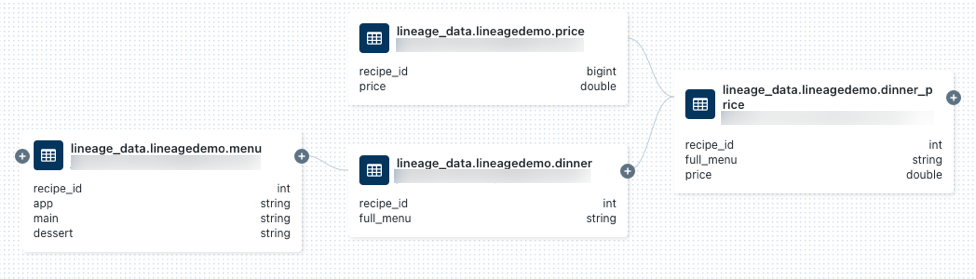
Klicken Sie auf einen Pfeil, der Knoten im Datenherkunftsgraph verbindet, um das Panel Datenherkunftsverbindung zu öffnen. Das Panel Datenherkunftsverbindung zeigt Details zur Verbindung, darunter Quell- und Zieltabellen, Notebooks und Aufträge.
Erfassen und Anzeigen der Workflow-Herkunft
Die Datenherkunft wird auch für jeden Workflow erfasst, der in Unity Catalog liest oder schreibt. So zeigen Sie die Datenherkunft für einen Azure Databricks-Workflow an:
Klicken Sie auf der Seitenleiste auf
Neu, und wählen Sie aus dem Menü die Option Notebook aus.Geben Sie einen Namen für das Notbook ein, und wählen Sie SQL in der Standardsprache aus.
Klicken Sie auf Erstellen.
Geben Sie in der ersten Notebook-Zelle die folgenden Abfragen ein:
SELECT * FROM lineage_data.lineagedemo.menuKlicken Sie auf Planen in der oberen Leiste. Wählen Sie im Dialogfeld „Planen“ die Option Manuell aus, wählen Sie ein Cluster mit Zugriff auf Unity Catalog aus, und klicken Sie auf Erstellen.
Klicken Sie auf Jetzt ausführen.
Suchen Sie im Feld Suchen in der oberen Leiste des Azure Databricks-Arbeitsbereichs nach der
lineage_data.lineagedemo.menu-Tabelle, und wählen Sie sie aus.Klicken Sie auf der Registerkarte Datenherkunft auf Workflows, und wählen Sie die Registerkarte Downstream aus. Der Auftragsname wird unter Auftragsname als Consumer der
menu-Tabelle angezeigt.
Erfassen und Anzeigen der Dashboard-Datenherkunft
So erstellen Sie ein Dashboard und zeigen dessen Datenherkunft an:
Wechseln Sie zu Ihrer Azure Databricks-Startseite, und öffnen Sie den Katalog-Explorer, indem Sie in der Randleiste auf Katalog klicken.
Klicken Sie auf den Katalognamen, dann auf lineagedemo, und wählen Sie die
menu-Tabelle aus. Sie können auch das Feld Suchen in der oberen Leiste verwenden, um nach dermenu-Tabelle zu suchen.Klicken Sie auf Auf einem Dashboard öffnen.
Wählen Sie die Spalten aus, die Sie dem Dashboard hinzufügen möchten, und klicken Sie auf Erstellen.
Veröffentlichen Sie das Dashboard.
Nur veröffentlichte Dashboards werden in der Datenherkunft nachverfolgt.
Suchen Sie im Feld Suchen in der oberen Leiste nach der
lineage_data.lineagedemo.menu-Tabelle, und wählen Sie sie aus.Klicken Sie auf der Registerkarte Datenherkunft auf Dashboards. Das Dashboard wird unter Dashboardname als Consumer der Menütabelle angezeigt.
Herkunftsberechtigungen
Datenherkunftsdiagramme haben das gleiche Berechtigungsmodell wie Unity Catalog. Wenn ein Benutzer nicht über die Berechtigungen BROWSE oder SELECT für eine Tabelle verfügt, kann er die Datenherkunft nicht erkunden. Darüber hinaus können Benutzer nur Notebooks, Aufträge und Dashboards einsehen, für die sie über Anzeigeberechtigungen verfügen. Wenn Sie beispielsweise die folgenden Befehle für einen Nicht-Administratorbenutzer userA ausführen:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Wenn userA das Liniendiagramm für die Tabelle lineage_data.lineagedemo.menu anzeigt, wird die Tabelle menu angezeigt. Sie können keine Informationen zu zugehörigen Tabellen anzeigen, z. B. die nachgeschaltete lineage_data.lineagedemo.dinner Tabelle. Die dinner-Tabelle wird als masked-Knoten in der Anzeige für userA angezeigt und userA kann das Diagramm nicht ausklappen, um nachgelagerte Tabellen aus Tabellen anzuzeigen, für er keine Zugriffsberechtigung hat.
Wenn Sie den folgenden Befehl ausführen, um einem Nicht-Administrator-Benutzer userB die Berechtigung BROWSE zu erteilen:
GRANT BROWSE on lineage_data to `userA@company.com`;
userB kann nun das Liniendiagramm für eine beliebige Tabelle im Schema lineage_dataanzeigen.
Weitere Informationen zum Verwalten des Zugriffs auf sicherungsfähige Objekte in Unity Catalog finden Sie unter Verwalten von Berechtigungen in Unity Catalog. Weitere Informationen zum Verwalten des Zugriffs auf Arbeitsbereichsobjekte wie Notebooks, Aufträge und Dashboards finden Sie unter Zugriffssteuerungslisten.
Löschen von Datenherkunftsdaten
Warnung
Die folgenden Anweisungen löschen alle Objekte, die im Unity Catalog gespeichert sind. Verwenden Sie diese Anweisungen nur bei Bedarf. Beispielsweise, um Compliance-Anforderungen zu erfüllen.
Um Datenherkunftsdaten zu löschen, müssen Sie den Metastore löschen, der die Unity Catalog-Objekte verwaltet. Weitere Informationen zum Löschen des Metastores finden Sie unter Löschen eines Metastores. Daten werden innerhalb von 90 Tagen gelöscht.
Abfragen von Herkunftsdaten mithilfe von Systemtabellen
Sie können die Herkunftssystemtabellen verwenden, um Herkunftsdaten programmgesteuert abzufragen. Ausführliche Anweisungen finden Sie unter Überwachen der Nutzung mit Systemtabellen und Referenz zu Herkunftssystemtabellen.
Wenn sich Ihr Arbeitsbereich in einer Region befindet, in der Herkunftssystemtabellen nicht unterstützt werden, können Sie alternativ die REST-API für Datenherkunft verwenden, um Herkunftsdaten programmgesteuert abzurufen.
Abrufen der Herkunft mithilfe der REST-API für Datenherkunft
Mit der Datenherkunfts-API können Sie die Datenherkunft von Tabellen und Spalten abrufen. Wenn sich Ihr Arbeitsbereich jedoch in einer Region befindet, die die Herkunftssystemtabellen unterstützt, sollten Sie Systemtabellenabfragen anstelle der REST-API verwenden. Systemtabellen sind eine bessere Option zum programmgesteuerten Abrufen von Herkunftsdaten. Die meisten Regionen unterstützen die Herkunftssystemtabellen.
Wichtig
Für den Zugriff auf Databricks-REST-APIs müssen Sie sich authentifizieren.
Abrufen der Tabellendatenherkunft
In diesem Beispiel wird die Datenherkunft für die dinner-Tabelle abgerufen.
Anfordern
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
Ersetzen Sie <workspace-instance>.
In diesem Beispiel wird eine NETRC-Datei verwendet.
response
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
Abrufen der Spaltendatenherkunft
In diesem Beispiel wird die Datenherkunft für die dinner-Tabelle abgerufen.
Anfordern
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
Ersetzen Sie <workspace-instance>.
In diesem Beispiel wird eine NETRC-Datei verwendet.
Antwort
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
Begrenzungen
- Da die Herkunft in einem einjährigen rollierenden Fenster berechnet wird, werden die vor mehr als einem Jahr gesammelten Linien nicht angezeigt. Wenn beispielsweise ein Auftrag oder eine Abfrage Daten aus Tabelle A liest und in Tabelle B schreibt, wird die Verknüpfung zwischen Tabelle A und Tabelle B nur ein Jahr lang angezeigt. Sie können Herkunftsdaten innerhalb des einjährigen Fensters nach Zeitraum filtern.
- Aufträge, die die
runs submit-Anforderung der Auftrags-API verwenden, sind beim Anzeigen der Datenherkunft nicht verfügbar. Die Datenherkunft auf Tabellen- und Spaltenebene wird weiterhin erfasst, wenn dieruns submit-Anforderung verwendet wird, aber der Link zur Ausführung wird nicht erfasst. - Unity Catalog erfasst so weit wie möglich die Datenherkunft auf Spaltenebene. Es gibt jedoch einige Fälle, in denen die Datenherkunft auf Spaltenebene nicht erfasst werden kann.
- Spaltenlinien werden nur unterstützt, wenn sowohl die Quelle als auch das Ziel nach Tabellenname referenziert werden (Beispiel:
select * from <catalog>.<schema>.<table>). Die Spaltenabfolge kann nicht erfasst werden, wenn die Quelle oder das Ziel durch einen Pfad adressiert wird (Beispiel:select * from delta."s3://<bucket>/<path>"). - Wenn eine Tabelle oder Ansicht umbenannt wird, wird die Datenherkunft für die umbenannte Tabelle oder Ansicht nicht erfasst.
- Wenn ein Schema oder Katalog umbenannt wird, wird die Herkunft für Tabellen und Ansichten unter dem umbenannten Katalog oder Schema nicht erfasst.
- Wenn Sie Spark SQL-Dataset-Prüfpunkte verwenden, wird die Herkunft nicht erfasst.
- Unity Catalog erfasst in den meisten Fällen die Datenherkunft von Delta Live Tables-Pipelines. In einigen Fällen kann jedoch keine vollständige Herkunftsabdeckung garantiert werden, z. B. wenn Pipelines die APPLY CHANGES-API oder TEMPORARY-Tabellen verwenden.
- Herkunft erfasst keine Stapelfunktionen.
- Globale Temp-Ansichten werden nicht nach Herkunft erfasst.
- Tabellen unter
system.information_schemawerden nicht nach Herkunft erfasst.