Erste Schritte: Importieren und Visualisieren von CSV-Daten aus einem Notebook
In diesem Artikel wird erläutert, wie Sie ein Azure Databricks-Notebook zum Importieren von Daten aus einer CSV-Datei mit Babynamendaten von health.data.ny.gov in Ihr Unity Catalog-Volume mithilfe von Python, Scala und R verwenden. Außerdem erfahren Sie, wie Sie einen Spaltennamen ändern, die Daten visualisieren und sie in einer Tabelle speichern.
Anforderungen
Um die Aufgaben in diesem Artikel abzuschließen, müssen die folgenden Anforderungen erfüllt sein:
- Ihr Arbeitsbereich muss für Unity Catalog aktiviert sein. Weitere Informationen zu den ersten Schritten mit Unity Catalog finden Sie unter Einrichten und Verwalten von Unity Catalog.
- Sie müssen über die Berechtigung verfügen, eine vorhandene Computeressource zu verwenden oder eine neue Computeressource zu erstellen. Weitere Informationen erhalten Sie unter Erste Schritte: Einrichten von Konto und Arbeitsbereich oder von Ihren Databricks-Administratoren/-Administratorinnen.
Tipp
Ein vollständiges Notebook für diesen Artikel finden Sie unter Importieren und Visualisieren des Datennotebooks.
Schritt 1: Erstellen eines neuen Notebooks
Wenn Sie ein Notebook in Ihrem Arbeitsbereich erstellen möchten, wählen Sie in der Randleiste ![]() Neu aus, und wählen Sie dann Notebook aus. Im Arbeitsbereich wird ein leeres Notebook geöffnet.
Neu aus, und wählen Sie dann Notebook aus. Im Arbeitsbereich wird ein leeres Notebook geöffnet.
Weitere Informationen zum Erstellen und Verwalten von Notebooks finden Sie unter Verwalten von Notebooks.
Schritt 2: Definieren von Variablen
In diesem Schritt definieren Sie Variablen für die Verwendung im Beispiel-Notebook, das Sie in diesem Artikel erstellen.
Kopieren Sie den folgenden Code, und fügen Sie ihn in die neue leere Notebookzelle ein. Ersetzen Sie
<catalog-name>,<schema-name>und<volume-name>durch die Katalog-, Schema- und Volumenamen für ein Unity Catalog-Volume. Ersetzen Sie<table_name>durch einen Tabellennamen Ihrer Wahl. Im weiteren Verlauf dieses Artikels speichern Sie die Babynamendaten in dieser Tabelle.Drücken Sie
Shift+Enter, um die Zelle auszuführen und eine neue leere Zelle zu erstellen.Python
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
Schritt 3: Importieren der CSV-Datei
In diesem importieren Sie eine CSV-Datei mit Babynamendaten von health.data.ny.gov in Ihr Unity Catalog-Volume.
Kopieren Sie den folgenden Code, und fügen Sie ihn in die neue leere Notebookzelle ein. Dieser Code kopiert mithilfe des Databricks-Befehls „dbutuils“ die
rows.csv-Datei aus health.data.ny.gov in Ihr Unity Catalog-Volume.Drücken Sie
Shift+Enter, um die Zelle auszuführen, und wechseln Sie dann zur nächsten Zelle.Python
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Schritt 4: Laden von CSV-Daten in einen Datenrahmen
In diesem Schritt erstellen Sie mithilfe der Methode spark.read.csv einen Datenrahmen namens df aus der CSV-Datei, die Sie zuvor in Ihr Unity Catalog-Volume geladen haben.
Kopieren Sie den folgenden Code, und fügen Sie ihn in die neue leere Notebookzelle ein. Dieser Code lädt Babynamendaten aus der CSV-Datei in den Datenrahmen
df.Drücken Sie
Shift+Enter, um die Zelle auszuführen, und wechseln Sie dann zur nächsten Zelle.Python
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
Sie können Daten aus vielen unterstützten Dateiformaten laden.
Schritt 5: Visualisieren von Daten aus einem Notebook
In diesem Schritt verwenden Sie die Methode display(), um den Inhalt des Datenrahmens in einer Tabelle im Notebook anzuzeigen, und visualisieren dann die Daten in einem Wortwolkendiagramm im Notebook.
Kopieren Sie den folgenden Code, fügen Sie ihn in die neue leere Notebook-Zelle ein, und klicken Sie dann auf Zelle ausführen, um die Daten in einer Tabelle anzuzeigen.
Python
display(df)Scala
display(df)R
display(df)Überprüfen Sie die Ergebnisse in der Tabelle.
Klicken Sie neben der Registerkarte Tabelle auf + und klicken Sie dann auf Visualisierung.
Klicken Sie im Visualisierungs-Editor auf Visualisierungstyp, und stellen Sie sicher, dass Wortwolke ausgewählt ist.
Überprüfen Sie unter Wörterspalte, ob
First Nameausgewählt ist.Klicken Sie unter Häufigkeitsbeschränkung auf
35.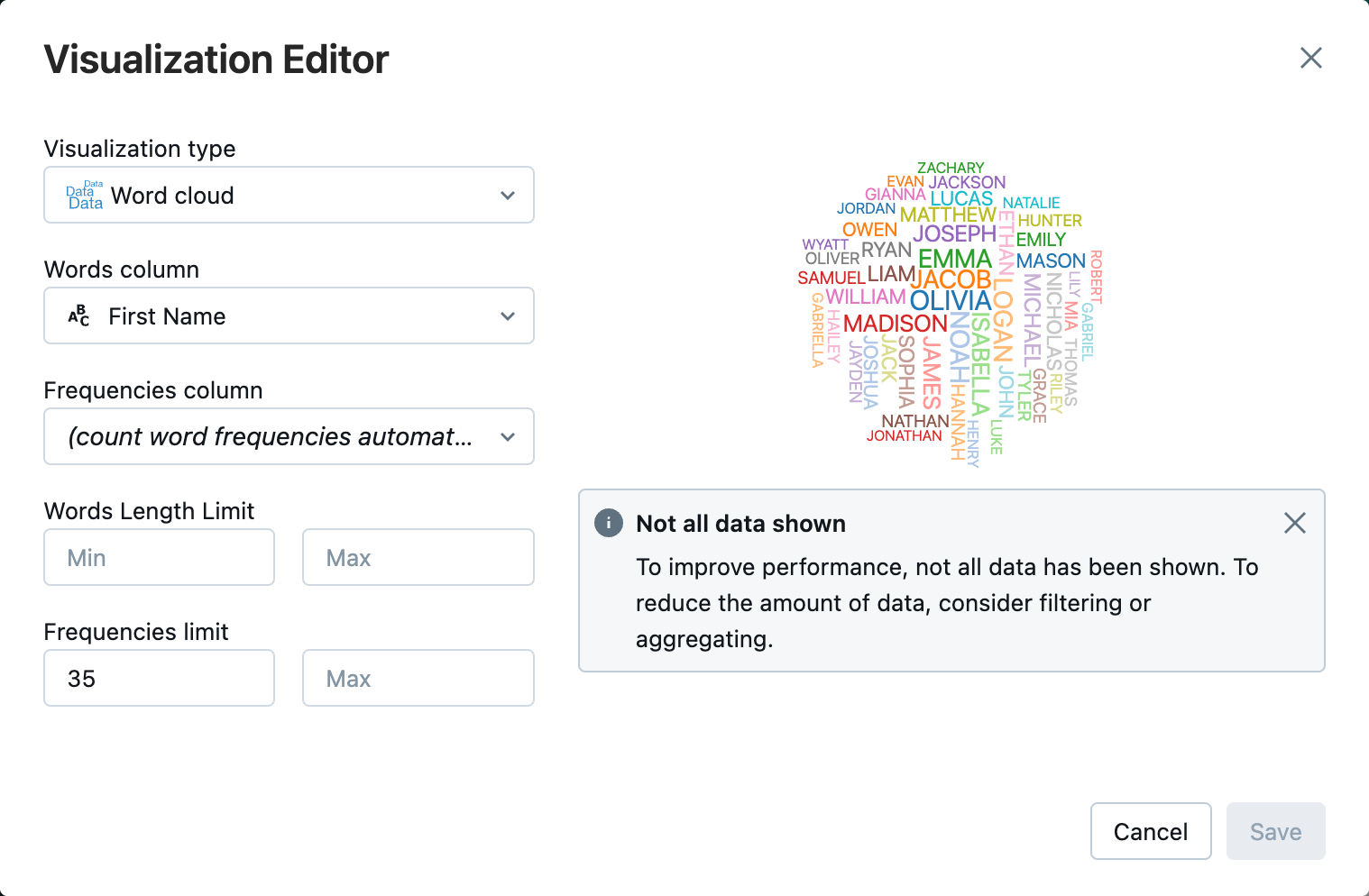
Klicken Sie auf Speichern.
Schritt 6: Speichern des DataFrame in einer Tabelle
Wichtig
Um Ihren Datenrahmens in Unity Catalog zu speichern, benötigen Sie die Berechtigung CREATE für Tabellen für den Katalog und das Schema. Informationen zu Berechtigungen in Unity Catalog finden Sie unter Berechtigungen und sicherungsfähige Objekte in Unity Catalog, Verwalten von Berechtigungen in Unity Catalog.
Kopieren Sie den folgenden Code, und fügen Sie ihn in eine leere Notebookzelle ein. Dieser Code ersetzt ein Leerzeichen im Spaltennamen. Sonderzeichen, z. B. Leerzeichen, sind in Spaltennamen nicht zulässig. Dieser Code verwendet die Apache Spark-Methode
withColumnRenamed().Python
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Kopieren Sie den folgenden Code, und fügen Sie ihn in eine leere Notebookzelle ein. Dieser Code speichert den Inhalt des Datenrahmens in einer Tabelle in Unity Catalog mithilfe der Tabellennamenvariablen, die Sie am Anfang dieses Artikels definiert haben.
Python
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Um zu überprüfen, ob die Tabelle gespeichert wurde, klicken Sie auf der linken Seitenleiste auf Katalog, um die Benutzeroberfläche des Katalog-Explorers zu öffnen. Öffnen Sie Ihren Katalog und dann das Schema, um zu überprüfen, ob die Tabelle angezeigt wird.
Klicken Sie auf die Tabelle, um das Tabellenschema auf der Registerkarte Übersicht anzuzeigen.
Klicken Sie auf Beispieldaten, um 100 Datenzeilen aus der Tabelle anzuzeigen.
Importieren und Visualisieren von Datennotebooks
Verwenden Sie eines der folgenden Notebooks, um die Schritte in diesem Artikel auszuführen.
Python
Importieren von Daten aus CSV mithilfe des Python
Scala
Importieren von Daten aus CSV mithilfe des Scala
R
Importieren von Daten aus CSV mithilfe des R
Nächste Schritte
- Weitere Informationen zum Hinzufügen zusätzlicher Daten zu einer vorhandenen Tabelle aus einer CSV-Datei finden Sie unter Erste Schritte: Aufnehmen und Einfügen zusätzlicher Daten.
- Informationen zum Bereinigen und Verbessern von Daten finden Sie unter Erste Schritte: Verbessern und Bereinigen von Daten.