Verwenden von Databricks SQL in einem Azure Databricks-Auftrag
Sie können den SQL-Aufgabentyp in einem Azure Databricks-Auftrag verwenden und dadurch Workflows erstellen, planen, betreiben und überwachen, die Databricks SQL-Objekte wie Abfragen, Legacydashboards und Warnungen enthalten. Beispielsweise kann Ihr Workflow Daten erfassen, die Daten aufbereiten, Analysen mithilfe von Databricks SQL-Abfragen durchführen und die Ergebnisse dann in einem Legacydashboard anzeigen.
Dieser Artikel enthält einen Beispielworkflow, der ein Legacydashboard mit Metriken für GitHub-Beiträge erstellt. In diesem Beispiel führen Sie folgende Schritte aus:
- Erfassen von GitHub-Daten mithilfe eines Python-Skripts und der GitHub-REST-API
- Transformieren der GitHub-Daten mithilfe einer Delta Live Tables-Pipeline
- Auslösen von Databricks SQL-Abfragen, die eine Analyse für die vorbereiteten Daten ausführen
- Zeigen Sie die Analyse in einem Legacydashboard an.
Voraussetzungen
Für diese exemplarische Vorgehensweise benötigen Sie Folgendes:
- Ein persönliches GitHub-Zugriffstoken. Dieses Token muss über die Berechtigung Repository verfügen.
- Ein serverloses SQL-Warehouse oder ein Pro-SQL-Warehouse. Siehe SQL Warehouse-Typen.
- Ein Databricks-Geheimnisbereich. Der Geheimnisbereich wird zum sicheren Speichern des GitHub-Tokens verwendet. Weitere Informationen finden Sie unter Schritt 1: Speichern des GitHub-Tokens in einem Geheimnis.
Schritt 1: Speichern des GitHub-Tokens in einem Geheimnis
Anstatt Anmeldeinformationen wie das persönliche GitHub-Zugriffstoken in einem Auftrag hartzucodieren, empfiehlt Databricks die Verwendung eines Geheimnisbereichs zum sicheren Speichern und Verwalten von Geheimnissen. Die folgenden Befehle der Databricks-Befehlszeilenschnittstelle sind ein Beispiel für das Erstellen eines Geheimnisbereichs und das Speichern des GitHub-Tokens in einem Geheimnis in diesem Bereich:
databricks secrets create-scope <scope-name>
databricks secrets put-secret <scope-name> <token-key> --string-value <token>
- Ersetzen Sie
<scope-namedurch den Namen eines Azure Databricks-Geheimnisbereichs zum Speichern des Tokens. - Ersetzen Sie
<token-key>durch den Namen eines Schlüssels, der dem Token zugewiesen werden soll. - Ersetzen Sie
<token>durch den Wert des persönlichen GitHub-Zugriffstokens.
Schritt 2: Erstellen eines Skripts zum Abrufen von GitHub-Daten
Das folgende Python-Skript verwendet die GitHub-REST-API, um Daten zu Commits und Beiträgen aus einem GitHub-Repository abzurufen. Eingabeargumente geben das GitHub-Repository an. Die Datensätze werden an einem Speicherort im DBFS gespeichert, der von einem anderen Eingabeargument angegeben wird.
In diesem Beispiel wird das DBFS zum Speichern des Python-Skripts verwendet. Sie können aber auch Databricks Git-Ordner oder Arbeitsbereichsdateien verwenden, um das Skript zu speichern und zu verwalten.
Speichern Sie dieses Skript an einem Speicherort auf Ihrem lokalen Datenträger:
import json import requests import sys api_url = "https://api.github.com" def get_commits(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/commits" more = True get_response(request_url, f"{path}/commits", token) def get_contributors(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/contributors" more = True get_response(request_url, f"{path}/contributors", token) def get_response(request_url, path, token): page = 1 more = True while more: response = requests.get(request_url, params={'page': page}, headers={'Authorization': "token " + token}) if response.text != "[]": write(path + "/records-" + str(page) + ".json", response.text) page += 1 else: more = False def write(filename, contents): dbutils.fs.put(filename, contents) def main(): args = sys.argv[1:] if len(args) < 6: print("Usage: github-api.py owner repo request output-dir secret-scope secret-key") sys.exit(1) owner = sys.argv[1] repo = sys.argv[2] request = sys.argv[3] output_path = sys.argv[4] secret_scope = sys.argv[5] secret_key = sys.argv[6] token = dbutils.secrets.get(scope=secret_scope, key=secret_key) if (request == "commits"): get_commits(owner, repo, token, output_path) elif (request == "contributors"): get_contributors(owner, repo, token, output_path) if __name__ == "__main__": main()Laden Sie das Skript in das DBFS hoch:
- Wechseln Sie zur Landing Page von Azure Databricks, und klicken Sie auf der Seitenleiste auf
 Katalog
Katalog - Klicken Sie auf DBFS durchsuchen.
- Klicken Sie im DBFS-Dateibrowser auf Hochladen. Das Dialogfeld Daten in DBFS hochladen wird angezeigt.
- Geben Sie einen Pfad im DBFS zum Speichern des Skripts ein, klicken Sie auf Dateien zum Hochladen ablegen oder zum Durchsuchen klicken, und wählen Sie das Python-Skript aus.
- Klicken Sie auf Fertig.
- Wechseln Sie zur Landing Page von Azure Databricks, und klicken Sie auf der Seitenleiste auf
Schritt 3: Erstellen einer Delta Live Tables-Pipeline zum Verarbeiten der GitHub-Daten
In diesem Abschnitt erstellen Sie eine Delta Live Tables-Pipeline, um die GitHub-Rohdaten in Tabellen zu konvertieren, die von Databricks SQL-Abfragen analysiert werden können. Führen Sie zum Erstellen der Pipeline die folgenden Schritte aus:
Klicken Sie auf der Seitenleiste auf
 Neu, und wählen Sie im Menü die Option Notebook aus. Das Dialogfeld Notebook erstellen wird angezeigt.
Neu, und wählen Sie im Menü die Option Notebook aus. Das Dialogfeld Notebook erstellen wird angezeigt.Geben Sie unter Standardsprache einen Namen ein, und wählen Sie Python aus. Sie können Cluster auf den Standardwert festlegen. Die Delta Live Tables-Runtime erstellt einen Cluster, bevor die Pipeline ausgeführt wird.
Klicken Sie auf Erstellen.
Kopieren Sie das Python-Codebeispiel, und fügen Sie es in Ihr neues Notebook ein. Sie können den Beispielcode zu einer einzelnen Zelle des Notebooks oder mehreren Zellen hinzufügen.
import dlt from pyspark.sql.functions import * def parse(df): return (df .withColumn("author_date", to_timestamp(col("commit.author.date"))) .withColumn("author_email", col("commit.author.email")) .withColumn("author_name", col("commit.author.name")) .withColumn("comment_count", col("commit.comment_count")) .withColumn("committer_date", to_timestamp(col("commit.committer.date"))) .withColumn("committer_email", col("commit.committer.email")) .withColumn("committer_name", col("commit.committer.name")) .withColumn("message", col("commit.message")) .withColumn("sha", col("commit.tree.sha")) .withColumn("tree_url", col("commit.tree.url")) .withColumn("url", col("commit.url")) .withColumn("verification_payload", col("commit.verification.payload")) .withColumn("verification_reason", col("commit.verification.reason")) .withColumn("verification_signature", col("commit.verification.signature")) .withColumn("verification_verified", col("commit.verification.signature").cast("string")) .drop("commit") ) @dlt.table( comment="Raw GitHub commits" ) def github_commits_raw(): df = spark.read.json(spark.conf.get("commits-path")) return parse(df.select("commit")) @dlt.table( comment="Info on the author of a commit" ) def commits_by_author(): return ( dlt.read("github_commits_raw") .withColumnRenamed("author_date", "date") .withColumnRenamed("author_email", "email") .withColumnRenamed("author_name", "name") .select("sha", "date", "email", "name") ) @dlt.table( comment="GitHub repository contributors" ) def github_contributors_raw(): return( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "json") .load(spark.conf.get("contribs-path")) )Klicken Sie auf der Seitenleiste auf
 Workflows, anschließend auf die Registerkarte Delta Live Tables und dann auf Pipeline erstellen.
Workflows, anschließend auf die Registerkarte Delta Live Tables und dann auf Pipeline erstellen.Geben Sie der Pipeline einen Namen, z. B.
Transform GitHub data.Geben Sie im Feld Notebook-Bibliotheken den Pfad zu Ihrem Notizbuch ein, oder klicken Sie auf
 , um das Notebook auszuwählen.
, um das Notebook auszuwählen.Klicken Sie auf Konfiguration hinzufügen. Geben Sie
commits-pathin das TextfeldKeyein. Geben Sie im TextfeldValueden DBFS-Pfad ein, in den die GitHub-Datensätze geschrieben werden sollen. Dies kann ein von Ihnen ausgewählter beliebiger Pfad sein. Dabei handelt es sich um denselben Pfad, den Sie beim Konfigurieren der ersten Python-Aufgabe beim Erstellen des Workflows verwenden.Klicken Sie erneut auf Konfiguration hinzufügen. Geben Sie
contribs-pathin das TextfeldKeyein. Geben Sie im TextfeldValueden DBFS-Pfad ein, in den die GitHub-Datensätze geschrieben werden sollen. Dies kann ein von Ihnen ausgewählter beliebiger Pfad sein. Dabei handelt es sich um denselben Pfad, den Sie beim Konfigurieren der zweiten Python-Aufgabe beim Erstellen des Workflows verwenden.Geben Sie im Feld Ziel eine Zieldatenbank ein, z. B.
github_tables. Das Festlegen einer Zieldatenbank veröffentlicht die Ausgabedaten im Metastore und ist für die Downstreamabfragen erforderlich, die die von der Pipeline erzeugten Daten analysieren.Klicken Sie auf Speichern.
Schritt 4: Erstellen eines Workflows zum Erfassen und Transformieren von GitHub-Daten
Vor dem Analysieren und Visualisieren der GitHub-Daten mit Databricks SQL müssen Sie die Daten erfassen und vorbereiten. Führen Sie die folgenden Schritte aus, um einen Workflow zum Ausführen dieser Aufgaben zu erstellen:
Erstellen eines Azure Databricks-Auftrags und Hinzufügen der ersten Aufgabe
Wechseln Sie zu Ihrer Azure Databricks-Zielseite, und führen Sie einen der folgenden Schritte aus:
- Klicken Sie auf der Randleiste auf Workflows und dann auf
 .
. - Klicken Sie auf der Randleiste auf Neu, und wählen Sie im Menü Auftrag aus.
- Klicken Sie auf der Randleiste auf
Ersetzen Sie im Aufgabendialogfeld, das auf der Registerkarte Aufgaben angezeigt wird, Namen für Ihren Auftrag hinzufügen… durch den Namen für den Auftrag, z. B.
GitHub analysis workflow.Geben Sie unter Aufgabenname einen Namen für die Aufgabe ein, z. B.
get_commits.Wählen Sie unter Typ die Option Python-Skript aus.
Wählen Sie unter Quelle die Option DBFS/S3 aus.
Geben Sie unter Pfad den Pfad zum Skript im DBFS ein.
Geben Sie unter Parameter die folgenden Argumente für das Python-Skript ein:
["<owner>","<repo>","commits","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- Ersetzen Sie
<owner>durch den Namen des Repositorybesitzers. Geben Sie beispielsweisedatabrickslabszum Abrufen von Datensätzen aus dem Repositorygithub.com/databrickslabs/overwatchein. - Ersetzen Sie
<repo>durch den Repositorynamen, etwaoverwatch. - Ersetzen Sie
<DBFS-output-dir>durch einen Pfad im DBFS, um die von GitHub abgerufenen Datensätze zu speichern. - Ersetzen Sie
<scope-name>durch den Namen des Geheimnisbereichs, den Sie zum Speichern des GitHub-Tokens erstellt haben. - Ersetzen Sie
<github-token-key>durch den Namen des Schlüssels, den Sie dem GitHub-Token zugewiesen haben.
- Ersetzen Sie
Klicken Sie auf Aufgabe speichern.
Hinzufügen einer weiteren Aufgabe
Klicken Sie unterhalb der soeben von Ihnen erstellten Aufgabe auf
 .
.Geben Sie unter Aufgabenname einen Namen für die Aufgabe ein, z. B.
get_contributors.Wählen Sie unter Typ den Aufgabentyp Python-Skript aus.
Wählen Sie unter Quelle die Option DBFS/S3 aus.
Geben Sie unter Pfad den Pfad zum Skript im DBFS ein.
Geben Sie unter Parameter die folgenden Argumente für das Python-Skript ein:
["<owner>","<repo>","contributors","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- Ersetzen Sie
<owner>durch den Namen des Repositorybesitzers. Geben Sie beispielsweisedatabrickslabszum Abrufen von Datensätzen aus dem Repositorygithub.com/databrickslabs/overwatchein. - Ersetzen Sie
<repo>durch den Repositorynamen, etwaoverwatch. - Ersetzen Sie
<DBFS-output-dir>durch einen Pfad im DBFS, um die von GitHub abgerufenen Datensätze zu speichern. - Ersetzen Sie
<scope-name>durch den Namen des Geheimnisbereichs, den Sie zum Speichern des GitHub-Tokens erstellt haben. - Ersetzen Sie
<github-token-key>durch den Namen des Schlüssels, den Sie dem GitHub-Token zugewiesen haben.
- Ersetzen Sie
Klicken Sie auf Aufgabe speichern.
Hinzufügen einer Aufgabe zum Transformieren der Daten
- Klicken Sie unterhalb der soeben von Ihnen erstellten Aufgabe auf .
- Geben Sie unter Aufgabenname einen Namen für die Aufgabe ein, z. B.
transform_github_data. - Wählen Sie unter Typ die Option Delta Live Tables-Pipeline aus, und geben Sie einen Namen für die Aufgabe ein.
- Wählen Sie unter Pipeline die Pipeline aus, die Sie in Schritt 3: Erstellen einer Delta Live Tables-Pipeline zum Verarbeiten der GitHub-Daten erstellt haben.
- Klicken Sie auf Erstellen.
Schritt 5: Ausführen des Datentransformationsworkflows
Klicken Sie auf die  , um den Workflow auszuführen. Klicken Sie zum Anzeigen von Details für die Ausführung in der Ansicht Auftragsausführungen in der Spalte Startzeit für die Ausführung auf den Link. Klicken Sie auf die einzelnen Aufgaben, um Details für die Taskausführung anzuzeigen.
, um den Workflow auszuführen. Klicken Sie zum Anzeigen von Details für die Ausführung in der Ansicht Auftragsausführungen in der Spalte Startzeit für die Ausführung auf den Link. Klicken Sie auf die einzelnen Aufgaben, um Details für die Taskausführung anzuzeigen.
Schritt 6: (Optional) Führen Sie die folgenden Schritte aus, um die Ausgabedaten nach Abschluss der Workflowausführung anzuzeigen:
- Klicken Sie in der Ansicht mit den Ausführungsdetails auf die Delta Live Tables-Aufgabe.
- Klicken Sie im Bereich Details zur Aufgabenausführung unter Pipeline auf den Pipelinenamen. Die Seite Pipelinedetails wird angezeigt.
- Wählen Sie im Pipeline-DAG die Tabelle
commits_by_authoraus. - Klicken Sie im Bereich commits_by_author neben Metastore auf den Tabellennamen. Die Katalog-Explorer-Seite wird geöffnet.
Im Katalog-Explorer können Sie das Tabellenschema, Beispieldaten und andere Details für die Daten anzeigen. Führen Sie die gleichen Schritte aus, um Daten für die Tabelle github_contributors_raw anzuzeigen.
Schritt 7: Entfernen der GitHub-Daten
In einer realen Anwendung erfassen und verarbeiten Sie möglicherweise kontinuierlich Daten. Da in diesem Beispiel das gesamte Dataset heruntergeladen und verarbeitet wird, müssen Sie die bereits heruntergeladenen GitHub-Daten entfernen, um einen Fehler beim erneuten Ausführen des Workflows zu vermeiden. Führen Sie die folgenden Schritte aus, um die heruntergeladenen Daten zu entfernen:
Erstellen Sie ein neues Notebook, und geben Sie die folgenden Befehle in die erste Zelle ein:
dbutils.fs.rm("<commits-path", True) dbutils.fs.rm("<contributors-path", True)Ersetzen Sie
<commits-path>und<contributors-path>durch die DBFS-Pfade, die Sie beim Erstellen der Python-Aufgaben konfiguriert haben.Klicken Sie auf
 , und wählen Sie Zelle ausführen aus.
, und wählen Sie Zelle ausführen aus.
Sie können dieses Notebook auch als Aufgabe im Workflow hinzufügen.
Schritt 8: Erstellen der Databricks SQL-Abfragen
Nachdem Sie den Workflow ausgeführt und die erforderlichen Tabellen erstellt haben, erstellen Sie Abfragen, um die vorbereiteten Daten zu analysieren. Führen Sie die folgenden Schritte aus, um die Beispielabfragen und -visualisierungen zu erstellen:
Anzeigen der 10 wichtigsten Mitwirkenden nach Monat
Klicken Sie auf der Seitenleiste unterhalb des Databricks-Logos
 auf das Symbol, und wählen Sie SQL aus.
auf das Symbol, und wählen Sie SQL aus.Klicken Sie auf Abfrage erstellen, um den Databricks SQL-Abfrage-Editor zu öffnen.
Vergewissern Sie sich, dass der Katalog auf hive_metastore festgelegt ist. Klicken Sie neben hive_metastore auf Standard, und legen Sie die Datenbank auf den Zielwert fest, den Sie in der Delta Live Tables-Pipeline festgelegt haben.
Geben Sie auf der Registerkarte Neue Abfrage die folgende Abfrage ein:
SELECT date_part('YEAR', date) AS year, date_part('MONTH', date) AS month, name, count(1) FROM commits_by_author WHERE name IN ( SELECT name FROM commits_by_author GROUP BY name ORDER BY count(name) DESC LIMIT 10 ) AND date_part('YEAR', date) >= 2022 GROUP BY name, year, month ORDER BY year, month, nameKlicken Sie auf die Registerkarte Neue Abfrage, und benennen Sie die Abfrage um, z. B.
Commits by month top 10 contributors.Standardmäßig werden die Ergebnisse in Tabellenform dargestellt. Wenn Sie die Art der Datenvisualisierung ändern möchten, beispielsweise mithilfe eines Balkendiagramms, klicken Sie im Bereich Ergebnisse auf
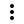 und dann auf Bearbeiten.
und dann auf Bearbeiten.Wählen Sie unter Visualisierungstyp die Option Balken aus.
Wählen Sie unter X-Spalte die Option month aus.
Wählen Sie unter Y-Spalten die Option count(1) aus.
Wählen Sie unter Gruppieren nach die Option name aus.
Klicken Sie auf Speichern.
Anzeigen der 20 wichtigsten Mitwirkenden
Klicken Sie auf + > Neue Abfrage erstellen, und stellen Sie sicher, dass der Katalog auf hive_metastore festgelegt ist. Klicken Sie neben hive_metastore auf Standard, und legen Sie die Datenbank auf den Zielwert fest, den Sie in der Delta Live Tables-Pipeline festgelegt haben.
Geben Sie die folgende Abfrage ein:
SELECT login, cast(contributions AS INTEGER) FROM github_contributors_raw ORDER BY contributions DESC LIMIT 20Klicken Sie auf die Registerkarte Neue Abfrage, und benennen Sie die Abfrage um, z. B.
Top 20 contributors.Um die Visualisierung über die Standardtabelle zu ändern, klicken Sie im Bereich Ergebnisse auf
und dann auf Bearbeiten.Wählen Sie unter Visualisierungstyp die Option Balken aus.
Wählen Sie unter X-Spalte die Option login aus.
Wählen Sie unter Y-Spalten die Option contributions aus.
Klicken Sie auf Speichern.
Anzeigen der Gesamtanzahl von Commits nach Ersteller
Klicken Sie auf + > Neue Abfrage erstellen, und stellen Sie sicher, dass der Katalog auf hive_metastore festgelegt ist. Klicken Sie neben hive_metastore auf Standard, und legen Sie die Datenbank auf den Zielwert fest, den Sie in der Delta Live Tables-Pipeline festgelegt haben.
Geben Sie die folgende Abfrage ein:
SELECT name, count(1) commits FROM commits_by_author GROUP BY name ORDER BY commits DESC LIMIT 10Klicken Sie auf die Registerkarte Neue Abfrage, und benennen Sie die Abfrage um, z. B.
Total commits by author.Um die Visualisierung über die Standardtabelle zu ändern, klicken Sie im Bereich Ergebnisse auf
und dann auf Bearbeiten.Wählen Sie unter Visualisierungstyp die Option Balken aus.
Wählen Sie unter X-Spalte die Option name aus.
Wählen Sie unter Y-Spalten die Option commits aus.
Klicken Sie auf Speichern.
Schritt 9: Erstellen eines Dashboards
- Klicken Sie auf der Randleiste auf
 Dashboards.
Dashboards. - Klicken Sie auf Dashboard erstellen.
- Geben Sie einen Namen für das Dashboard ein, etwa
GitHub analysis. - Klicken Sie für jede Abfrage und Visualisierung, die in Schritt 8: Erstellen der Databricks SQL-Abfragen erstellt wurden, auf Hinzufügen > Visualisierung, und wählen Sie die einzelnen Visualisierungen aus.
Schritt 10: Hinzufügen der SQL-Aufgaben zum Workflow
So fügen Sie dem Workflow, den Sie unter Erstellen eines Azure Databricks-Auftrags und Hinzufügen der ersten Aufgabe erstellt haben, für jede in Schritt 8: Erstellen der Databricks SQL-Abfragen erstellte Abfrage die neuen Abfrageaufgaben hinzu
- Klicken Sie auf der Randleiste auf Workflows.
- Klicken Sie in der Spalte Name auf den Auftragsnamen.
- Klicken Sie auf die Registerkarte Aufgaben.
- Klicken Sie unter der letzten Aufgabe auf .
- Geben Sie einen Namen für die Aufgabe ein, wählen Sie unter Typ die Option SQL und unter SQL-Aufgabe die Option Abfrage aus.
- Wählen Sie unter SQL-Abfrage die Abfrage aus.
- Wählen Sie unter SQL-Warehouse ein serverloses SQL-Warehouse oder ein Pro-SQL-Warehouse aus, um die Aufgabe auszuführen.
- Klicken Sie auf Erstellen.
Schritt 11: Hinzufügen einer Dashboardaufgabe
- Klicken Sie unter der letzten Aufgabe auf .
- Geben Sie einen Namen für die Aufgabe ein, wählen Sie unter Typ die Option SQL und unter SQL-Aufgabe die Option Legacydashboard aus.
- Wählen Sie das Dashboard aus, das in Schritt 9: Erstellen eines Dashboards erstellt wurde.
- Wählen Sie unter SQL-Warehouse ein serverloses SQL-Warehouse oder ein Pro-SQL-Warehouse aus, um die Aufgabe auszuführen.
- Klicken Sie auf Erstellen.
Schritt 12: Ausführen des vollständigen Workflows
Klicken Sie auf , um den Workflow auszuführen. Klicken Sie zum Anzeigen von Details für die Ausführung in der Ansicht Auftragsausführungen in der Spalte Startzeit für die Ausführung auf den Link.
Schritt 13: Anzeigen der Ergebnisse
Um die Ergebnisse nach Abschluss der Ausführung anzuzeigen, klicken Sie auf die abschließende Dashboardaufgabe, und klicken Sie im rechten Bereich unter SQL-Dashboard auf den Dashboardnamen.