MLOps Stacks: Modellentwicklungsprozess als Code
In diesem Artikel wird beschrieben, wie Sie mit MLOps Stacks den Entwicklungs- und Bereitstellungsprozess als Code in einem quellcodeverwalteten Repository implementieren können. Außerdem werden die Vorteile der Modellentwicklung auf der Databricks Data Intelligence-Plattform beschrieben, einer einzigen Plattform, die die einzelnen Schritte des Prozesses zur Modellentwicklung und -bereitstellung vereinheitlicht.
Was ist MLOps Stacks?
Mit MLOps Stacks wird der gesamte Modellentwicklungsprozess implementiert, gespeichert und als Code in einem quellcodeverwalteten Repository nachverfolgt. Die Automatisierung des Prozesses auf diese Weise erleichtert eine besser wiederholbare, vorhersehbare und systematische Bereitstellung und ermöglicht die Integration in Ihren CI/CD-Prozess. Wenn Sie den Modellentwicklungsprozess als Code darstellen, können Sie den Code anstelle des Modells bereitstellen. Durch die Bereitstellung des Codes wird die Funktion zum Erstellen des Modells automatisiert, sodass es bei Bedarf wesentlich einfacher ist, das Modell neu zu trainieren.
Wenn Sie ein Projekt mithilfe von MLOps Stacks erstellen, definieren Sie die Komponenten Ihres ML-Prozesses für die Entwicklung und Bereitstellung (z. B. Notebooks für Feature Engineering, Training, Tests und Bereitstellung, Pipelines für Training und Tests, Arbeitsbereiche für die einzelnen Phasen und CI/CD-Workflows) mithilfe von GitHub Actions oder Azure DevOps für automatisierte Tests und die Bereitstellung Ihres Codes.
Die von MLOps Stacks erstellte Umgebung implementiert den MLOps-Workflow, der von Databricks empfohlen wird. Sie können den Code anpassen, um Stapel zu erstellen, die den Prozessen oder Anforderungen Ihrer Organisation entsprechen.
Wie funktioniert MLOps Stacks?
Sie verwenden die Databricks CLI, um einen MLOps-Stapel zu erstellen. Eine ausführliche Anleitungen finden Sie unter Databricks-Ressourcenpakete für MLOps Stacks.
Wenn Sie ein MLOps Stacks-Projekt initiieren, führt die Software Sie durch die Eingabe der Konfigurationsdetails und erstellt dann ein Verzeichnis mit den Dateien, die Ihr Projekt bilden. Dieses Verzeichnis oder dieser Stapel implementiert den von Databricks empfohlenen MLOps-Produktionsworkflow. Die im Diagramm angezeigten Komponenten werden für Sie erstellt, und Sie müssen die Dateien nur bearbeiten, um Ihren benutzerdefinierten Code hinzuzufügen.
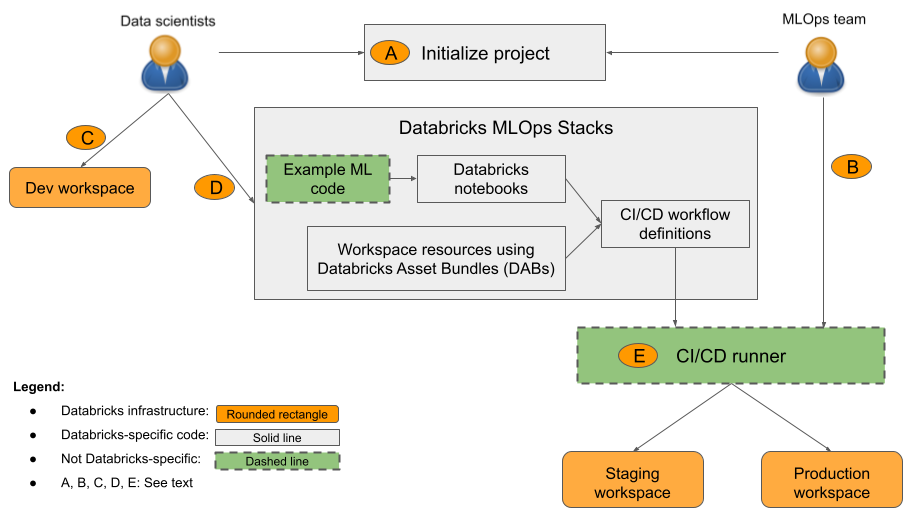
In der Abbildung:
- A: Eine Wissenschaftliche Fachkraft für Daten oder ML-Techniker initialisiert das Projekt mit
databricks bundle init mlops-stacks. Wenn Sie das Projekt initialisieren, können Sie die ML-Codekomponenten (in der Regel von wissenschaftliche Fachkräften für Daten verwendet), die CI/CD-Komponenten (in der Regel von ML-Technikern) oder beides einrichten. - B: ML-Techniker richten Databricks-Dienstprinzipalschlüssel für CI/CD ein.
- C: Wissenschaftliche Fachkräfte für Daten entwickeln Modelle auf Databricks oder auf ihrem lokalen System.
- D: Wissenschaftliche Fachkräfte für Daten erstellen Pull Requests zum Aktualisieren von ML-Code.
- E: Der CI/CD-Runner führt Notebooks aus, erstellt Aufträge und führt andere Aufgaben in den Staging- und Produktionsarbeitsbereichen aus.
Ihre Organisation kann den Standardstapel verwenden oder diesen nach Bedarf anpassen, um Komponenten hinzuzufügen, zu entfernen oder zu überarbeiten und für die Praktiken Ihrer Organisation anzupassen. Details finden Sie in der Infodatei zu GitHub-Repositorys.
MLOps Stacks wurde mit einer modularen Struktur entwickelt, um es den verschiedenen ML-Teams zu ermöglichen, unabhängig von einander an einem Projekt zu arbeiten, während sie die bewährten Methoden der Softwaretechnik berücksichtigen und CI/CD auf Produktionsniveau beibehalten wird. Technische Produktionsfachkräfte konfigurieren die ML-Infrastruktur, mit der wissenschaftliche Fachkräfte für Daten ML-Pipelines und -Modelle für die Produktion entwickeln, testen und bereitstellen können.
Wie im Diagramm gezeigt, enthält die MLOps Stacks-Standardinstanz die folgenden drei Komponenten:
- ML-Code. MLOps Stacks erstellt verschiedene Vorlagen für ein ML-Projekt, einschließlich Notebooks für Training, Batchrückschluss usw. Mit der standardisierten Vorlage können Data Scientists schnell erste Schritte ausführen. Außerdem vereinheitlicht sie die Projektstruktur für Teams und erzwingt modularisierten Code für Tests.
- ML-Ressourcen als Code. MLOps Stacks definiert Ressourcen wie Arbeitsbereiche und Pipelines für Aufgaben wie Trainings und Batchrückschlüsse. Ressourcen werden in Databricks-Ressourcenbündeln definiert, um Tests, Optimierung und Quellcodeverwaltung für die ML-Umgebung zu erleichtern. Sie können z. B. einen größeren Instanztyp für das automatische erneute Modelltraining ausprobieren, und die Änderung wird automatisch zur zukünftigen Referenz nachverfolgt.
- CI/CD. Sie können GitHub Actions oder Azure DevOps verwenden, um ML-Code und -Ressourcen zu testen und bereitzustellen und so sicherzustellen, dass alle Produktionsänderungen über Automatisierung erfolgen und nur getesteter Code in der Produktion bereitgestellt wird.
MLOps-Projektflow
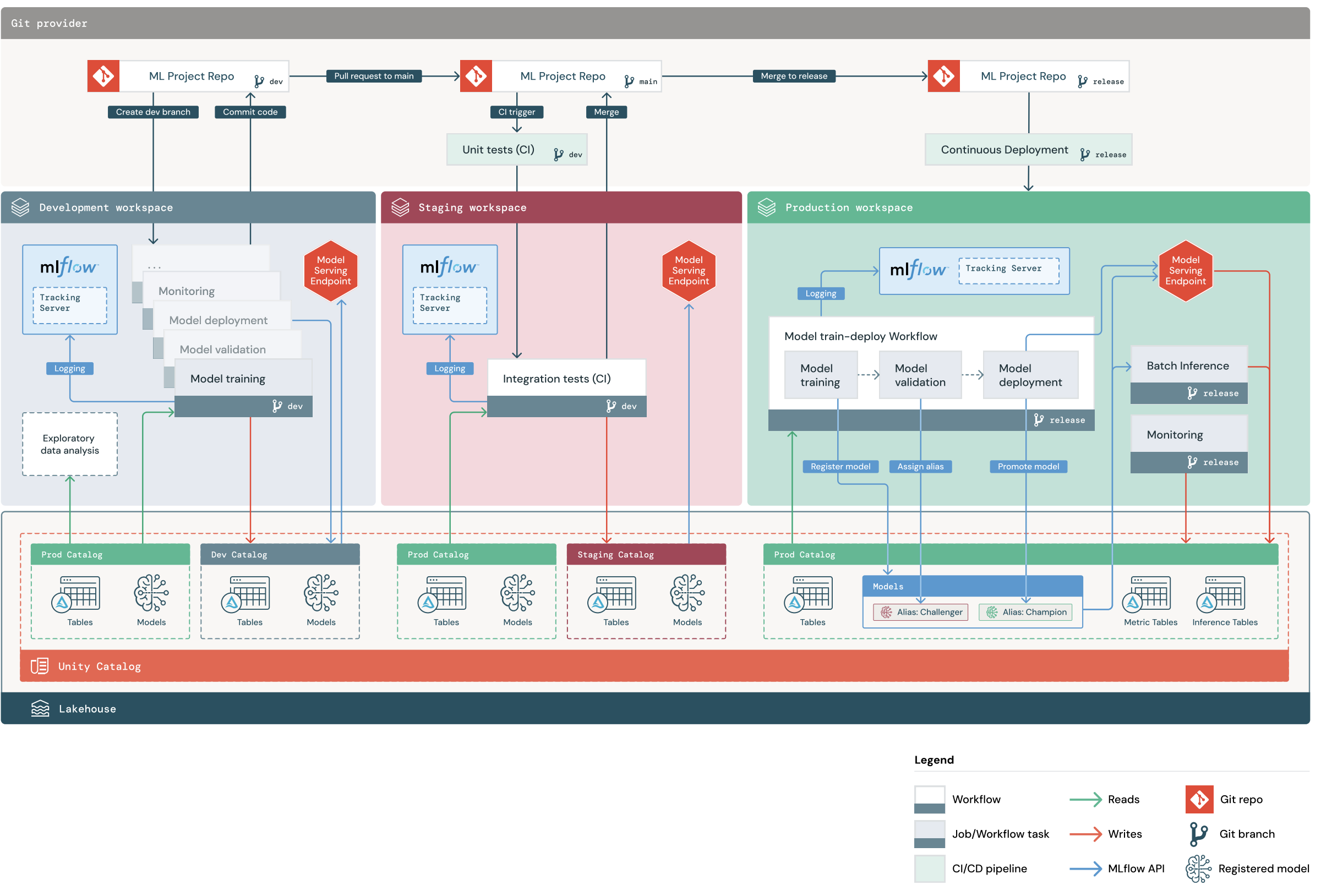
Ein MLOps Stacks-Standardprojekt enthält eine ML-Pipeline mit CI/CD-Workflows zum Testen und Bereitstellen automatisierter Aufträge für Modelltraining und Batchrückschlüsse in Databricks-Arbeitsbereichen für Entwicklung, Staging und Produktion. MLOps Stacks ist konfigurierbar, sodass Sie die Projektstruktur den Prozessen Ihrer Organisation entsprechend ändern können.
Das Diagramm zeigt den Prozess, der von MLOps Stack standardmäßig implementiert wird. Im Entwicklungsarbeitsbereich durchlaufen Data Scientists ML-Code und erstellen Pull Requests (PRs). PRs lösen Komponententests und Integrationstests in einem isolierten Databricks-Stagingarbeitsbereich aus. Wenn ein PR im Mainbranch zusammengeführt wird, werden im Stagingprozess ausgeführte Modelltrainings- und Batchrückschlussaufträge sofort aktualisiert, um den neuesten Code auszuführen. Nachdem Sie einen PR im Mainbranch zusammengeführt haben, können Sie im Rahmen Ihres geplanten Releaseprozesses einen neuen Releasebranch erstellen und die Codeänderungen in der Produktion bereitstellen.
MLOps Stacks-Projektstruktur
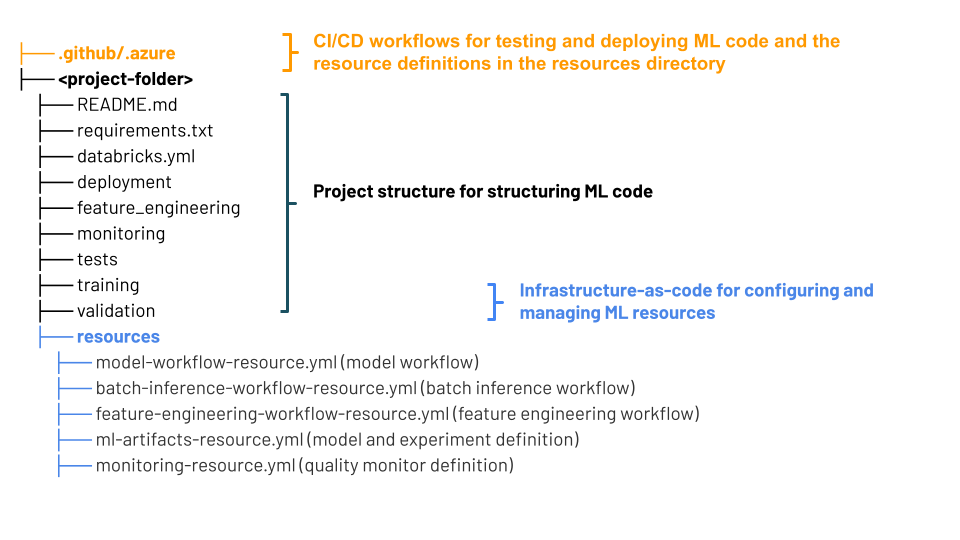
Ein MLOps-Stapel verwendet Databricks-Ressourcenpakete, eine Sammlung von Quelldateien, die als End-to-End-Definition eines Projekts dienen. Diese Quelldateien enthalten Informationen darüber, wie sie getestet und bereitgestellt werden müssen. Das Sammeln der Dateien als Paket erleichtert die Änderungen der gemeinsamen Version und die Verwendung bewährter Methoden der Softwareentwicklung wie Quellcodeverwaltung, Codeüberprüfung, Tests und CI/CD.
Das Diagramm zeigt die Dateien, die für den MLOps-Standardstapel erstellt wurden. Ausführliche Informationen zu den im Stapel enthaltenen Dateien finden Sie in der Dokumentation im GitHub-Repository oder unter Databricks-Ressourcenpakete für MLOps Stacks.
MLOps Stacks-Komponenten
Ein „Stapel“ bezieht sich auf den Satz von Tools, die in einem Entwicklungsprozess verwendet werden. Der MLOps-Standardstapel nutzt die einheitliche Databricks-Plattform und verwendet die folgenden Tools:
| Komponente | Tool in Databricks |
|---|---|
| Code für die ML-Modellentwicklung | Databricks-Notebooks, MLflow |
| Featureentwicklung und -verwaltung | Feature Engineering |
| ML-Modellrepository | Modelle in Unity Catalog |
| ML-Modellbereitstellung | Mosaic AI Model Serving |
| Infrastructure-as-Code | Databricks-Ressourcenbundles |
| Orchestrator | Databricks-Aufträge |
| CI/CD | GitHub Actions, Azure DevOps |
| Daten- und Modellleistungsüberwachung | Lakehouse Monitoring |
Nächste Schritte
Informationen zu den ersten Schritten finden Sie unter Databricks Asset Bundles für MLOps Stacks oder das Databricks MLOps Stacks Repository auf GitHub.