Erstellen von benutzerdefinierten Modellbereitstellungsendpunkten
In diesem Artikel wird beschrieben, wie Sie mithilfe von Databricks Model Serving Endpunkte für die Modellbereitstellung für benutzerdefinierte Modelle erstellen.
Die Model Serving bietet die folgenden Optionen für die Erstellung von Bereitstellungsendpunkten:
- Die Serving-Benutzeroberfläche
- REST-API
- MLflow Deployments SDK
Weitere Informationen zum Erstellen von Endpunkten, die generative KI-Modelle bereitstellen, finden Sie unter Erstellen von Endpunkten, die generative KI-Modelle bereitstellen.
Anforderungen
- Ihr Arbeitsbereich muss sich in einer unterstützten Region befinden.
- Wenn Sie benutzerdefinierte Bibliotheken oder Bibliotheken aus einem privaten Spiegelserver mit Ihrem Modell verwenden, lesen Sie Verwenden benutzerdefinierter Python-Bibliotheken mit der Modellbereitstellung, bevor Sie den Modellendpunkt erstellen.
- Zum Erstellen von Endpunkten mithilfe des MLflow Deployments SDK müssen Sie den MLflow Deployment-Client installieren. Führen Sie zur Installation Folgendes aus:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Zugriffssteuerung
Weitere Informationen zu den Zugriffsteuerungsoptionen für Modellbereitstellungsendpunkte für die Endpunktverwaltung finden Sie unter Verwalten von Berechtigungen für Ihren Modellbereitstellungsendpunkt.
Sie können auch Umgebungsvariablen hinzufügen, um Anmeldeinformationen für die Modellbereitstellung zu speichern. Weitere Informationen finden Sie unter Konfigurieren des Zugriffs auf Ressourcen über Modellbereitstellungsendpunkte.
Erstellen eines Endpunkts
Serving-Benutzeroberfläche
Sie können einen Endpunkt für die Modellbereitstellung mit der Benutzeroberfläche für die Bereitstellung erstellen.
Klicken Sie in der Seitenleiste auf Bereitstellung, um die Benutzeroberfläche für die Bereitstellung anzuzeigen.
Klicken Sie auf Bereitstellungsendpunkt erstellen.
Für Modelle, die in der Arbeitsbereichsmodellregistrierung oder -modelle im Unity-Katalog registriert sind:
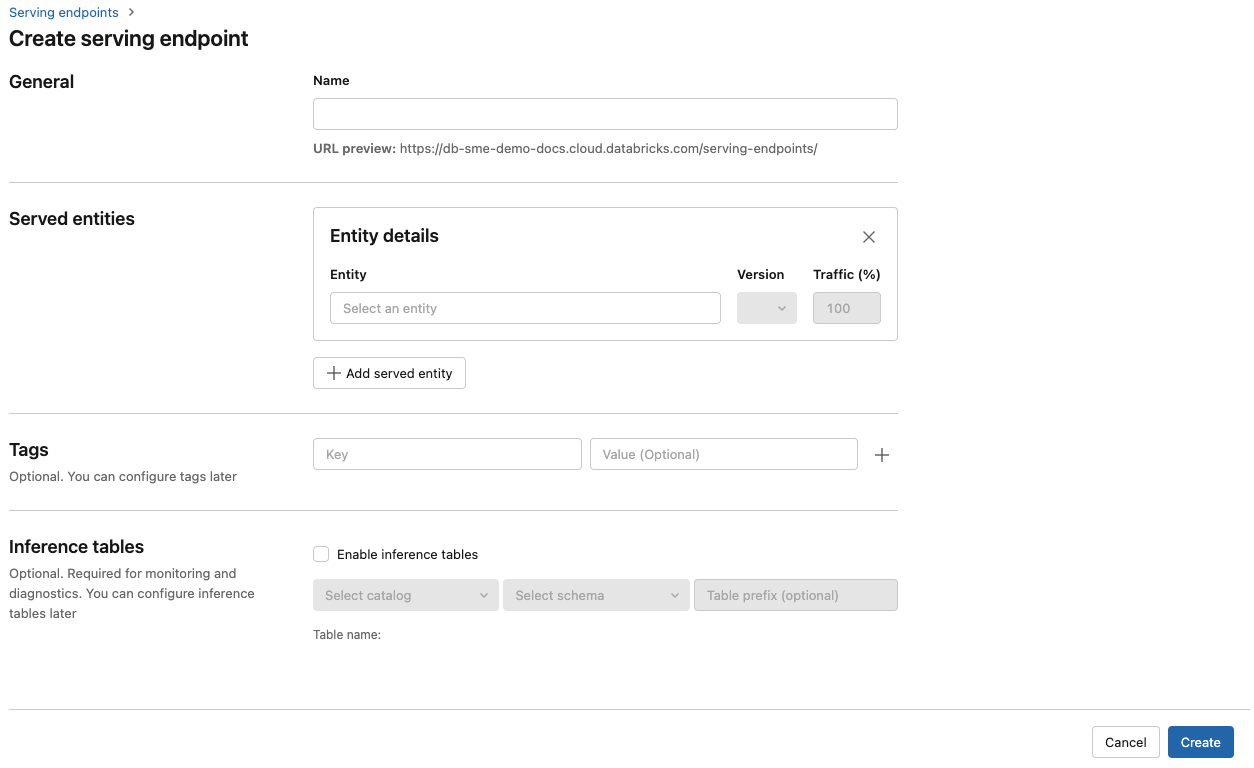
Geben Sie im Feld Name einen Namen für Ihren Endpunkt an.
Im Abschnitt Bereitgestellte Entitäten
- Wählen Sie das Feld Entität aus, um das Formular Bereitgestellte Entität auswählen zu öffnen.
- Wählen Sie den Modelltyp aus, den Sie bereitstellen möchten. Das Formular wird basierend auf Ihrer Auswahl dynamisch aktualisiert.
- Wählen Sie aus, welches Modell und welche Modellversion Sie bereitstellen möchten.
- Wählen Sie den Prozentsatz des Datenverkehrs aus, der an Ihr bereitgestelltes Modell weitergeleitet wird.
- Wählen Sie die zu verwendende Computegröße aus. Sie können für Ihre Workloads CPU- oder GPU-Computeressourcen verwenden. Weitere Informationen zu verfügbaren GPU-Computeressourcen finden Sie unter GPU-Workloadtypen.
- Wählen Sie die zu verwendende Computegröße aus. Sie können für Ihre Workloads CPU- oder GPU-Computeressourcen verwenden. Weitere Informationen zu verfügbaren GPU-Computeressourcen finden Sie unter GPU-Workloadtypen.
- Wählen Sie unter Horizontale Computeskalierung die Größe der horizontalen Computeskalierung aus. Sie sollte der Anzahl der Anforderungen entsprechen, die dieses bereitgestellte Modell gleichzeitig verarbeiten kann. Diese Zahl sollte ungefähr dem Ergebnis der folgenden Rechnung entsprechen: QPS × Modelllaufzeit.
- Verfügbare Größen sind Klein für 0–4 Anforderungen, Mittel 8–16 Anforderungen und Große für 16–64 Anforderungen.
- Geben Sie an, ob der Endpunkt auf null skaliert werden soll, wenn er nicht verwendet wird.
Klicken Sie auf Erstellen. Die Seite Bereitstellungsendpunkte wird mit dem Status „Nicht bereit“ für den Bereitstellungsendpunkt angezeigt.
REST-API
Sie können Endpunkte mithilfe der REST-API erstellen. Informationen zu Endpunktkonfigurationsparametern finden Sie unter POST /api/2.0/serving-endpoints.
Im folgenden Beispiel wird ein Endpunkt erstellt, der die erste Version des ads1-Modells bereitstellt, das in der Modellregistrierung registriert ist. Um ein Modell aus Unity Catalog anzugeben, geben Sie den vollständigen Modellnamen an, einschließlich des übergeordneten Katalogs und des Schemas, etwa catalog.schema.example-model.
POST /api/2.0/serving-endpoints
{
"name": "workspace-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
},
{
"entity_name": "my-ads-model",
"entity_version": "4",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
},
{
"served_model_name": "my-ads-model-4",
"traffic_percentage": 20
}
]
}
},
"tags": [
{
"key": "team",
"value": "data science"
}
]
}
Hier sehen Sie eine Beispielantwort. Der config_update-Status des Endpunkts lautet NOT_UPDATING, und das bereitgestellte Modell hat den Status READY.
{
"name": "workspace-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "my-ads-model-3",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
MLflow Deployments SDK
MLflow-Bereitstellungen bieten eine API zum Erstellen, Aktualisieren und Löschen von Aufgaben. Die APIs für diese Aufgaben akzeptieren dieselben Parameter wie die REST-API für Bereitstellungsendpunkte. Informationen zu Endpunktkonfigurationsparametern finden Sie unter POST /api/2.0/serving-endpoints.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="workspace-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
}
}
)
Weitere Funktionen:
Konfigurieren Ihres Endpunkts für die Bereitstellung mehrerer Modelle
Aktivieren Sie Rückschlusstabellen, um eingehende Anforderungen und ausgehende Antworten an Ihre Modellbereitstellungsendpunkte automatisch zu erfassen.
GPU-Workloadtypen
Die GPU-Bereitstellung ist mit den folgenden Paketversionen kompatibel:
- Pytorch 1.13.0-2.0.1
- TensorFlow 2.5.0-2.13.0
- MLflow 2.4.0 und höher
Um Ihre Modelle mithilfe von GPUs bereitzustellen, schließen Sie das workload_type-Feld in die Endpunktkonfiguration während der Endpunkterstellung oder als Endpunktkonfigurationsupdate mithilfe der API ein. Um Ihren Endpunkt für GPU-Workloads mit der Benutzeroberfläche für die Bereitstellung zu konfigurieren, wählen Sie den gewünschten GPU-Typ aus der Dropdownliste Compute-Typ aus.
{
"served_entities": [{
"name": "ads1",
"entity_version": "2",
"workload_type": "GPU_LARGE",
"workload_size": "Small",
"scale_to_zero_enabled": false,
}]
}
In der folgenden Tabelle sind die verfügbaren GPU-Workloadtypen zusammengefasst, die unterstützt werden.
| GPU-Workloadtyp | GPU-Instanz | GPU-Arbeitsspeicher |
|---|---|---|
GPU_SMALL |
1xT4 | 16 GB |
GPU_LARGE |
1xA100 | 80GB |
GPU_LARGE_2 |
2xA100 | 160GB |
Ändern eines benutzerdefinierten Modellendpunkts
Nachdem Sie einen benutzerdefinierten Modellendpunkt aktiviert haben, können Sie die Computekonfiguration wie gewünscht aktualisieren. Diese Konfiguration ist besonders hilfreich, wenn Sie zusätzliche Ressourcen für Ihr Modell benötigen. Workloadgröße und Computekonfiguration spielen eine wichtige Rolle bei der Bereitstellung Ihres Modells.
Bis die neue Konfiguration bereit ist, stellt die alte Konfiguration weiterhin Vorhersagedatenverkehr bereit. Während ein Update ausgeführt wird, kann kein weiteres Update durchgeführt werden. Sie können jedoch eine in Bearbeitung ausgeführte Aktualisierung von der Serving-Benutzeroberfläche abbrechen.
Serving-Benutzeroberfläche
Nachdem Sie einen Modellendpunkt aktiviert haben, wählen Sie Endpunkt bearbeiten aus, um die Computekonfiguration Ihres Endpunkts zu ändern.
Sie können folgendermaßen vorgehen:
- Sie können zwischen einigen Workloadgrößen wählen, und die automatische Skalierung wird automatisch innerhalb der Workloadgröße konfiguriert.
- Geben Sie an, ob Ihr Endpunkt bei Nichtverwendung auf Null herunterskaliert werden soll.
- Ändern Sie den Prozentsatz des Datenverkehrs, der an Ihr bereitgestelltes Modell weitergeleitet wird.
Sie können ein laufendes Konfigurationsupdate abbrechen, indem Sie oben rechts auf der Detailseite des Endpunkts Update abbrechen auswählen. Diese Funktionalität ist nur in der Serving-Benutzeroberfläche verfügbar.
REST-API
Nachfolgend sehen Sie ein Beispiel für ein Endpunktkonfigurationsupdate mit der REST-API. Siehe PUT /api/2.0/serving-endpoints/{name}/config.
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
MLflow Deployments SDK
Das MLflow Deployments SDK verwendet dieselben Parameter wie die REST-API. Details zum Anforderungs- und Antwortschema finden Sie unter PUT /api/2.0/serving-endpoints/{Name}/config.
Im folgenden Codebeispiel wird ein Modell aus der Unity Catalog-Modellregistrierung verwendet:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
Bewerten eines Modellendpunkts
Um Ihr Modell zu bewerten, senden Sie Anforderungen an den Modellbereitstellungsendpunkt.
- Siehe Abfragen von Bereitstellungsendpunkten für benutzerdefinierte Modelle.
- Siehe abfragegenerive KI-Modelle.
Zusätzliche Ressourcen
- Verwalten von Modellbereitstellungsendpunkten.
- Externe Modelle in Mosaic AI Model Serving
- Wenn Sie Python verwenden möchten, können Sie die Databricks echtzeitbasierte Python SDKverwenden.
Notebook-Beispiele
Die folgenden Notebooks umfassen verschiedene in Databricks registrierte Modelle, die Sie verwenden können, um Modellbereitstellungsendpunkte einzurichten und auszuführen.
Die Modellbeispiele können in den Arbeitsbereich importiert werden, indem Sie den Anweisungen unter Notebook importieren folgen. Nachdem Sie ein Modell aus einem der Beispiele ausgewählt und erstellt haben, registrieren Sie es im Unity-Katalog, und führen Sie dann die Schritte des UI-Workflows für die Modellbereitstellung aus.