Binärdatei
Databricks Runtime unterstützt die Datenquelle Binärdatei, die Binärdateien liest und jede Datei in einen einzelnen Datensatz konvertiert, der den unformatierten Inhalt und die Metadaten der Datei enthält. Dieser Datenquellentyp erzeugt einen DataFrame, der die folgenden Spalten und möglicherweise Partitionsspalten enthält:
path (StringType): Der Pfad der Datei.modificationTime (TimestampType): Der Zeitpunkt der letzten Änderung der Datei. In einigen HDFS-Implementierungen (Hadoop FileSystem) ist dieser Parameter möglicherweise nicht verfügbar, und der Wert wird auf einen Standardwert festgelegt.length (LongType): Die Länge der Datei in Byte.content (BinaryType): Der Inhalt der Datei.
Um Binärdateien zu lesen, geben Sie die Datenquelle format als binaryFile an.
Bilder
Databricks empfiehlt, die Binärdateidatenquelle zum Laden von Bilddaten zu verwenden.
Die Databricks-Funktion display unterstützt die Anzeige von Bilddaten, die mithilfe der binären Datenquelle geladen wurden.
Wenn alle geladenen Dateien einen Dateinamen mit einer Erweiterung für Bilddateien aufweisen, wird automatisch die Bildvorschau aktiviert:
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
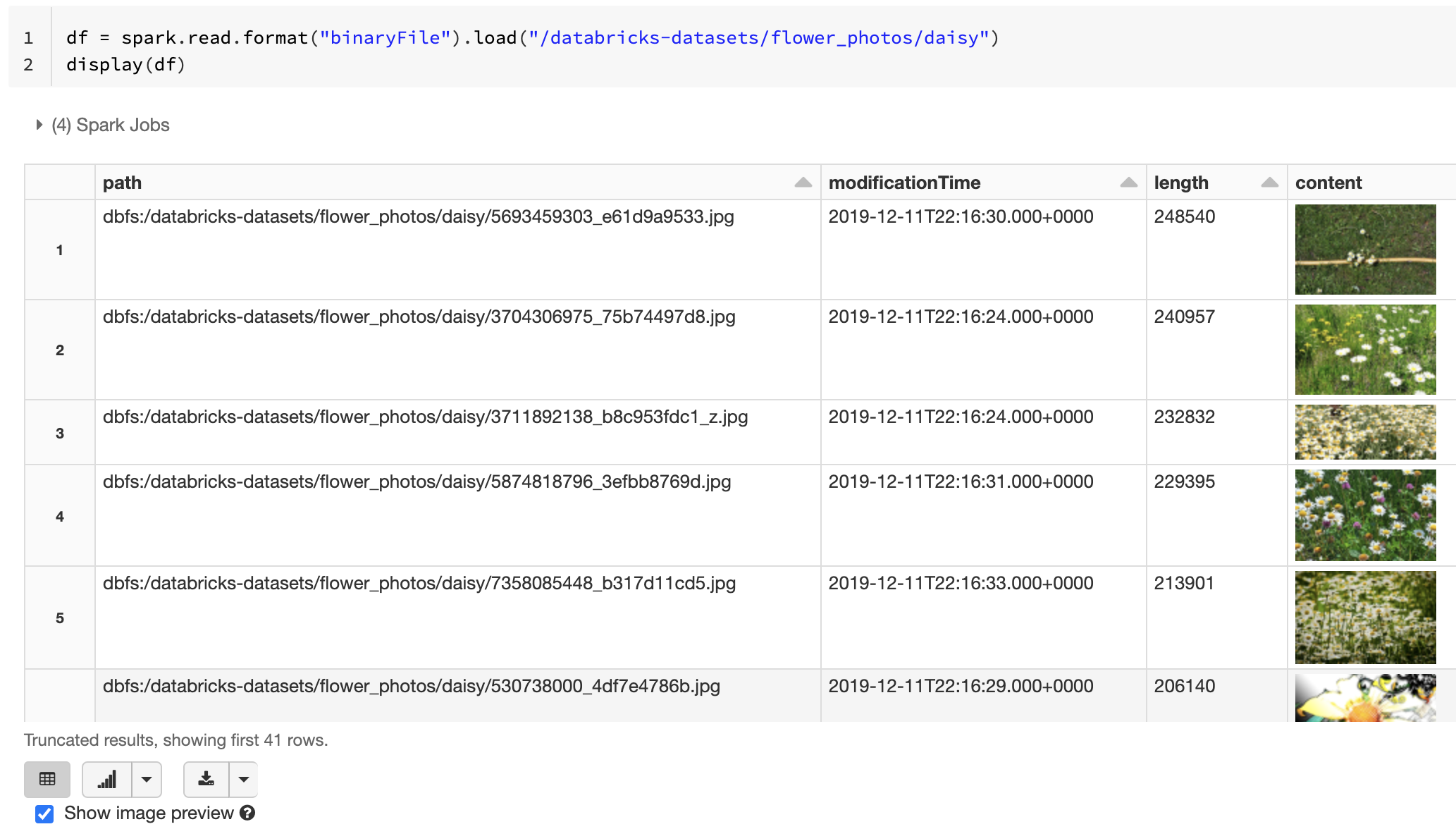
Alternativ können Sie die Bildvorschau erzwingen, indem Sie die Option mimeType mit einem Zeichenfolgenwert "image/*" verwenden, um die Binärspalte zu kommentieren. Bilder werden basierend auf ihren Formatinformationen im binären Inhalt decodiert. Unterstützte Bildtypen sind bmp, gif, jpeg und png. Nicht unterstützte Dateien werden mit einem Symbol für ein defektes Bild angezeigt.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon

Siehe Referenzlösung für Bildanwendungen für den empfohlenen Workflow zum Umgang mit Image-Daten.
Optionen
Zum Laden von Dateien mit Pfaden, die einem bestimmten Globmuster entsprechen, während das Verhalten der Partitionsermittlung beibehalten wird, können Sie die Option pathGlobFilter verwenden. Der folgende Code liest mittels Partitionsermittlung alle JPG-Dateien aus dem Eingabeverzeichnis:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
Wenn Sie die Partitionsermittlung ignorieren und Dateien im Eingabeverzeichnis rekursiv durchsuchen möchten, verwenden Sie die Option recursiveFileLookup. Mit dieser Option werden geschachtelte Verzeichnisse auch dann durchsucht, wenn ihre Namen nicht einem Partitionsbenennungsschema wie date=2019-07-01 folgen.
Der folgende Code liest alle JPG-Dateien rekursiv aus dem Eingabeverzeichnis und ignoriert die Partitionsermittlung:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Ähnliche APIs sind für Scala, Java und R vorhanden.
Hinweis
Um die Leseleistung beim Laden von Daten zu verbessern, empfiehlt Azure Databricks, Daten aus Binärdateien mithilfe von Delta-Tabellen zu speichern:
df.write.save("<path-to-table>")