Express.js App konvertiert Text in Sprache mit Azure AI Speech
Fügen Sie in diesem Lernprogramm azure AI Speech zu einer vorhandenen Express.js-App hinzu, um eine Konvertierung von Text zu Sprache mithilfe des Azure AI Speech-Diensts hinzuzufügen. Bei der Text-zu-Sprache-Konvertierung erhalten Sie Audiodaten, ohne dass Sie diese manuell generieren müssen.
Dieses Lernprogramm zeigt 3 verschiedene Möglichkeiten zum Konvertieren von Text in Sprache aus Azure AI Speech:
- Direktes Abrufen der Audiodaten durch den JavaScript-Code des Clients
- Abrufen der Audiodaten durch den JavaScript-Code des Servers aus einer Datei (*.MP3)
- Abrufen der Audiodaten aus In-Memory-arrayBuffer durch den JavaScript-Code des Servers
Anwendungsarchitektur
Im Tutorial wird eine minimal ausgestattete Express.js-App verwendet, und die Funktionen werden über eine Kombination der folgenden Elemente hinzugefügt:
- Neue Route für die Server-API für die Text-zu-Sprache-Konvertierung, bei der ein MP3-Stream zurückgegeben wird
- Neue Route für ein HTML-Formular, damit Sie Ihre Informationen eingeben können
- Neues HTML-Formular mit JavaScript zum Durchführen eines clientseitigen Aufrufs des Speech-Diensts
Diese Anwendung verfügt über drei verschiedene Aufrufe für die Sprache-in-Text-Konvertierung:
- Mit dem ersten Serveraufruf wird eine Datei auf dem Server erstellt, die dann an den Client zurückgegeben wird. Dieser Aufruf wird normalerweise für längere oder mehr als einmal bereitzustellende Texte genutzt.
- Der zweite Serveraufruf ist für kürzeren Begriffstext vorgesehen und wird im Arbeitsspeicher gehalten, bevor er an den Client zurückgegeben wird.
- Der Clientaufruf veranschaulicht einen direkten Aufruf des Speech-Diensts per SDK. Sie können diesen Aufruf auch nutzen, wenn Sie eine reine Clientanwendung ohne Server verwenden.
Voraussetzungen
Node.js LTS – auf Ihrem lokalen Computer installiert.
Visual Studio Code (installiert auf Ihrem lokalen Computer)
Azure App Service-Erweiterung für VS Code (installiert aus VS Code)
Git zum Pushen an GitHub, wodurch wiederum die GitHub-Aktion aktiviert wird
Verwenden von Azure Cloud Shell mithilfe der Bash

Wenn Sie möchten, können Sie auch die Azure CLI installieren, um CLI-Verweisbefehle auszuführen.
- Wenn Sie eine lokale Installation verwenden, melden Sie sich mithilfe des Befehls az login bei der Azure CLI an. Führen Sie die in Ihrem Terminal angezeigten Schritte aus, um den Authentifizierungsprozess abzuschließen. Weitere Anmeldeoptionen finden Sie unter Anmelden mit der Azure CLI.
- Installieren Sie die Azure CLI-Erweiterungen bei der ersten Verwendung, wenn Sie dazu aufgefordert werden. Weitere Informationen zu Erweiterungen finden Sie unter Verwenden von Erweiterungen mit der Azure CLI.
- Führen Sie az version aus, um die installierte Version und die abhängigen Bibliotheken zu ermitteln. Führen Sie az upgrade aus, um das Upgrade auf die aktuelle Version durchzuführen.
Herunterladen des Express.js-Beispielrepositorys
Verwenden Sie Git, um das Express.js-Beispielrepository auf Ihrem lokalen Computer zu klonen.
git clone https://github.com/Azure-Samples/js-e2e-express-serverWechseln Sie in das neue Verzeichnis mit dem Beispiel.
cd js-e2e-express-serverÖffnen Sie das Projekt in Visual Studio Code.
code .Öffnen Sie in Visual Studio Code ein neues Terminal, und installieren Sie die Projektabhängigkeiten.
npm install
Installieren des Azure AI Speech SDK für JavaScript
Installieren Sie im Visual Studio Code-Terminal das Azure AI Speech SDK.
npm install microsoft-cognitiveservices-speech-sdk
Erstellen eines Speech-Moduls für die Express.js-App
Erstellen Sie im Ordner
srceine Datei mit dem Namenazure-cognitiveservices-speech.js, um das Speech SDK in die Express.js-Anwendung zu integrieren.Fügen Sie den folgenden Code hinzu, um Abhängigkeiten zu pullen und eine Funktion für die Text-zu-Sprache-Konvertierung zu erstellen.
// azure-cognitiveservices-speech.js const sdk = require('microsoft-cognitiveservices-speech-sdk'); const { Buffer } = require('buffer'); const { PassThrough } = require('stream'); const fs = require('fs'); /** * Node.js server code to convert text to speech * @returns stream * @param {*} key your resource key * @param {*} region your resource region * @param {*} text text to convert to audio/speech * @param {*} filename optional - best for long text - temp file for converted speech/audio */ const textToSpeech = async (key, region, text, filename)=> { // convert callback function to promise return new Promise((resolve, reject) => { const speechConfig = sdk.SpeechConfig.fromSubscription(key, region); speechConfig.speechSynthesisOutputFormat = 5; // mp3 let audioConfig = null; if (filename) { audioConfig = sdk.AudioConfig.fromAudioFileOutput(filename); } const synthesizer = new sdk.SpeechSynthesizer(speechConfig, audioConfig); synthesizer.speakTextAsync( text, result => { const { audioData } = result; synthesizer.close(); if (filename) { // return stream from file const audioFile = fs.createReadStream(filename); resolve(audioFile); } else { // return stream from memory const bufferStream = new PassThrough(); bufferStream.end(Buffer.from(audioData)); resolve(bufferStream); } }, error => { synthesizer.close(); reject(error); }); }); }; module.exports = { textToSpeech };- Parameter: Mit der Datei werden die Abhängigkeiten für die Nutzung des SDK, der Streams, der Puffer und des Dateisystems (fs) gepullt. Für die Funktion
textToSpeechwerden vier Argumente verwendet. Wenn ein Dateiname mit einem lokalen Pfad gesendet wird, wird der Text in eine Audiodatei konvertiert. Wenn kein Dateiname gesendet wird, wird ein In-Memory-Audiostream erstellt. - Speech SDK-Methode: Mit der Speech SDK-Methode synthesizer.speakTextAsync werden basierend auf der empfangenen Konfiguration unterschiedliche Typen zurückgegeben.
Die Methode gibt das Ergebnis zurück, das sich je nach dem, was die Methode zu tun hat, unterscheidet:
- Datei erstellen
- Erstellen eines In-Memory-Datenstroms als Array mit Puffern
- Audioformat: Das ausgewählte Audioformat ist MP3. Es gibt aber auch andere Formate und andere Methoden für die Audiokonfiguration.
Mit der lokalen Methode
textToSpeechwird die SDK-Rückruffunktion umschlossen und in eine Zusage konvertiert.- Parameter: Mit der Datei werden die Abhängigkeiten für die Nutzung des SDK, der Streams, der Puffer und des Dateisystems (fs) gepullt. Für die Funktion
Erstellen einer neuen Route für die Express.js-App
Öffnen Sie die Datei
src/server.js.Fügen Sie das Modul
azure-cognitiveservices-speech.jsoben in der Datei als Abhängigkeit hinzu:const { textToSpeech } = require('./azure-cognitiveservices-speech');Fügen Sie eine neue API-Route für den Aufruf der textToSpeech-Methode hinzu, die im vorherigen Abschnitt des Tutorials erstellt wurde. Fügen Sie diesen Code nach der
/api/helloRoute hinzu.// creates a temp file on server, the streams to client /* eslint-disable no-unused-vars */ app.get('/text-to-speech', async (req, res, next) => { const { key, region, phrase, file } = req.query; if (!key || !region || !phrase) res.status(404).send('Invalid query string'); let fileName = null; // stream from file or memory if (file && file === true) { fileName = `./temp/stream-from-file-${timeStamp()}.mp3`; } const audioStream = await textToSpeech(key, region, phrase, fileName); res.set({ 'Content-Type': 'audio/mpeg', 'Transfer-Encoding': 'chunked' }); audioStream.pipe(res); });Bei dieser Methode werden die erforderlichen und optionalen Parameter für die
textToSpeech-Methode aus der Abfragezeichenfolge verwendet. Wenn eine Datei erstellt werden muss, wird ein eindeutiger Dateiname entwickelt. DietextToSpeech-Methode wird asynchron aufgerufen, und das Ergebnis wird per Pipe-Zeichen mit dem Antwortobjekt (res) verbunden.
Aktualisieren der Clientwebseite mit einem Formular
Aktualisieren Sie die HTML-Webseite des Clients mit einem Formular, mit dem die erforderlichen Parameter erfasst werden. Der optionale Parameter wird basierend darauf übergeben, welches Audiosteuerelement der Benutzer auswählt. Da dieses Tutorial ein Verfahren zum Aufrufen des Azure Speech-Diensts über den Client umfasst, ist auch der entsprechende JavaScript-Code angegeben.
Öffnen Sie die Datei /public/client.html, und ersetzen Sie ihren Inhalt durch Folgendes:
<!DOCTYPE html>
<html lang="en">
<head>
<title>Microsoft Cognitive Services Demo</title>
<meta charset="utf-8" />
</head>
<body>
<div id="content" style="display:none">
<h1 style="font-weight:500;">Microsoft Cognitive Services Speech </h1>
<h2>npm: microsoft-cognitiveservices-speech-sdk</h2>
<table width="100%">
<tr>
<td></td>
<td>
<a href="https://docs.microsoft.com/azure/cognitive-services/speech-service/get-started" target="_blank">Azure
Cognitive Services Speech Documentation</a>
</td>
</tr>
<tr>
<td align="right">Your Speech Resource Key</td>
<td>
<input id="resourceKey" type="text" size="40" placeholder="Your resource key (32 characters)" value=""
onblur="updateSrc()">
</tr>
<tr>
<td align="right">Your Speech Resource region</td>
<td>
<input id="resourceRegion" type="text" size="40" placeholder="Your resource region" value="eastus"
onblur="updateSrc()">
</td>
</tr>
<tr>
<td align="right" valign="top">Input Text (max 255 char)</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:50px" maxlength="255"
onblur="updateSrc()">all good men must come to the aid</textarea></td>
</tr>
<tr>
<td align="right">
Stream directly from Azure Cognitive Services
</td>
<td>
<div>
<button id="clientAudioAzure" onclick="getSpeechFromAzure()">Get directly from Azure</button>
</div>
</td>
</tr>
<tr>
<td align="right">
Stream audio from file on server</td>
<td>
<audio id="serverAudioFile" controls preload="none" onerror="DisplayError()">
</audio>
</td>
</tr>
<tr>
<td align="right">Stream audio from buffer on server</td>
<td>
<audio id="serverAudioStream" controls preload="none" onerror="DisplayError()">
</audio>
</td>
</tr>
</table>
</div>
<!-- Speech SDK reference sdk. -->
<script
src="https://cdn.jsdelivr.net/npm/microsoft-cognitiveservices-speech-sdk@latest/distrib/browser/microsoft.cognitiveservices.speech.sdk.bundle-min.js">
</script>
<!-- Speech SDK USAGE -->
<script>
// status fields and start button in UI
var phraseDiv;
var resultDiv;
// subscription key and region for speech services.
var resourceKey = null;
var resourceRegion = "eastus";
var authorizationToken;
var SpeechSDK;
var synthesizer;
var phrase = "all good men must come to the aid"
var queryString = null;
var audioType = "audio/mpeg";
var serverSrc = "/text-to-speech";
document.getElementById('serverAudioStream').disabled = true;
document.getElementById('serverAudioFile').disabled = true;
document.getElementById('clientAudioAzure').disabled = true;
// update src URL query string for Express.js server
function updateSrc() {
// input values
resourceKey = document.getElementById('resourceKey').value.trim();
resourceRegion = document.getElementById('resourceRegion').value.trim();
phrase = document.getElementById('phraseDiv').value.trim();
// server control - by file
var serverAudioFileControl = document.getElementById('serverAudioFile');
queryString += `%file=true`;
const fileQueryString = `file=true®ion=${resourceRegion}&key=${resourceKey}&phrase=${phrase}`;
serverAudioFileControl.src = `${serverSrc}?${fileQueryString}`;
console.log(serverAudioFileControl.src)
serverAudioFileControl.type = "audio/mpeg";
serverAudioFileControl.disabled = false;
// server control - by stream
var serverAudioStreamControl = document.getElementById('serverAudioStream');
const streamQueryString = `region=${resourceRegion}&key=${resourceKey}&phrase=${phrase}`;
serverAudioStreamControl.src = `${serverSrc}?${streamQueryString}`;
console.log(serverAudioStreamControl.src)
serverAudioStreamControl.type = "audio/mpeg";
serverAudioStreamControl.disabled = false;
// client control
var clientAudioAzureControl = document.getElementById('clientAudioAzure');
clientAudioAzureControl.disabled = false;
}
function DisplayError(error) {
window.alert(JSON.stringify(error));
}
// Client-side request directly to Azure Cognitive Services
function getSpeechFromAzure() {
// authorization for Speech service
var speechConfig = SpeechSDK.SpeechConfig.fromSubscription(resourceKey, resourceRegion);
// new Speech object
synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig);
synthesizer.speakTextAsync(
phrase,
function (result) {
// Success function
// display status
if (result.reason === SpeechSDK.ResultReason.SynthesizingAudioCompleted) {
// load client-side audio control from Azure response
audioElement = document.getElementById("clientAudioAzure");
const blob = new Blob([result.audioData], { type: "audio/mpeg" });
const url = window.URL.createObjectURL(blob);
} else if (result.reason === SpeechSDK.ResultReason.Canceled) {
// display Error
throw (result.errorDetails);
}
// clean up
synthesizer.close();
synthesizer = undefined;
},
function (err) {
// Error function
throw (err);
audioElement = document.getElementById("audioControl");
audioElement.disabled = true;
// clean up
synthesizer.close();
synthesizer = undefined;
});
}
// Initialization
document.addEventListener("DOMContentLoaded", function () {
var clientAudioAzureControl = document.getElementById("clientAudioAzure");
var resultDiv = document.getElementById("resultDiv");
resourceKey = document.getElementById('resourceKey').value;
resourceRegion = document.getElementById('resourceRegion').value;
phrase = document.getElementById('phraseDiv').value;
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
clientAudioAzure.disabled = false;
document.getElementById('content').style.display = 'block';
}
});
</script>
</body>
</html>
Hervorgehobene Zeilen in der Datei:
- Zeile 74: Das Azure Speech SDK wird mithilfe der
cdn.jsdelivr.netWebsite in die Clientbibliothek abgerufen, um das NPM-Paket bereitzustellen. - Zeile 102: Die
updateSrcMethode aktualisiert die URL der Audiosteuerelementesrcmit der Abfragezeichenfolge, einschließlich Schlüssel, Region und Text. - Zeile 137: Wenn ein Benutzer die
Get directly from AzureSchaltfläche auswählt, ruft die Webseite direkt von der Clientseite an Azure auf und verarbeitet das Ergebnis.
Erstellen einer Azure KI Speech-Ressource
Erstellen Sie die Speech-Ressource mit Azure CLI-Befehlen in einer Azure Cloud Shell-Instanz.
Melden Sie sich bei Azure Cloud Shell an. Hierfür müssen Sie sich in einem Browser mit einem Konto authentifizieren, das über die Berechtigung zur Verwendung eines gültigen Azure-Abonnements verfügt.
Erstellen Sie eine Ressourcengruppe für Ihre Speech-Ressource.
az group create \ --location eastus \ --name tutorial-resource-group-eastusErstellen Sie in der Ressourcengruppe eine Speech-Ressource.
az cognitiveservices account create \ --kind SpeechServices \ --location eastus \ --name tutorial-speech \ --resource-group tutorial-resource-group-eastus \ --sku F0Für diesen Befehl tritt ein Fehler auf, falls Ihre kostenlose Speech-Ressource bereits erstellt wurde.
Verwenden Sie den Befehl, um die Schlüsselwerte für die neue Speech-Ressource abzurufen.
az cognitiveservices account keys list \ --name tutorial-speech \ --resource-group tutorial-resource-group-eastus \ --output tableKopieren Sie einen der Schlüssel.
Sie verwenden den Schlüssel, indem Sie ihn in das Webformular der Express-App einfügen, um sich beim Azure Speech-Dienst zu authentifizieren.
Ausführen der Express.js-App für die Text-zu-Sprache-Konvertierung
Starten Sie die App mit dem folgenden Bash-Befehl.
npm startÖffnen Sie die Web-App in einem Browser.
http://localhost:3000Fügen Sie Ihren Speech-Schlüssel in das hervorgehobene Textfeld ein.
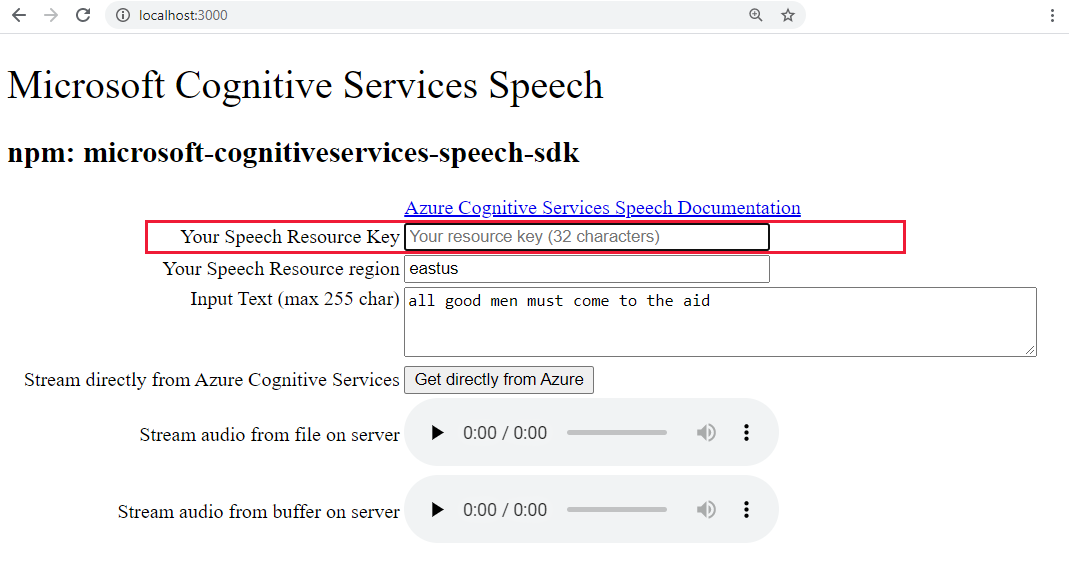
Wenn Sie möchten, können Sie den Text ändern.
Wählen Sie eine der drei Schaltflächen aus, um die Konvertierung in das Audioformat zu starten:
- Direktes Abrufen aus Azure: Clientseitiger Aufruf von Azure
- Audiosteuerelement für Audiodaten aus Datei
- Audiosteuerelement für Audiodaten aus Puffer
Unter Umständen kommt es zwischen der Auswahl des Steuerelements und der Wiedergabe der Audiodaten zu einer kurzen Verzögerung.
Erstellen einer neuen Azure App Service-Instanz in Visual Studio Code
Geben Sie in der Befehlspalette (STRG+UMSCHALT+P) "Web erstellen" ein, und wählen Sie Azure-App Dienst aus: Neue Web App erstellen... Erweitert. Sie verwenden den erweiterten Befehl anstelle der Linux-Standardeinstellungen, um die vollständige Kontrolle über die Bereitstellung zu haben, einschließlich Ressourcengruppe, App Service-Plan und Betriebssystem.
Gehen Sie bei den Aufforderungen wie folgt vor:
- Wählen Sie Ihr Abonnementkonto aus.
- Geben Sie unter Geben Sie einen global eindeutigen Namen ein einen Namen wie
my-text-to-speech-appein.- Der eingegebene Name muss innerhalb von Azure eindeutig sein. Verwenden Sie nur alphanumerische Zeichen („A - Z“, „a - z“ und „0 - 9“) und Bindestriche („-“).
- Wählen Sie
tutorial-resource-group-eastusals Ressourcengruppe aus. - Wählen Sie einen Runtimestapel einer Version aus, die
NodeundLTSbeinhaltet. - Wählen Sie das Linux-Betriebssystem aus.
- Wählen Sie Einen neuen App Services-Plan erstellen aus, und geben Sie einen Namen (etwa
my-text-to-speech-app-plan) an. - Wählen Sie den kostenlosen Tarif F1 aus. Wenn Ihr Abonnement bereits über eine kostenlose Web-App verfügt, wählen Sie den Tarif
Basicaus. - Wählen Sie für die Application Insights-Ressource die Option Vorerst überspringen aus.
- Wählen Sie den Standort
eastusaus.
Nach kurzer Zeit erhalten Sie von Visual Studio Code die Benachrichtigung, dass die Erstellung abgeschlossen ist. Schließen Sie die Benachrichtigung mit der Schaltfläche X.
Bereitstellen einer lokalen Express.js-App für eine App Service-Remoteinstanz in Visual Studio Code
Da die Web-App nun vorhanden ist, können Sie Ihren Code über den lokalen Computer bereitstellen. Wählen Sie das Azure-Symbol aus, um den Azure App Service-Explorer zu öffnen. Erweitern Sie anschließend Ihren Abonnementknoten, klicken Sie mit der rechten Maustaste auf den Namen der gerade erstellten Web-App, und wählen Sie In Web-App bereitstellen aus.
Wählen Sie bei Bereitstellungsaufforderungen den Stammordner der Express.js-App, erneut Ihr Abonnementkonto und dann den Namen der zuvor erstellten Web-App
my-text-to-speech-appaus.Wenn Sie bei der Bereitstellung unter Linux zur Ausführung von
npm installaufgefordert werden, wählen Sie Ja aus, wenn Sie aufgefordert werden, Ihre Konfiguration für die Ausführung vonnpm installauf dem Zielserver zu aktualisieren.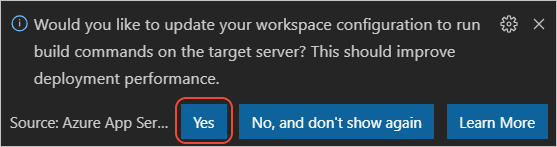
Wählen Sie nach Abschluss der Bereitstellung in der Aufforderung die Option Website durchsuchen aus, um Ihre neu bereitgestellte Web-App anzuzeigen.
(Optional): Sie können Änderungen an Ihren Codedateien vornehmen und dann die Bereitstellung in Web App in der Azure-App Diensterweiterung verwenden, um die Web-App zu aktualisieren.
Streamen von Remotedienstprotokollen in Visual Studio Code
Zeigen Sie mithilfe von Aufrufen von console.log eine beliebige Ausgabe an, die die ausgeführte App generiert. Diese Ausgabe wird im Fenster Ausgabe in Visual Studio Code angezeigt.
Klicken Sie im Azure App Service-Explorer mit der rechten Maustaste auf Ihren neuen App-Knoten, und wählen Sie Start Streaming Logs (Streamen der Protokolle starten) aus.
Starting Live Log Stream ---
Aktualisieren Sie die Webseite im Browser einige Male, um die zusätzliche Protokollausgabe anzuzeigen.
Bereinigen der Ressourcen durch das Entfernen der Ressourcengruppe
Nach Abschluss dieses Tutorials müssen Sie die Ressourcengruppe entfernen, in der die Ressource enthalten ist, um sicherzustellen, dass Ihnen hierfür keine weiteren Nutzungskosten in Rechnung gestellt werden.
Verwenden Sie in Azure Cloud Shell den Azure CLI-Befehl, um die Ressourcengruppe zu löschen:
az group delete --name tutorial-resource-group-eastus -y
Die Ausführung dieses Befehls kann mehrere Minuten dauern.