Erfahren Sie, wie Sie Ereignisnachrichten in Azure Data Lake Storage Gen2 mit der Apache Flink® DataStream-API schreiben
Hinweis
Azure HDInsight on AKS wird am 31. Januar 2025 eingestellt. Vor dem 31. Januar 2025 müssen Sie Ihre Workloads zu Microsoft Fabric oder einem gleichwertigen Azure-Produkt migrieren, um eine abruptes Beendigung Ihrer Workloads zu vermeiden. Die verbleibenden Cluster in Ihrem Abonnement werden beendet und vom Host entfernt.
Bis zum Einstellungsdatum ist nur grundlegende Unterstützung verfügbar.
Wichtig
Diese Funktion steht derzeit als Vorschau zur Verfügung. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure-Vorschauen enthalten weitere rechtliche Bestimmungen, die für Azure-Features in Betaversionen, in Vorschauversionen oder anderen Versionen gelten, die noch nicht allgemein verfügbar gemacht wurden. Informationen zu dieser spezifischen Vorschau finden Sie unter Informationen zur Vorschau von Azure HDInsight on AKS. Bei Fragen oder Funktionsvorschlägen senden Sie eine Anfrage an AskHDInsight mit den entsprechenden Details, und folgen Sie uns für weitere Updates in der Azure HDInsight-Community.
Apache Flink verwendet Dateisysteme, um Daten sowohl für die Ergebnisse von Anwendungen als auch für die Fehlertoleranz und Wiederherstellung zu nutzen und dauerhaft zu speichern. In diesem Artikel erfahren Sie, wie Sie Ereignisnachrichten in Azure Data Lake Storage Gen2 mit der DataStream-API schreiben.
Voraussetzungen
- Apache Flink-Cluster auf HDInsight auf AKS
- Apache Kafka-Cluster in HDInsight
- Sie müssen sicherstellen, dass die Netzwerkeinstellungen beachtet werden, wie unter Verwendung von Apache Kafka auf HDInsight beschrieben. Stellen Sie sicher, dass sich AKS- und HDInsight-Cluster mit HDInsight im selben virtuellen Netzwerk befinden.
- Verwenden von MSI für den Zugriff auf ADLS Gen2
- IntelliJ für die Entwicklung auf einem virtuellen Azure-Computer in HDInsight auf AKS Virtual Network
Apache Flink FileSystem-Connector
Dieser Dateisystem-Connector bietet die gleichen Garantien für BATCH und STREAMING und ist so konzipiert, dass genau einmal Semantik für die STREAMING-Ausführung bereitgestellt wird. Weitere Informationen finden Sie unter Flink DataStream-Dateisystem.
Apache Kafka-Connector
Flink bietet einen Apache Kafka-Connector zum Lesen von Daten aus und Schreiben von Daten in Kafka-Themen mit Genau-Einmal-Garantien. Weitere Informationen finden Sie unter Apache Kafka-Connector.
Erstellen des Projekts für Apache Flink
pom.xml on IntelliJ IDEA
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Programm für ADLS Gen2 Sink
abfsGen2.java
Hinweis
Ersetzen Sie Apache Kafka auf HDInsight-Cluster bootStrapServers durch Ihre eigenen Broker für Kafka 3.2.
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
Packen Sie die JAR-Datei, und übermitteln Sie sie an Apache Flink.
Laden Sie die JAR-Datei in ABFS hoch.

Übergeben Sie die Informationen der Auftrags-JAR-Datei bei der
AppMode-Clustererstellung.
Hinweis
Stellen Sie sicher, dass Sie „classloader.resolve-order“ als „parent-first“ und „hadoop.classpath.enable“ als
truehinzufügen.Wählen Sie „Auftragsprotokollaggregation“ aus, um Auftragsprotokolle in ein Speicherkonto zu übertragen.

Sie können sehen, dass der Auftrag ausgeführt wird.





Überprüfen von Streamingdaten auf ADLS Gen2
Das click_events-Streaming in ADLS Gen2 ist zu sehen.

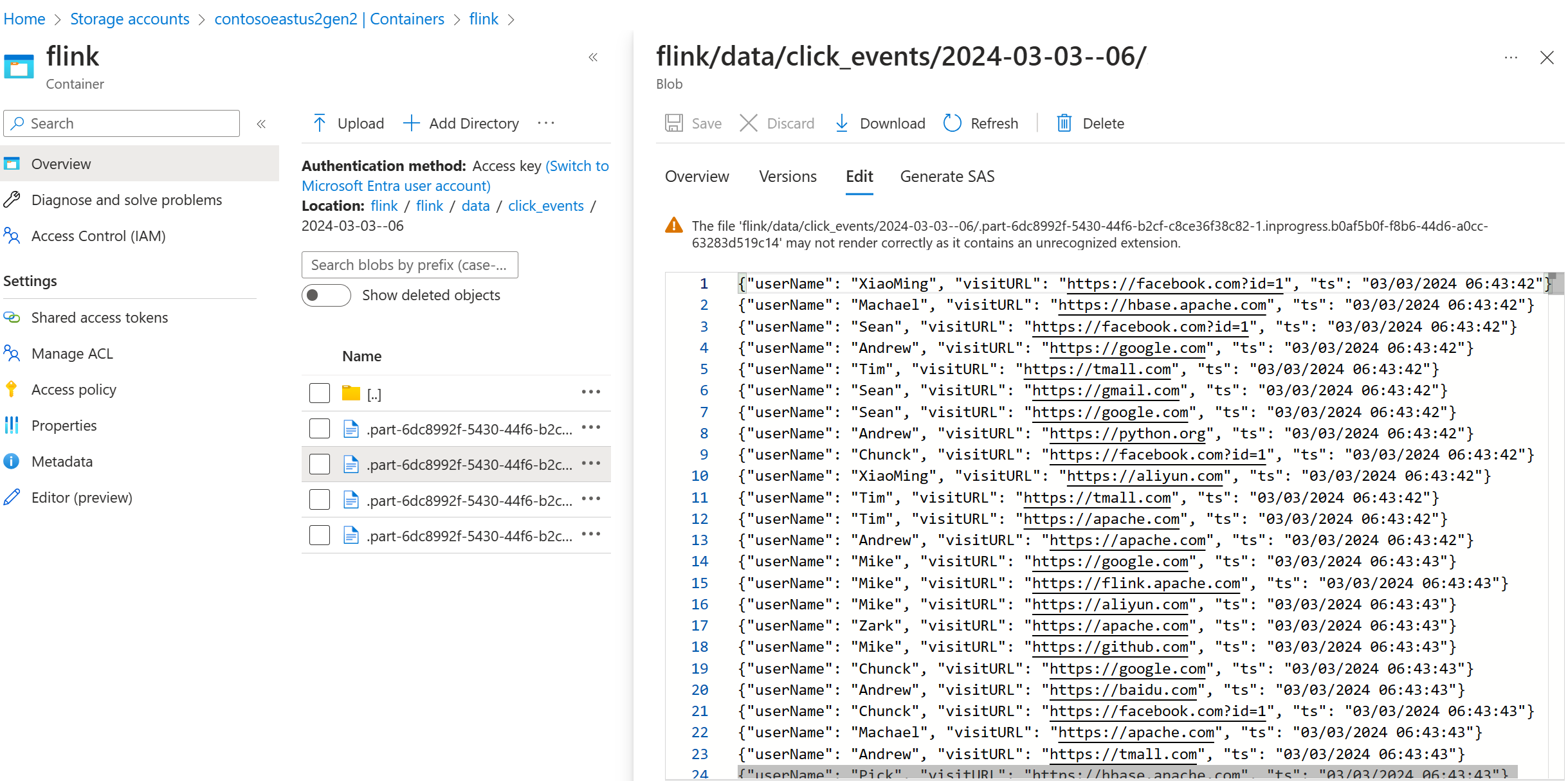
Sie können eine rollierende Richtlinie angeben, die die in Bearbeitung befindliche Teildatei bei einer der folgenden drei Bedingungen rolliert:
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
Verweis
- Apache Kafka-Connector
- Flink DataStream-Dateisystem
- Apache Flink-Website
- Apache, Apache Kafka, Kafka, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Handelsmarken der Apache Software Foundation (ASF).