Konfigurieren des Cachings
Hinweis
Azure HDInsight on AKS wird am 31. Januar 2025 eingestellt. Vor dem 31. Januar 2025 müssen Sie Ihre Workloads zu Microsoft Fabric oder einem gleichwertigen Azure-Produkt migrieren, um eine abruptes Beendigung Ihrer Workloads zu vermeiden. Die verbleibenden Cluster in Ihrem Abonnement werden beendet und vom Host entfernt.
Bis zum Einstellungsdatum ist nur grundlegende Unterstützung verfügbar.
Wichtig
Diese Funktion steht derzeit als Vorschau zur Verfügung. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure-Vorschauen enthalten weitere rechtliche Bestimmungen, die für Azure-Features in Betaversionen, in Vorschauversionen oder anderen Versionen gelten, die noch nicht allgemein verfügbar gemacht wurden. Informationen zu dieser spezifischen Vorschau finden Sie unter Informationen zur Vorschau von Azure HDInsight on AKS. Bei Fragen oder Funktionsvorschlägen senden Sie eine Anfrage an AskHDInsight mit den entsprechenden Details, und folgen Sie uns für weitere Updates in der Azure HDInsight-Community.
Das Abfragen des Objektspeichers mithilfe des Hive-Connectors ist ein gängiger Anwendungsfall für Trino. Dieser Vorgang umfasst häufig das Senden großer Datenmengen. Objekte werden aus HDFS oder einem anderen unterstützten Objektspeicher von mehreren Workern abgerufen und von diesen verarbeitet. Wiederholte Abfragen mit unterschiedlichen Parametern oder sogar unterschiedliche Abfragen von verschiedenen Benutzer*innen, greifen häufig auf dieselben Objekte zu und übertragen sie.
In HDInsight on AKS wurde eine Funktion zum Zwischenspeichern der Endergebnisse für Trino hinzugefügt, die die folgenden Vorteile bietet:
- Verringern der Auslastung des Objektspeichers
- Verbessern der Abfrageleistung
- Reduzieren der Abfragekosten
Optionen für die Zwischenspeicherung
Verschiedene Optionen für die Zwischenspeicherung:
- Zwischenspeichern der Endergebnisse: Wenn diese Option aktiviert ist (im Abschnitt zur Konfiguration der Koordinatorkomponente), wird ein Ergebnis für alle Abfragen für alle Kataloge auf einer Koordinator-VM zwischengespeichert.
- Zwischenspeichern von Hive-/Iceberg-/Delta Lake-Katalogen: Wenn diese Option (für einen bestimmten Katalog des entsprechenden Typs) aktiviert ist, werden geteilte Daten für jede Abfrage innerhalb des Clusters auf Worker-VMs zwischengespeichert.
Zwischenspeichern von Endergebnissen
Das Zwischenspeichern von Endergebnissen kann auf zwei Arten konfiguriert werden:
Die verfügbaren Konfigurationsparameter sind:
| Eigenschaft | Standard | Beschreibung |
|---|---|---|
query.cache.enabled |
false | Bei „true“ wird das Zwischenspeichern von Endergebnissen aktiviert. |
query.cache.ttl |
- | Definiert einen Zeitpunkt, bis zu dem Cachedaten aufbewahrt werden, bevor sie entfernt werden. Beispiel: 10m, 1h |
query.cache.disk-usage-percentage |
80 | Prozentsatz des Speicherplatzes, der für zwischengespeicherte Daten verwendet wird. |
query.cache.max-result-data-size |
0 | Maximale Datengröße für ein Ergebnis. Wird dieser Wert überschritten, werden die Ergebnisse nicht zwischengespeichert. |
Hinweis
Beim Zwischenspeichern von Endergebnissen werden ein Abfrageplan und TTL als Cacheschlüssel verwendet.
Das Zwischenspeichern von Endergebnissen kann auch über die folgenden Sitzungsparameter gesteuert werden:
| Sitzungsparameter | Standard | Beschreibung |
|---|---|---|
query_cache_enabled |
Ursprünglicher Konfigurationswert | Aktiviert/deaktiviert die Zwischenspeicherung von Endergebnissen für eine Abfrage/Sitzung. |
query_cache_ttl |
Ursprünglicher Konfigurationswert | Definiert einen Zeitpunkt, bis zu dem Cachedaten aufbewahrt werden, bevor sie entfernt werden. |
query_cache_max_result_data_size |
Ursprünglicher Konfigurationswert | Maximale Datengröße für ein Ergebnis. Wird dieser Wert überschritten, werden die Ergebnisse nicht zwischengespeichert. |
query_cache_forced_refresh |
false | Wenn dieser Wert auf „true“ festgelegt ist, wird das Zwischenspeichern der Abfrageausführung erzwungen, das heißt, das Ergebnis ersetzt vorhandene zwischengespeicherte Daten, sofern vorhanden. |
Hinweis
Sitzungsparameter können für eine Sitzung (z. B. bei Verwendung der Trino CLI) oder vor Abfragetext in mehreren Anweisungen festgelegt werden. Ein auf ein Objekt angewendeter
set session query_cache_enabled=true;
select cust.name, *
from tpch.tiny.orders
join tpch.tiny.customer as cust on cust.custkey = orders.custkey
order by cust.name
limit 10;
Endergebniszwischenspeicherung erzeugt JMX-Metriken, die mithilfe von verwaltetem Prometheus und Grafana angezeigt werden können. Folgende Metriken sind verfügbar:
| Metrik | Beschreibung |
|---|---|
trino_cache_cachestats_requestcount |
Die Gesamtanzahl der Abfragen, die die Cacheebene durchlaufen. Diese Zahl enthält keine Abfragen, die mit deaktiviertem Cache ausgeführt werden. |
trino_cache_cachestats_hitcount |
Die Anzahl der Cachetreffer, d. h. die Anzahl der Abfragen, wenn Daten verfügbar und aus dem Cache zurückgegeben wurden. |
trino_cache_cachestats_misscount |
Die Anzahl der Cachefehler, d. h. die Anzahl der Abfragen, wenn Daten nicht verfügbar waren und zwischengespeichert werden mussten. |
trino_cache_cachestats_hitrate |
Prozentuale Darstellung von Cachetreffern in Relation zur Gesamtzahl der Abfragen. |
trino_cache_cachestats_totalevictedcount |
Anzahl zwischengespeicherter Abfragen, die aus dem Cache entfernt wurden. |
trino_cache_cachestats_totalbytesfromsource |
Anzahl der von der Quelle gelesenen Bytes. |
trino_cache_cachestats_totalbytesfromcache |
Anzahl der vom Cache gelesenen Bytes. |
trino_cache_cachestats_totalcachedbytes |
Gesamtanzahl zwischengespeicherter Bytes. |
trino_cache_cachestats_totalevictedbytes |
Gesamtanzahl gelöschter Bytes. |
trino_cache_cachestats_spaceused |
Aktuelle Größe des Caches. |
trino_cache_cachestats_cachereadfailures |
Anzahl der Fälle, in denen Daten aufgrund eines Fehlers nicht aus dem Cache gelesen werden können. |
trino_cache_cachestats_cachewritefailures |
Anzahl der Fälle, in denen Daten aufgrund eines Fehlers nicht in den Cache geschrieben werden können. |
Über das Azure-Portal
Melden Sie sich beim Azure-Portal an.
Geben Sie in die Suchleiste des Azure-Portals den Suchbegriff „HDInsight on AKS-Cluster“ ein, und wählen Sie in der Dropdownliste „Azure HDInsight on AKS-Cluster“ aus.

Wählen Sie auf der Seite mit der Liste den Namen Ihres Clusters aus.

Navigieren Sie zum Blatt Konfigurationsverwaltung.
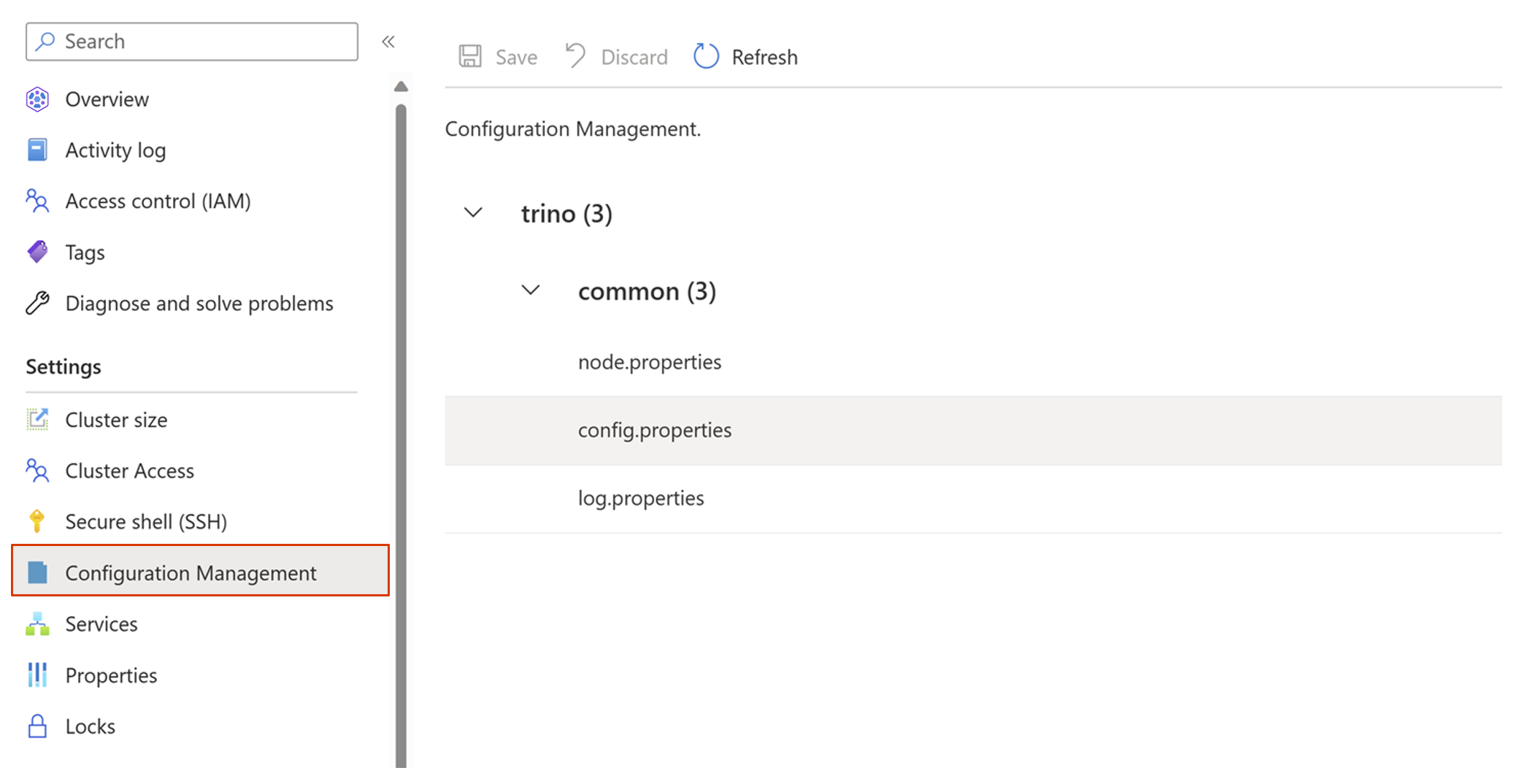
Wechseln Sie zu „config.properties“ > „Benutzerdefinierte Konfigurationen“, und klicken Sie dann auf Hinzufügen.
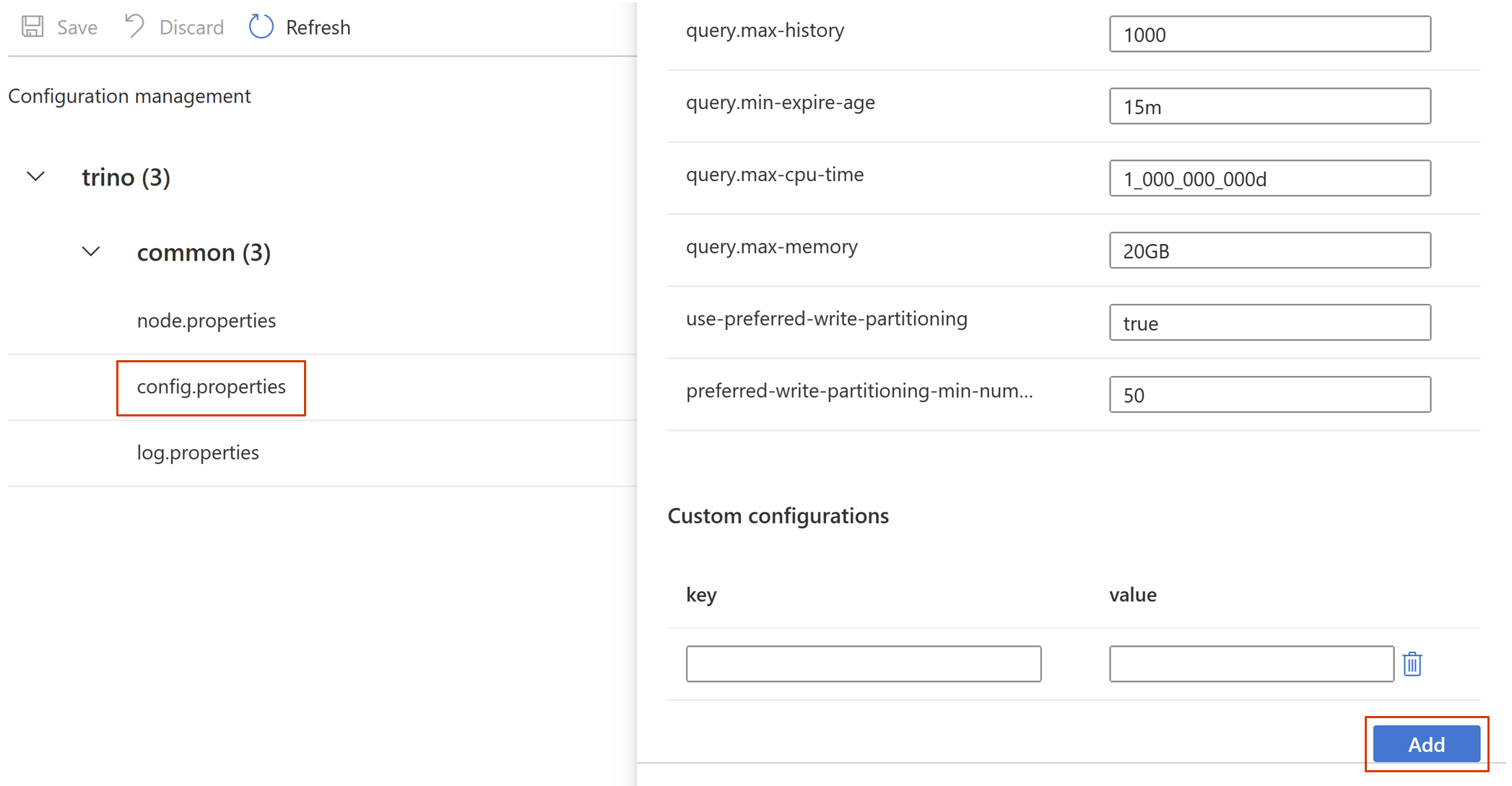
Legen Sie die erforderlichen Eigenschaften fest, und klicken Sie auf OK.

Speichern Sie die Konfiguration.

Per ARM-Vorlage
Voraussetzungen
- Ein betriebsbereiter Trino-Cluster mit HDInsight on AKS.
- Erstellen einer ARM-Vorlage für Ihren Cluster
- Überprüfen eines Beispielclusters basierend auf einer ARM-Vorlage
- Kenntnisse in der Erstellung und Bereitstellung von ARM-Vorlagen
Sie müssen die Eigenschaften in der Koordinatorkomponente im Abschnitt properties.clusterProfile.serviceConfigsProfiles der ARM-Vorlage definieren.
Im folgenden Beispiel wird veranschaulicht, wo die Eigenschaften hinzugefügt werden.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"resources": [
{
"type": "microsoft.hdinsight/clusterpools/clusters",
"apiVersion": "<api-version>",
"name": "<cluster-pool-name>/<cluster-name>",
"location": "<region, e.g. westeurope>",
"tags": {},
"properties": {
"clusterType": "Trino",
"clusterProfile": {
"serviceConfigsProfiles": [
{
"serviceName": "trino",
"configs": [
{
"component": "coordinator",
"files": [
{
"fileName": "config.properties",
"values": {
"query.cache.enabled": "true",
"query.cache.ttl": "10m"
}
}
]
}
]
}
]
}
}
}
]
}
Hive-/Iceberg-/Delta Lake-Zwischenspeicherung
Alle drei Connectors verwenden die gleichen Parameter, die auch unter Hive-Zwischenspeicherung beschrieben sind.
Hinweis
Bestimmte Parameter sind nicht konfigurierbar und werden immer auf ihre Standardwerte festgelegt:
hive.cache.data-transfer-port=8898
hive.cache.bookkeeper-port=8899
hive.cache.location=/etc/trino/cache
hive.cache.disk-usage-percentage=80
Im folgenden Beispiel wird veranschaulicht, wo die Eigenschaften zum Aktivieren der Hive-Zwischenspeicherung mithilfe der ARM-Vorlage hinzugefügt werden.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"resources": [
{
"type": "microsoft.hdinsight/clusterpools/clusters",
"apiVersion": "<api-version>",
"name": "<cluster-pool-name>/<cluster-name>",
"location": "<region, e.g. westeurope>",
"tags": {},
"properties": {
"clusterType": "Trino",
"clusterProfile": {
"serviceConfigsProfiles": [
{
"serviceName": "trino",
"configs": [
{
"component": "catalogs",
"files": [
{
"fileName": "hive1.properties",
"values": {
"connector.name": "hive"
"hive.cache.enabled": "true",
"hive.cache.ttl": "5d"
}
}
]
}
]
}
]
}
}
}
]
}
Stellen Sie die aktualisierte ARM-Vorlage bereit, um die Änderungen in Ihrem Cluster widerzuspiegeln. Erfahren Sie, wie Sie eine ARM-Vorlage bereitstellen.