Beispiel für Apache Spark-Streaming (DStream) mit Apache Kafka in HDInsight
Erfahren Sie, wie Sie Apache Spark verwenden, um Daten mithilfe von DStreams in oder aus Apache Kafka in HDInsight zu streamen. In diesem Beispiel wird ein auf dem Spark-Cluster ausgeführtes Jupyter Notebook verwendet.
Hinweis
Mit den in diesem Dokument beschriebenen Schritten wird eine Azure-Ressourcengruppe erstellt, die jeweils einen Spark- und einen Kafka-Cluster in HDInsight beinhaltet. Die Cluster befinden sich innerhalb eines virtuellen Azure-Netzwerks, wodurch Spark- und Kafka-Cluster direkt miteinander kommunizieren können.
Denken Sie nach dem Ausführen der Schritte in diesem Dokument daran, die Cluster zu löschen, um das Anfallen von Gebühren zu verhindern.
Wichtig
Dieses Beispiel verwendet DStreams, also eine ältere Spark-Streamingtechnologie. Ein Beispiel, das neuere Spark-Streamingfeatures verwendet, finden Sie im Dokument Verwenden von strukturiertem Spark-Streaming mit Apache Kafka in HDInsight.
Erstellen von Clustern
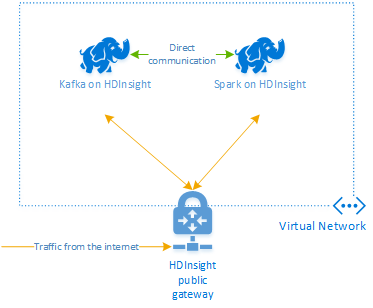
Apache Kafka in HDInsight ermöglicht keinen Zugriff auf die Kafka-Broker über das öffentliche Internet. Komponenten, die mit Kafka kommunizieren, müssen sich jeweils im selben virtuellen Azure-Netzwerk befinden wie die Knoten im Kafka-Cluster. Für dieses Beispiel sind die Kafka- und Spark-Cluster in einem virtuellen Azure-Netzwerk angeordnet. Im folgenden Diagramm ist dargestellt, wie der Kommunikationsfluss zwischen den Clustern abläuft:
Hinweis
Kafka selbst ist zwar auf die Kommunikation innerhalb des virtuellen Netzwerks beschränkt, aber auf andere Dienste im Cluster, z.B. SSH und Ambari, kann über das Internet zugegriffen werden. Weitere Informationen zu den öffentlichen Ports, die für HDInsight verfügbar sind, finden Sie unter Von HDInsight verwendete Ports und URIs.
Es ist zwar möglich, ein virtuelles Azure-Netzwerk, einen Kafka-Cluster und einen Spark-Cluster manuell zu erstellen, aber mit einer Azure Resource Manager-Vorlage ist dies erheblich einfacher. Führen Sie die folgenden Schritte aus, um ein virtuelles Azure-Netzwerk, Kafka- und Spark-Cluster für Ihr Azure-Abonnement bereitzustellen.
Verwenden Sie die folgende Schaltfläche, um sich bei Azure anzumelden, und öffnen Sie die Vorlage im Azure-Portal.

Warnung
Um die Verfügbarkeit von Kafka in HDInsight zu gewährleisten, muss der Cluster mindestens vier Workerknoten enthalten. Diese Vorlage erstellt einen Kafka-Cluster mit vier Workerknoten.
Mit dieser Vorlage wird ein HDInsight 4.0-Cluster für Kafka und Spark erstellt.
Verwenden Sie die folgenden Informationen, um die Einträge auf dem Abschnitt Benutzerdefinierte Bereitstellung aufzufüllen:
Eigenschaft Wert Resource group Erstellen Sie eine Gruppe, oder wählen Sie eine vorhandene Gruppe aus. Location Wählen Sie einen Standort in Ihrer Nähe aus. Basisclustername Dieser Wert wird als Basisname für Spark- und Kafka-Cluster verwendet. Wenn Sie beispielsweise hdistreaming eingeben, werden ein Spark-Cluster mit dem Namen spark-hdistreaming und ein Kafka-Cluster mit dem Namen kafka-hdistreaming erstellt. Benutzername für Clusteranmeldung Der Administratorbenutzername für die Spark- und Kafka-Cluster. Kennwort für Clusteranmeldung Das Administratorbenutzerkennwort für die Spark- und Kafka-Cluster. SSH-Benutzername SSH-Benutzer, der für die Spark- und Kafka-Cluster erstellt wird. SSH-Kennwort Kennwort für den SSH-Benutzer für die Spark- und Kafka-Cluster. 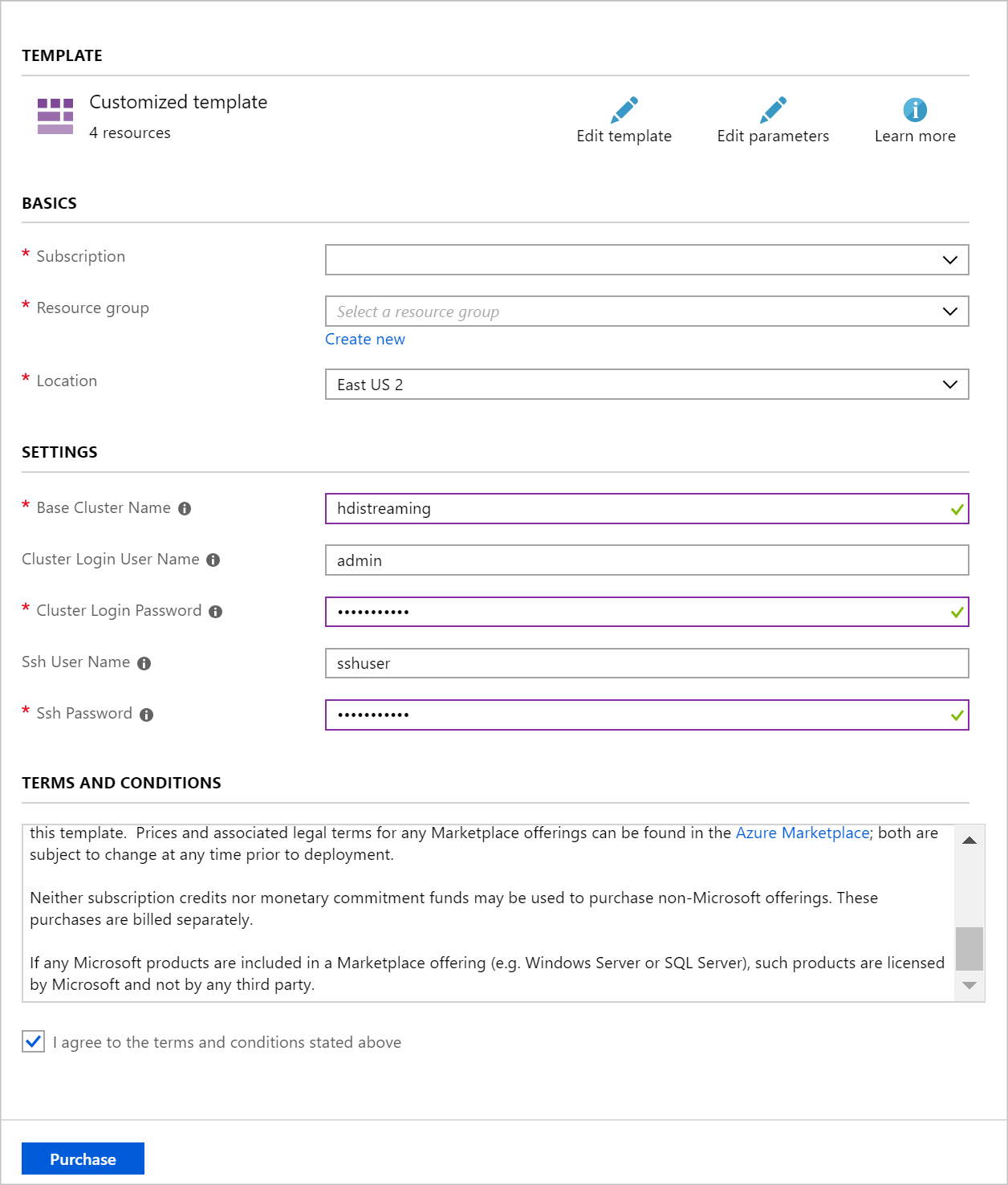
Lesen Sie die Geschäftsbedingungen, und wählen Sie anschließend die Option Ich stimme den oben genannten Geschäftsbedingungen zu.
Wählen Sie abschließend Kaufen aus. Das Erstellen der Cluster dauert ca. 20 Minuten.
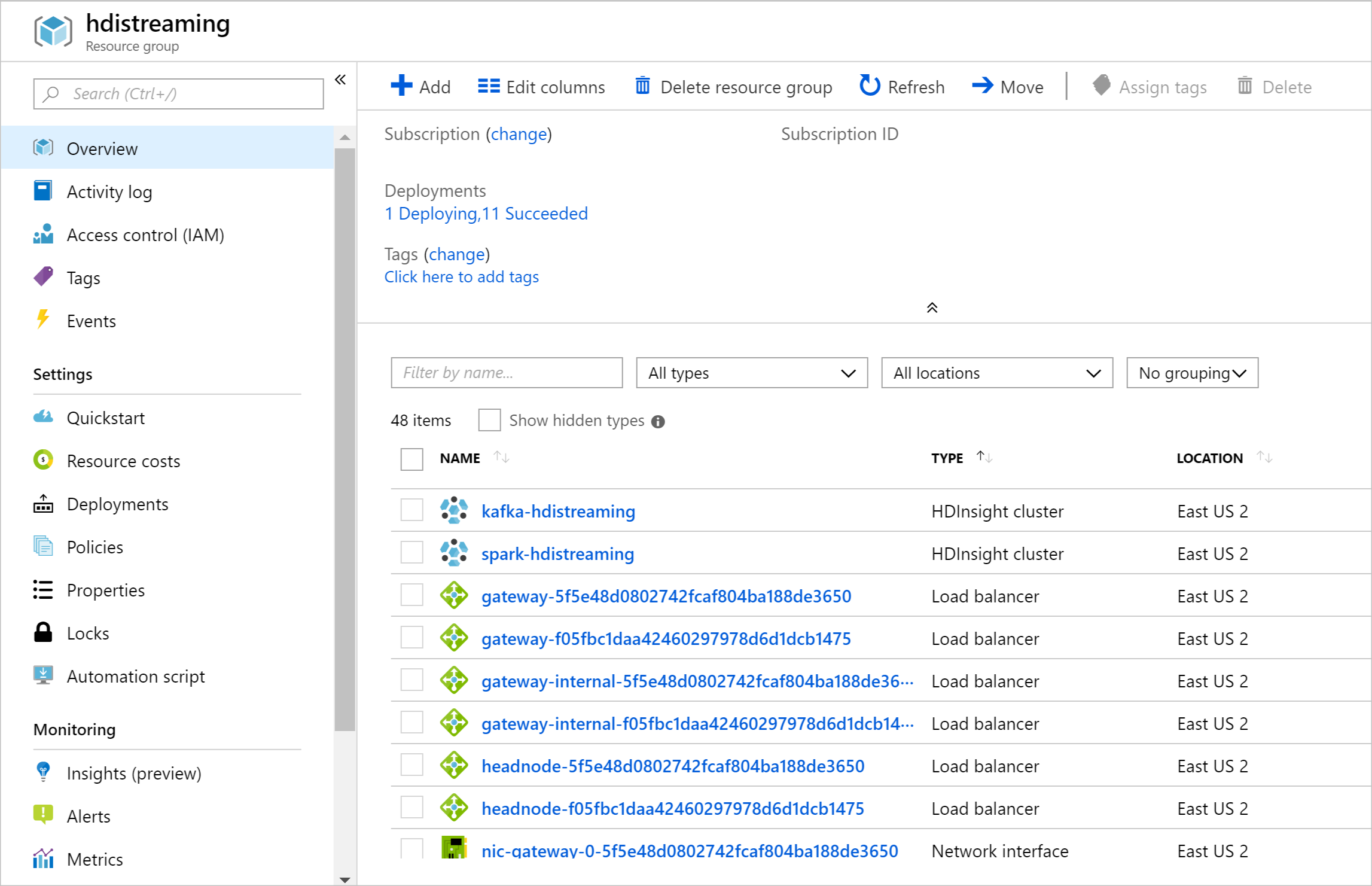
Sobald die Ressourcen erstellt wurden, wird eine Zusammenfassungsseite angezeigt.
Wichtig
Beachten Sie, dass die Namen der HDInsight-Cluster spark-BASENAME und kafka-BASENAME lauten, wobei BASENAME der Name ist, den Sie für die Vorlage angegeben haben. Sie verwenden diese Namen in späteren Schritten, wenn Sie eine Verbindung mit den Clustern herstellen.
Verwenden der Notebooks
Den Code für das in diesem Dokument beschriebene Beispiel finden Sie unter https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
Löschen des Clusters
Warnung
Die Abrechnung für die HDInsight-Cluster erfolgt anteilsmäßig auf Minutenbasis und ist unabhängig von der Verwendung. Daher sollten Sie Ihren Cluster nach der Verwendung unbedingt wieder löschen. Sehen Sie sich die Informationen zum Löschen eines HDInsight-Clusters an.
Da mit den Schritten in diesem Dokument beide Cluster in derselben Azure-Ressourcengruppe erstellt werden, können Sie die Ressourcengruppe im Azure-Portal löschen. Durch das Löschen der Gruppe werden alle beim Durcharbeiten dieses Dokuments erstellten Ressourcen sowie das virtuelle Azure-Netzwerk und das von den Clustern verwendete Speicherkonto entfernt.
Nächste Schritte
In diesem Beispiel haben Sie erfahren, wie Spark verwendet wird, um in Kafka Lese- und Schreibvorgänge auszuführen. Verwenden Sie die folgenden Links, um weitere Möglichkeiten zur Arbeit mit Kafka kennenzulernen: