Verbessern der Leistung von Apache Spark-Workloads per Azure HDInsight IO Cache
Hinweis
- E/A-Cache wurde bis Spark 2.3 unterstützt und wird in Spark 2.4 (HDInsight 4.0) und Spark 3.1.2 (HDInsight 5.0) nicht mehr unterstützt.
IO Cache ist ein Dienst zum Zwischenspeichern von Daten für Azure HDInsight, mit dem die Leistung von Apache Spark-Aufträgen verbessert wird. IO Cache funktioniert auch mit Apache TEZ- und Apache Hive-Workloads, die auf Apache Spark-Clustern ausgeführt werden können. Für IO Cache wird eine Open-Source-Komponente für die Zwischenspeicherung mit dem Namen RubiX verwendet. RubiX ist ein lokaler Datenträgercache zur Verwendung mit Big Data-Analysemodulen, bei denen über Cloudspeichersysteme auf Daten zugegriffen wird. RubiX ist unter Zwischenspeicherungssystemen einzigartig, da SSDs (Solid-State Drives) genutzt werden, anstatt regulären Arbeitsspeicher für die Zwischenspeicherung zu reservieren. Der Dienst IO Cache startet und verwaltet RubiX-Metadatenserver auf jedem Workerknoten des Clusters. Außerdem werden alle Dienste des Clusters für die transparente Nutzung des RubiX-Caches konfiguriert.
Die meisten SSDs ermöglichen eine Bandbreite von mehr als 1 GB pro Sekunde. Diese Bandbreite wird durch den In-Memory-Dateicache des Betriebssystems ergänzt und reicht aus, um Module für Big Data-Computeaufgaben, z.B. Apache Spark, zu laden. Das Betriebssystem bleibt für Apache Spark verfügbar, damit Aufgaben mit starker Abhängigkeit vom Arbeitsspeicher, z.B. Shufflevorgänge, verarbeitet werden können. Indem die exklusive Nutzung des regulären Arbeitsspeichers möglich ist, kann für Apache Spark eine optimale Ressourcennutzung erzielt werden.
Hinweis
Für IO Cache wird derzeit RubiX als Komponente für die Zwischenspeicherung genutzt, aber dies kann sich in zukünftigen Versionen des Diensts ändern. Es ist ratsam, IO Cache-Schnittstellen zu verwenden und keine direkten Abhängigkeiten von der RubiX-Implementierung einzurichten. IO Cache wird derzeit nur für Azure Blob Storage unterstützt.
Vorteile von Azure HDInsight IO Cache
Durch die Verwendung von IO Cache wird eine Leistungssteigerung für Aufträge erzielt, bei denen Daten aus Azure Blob Storage gelesen werden.
Sie müssen keine Änderungen an Ihren Spark-Aufträgen vornehmen, um bei der Verwendung von IO Cache Leistungssteigerungen zu erzielen. Wenn IO Cache deaktiviert ist, werden mit diesem Spark-Code Daten remote aus Azure Blob Storage gelesen: spark.read.load('wasbs:///myfolder/data.parquet').count(). Wenn der IO Cache aktiviert ist, bewirkt die gleiche Codezeile einen zwischengespeicherten Lesevorgang per IO Cache. Bei den folgenden Lesevorgängen werden die Daten lokal von der SSD gelesen. Workerknoten im HDInsight-Cluster sind mit lokal angefügten, dedizierten SSD-Laufwerken ausgerüstet. Bei HDInsight IO Cache werden diese lokalen SSDs für die Zwischenspeicherung verwendet, um die geringstmögliche Latenzebene und die höchste Bandbreite zu erzielen.
Erste Schritte
Azure HDInsight IO Cache ist in der Vorschauversion standardmäßig deaktiviert. IO Cache ist in Azure HDInsight 3.6+-Spark-Clustern verfügbar, in denen Apache Spark 2.3 ausgeführt wird. Führen Sie die folgenden Schritte aus, um IO Cache in HDInsight 4.0 zu aktivieren:
Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net, wobeiCLUSTERNAMEder Name Ihres Clusters ist.Wählen Sie auf der linken Seite den Dienst IO Cache aus.
Wählen Sie Aktionen (Dienstaktionen in HDI 3.6) und dann Aktivieren aus.

Vergewissern Sie sich, dass alle betroffenen Dienste im Cluster neu gestartet wurden.
Hinweis
Auch wenn in der Statusanzeige „Aktiviert“ angezeigt wird, wird IO Cache erst aktiviert, nachdem Sie die anderen betroffenen Dienste neu gestartet haben.
Problembehandlung
Unter Umständen erhalten Sie Datenträgerspeicher-Fehler, wenn Sie nach dem Aktivieren von IO Cache Spark-Aufträge ausführen. Diese Fehler treten auf, da für Spark zum Speichern von Daten bei Shufflevorgängen auch lokaler Datenträgerspeicher verwendet wird. Es kann sein, dass für Spark kein SSD-Speicherplatz mehr vorhanden ist, nachdem IO Cache aktiviert und der Speicherplatz für den Spark-Speicher reduziert wurde. Standardmäßig beträgt die von IO Cache genutzte Speichermenge die Hälfte des gesamten SSD-Speicherplatzes. Die Nutzung des Datenträgerspeichers für IO Cache kann in Ambari konfiguriert werden. Wenn Sie Datenträgerspeicher-Fehler erhalten, sollten Sie die SSD-Speichermenge reduzieren, die für IO Cache genutzt wird, und den Dienst neu starten. Führen Sie die folgenden Schritte aus, um den festgelegten Speicherplatz für IO Cache zu ändern:
Wählen Sie in Apache Ambari auf der linken Seite den Dienst HDFS aus.
Wählen Sie die Registerkarten Configs und Advanced.

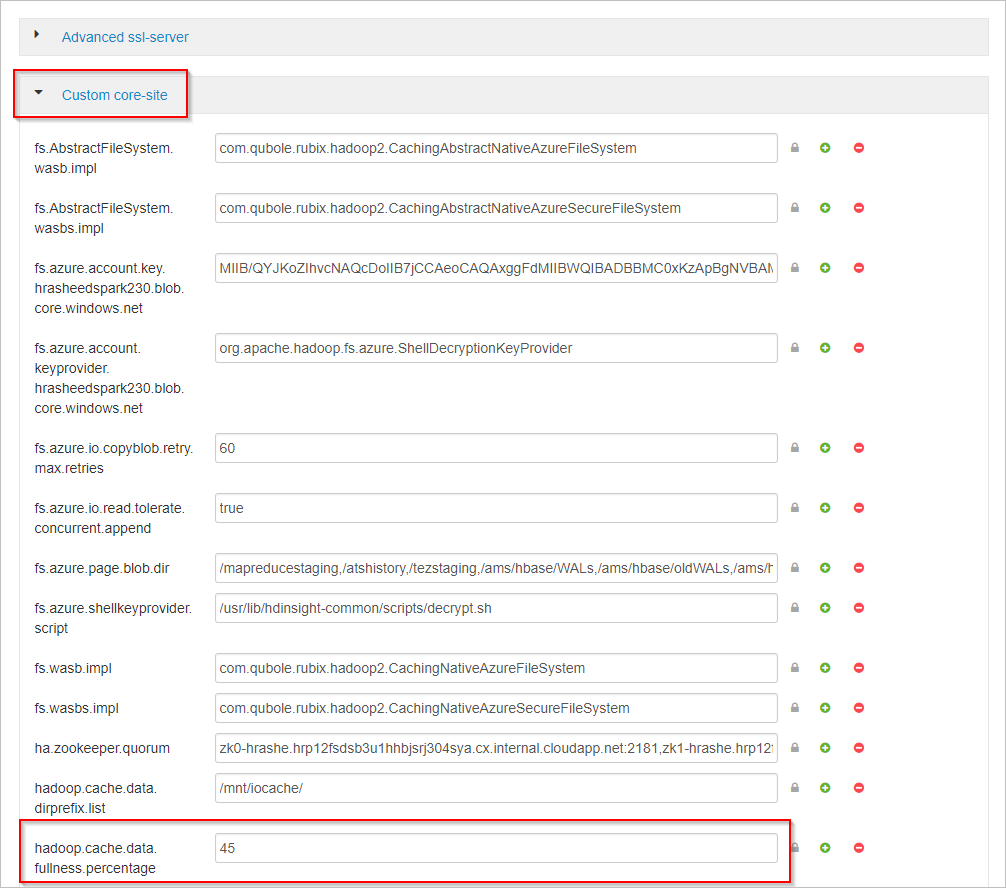
Scrollen Sie nach unten, und erweitern Sie den Bereich Custom core-site.
Suchen Sie nach der Eigenschaft hadoop.cache.data.fullness.percentage.
Ändern Sie den Wert im Feld.
Wählen Sie oben rechts die Option Save.
Wählen Sie Restart>Restart All Affected.

Wählen Sie Confirm Restart All.
Deaktivieren Sie IO Cache, falls dies nicht funktioniert.
Nächste Schritte
Informieren Sie sich weiter über IO Cache, z.B. über Leistungsbenchmarks, in diesem Blogbeitrag: Apache Spark jobs gain up to 9x speed up with HDInsight IO Cache (Bis zu neunfache Geschwindigkeit für Apache Spark-Aufträge mit HDInsight IO Cache).