Verwenden externer Pakete mit Jupyter Notebooks in Apache Spark-Clustern unter HDInsight
Erfahren Sie, wie Sie ein Jupyter Notebook im Apache Spark-Cluster auf HDInsight konfigurieren, um externe, von der Community bereitgestellte Apache Maven-Pakete zu verwenden, die nicht standardmäßig im Cluster enthalten sind.
Sie können das Maven Repository nach einer vollständigen Liste der verfügbaren Pakete durchsuchen. Sie können die Liste der verfügbaren Pakete auch aus anderen Quellen abrufen. Beispielsweise steht eine vollständige Liste der von der Community bereitgestellten Pakete auf Spark-Paketezur Verfügung.
In diesem Artikel erfahren Sie, wie Sie das Paket spark-csv mit dem Jupyter Notebook verwenden.
Voraussetzungen
Ein Apache Spark-Cluster unter HDInsight. Eine Anleitung finden Sie unter Erstellen von Apache Spark-Clustern in Azure HDInsight.
Kenntnisse im Umgang mit Jupyter Notebooks mit Spark in HDInsight. Weitere Informationen finden Sie unter Tutorial: Laden von Daten und Ausführen von Abfragen auf einem Apache Spark-Cluster in Azure HDInsight.
Das URI-Schema für Ihren primären Clusterspeicher. Dies wäre
wasb://für Azure Storage,abfs://für Azure Data Lake Storage Gen2. Wenn die sichere Übertragung für Azure Storage oder Data Lake Storage Gen2 aktiviert ist, lautet der URIwasbs://bzw.abfss://. Weitere Informationen finden Sie unter Sichere Übertragung.
Verwenden von externen Paketen mit Jupyter Notebooks
Navigieren Sie zu
https://CLUSTERNAME.azurehdinsight.net/jupyter, wobeiCLUSTERNAMEder Name Ihres Spark-Clusters ist.Erstellen Sie ein neues Notebook. Wählen Sie Neu und dann Spark aus.
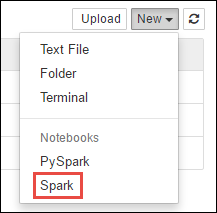
Ein neues Notebook mit dem Namen „Untitled.pynb“ wird erstellt und geöffnet. Wählen Sie oben den Namen des Notebooks aus, und geben Sie einen Anzeigenamen ein.
Verwenden Sie den Magic-Befehl
%%configure, um das Notebook so zu konfigurieren, dass es ein externes Paket verwendet. Stellen Sie sicher, dass Notebooks, die externe Pakete verwenden, die%%configure-Magic in der ersten Codezelle aufrufen. Dadurch wird sichergestellt, dass der Kernel für die Verwendung des Pakets konfiguriert ist, bevor die Sitzung gestartet wird.Wichtig
Wenn Sie vergessen, den Kernel in der ersten Zelle zu konfigurieren, können Sie
%%configuremit dem Parameter-fverwenden. Allerdings wird die Sitzung dadurch neu gestartet, und der bisherige Fortschritt geht verloren.HDInsight-Version Get-Help Für HDInsight 3.5 und HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}Für HDInsight 3.3 und HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }Im obigen Codeausschnitt werden die Maven-Koordinaten für das externe Paket im zentralen Maven-Repository erwartet. In diesem Codeausschnitt ist
com.databricks:spark-csv_2.11:1.5.0die Maven-Koordinate für das Paket spark-csv . Nachstehend finden Sie eine Anleitung zur Erstellung von Koordinaten für ein Paket.a. Suchen Sie das Paket im Maven-Repository. In diesem Artikel verwenden wir spark-csv.
b. Sammeln Sie im Repository die Werte für GroupId, ArtifactId und Version. Vergewissern Sie sich, dass die erfassten Werte Ihrem Cluster entsprechen. In diesem Fall wird ein Scala 2.11- und Spark 1.5.0-Paket verwendet, möglicherweise müssen Sie jedoch für die jeweilige Scala- oder Spark-Version in Ihrem Cluster andere Versionen auswählen. Sie können die Scala-Version im Cluster ermitteln, indem Sie
scala.util.Properties.versionStringim Spark Jupyter-Kernel oder in Spark-Submit ausführen. Sie können die Spark-Version im Cluster ermitteln, indem Siesc.versionfür Jupyter Notebooks ausführen.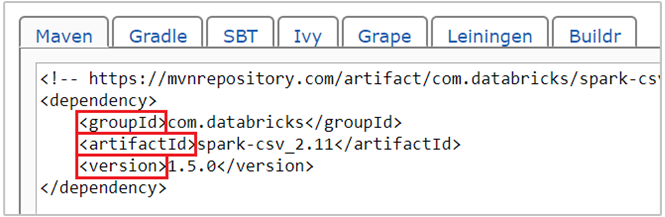
c. Verketten Sie die drei Werte, getrennt durch einen Doppelpunkt ( : ).
com.databricks:spark-csv_2.11:1.5.0Führen Sie die Codezelle mit der
%%configure-Magic aus. Dadurch wird die zugrunde liegende Livy-Sitzung für die Verwendung des von Ihnen bereitgestellten Pakets konfiguriert. Sie können das Paket nun in den folgenden Codezellen in Ihrem Notebook verwenden, wie unten dargestellt.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Für HDInsight 3.4 und ältere Versionen sollten Sie den folgenden Codeausschnitt verwenden.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Anschließend können Sie die Codeausschnitte wie unten dargestellt ausführen, um die Daten aus dem im vorherigen Schritt erstellten Datenrahmen anzuzeigen.
df.show() df.select("Time").count()
Weitere Informationen
Szenarien
- Apache Spark mit BI: Durchführen interaktiver Datenanalysen mithilfe von Spark in HDInsight mit BI-Tools
- Apache Spark mit Machine Learning: Analysieren von Gebäudetemperaturen mithilfe von Spark in HDInsight und HVAC-Daten
- Apache Spark mit Machine Learning: Vorhersage von Lebensmittelkontrollergebnissen mithilfe von Spark in HDInsight
- Websiteprotokollanalyse mithilfe von Apache Spark in HDInsight
Erstellen und Ausführen von Anwendungen
- Erstellen einer eigenständigen Anwendung mit Scala
- Ausführen von Remoteaufträgen in einem Apache Spark-Cluster mithilfe von Apache Livy
Tools und Erweiterungen
- Verwenden von externen Python-Paketen mit Jupyter Notebooks in Apache Spark-Clustern unter HDInsight (Linux)
- Verwenden des HDInsight-Tools-Plug-Ins für IntelliJ IDEA zum Erstellen und Übermitteln von Spark Scala-Anwendungen
- Verwenden des HDInsight-Tools-Plug-Ins für IntelliJ IDEA zum Remotedebuggen von Apache Spark-Anwendungen
- Verwenden von Apache Zeppelin Notebooks mit einem Apache Spark-Cluster unter HDInsight
- Kernel für Jupyter Notebook in Apache Spark-Clustern für HDInsight
- Installieren von Jupyter Notebook auf Ihrem Computer und Herstellen einer Verbindung zum Apache Spark-Cluster in Azure HDInsight (Vorschau)