OutOfMemoryError-Ausnahmen für Apache Spark in Azure HDInsight
In diesem Artikel werden Schritte zur Problembehandlung und mögliche Lösungen für Probleme bei der Verwendung von Apache Spark-Komponenten in Azure HDInsight-Clustern beschrieben.
Szenario: OutOfMemoryError-Ausnahme für Apache Spark
Problem
Bei Ihrer Apache Spark-Anwendung ist ein OutOfMemoryError-Ausnahmefehler aufgetreten. Unter Umständen wird in etwa folgende Fehlermeldung angezeigt:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Ursache
Die wahrscheinlichste Ursache dieser Ausnahme besteht darin, dass den Java Virtual Machines (JVMs) kein ausreichender Heapspeicher zugeordnet ist. Diese JVMs werden als Executors oder Treiber im Rahmen der Apache Spark-Anwendung gestartet.
Lösung
Ermitteln Sie die maximale Größe der Daten, die von der Spark-Anwendung verarbeitet werden. Schätzen Sie die Größe basierend auf der maximalen Größe der Eingabedaten, den bei der Transformation der Eingabedaten erzeugten Zwischendaten und den erzeugten Ausgabedaten, mit denen die Zwischendaten weiter transformiert werden. Wenn die anfängliche Schätzung nicht ausreichend ist, erhöhen Sie die Größe um einen geringen Wert, und wiederholen Sie diesen Vorgang so lange, bis die Arbeitsspeicherfehler nicht mehr angezeigt werden.
Stellen Sie sicher, dass der zu verwendende HDInsight-Cluster über genügend Ressourcen im Hinblick auf Arbeitsspeicher und Kerne verfügt, um die Spark-Anwendung auszuführen. Dies lässt sich feststellen, indem man im Abschnitt Cluster-Metriken der YARN UI des Clusters die Werte von Memory Used vs. Memory Total und VCores Used vs. VCores Total betrachtet.

Legen Sie die folgenden Spark-Konfigurationseinstellungen auf geeignete Werte fest. Gleichen Sie die Anwendungsanforderungen mit den verfügbaren Ressourcen im Cluster ab. Diese Werte sollten 90 % des verfügbaren Arbeitsspeichers und der verfügbaren Kerne aus Sicht von YARN nicht überschreiten und außerdem die minimalen Arbeitsspeicheranforderungen der Spark-Anwendung erfüllen:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Gesamter von allen Executors verwendeter Arbeitsspeicher =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Gesamter vom Treiber verwendeter Arbeitsspeicher =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Szenario: Java-Heapspeicherfehler beim Öffnen des Apache Spark-Verlaufsservers
Problem
Beim Öffnen von Ereignissen im Spark-Verlaufsserver tritt der folgende Fehler auf:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Ursache
Dieses Problem ist häufig auf unzureichende Ressourcen beim Öffnen großer Spark-Ereignisdateien zurückzuführen. Die Spark-Heapgröße ist standardmäßig auf 1 GB festgelegt, aber für große Spark-Ereignisdateien reicht dies unter Umständen nicht aus.
Wenn Sie die Größe der zu ladenden Dateien überprüfen möchten, können Sie die folgenden Befehle ausführen:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Lösung
Sie können den Arbeitsspeicher des Spark-Verlaufsservers erhöhen, indem Sie in der Spark-Konfiguration die SPARK_DAEMON_MEMORY-Eigenschaft bearbeiten und alle Dienste neu starten.
Hierzu können Sie auf der Ambari-Browserbenutzeroberfläche den Abschnitt „Spark2/Config/Advanced spark2-env“ auswählen.
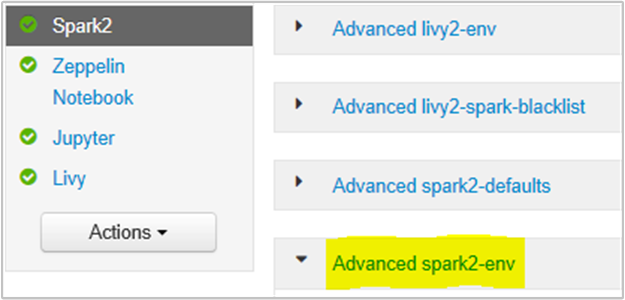
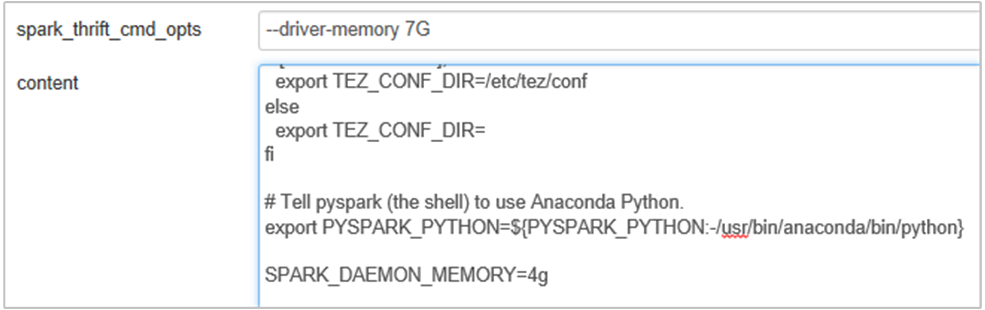
Fügen Sie die folgende Eigenschaft hinzu, um den Arbeitsspeicher des Spark-Verlaufsservers von 1 GB auf 4 GB zu erhöhen: SPARK_DAEMON_MEMORY=4g.
Anschließend müssen alle betroffenen Dienste über Ambari neu gestartet werden.
Szenario: Fehler beim Starten des Livy-Servers in einem Apache Spark-Cluster
Problem
Der Livy-Server kann auf einem Apache Spark-Cluster [(Spark 2.1 unter Linux (HDI 3.6)] nicht gestartet werden. Ein versuchter Neustart führt zu folgendem Fehlerstapel (aus den Livy-Protokollen):
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Ursache
java.lang.OutOfMemoryError: unable to create new native thread deutet darauf hin, dass das Betriebssystem JVMs keine weiteren nativen Threads mehr zuweisen kann. Diese Ausnahme ist auf eine Überschreitung des prozessspezifischen Grenzwerts für die Threadanzahl zurückzuführen.
Wenn der Livy-Server unerwartet beendet wird, werden alle Verbindungen mit Spark-Clustern ebenfalls beendet. Dies bedeutet, dass alle Aufträge und die zugehörigen Daten verloren gehen. In HDP 2.6 wurde ein Sitzungswiederherstellungsmechanismus eingeführt: Livy speichert die Sitzungsdetails in ZooKeeper, sodass sie wiederhergestellt werden können, wenn der Livy-Server wieder verfügbar ist.
Wenn eine so große Anzahl von Aufträgen über Livy übermittelt wird, werden die Sitzungszustände im Rahmen der Hochverfügbarkeit für den Livy-Server in ZooKeeper (auf HDInsight-Clustern) gespeichert und diese Sitzungen beim Neustart des Livy-Diensts wiederhergestellt. Bei einem Neustart nach unerwarteter Beendigung erstellt Livy jeweils einen Thread pro Sitzung. Hierdurch ergeben sich einige wiederherzustellende Sitzungen, was zur Erstellung einer zu großen Anzahl von Threads führt.
Lösung
Löschen Sie alle Einträge mithilfe der folgenden Schritte.
Rufen Sie die IP-Adresse der ZooKeeper-Knoten ab:
grep -R zk /etc/hadoop/confDer vorstehende Befehl listet alle ZooKeeper-Knoten für einen Cluster auf.
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>Rufen Sie die IP-Adresse der ZooKeeper-Knoten mithilfe von Ping ab. Alternativ können Sie auch über den Hauptknoten mit dem ZooKeeper-Namen eine Verbindung mit ZooKeeper herstellen.
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181Führen Sie nach der Verbindungsherstellung mit ZooKeeper den folgenden Befehl zum Auflisten aller Sitzungen aus, für die ein Neustart versucht wurde.
Die Liste umfasst häufig mehr als 8.000 Sitzungen.
ls /livy/v1/batchMit dem folgenden Befehl werden alle wiederherzustellenden Sitzungen entfernt: #####
rmr /livy/v1/batch
Warten Sie, bis der obige Befehl abgeschlossen wurde und der Cursor sich wieder an der Eingabeaufforderung befindet, und starten Sie dann den Livy-Dienst über Ambari neu. Dieser Vorgang sollte nun erfolgreich sein.
Hinweis
Löschen Sie die Livy-Sitzung nach Abschluss der Ausführung mit DELETE. Die Livy-Batchsitzungen werden nicht automatisch gelöscht, sobald die Ausführung der Spark-App abgeschlossen ist. Dieses Verhalten ist beabsichtigt. Eine Livy-Sitzung ist eine Entität, die durch eine POST-Anforderung für den Livy-REST-Server erstellt wird. Zum Löschen dieser Entität muss DELETE aufgerufen werden. Alternativ kann auch auf die Initiierung der Garbage Collection gewartet werden.
Nächste Schritte
Wenn Ihr Problem nicht aufgeführt ist oder Sie es nicht lösen können, besuchen Sie einen der folgenden Kanäle, um weitere Unterstützung zu erhalten:
Spark memory management overview (Übersicht über die Spark-Speicherverwaltung).
Debugging Spark application on HDInsight clusters (Debuggen der Spark-Anwendung in HDInsight-Clustern).
Nutzen Sie den Azure-Communitysupport, um Antworten von Azure-Experten zu erhalten.
Setzen Sie sich mit @AzureSupport in Verbindung, dem offiziellen Microsoft Azure-Konto zum Verbessern der Kundenfreundlichkeit. Verbinden der Azure-Community mit den richtigen Ressourcen: Antworten, Support und Experten.
Sollten Sie weitere Unterstützung benötigen, senden Sie eine Supportanfrage über das Azure-Portal. Wählen Sie dazu auf der Menüleiste die Option Support aus, oder öffnen Sie den Hub Hilfe und Support. Ausführlichere Informationen hierzu finden Sie unter Erstellen einer Azure-Supportanfrage. Zugang zu Abonnementverwaltung und Abrechnungssupport ist in Ihrem Microsoft Azure-Abonnement enthalten. Technischer Support wird über einen Azure-Supportplan bereitgestellt.