Problembehandlung bei Apache Spark mit Azure HDInsight
Lernen Sie die wichtigsten Probleme und ihre Lösungen bei der Arbeit mit Apache Spark-Nutzlasten in Apache Ambari kennen.
Wie konfiguriere ich eine Apache Spark-Anwendung über Apache Ambari in Clustern?
Spark-Konfigurationswerte können optimiert werden, um eine OutofMemoryError-Ausnahme der Apache Spark-Anwendung zu vermeiden. Die folgenden Schritte zeigen die Standardwerte der Spark-Konfiguration in Azure HDInsight:
Melden Sie sich unter
https://CLUSTERNAME.azurehdidnsight.netmit Ihren Clusteranmeldeinformationen bei Ambari an. Auf dem ersten Bildschirm wird ein Dashboard mit einer Übersicht angezeigt. Es gibt geringfügige kosmetische Unterschiede zwischen HDInsight 4.0.Navigieren Sie zu Spark2>Configs.
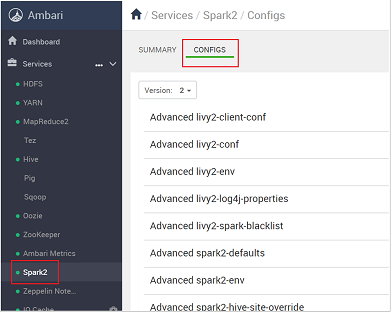
Wählen Sie in der Liste der Konfigurationen den Eintrag Custom-spark2-defaults aus, und erweitern Sie diesen.
Suchen Sie nach der Werteinstellung, die Sie anpassen müssen, z.B. spark.executor.memory. In diesem Fall ist der Wert 9728m zu hoch.
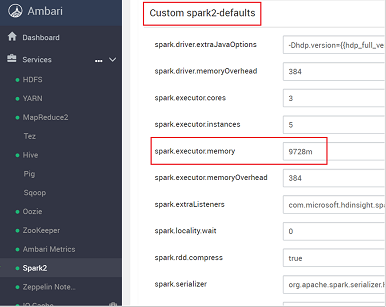
Legen Sie den Wert auf die empfohlene Einstellung fest. Für diese Einstellung wird der Wert 2048m empfohlen.
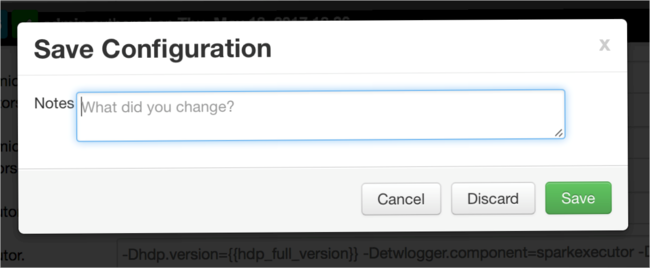
Speichern Sie den Wert und anschließend die Konfiguration. Wählen Sie Speichern.

Schreiben Sie eine Notiz zu den Konfigurationsänderungen, und wählen Sie Save (Speichern) aus.
Sie werden benachrichtigt, wenn für eine Konfiguration Maßnahmen erforderlich sind. Notieren Sie sich die Elemente, und wählen Sie anschließend Proceed Anyway (Dennoch fortfahren) aus.

Wenn eine Konfiguration gespeichert ist, werden Sie aufgefordert, den Dienst neu starten. Wählen Sie Neu starten aus.
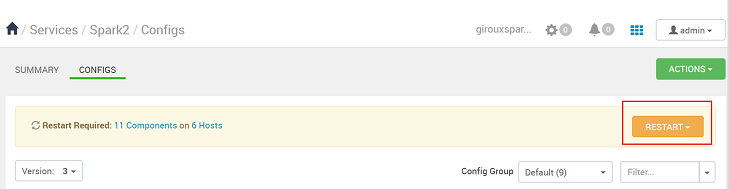
Bestätigen Sie den Neustart.
Sie können die ausgeführten Prozesse überprüfen.
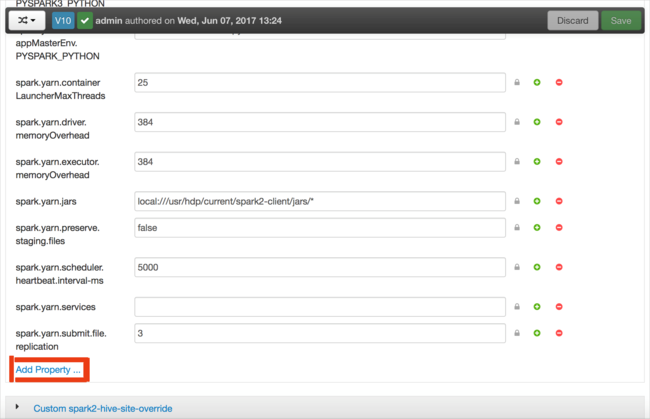
Sie können Konfigurationen hinzufügen. Wählen Sie in der Liste der Konfigurationen Custom-spark2-defaults aus, und wählen Sie dann Add Property (Eigenschaft hinzufügen) aus.
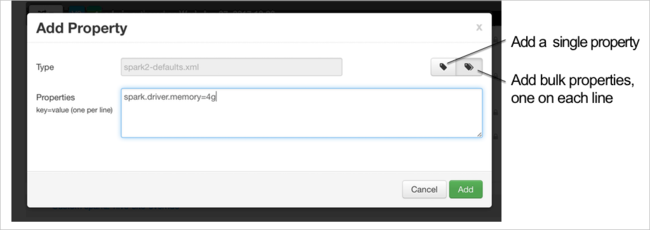
Definieren Sie eine neue Eigenschaft. Sie können eine einzelne Eigenschaft mithilfe eines Dialogfelds für bestimmte Einstellungen definieren (z.B. den Datentyp). Sie können auch mehrere Eigenschaften definieren, indem Sie eine Eigenschaft pro Zeile angeben.
In diesem Beispiel wird die Eigenschaft spark.driver.memory mit dem Wert 4g definiert.
Speichern Sie die Konfiguration, und starten Sie den Dienst wie in Schritt 6 und 7 beschrieben neu.
Diese Änderungen betreffen den gesamten Cluster, sie können jedoch beim Senden des Spark-Auftrags überschrieben werden.
Wie konfiguriere ich eine Apache Spark-Anwendung über ein Jupyter-Notebook in Clustern?
Geben Sie in der ersten Zelle im Jupyter-Notebook nach der Anweisung %%configure die Spark-Konfigurationen in einem gültigen JSON-Format ein. Ändern Sie die tatsächlichen Werte entsprechend den jeweiligen Anforderungen:

Wie konfiguriere ich eine Apache Spark-Anwendung über Apache Livy in Clustern?
Senden Sie die Spark-Anwendung mit einem REST-Client wie cURL an Livy. Führen Sie einen Befehl aus, der dem folgenden ähnelt: Ändern Sie die tatsächlichen Werte entsprechend den jeweiligen Anforderungen:
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
Wie konfiguriere ich eine Apache Spark-Anwendung über spark-submit in Clustern?
Starten Sie spark-shell mit einem Befehl, der dem folgenden ähnelt. Ändern Sie den tatsächlichen Wert der Konfigurationen entsprechend den jeweiligen Anforderungen:
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
Zusätzliche Lektüre
Übermitteln von Apache Spark-Aufträgen in HDInsight-Clustern
Nächste Schritte
Wenn Ihr Problem nicht aufgeführt ist oder Sie es nicht lösen können, besuchen Sie einen der folgenden Kanäle, um weitere Unterstützung zu erhalten:
Spark memory management overview (Übersicht über die Spark-Speicherverwaltung).
Debugging Spark application on HDInsight clusters (Debuggen der Spark-Anwendung in HDInsight-Clustern).
Nutzen Sie den Azure-Communitysupport, um Antworten von Azure-Experten zu erhalten.
Setzen Sie sich mit @AzureSupport in Verbindung, dem offiziellen Microsoft Azure-Konto zum Verbessern der Kundenfreundlichkeit. Verbinden der Azure-Community mit den richtigen Ressourcen: Antworten, Support und Experten.
Sollten Sie weitere Unterstützung benötigen, senden Sie eine Supportanfrage über das Azure-Portal. Wählen Sie dazu auf der Menüleiste die Option Support aus, oder öffnen Sie den Hub Hilfe und Support. Ausführlichere Informationen hierzu finden Sie unter Erstellen einer Azure-Supportanfrage. Zugang zu Abonnementverwaltung und Abrechnungssupport ist in Ihrem Microsoft Azure-Abonnement enthalten. Technischer Support wird über einen Azure-Supportplan bereitgestellt.