Standardmäßige Lastenausgleichsdiagnose mit Metriken, Warnungen und Ressourcenintegrität
Azure Load Balancer bietet die folgenden Diagnosefunktionen:
Mehrdimensionale Metriken und Warnungen: Bietet mehrdimensionale Diagnosefunktionen über Azure Monitor für Azure Load Balancer-Konfigurationen. Sie können Ihre Load Balancer Standard-Ressourcen überwachen, verwalten und hinsichtlich Fehlern behandeln.
Ressourcenintegrität:Der Ressourcenintegritätsstatus Ihrer Load Balancer-Instanz ist auf der Seite Ressourcenintegrität unter Monitor verfügbar. Diese automatische Überprüfung informiert Sie über die aktuelle Verfügbarkeit Ihrer Lastenausgleichsressource.
Dieser Artikel enthält einen kurzen Überblick über diese Funktionen und zeigt Möglichkeiten auf, wie diese für einen standardmäßigen Lastenausgleich verwendet werden können.
Mehrdimensionale Metriken
Azure Load Balancer stellt mehrdimensionale Metriken über die Azure-Metriken im Azure-Portal zur Verfügung und ermöglicht es Ihnen, in Echtzeit diagnostische Einblicke in Ihre Lastenausgleichsressourcen zu erhalten. Beachten Sie, dass mehrdimensionale Metriken nicht für einfache Lastenausgleichsgeräte unterstützt werden.
Die verschiedenen Lastenausgleichskonfigurationen bieten die folgenden Metriken:
| Metrik | Ressourcentyp | BESCHREIBUNG | Empfohlene Aggregation |
|---|---|---|---|
| Data Path Availability (Verfügbarkeit des Datenpfads) | Öffentlicher und interner Load Blancer | Ein Lastenausgleich wendet kontinuierlich den Datenpfad aus einer Region auf das Lastenausgleichs-Front-End an, bis zu dem Netzwerk, das Ihren virtuellen Computer unterstützt. Solange integre Instanzen verbleiben, folgt die Messung demselben Pfad wie der Datenverkehr mit Lastenausgleich Ihrer Anwendungen. Der verwendete Datenpfad wird validiert. Die Messung ist für Ihre Anwendung nicht sichtbar und beeinträchtigt keine anderen Vorgängen. | Average |
| Health Probe Status (Status des Integritätstests) | Öffentlicher und interner Load Blancer | Ein Lastenausgleich verwendet einen verteilten Integritätsprüfungsdienst, der die Integrität Ihres Anwendungsendpunkts gemäß Ihren Konfigurationseinstellungen überwacht. Diese Metrik stellt eine Aggregat- oder nach Endpunkt gefilterte Ansicht jedes Instanzendpunkts im Load Balancer-Pool bereit. Sie können sehen, wie der Lastenausgleich die Integrität Ihrer Anwendung gemäß Ihrer Integritätsprüfungskonfiguration beurteilt. | Average |
| SYN-Anzahl | Öffentlicher und interner Load Blancer | Ein Lastenausgleich beendet keine TCP-Verbindungen (Transmission Control Protocol) und interagiert nicht mit TCP- oder UDP-Flows (User Data-gram Packet). Datenflüsse und deren Handshakes erfolgen immer zwischen der Quelle und der VM-Instanz. Für eine bessere Problembehandlung Ihrer TCP-Protokollszenarien können Sie SYN-Paketzähler verwenden, um zu verstehen, wie viele TCP-Verbindungsversuche vorgenommen werden. Die Metrik gibt die Anzahl der TCP-SYN-Pakete an, die empfangen wurden. | SUM |
| Anzahl der SNAT-Verbindungen (Source Network Address Translation, Quellnetzwerkadressen-Übersetzung) | Öffentlicher Load Balancer | Ein Lastenausgleich meldet die Anzahl von maskierten ausgehenden Flows an das Front-End mit der öffentlichen IP-Adresse. SNAT Ports stellen eine erschöpfbare Ressource dar. Diese Metrik kann einen Hinweis darauf geben, in welchem Umfang Ihre Anwendung SNAT für ausgehende Flows nutzt. Es werden Zähler für erfolgreiche und nicht erfolgreiche ausgehende SNAT-Flows gemeldet. Die Zähler können zur Problembehandlung und zum Verständnis des Zustands Ihrer ausgehenden Flows verwendet werden. | SUM |
| Zugeordnete SNAT-Ports | Öffentlicher Load Balancer | Ein Lastenausgleich meldet die Anzahl der pro Back-End-Instanz zugeordneten SNAT-Ports. | Average. |
| Verwendete SNAT-Ports | Öffentlicher Load Balancer | Ein Lastenausgleich meldet die Anzahl der pro Back-End-Instanz genutzten SNAT-Ports. | Average |
| Byteanzahl | Öffentlicher und interner Load Blancer | Ein Lastenausgleich meldet die pro Front-End verarbeiteten Daten. Sie bemerken möglicherweise, dass die Bytes nicht gleichmäßig auf die Back-End-Instanzen verteilt sind. Dies ist zu erwarten, da der Azure Load Balancer-Algorithmus auf Flows basiert. | SUM |
| Paketanzahl | Öffentlicher und interner Load Blancer | Ein Lastenausgleich meldet die pro Front-End verarbeiteten Pakete. | Sum |
Hinweis
Datenverkehr zu einem internen Lastenausgleich über einen UDR (z. B. von einer NVA oder Firewall) wird von bandbreitenbezogenen Metriken wie SYN-Pakete, Byteanzahl und Paketanzahl nicht erfasst.
Maximale und minimale Aggregationen sind für die Metriken zu SYN-Anzahl, Paketanzahl, Anzahl von SNAT-Verbindungen und Byteanzahl nicht verfügbar. Die Aggregation der Anzahl wird für die Verfügbarkeit von Datenpfaden und den Status der Integritätsprüfung nicht empfohlen. Verwenden Sie stattdessen den Mittelwert für optimal dargestellte Integritätsdaten.
Anzeigen Ihrer Load Balancer-Metriken im Azure-Portal
Das Azure-Portal macht die Lastenausgleichsmetriken über die Seite „Metriken“ verfügbar. Diese Seite ist sowohl auf der Ressourcenseite des Lastenausgleichs für eine bestimmte Ressource als auch auf der Azure Monitor-Seite verfügbar.
Hinweis
Azure Load Balancer sendet keine Integritätstests an virtuelle Computer mit aufgehobener Zuordnung. Wenn die Zuordnung virtueller Computer aufgehoben wird, beendet der Lastenausgleich das Melden von Metriken für diese Instanz. Metriken, die nicht verfügbar sind, werden im Portal als gestrichelte Linie angezeigt, oder es wird eine Fehlermeldung angezeigt, die angibt, dass Metriken nicht abgerufen werden können.
So zeigen Sie die Metriken für Ihre Lastenausgleichsressourcen an:
Wechseln Sie zur Seite „Metriken“, und führen Sie eine der folgenden Ausgaben aus:
Wählen Sie auf der Ressourcenseite des Lastenausgleichs den Metriktyp in der Dropdownliste aus.
Wählen Sie auf der Seite „Azure Monitor“ die Load Balancer-Ressource aus.
Legen Sie den entsprechenden Metrikaggregationstyp fest.
Konfigurieren Sie optional die erforderliche Filterung und Gruppierung.
Konfigurieren Sie optional den Zeitbereich und die Aggregation. Standardmäßig wird die Uhrzeit in UTC (koordinierte Weltzeit) angezeigt.
Hinweis
Die Zeitaggregation ist bei der Interpretation bestimmter Metriken wichtig, da die Daten einmal pro Minute erfasst werden. Wenn die Zeitaggregation auf fünf Minuten eingestellt ist und der Metrikaggregationstyp „Summe“ für Metriken wie SNAT-Zuweisung verwendet wird, zeigt Ihr Diagramm das Fünffache der insgesamt zugewiesenen SNAT-Ports an.
Empfehlung: Bei der Analyse der Metrikaggregationstypen „Sum“ und „Count“ sollten Sie einen Zeitaggregationswert verwenden, der höher als eine Minute ist.
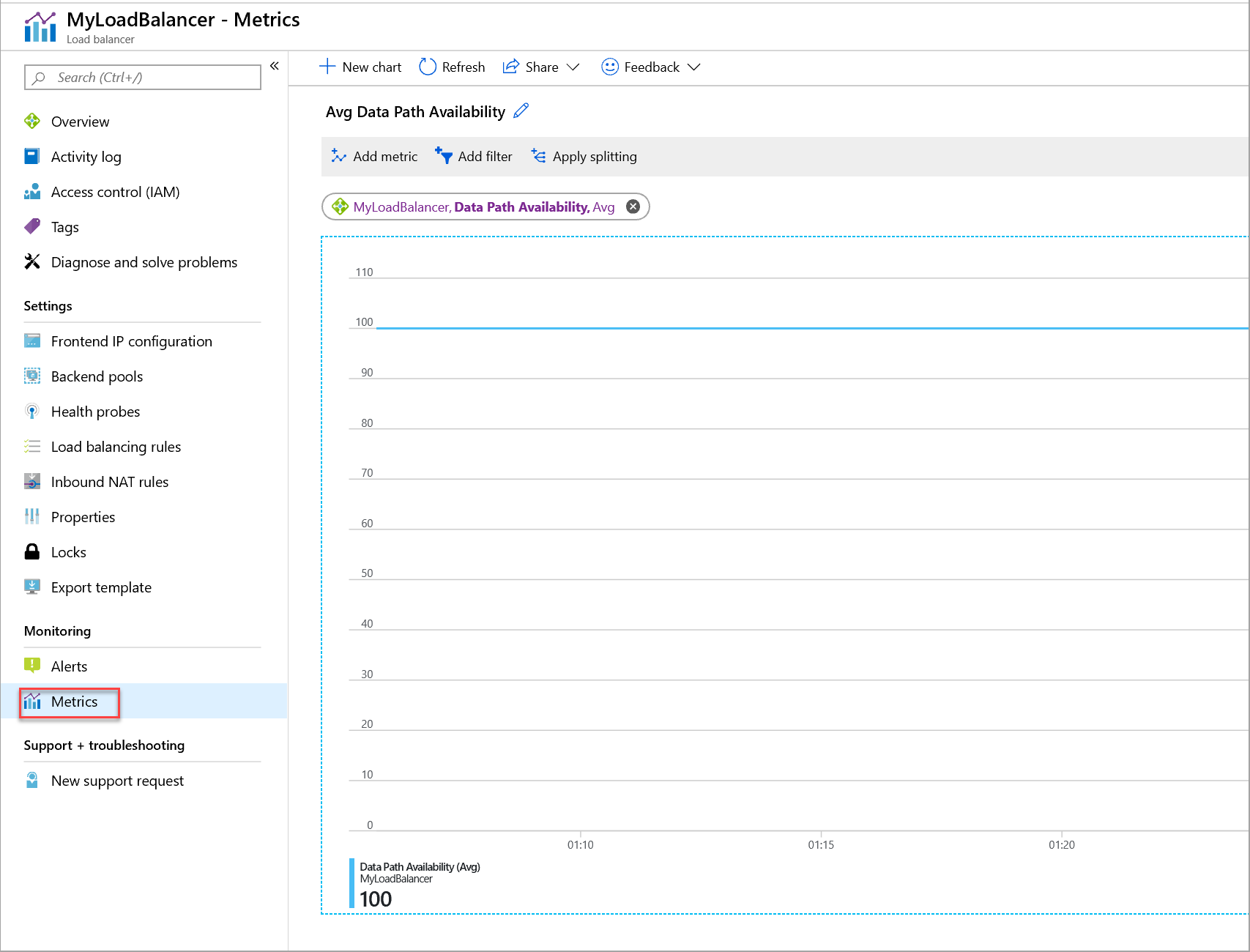
Abbildung: Datenpfad-Verfügbarkeitsmetrik für einen standardmäßigen Lastenausgleich
Programmgesteuertes Abrufen von mehrdimensionalen Metriken über APIs
Eine API-Anleitung zum Abrufen von Definitionen und Werten für multidimensionale Metriken finden Sie unter Exemplarische Vorgehensweise für die Azure Monitor-REST-API. Diese Metriken können in ein Speicherkonto geschrieben werden, indem Sie eine Diagnoseeinstellung für die Kategorie „Alle Metriken“ hinzufügen.
Allgemeine Diagnoseszenarien und empfohlene Ansichten
Ist der Datenpfad aktiv und für mein Lastenausgleichs-Front-End verfügbar?
Erweitern
Die Metrik der Datenpfadverfügbarkeit beschreibt die Integrität innerhalb der Region des Datenpfads zu dem Computehost, auf dem sich Ihre VMs befinden. Die Metrik entspricht der Integrität Ihres Lastenausgleichs basierend auf Ihrer Konfiguration und der Azure-Infrastruktur. Anhand der Metrik können Sie:
Die externe Verfügbarkeit Ihres Diensts überwachen.
Die Plattform untersuchen, auf der Ihr Dienst bereitgestellt wird, und bestimmen, ob er fehlerfrei ist. Ermitteln, ob Ihr Gastbetriebssystem oder Ihre Anwendungsinstanz fehlerfrei ist.
Bestimmen, ob sich ein Ereignis auf Ihren Dienst oder die zugrunde liegende Datenebene bezieht. Verwechseln Sie diese Metrik nicht mit der Metrik „Integritätsteststatus“.
So rufen Sie die Datenpfadverfügbarkeit für Ihre Lastenausgleichsressourcen ab:
Vergewissern Sie sich, dass die richtige Load Balancer-Ressource ausgewählt ist.
Wählen Sie in der Dropdownliste Metrik die Option Datenpfadverfügbarkeit aus.
Wählen in der Dropdownliste Aggregation die Option Mittelwert aus.
Fügen Sie außerdem einen Filter für die Front-End-IP-Adresse oder den Front-End-Port als die Dimension mit der erforderlichen Front-End-IP-Adresse oder dem erforderlichen Front-End-Port hinzu. Gruppieren Sie diese dann nach der ausgewählten Dimension.
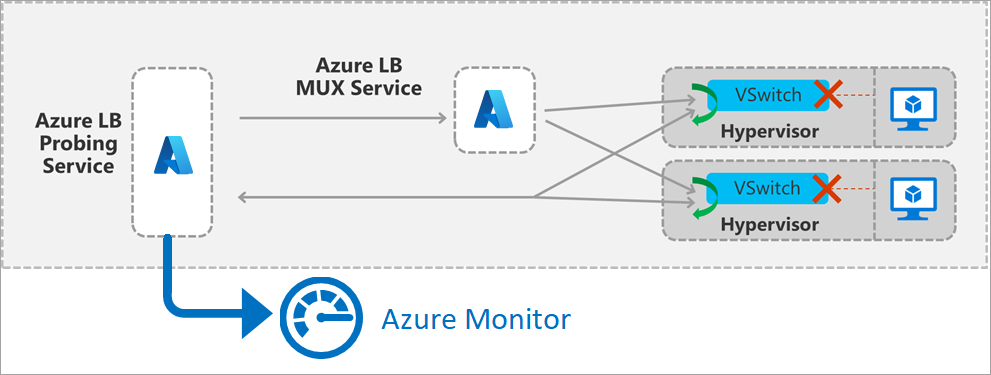
Abbildung: Sondierungsdetails des Lastenausgleichs-Front-Ends
Die Metrik wird von einem Probingdienst innerhalb der Region generiert, der den Datenverkehr simuliert. Der Probingdienst generiert in regelmäßigen Abständen ein Paket, das dem Front-End und der Lastenausgleichsregel Ihrer Bereitstellung entspricht. Das Paket durchläuft dann die Region von der Quelle zum Host einer VM im Back-End-Pool. Die Load Balancer-Infrastruktur führt dieselben Lastenausgleichs- und Übersetzungsvorgänge aus, wie sie dies für jeden anderen Datenverkehr tut. Sobald der Test auf dem Computehost eingeht, auf dem sich ein fehlerfreier virtueller Computer im Back-End-Pool befindet, generiert der Computehost eine Antwort an den Probingdienst. Ihr virtueller Computer „sieht“ diesen Datenverkehr nicht.
Beachten Sie, dass die Datenpfadverfügbarkeitsmetrik nur bei Front-End-IP-Konfigurationen mit Lastenausgleichsregeln generiert wird.
Die Datenpfadverfügbarkeitsmetrik kann aus den folgenden Gründen beeinträchtigt werden:
Ihre Bereitstellung hat keine fehlerfreien virtuellen Computern, die im Back-End-Pool verblieben sind.
Es ist ein Infrastrukturausfall aufgetreten.
Zu Diagnosezwecken können Sie die Datenpfadverfügbarkeit-Metrik zusammen mit dem Integritätsteststatus verwenden.
Verwenden Sie Mittelwert als Aggregation für die meisten Szenarien.
Reagieren die Back-End-Instanzen für meinen Lastenausgleich auf Tests?
Erweitern
Die Integritätsteststatus-Metrik beschreibt die Integrität Ihrer Anwendungsbereitstellung, wie Sie diese konfiguriert haben, als Sie den Integritätstest Ihres Lastenausgleichs konfiguriert haben. Der Load Balancer verwendet den Status des Integritätstests, um zu bestimmen, wohin neue Datenflüsse gesendet werden sollen. Integritätstests stammen aus einer Azure-Infrastrukturadresse und können im Gastbetriebssystem des virtuellen Computers angezeigt werden.
So rufen Sie den Integritätsteststatus für Ihre Lastenausgleichsressourcen ab:
Wählen Sie die Metrik Integritätsteststatus mit dem Aggregationstyp Mittelwert aus.
Wenden Sie einen Filter auf die erforderliche Front-End-IP-Adresse oder den erforderlichen Front-End-Port (oder auf beides) an.
Integritätstests schlagen aus den folgenden Gründen fehl:
Sie konfigurieren einen Integritätstest für einen Port, der nicht lauscht oder nicht reagiert oder das falsche Protokoll verwendet. Wenn für Ihren Dienst Direct Server Return- oder Floating IP-Regeln verwendet werden, vergewissern Sie sich, dass der Dienst auf die IP-Adresse der IP-Konfiguration der Netzwerkkarte und den Loopback lauscht, der mit der Front-End-IP-Adresse konfiguriert ist.
Ihre Netzwerksicherheitsgruppe, die Gastbetriebssystem-Firewall des virtuellen Computers oder die Filter auf Anwendungsebene lassen den Integritätstest-Datenverkehr nicht zu.
Verwenden Sie Mittelwert als Aggregation für die meisten Szenarien.
Wie überprüfe ich meine Statistiken für ausgehende Verbindungen?
Erweitern
Die SNAT-Verbindungen-Metrik beschreibt das Volumen erfolgreicher und fehlgeschlagener Verbindungen für ausgehende Datenflüsse.
Ein Volumen für fehlgeschlagene Verbindungen, das größer als 0 (null) ist, kennzeichnet eine SNAT-Portüberlastung. Sie müssen weitere Untersuchungen vornehmen, um festzustellen, wodurch diese Fehler verursacht werden können. Eine SNAT-Portüberlastung zeigt sich dadurch, dass kein ausgehender Datenfluss eingerichtet werden kann. Lesen Sie den Artikel über ausgehende Verbindungen, um die Szenarien und greifenden Mechanismen zu verstehen und Informationen über die Maßnahmen für Abmildern und Entwurf zu erhalten, um so eine SNAT-Portüberlastung zu verhindern.
So rufen Sie SNAT-Verbindungsstatistiken ab
Wählen Sie den Metriktyp SNAT-Verbindungen und Summe als Aggregation aus.
Gruppieren Sie nach dem Verbindungsstatus für die Anzahl erfolgreicher und die Anzahl fehlgeschlagener SNAT-Verbindungen, die durch unterschiedliche Linien dargestellt werden.
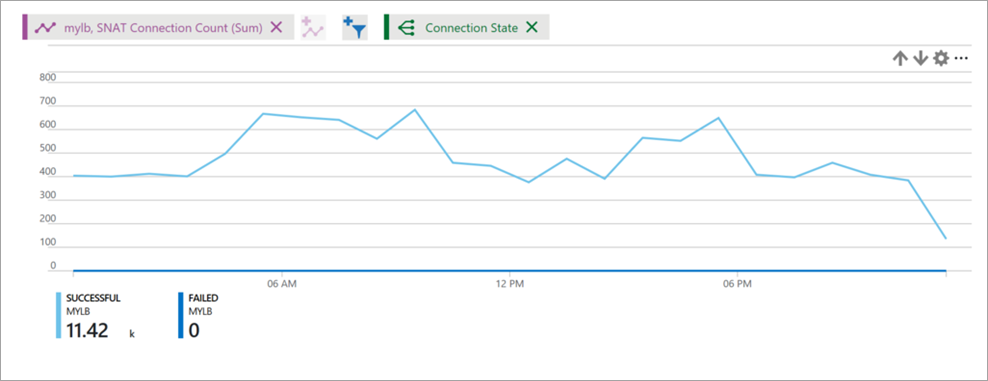
Abbildung: Anzahl von SNAT-Verbindungen des Lastenausgleichs
Wie überprüfe ich die Verwendung und Zuordnung meines SNAT-Ports?
Erweitern
Die Metrik für verwendete SNAT-Ports verfolgt nach, wie viele SNAT-Ports für ausgehende Flows genutzt werden. Diese Metrik zeigt an, wie viele eindeutige Flows zwischen einer Internetquelle und einer Back-End-VM oder einer VM-Skalierungsgruppe eingerichtet werden, die sich hinter einem Lastenausgleichsmodul befindet und keine öffentliche IP-Adresse besitzt. Durch Vergleich der Anzahl von verwendeten SNAT-Ports mit der Metrik der zugeordneten SNAT-Ports können Sie feststellen, ob eine SNAT-Überlastung (oder ein entsprechendes Risiko) für Ihren Dienst besteht, die zu Fehlern bei ausgehenden Flows führen kann.
Wenn Ihre Metriken auf das Risiko eines ausgehenden Flowfehlers hinweisen, verweisen Sie auf den Artikel und unternehmen Sie Schritte, um dies zu minimieren, um die Dienstintegrität sicherzustellen.
So zeigen Sie die Verwendung und Zuordnung von SNAT-Ports an
Legen Sie die Zeitaggregation des Diagramms auf eine Minute fest, um sicherzustellen, dass die gewünschten Daten angezeigt werden.
Wählen Sie Verwendete SNAT-Ports und/oder Zugeordnete SNAT-Ports als Metriktyp und Durchschnitt als Aggregation aus.
Standardmäßig stellen diese Metriken die durchschnittliche Anzahl der SNAT-Ports dar, die den einzelnen Back-End-VMs oder VM-Skalierungsgruppen zugewiesen sind oder von diesen verwendet werden. Sie entsprechen allen öffentlichen Front-End-IP-Adressen, die dem Lastenausgleich zugeordnet sind, aggregiert über TCP und UDP.
Verwenden Sie zum Anzeigen der gesamten SNAT-Ports, die der Lastenausgleich verwendet oder die ihm zugeordnet wurden, die Metrikaggregation Summe.
Filtern Sie nach einem bestimmten Protokolltyp, einer Reihe von Back-End-IP-Adressen und/oder Front-End-IP-Adressen.
Um die Integrität pro Back-End- oder Front-End-Instanz zu überwachen, wenden Sie die Teilung an.
- Durch die Teilung wird nur eine einzelne Metrik gleichzeitig angezeigt.
So können Sie z. B. die SNAT-Nutzung für TCP-Flows pro Computer überwachen, indem Sie nach Durchschnitt aggregieren, nach Back-End-IP-Adressen teilen und nach Protokolltyp filtern.
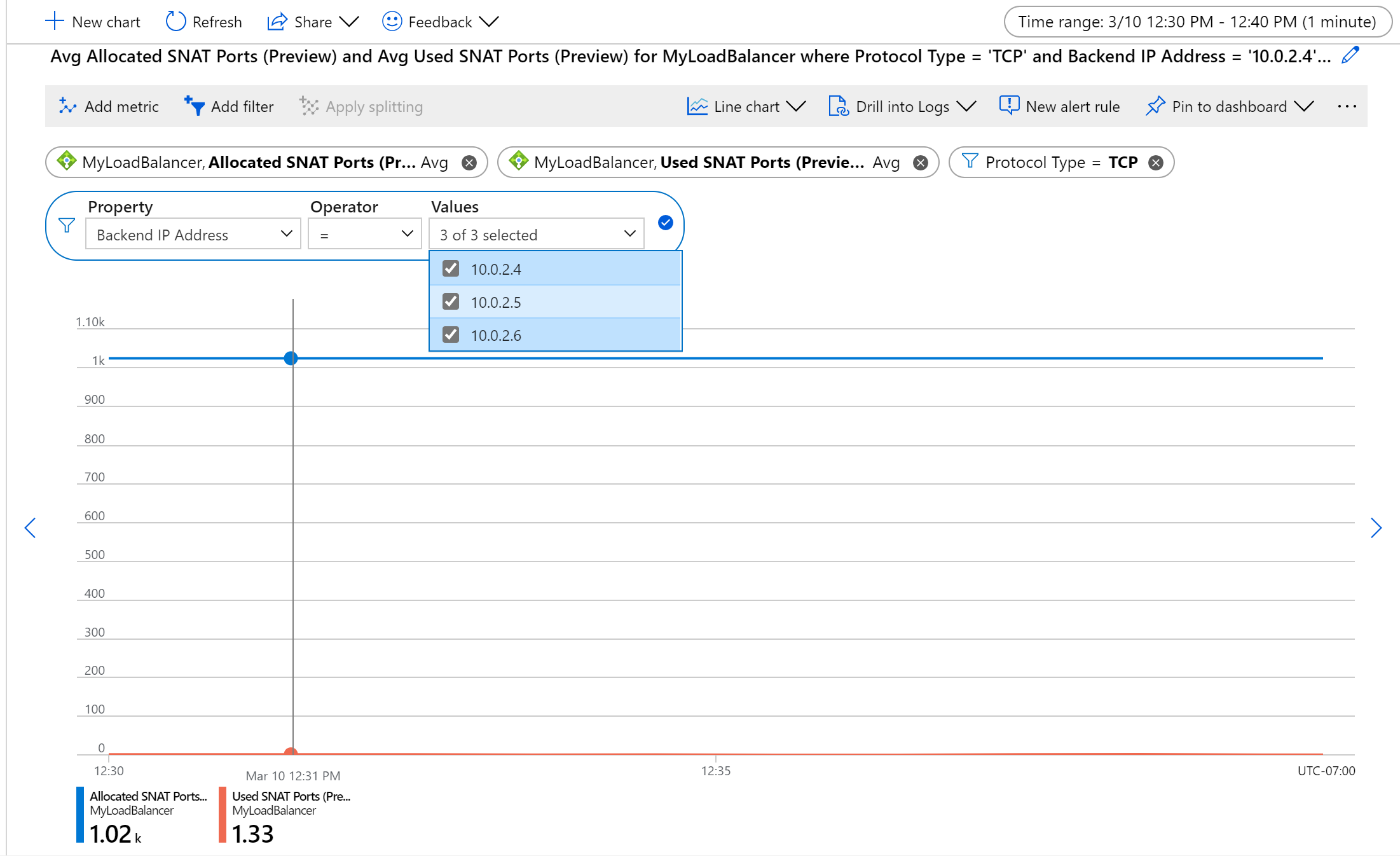
Abbildung: Durchschnittliche TCP-SNAT-Portzuordnung und -verwendung für eine Reihe von Back-End-VMs
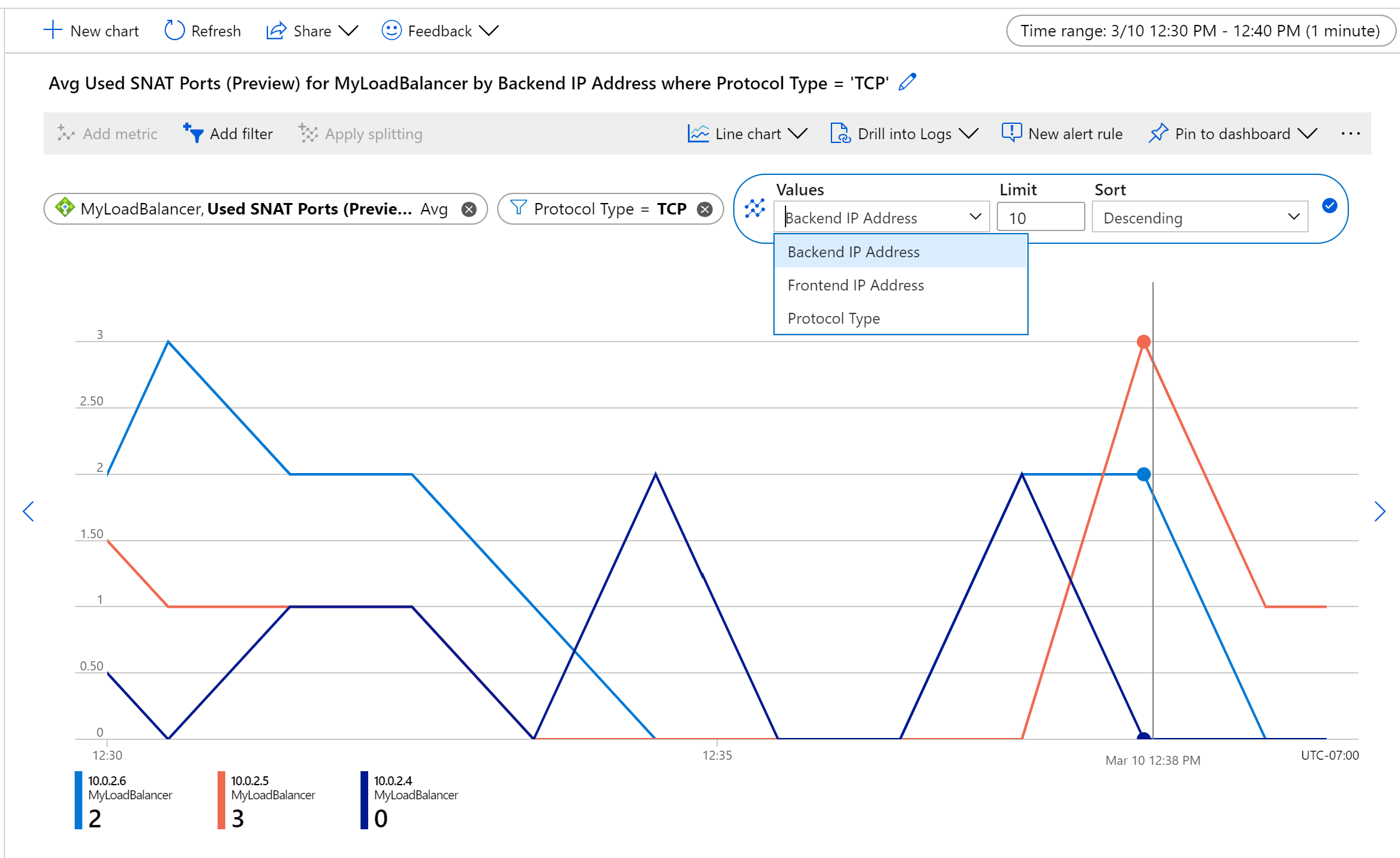
Abbildung: TCP SNAT-Portverwendung pro Back-End-Instanz
Wie überprüfe ich Versuche für eingehende/ausgehende Verbindungen für meinen Dienst?
Erweitern
: Eine SYN-Pakete-Metrik beschreibt das Volumen der TCP-SYN-Pakete, die für ausgehende Flows angekommen sind oder gesendet wurden und einem bestimmten Front-End zugeordnet sind. Mit dieser Metrik können TCP-Verbindungsversuche für Ihren Dienst ausgewertet werden.Weitere Informationen zu ausgehenden Verbindungen finden Sie unter Verwendung von SNAT (Source Network Address Translation) für ausgehende Verbindungen.
Verwenden Sie SUM als Aggregation für die meisten Szenarien.
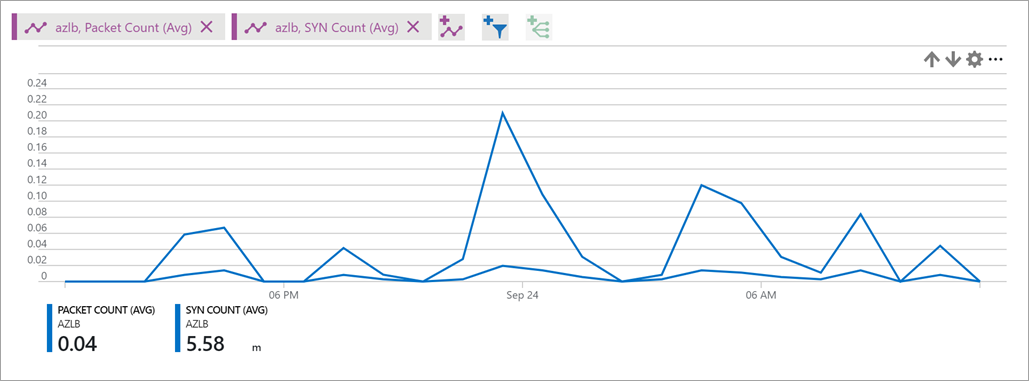
Abbildung: SYN-Anzahl des Lastenausgleichs
Wie überprüfe ich meine Netzwerkbandbreitennutzung?
Erweitern
Die Byte- und Paketleistungsindikatoren-Metrik beschreibt das Volumen der Bytes und Pakete, die jeweils pro Front-End von Ihrem Dienst gesendet oder empfangen wurden.
Verwenden Sie SUM als Aggregation für die meisten Szenarien.
So rufen Sie eine Byteanzahl- oder Paketzahlstatistik ab
Wählen Sie den Metriktyp Byteanzahl und/oder Paketzahl mit SUM als Aggregation aus.
Führen Sie einen der folgenden Schritte aus:
Wenden Sie einen Filter auf die gewünschte Komponente an: Front-End-IP, Front-End-Port oder Back-End-Port.
Rufen Sie die Gesamtstatistik für Ihre Load Balancer-Ressource ohne jegliche Filterung ab.
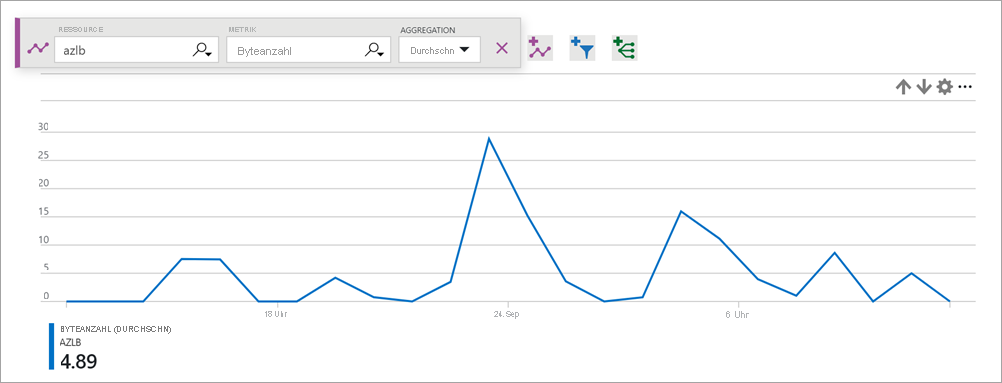
Abbildung: Byteanzahl des Lastenausgleichs
Wie führe ich eine Diagnose meiner Load Balancer-Bereitstellung durch?
Erweitern
Anhand einer Kombination der Metriken für Datenpfadverfügbarkeit und Integritätsteststatus in einem einzigen Diagramm können Sie erkennen, wo das Problem zu suchen ist und wie es sich beheben lässt. Sie können sich davon überzeugen, dass Azure ordnungsgemäß funktioniert, und auf dieser Grundlage eindeutig feststellen, dass die Konfiguration oder die Anwendung die Hauptursache ist.
Sie können Integritätstestmetriken verwenden, um zu erkennen, wie Azure die Integrität Ihrer Bereitstellung entsprechend der Konfiguration beurteilt, die Sie bereitgestellt haben. Ein Anzeigen der Integritätstests ist immer ein hervorragender erster Schritt beim Überwachen oder Ermitteln einer Ursache.
Sie können einen Schritt weiter gehen und Datenpfadverfügbarkeits-Metriken verwenden, um zu erfahren, wie Azure die Integrität der zugrunde liegenden Datenebene beurteilt, die für Ihre spezielle Bereitstellung zuständig ist. Wenn Sie beide Metriken kombinieren, können Sie, wie in diesem Beispiel veranschaulicht, gezielt feststellen, wo sich der Fehler befindet:
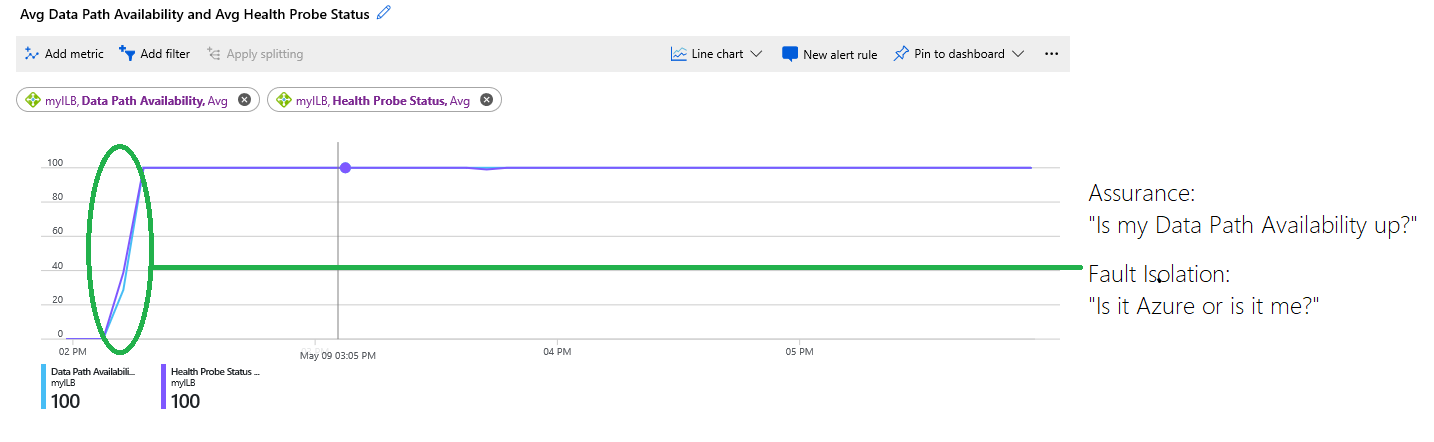
Abbildung: Kombinieren der Datenpfadverfügbarkeits- und Integritätsteststatus-Metriken
Im Diagramm werden die folgenden Informationen angezeigt:
Die Infrastruktur, in der Ihre virtuellen Computer gehostet werden, war am Anfang des Diagramms nicht verfügbar und lag bei 0 Prozent. Später war die Infrastruktur fehlerfrei, die virtuellen Computer waren erreichbar, und im Back-End waren mehrere virtuelle Computer platziert. Diese Informationen sind durch die blaue Ablaufverfolgung für Datenpfadverfügbarkeit gekennzeichnet, die später bei 100 Prozent lag.
Der Integritätsteststatus, der durch die violette Ablaufverfolgung gekennzeichnet ist, liegt jedoch am Anfang des Diagramms bei 0 Prozent. Der eingekreiste Bereich in Grün markiert, ab wann der Integritätsteststatus fehlerfrei wurde und an welchem Punkt die Bereitstellung des Kunden neue Datenflüsse akzeptieren konnte.
Anhand des Diagramms kann der Kunde eigenständig eine Fehlerbehebung für die Bereitstellung vornehmen, ohne zu erraten oder beim Support zu erfragen, ob andere Probleme auftreten. Der Dienst war nicht verfügbar, weil Integritätstests wegen einer Fehlkonfiguration oder einer fehlerhaften Anwendung fehlgeschlagen sind.
Konfigurieren von Warnungen für mehrdimensionale Metriken
Azure Load Balancer unterstützt leicht konfigurierbare Warnungen für mehrdimensionale Metriken. Konfigurieren Sie benutzerdefinierte Schwellenwerte für bestimmte Metriken, um Warnungen mit unterschiedlichen Schweregraden auszulösen und so eine berührungslose Ressourcenüberwachung zu ermöglichen.
So konfigurieren Sie Warnungen:
Wechseln Sie zur Seite „Warnung“ für den Lastenausgleich.
Erstellen einer neuen Warnungsregel
Konfigurieren der Warnungsbedingung (Hinweis: Um störende Warnungen zu vermeiden, empfehlen wir die Konfiguration von Warnungen, für die der Aggregationstyp auf „Durchschnitt“ festgelegt ist, Daten in den letzten fünf Minuten berücksichtigt werden und ein Schwellenwert von 95 % gilt.)
(Optional) Hinzufügen einer Aktionsgruppe für automatisierte Reparatur
Zuweisen von Schweregrad, Name und Beschreibung der Warnung, um eine intuitive Reaktion zu ermöglichen
Verfügbarkeitswarnungen für eingehenden Datenverkehr
Hinweis
Wenn die Back-End-Pools des Load Balancers leer sind, weist der Load Balancer keine gültigen Datenpfade zum Testen auf. Daher ist keine Metrik für die Datenpfadverfügbarkeit vorhanden, und die konfigurierten Azure-Warnungen für diese Metriken werden nicht ausgelöst.
Sie können mit den Metriken Datenpfadverfügbarkeit und Integritätsteststatus zwei verschiedene Warnungen zur Verfügbarkeit für eingehenden Datenverkehr erstellen. Kunden haben möglicherweise unterschiedliche Szenarien, die jeweils eine bestimmte Warnungslogik erfordern, die unten aufgeführten Beispiele sind jedoch für die meisten Konfigurationen hilfreich.
Mit der Datenpfadverfügbarkeit können Sie Warnungen auslösen, wenn eine bestimmte Lastenausgleichsregel nicht mehr angewendet werden kann. Sie können zum Konfigurieren dieser Warnung eine Warnungsbedingung für die Datenpfadverfügbarkeit festlegen und für Front-End-Port und Front-End-IP-Adresse eine Unterteilung nach allen aktuellen Werten und allen zukünftigen Werten vornehmen. Durch das Festlegen der Warnungslogik auf einen Wert kleiner oder gleich 0 wird diese Warnung ausgelöst, wenn eine Lastenausgleichsregel nicht mehr reagiert. Legen Sie die Aggregationsgranularität und die Häufigkeit der Auswertung gemäß der von Ihnen gewünschten Auswertung fest.
Mit „Integritätsteststatus“ kann eine Warnung ausgelöst werden, wenn eine bestimmte Back-End-Instanz für einen beträchtlichen Zeitraum nicht auf den Integritätstest reagiert. Legen Sie für die Warnungsbedingung die Verwendung der Integritätsteststatus-Metrikfest, und nehmen Sie eine Unterteilung nach Back-End-IP-Adresse und Back-End-Port vor. Dadurch wird sichergestellt, dass für die Fähigkeit jeder einzelnen Back-End-Instanz zum Bereitstellen von Datenverkehr an einem bestimmten Port gesonderte Warnungen ausgegeben werden können. Verwenden Sie den Aggregationstyp Average, und legen Sie den Schwellenwert entsprechend der Häufigkeit der Tests der Back-End-Instanz und Ihres Integritätsschwellenwerts fest.
Sie können auch Warnungen auf Ebene des Back-End-Pools bereitstellen, indem Sie nicht nach Dimensionen aufteilen und den Aggregationstyp Average verwenden. So können Sie Warnungsregeln einrichten, die z. B. eine Warnung auslösen, wenn 50 % der Mitglieder des Back-End-Pools fehlerhaft sind.
Verfügbarkeitswarnungen für ausgehenden Datenverkehr
Sie können mit den Metriken „Anzahl von SNAT-Verbindungen“ und „Verwendete SNAT-Ports“ zwei verschiedene Warnungen zur Verfügbarkeit für ausgehenden Datenverkehr erstellen.
Um Fehler bei ausgehenden Verbindungen zu erkennen, konfigurieren Sie eine Warnung, indem Sie die Anzahl von SNAT-Verbindungen verwenden und nach Verbindungsstatus = Fehler filtern. Verwenden Sie den Aggregationstyp Total. Sie können dann eine Unterteilung nach Back-End-IP-Adresse sowie nach allen aktuellen und zukünftigen Werten vornehmen, um für jede Back-End-Instanz mit fehlgeschlagenen Verbindungen gesonderte Warnungen bereitzustellen. Legen Sie einen höheren Schwellenwert als 0 fest, wenn Sie Fehler bei ausgehenden Verbindungen erwarten.
Mit verwendeten SNAT-Ports können Sie Warnungen bei einem höheren Risiko von SNAT-Auslastung und Fehlern bei ausgehenden Verbindungen bereitstellen. Nehmen Sie bei Verwendung dieser Warnung unbedingt eine Aufteilung nach Back-End-IP-Adresse und Protokoll vor. Verwenden Sie die Aggregation Durchschnitt. Legen Sie einen Schwellenwert fest, der größer ist als der Prozentsatz der pro Instanz zugeordneten Ports, den Sie als unsicher erachten. Konfigurieren Sie beispielsweise eine Warnung mit niedrigem Schweregrad, wenn eine Back-End-Instanz 75 % der ihr zugewiesenen Ports nutzt. Konfigurieren Sie eine Warnung mit hohem Schweregrad, wenn 90 % oder 100 % der zugeordneten Ports verwendet werden.
Ressourcenintegritätsstatus
Der Integritätsstatus für die standardmäßigen Lastenausgleichsressourcen wird über die vorhandene Ressourcenintegrität unter Überwachen > Dienstintegrität verfügbar gemacht. Er wird alle zwei Minuten ausgewertet. Dazu wird die Datenpfadverfügbarkeit gemessen, die bestimmt, ob Ihre Front-End-Lastenausgleichs-Endpunkte verfügbar sind.
| Ressourcenintegritätsstatus | BESCHREIBUNG |
|---|---|
| Verfügbar | Ihre Load Balancer Standard-Ressource ist fehlerfrei und verfügbar. |
| Heruntergestuft | Für die Load Balancer Standard-Instanz liegen plattform- oder benutzerseitig initiierte Ereignisse vor, die sich auf die Leistung auswirken. Die Metrik für die Datenpfadverfügbarkeit hat mindestens zwei Minuten lang weniger als 90 %, aber mehr als 25 %Integrität gemeldet. Bei diesem Status treten mittlere bis schwerwiegende Leistungsbeeinträchtigungen auf. Lesen Sie den Leitfaden zur Behandlung von Problemen mit RHC, um zu ermitteln, ob benutzerseitig initiierte Ereignisse vorliegen, die sich auf die Verfügbarkeit auswirken. |
| Nicht verfügbar | Ihre standardmäßige Lastenausgleichsressource ist nicht fehlerfrei. Die Metrik für die Datenpfadverfügbarkeit hat mindestens zwei Minuten lang weniger als 25 % Integrität gemeldet. Bei diesem Status sind Leistung und Verfügbarkeit für eingehende Verbindungen erheblich beeinträchtigt. Möglicherweise liegen Benutzer- oder Plattformereignisse vor, die eine Nichtverfügbarkeit verursachen. Lesen Sie den Leitfaden zur Behandlung von Problemen mit RHC, um zu ermitteln, ob benutzerseitig initiierte Ereignisse vorliegen, die sich auf die Verfügbarkeit auswirken. |
| Unbekannt | Der Integritätsstatus für Ihre Lastenausgleichsressource wurde in den letzten 10 Minuten nicht aktualisiert oder hat keine Informationen zur Verfügbarkeit des Datenpfads erhalten. Dieser Zustand sollte vorübergehend sein. Der korrekte Status wird angegeben, sobald Daten empfangen werden. |
So zeigen Sie die Integrität Ihrer öffentlichen standardmäßigen Lastenausgleichsressourcen an:
Wählen Sie Überwachen>Dienstintegrität aus.
Abbildung: Link „Dienstintegrität“ in Azure Monitor
Wählen Sie Dienstintegrität aus, und stellen Sie dann sicher, dass Abonnement-ID und Ressourcentyp = Load Balancer ausgewählt sind.
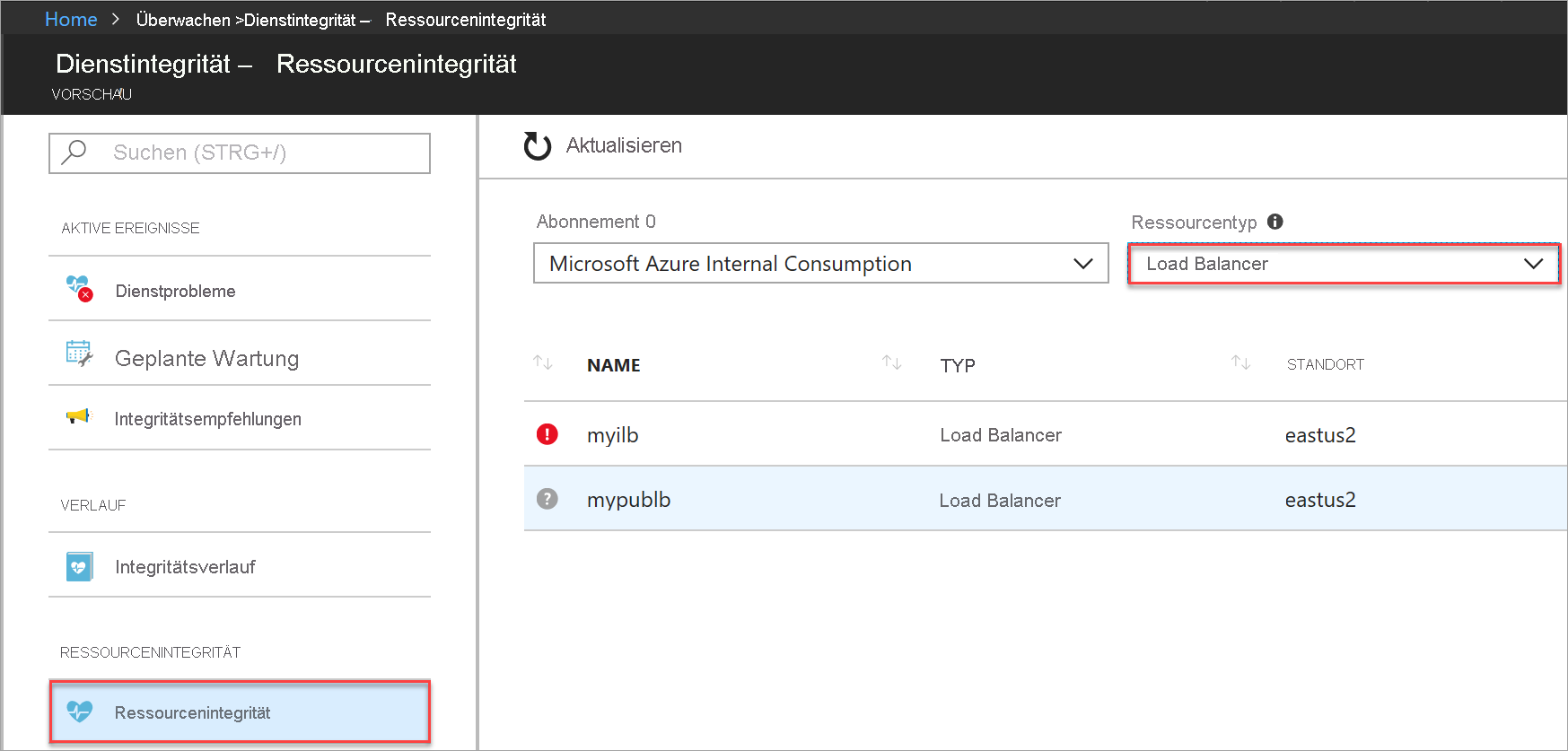
Abbildung: Ressource für Integritätsanzeige auswählen
Wählen Sie in der Liste die Lastenausgleichsressource aus, um deren Verlauf des Integritätsstatus anzuzeigen.
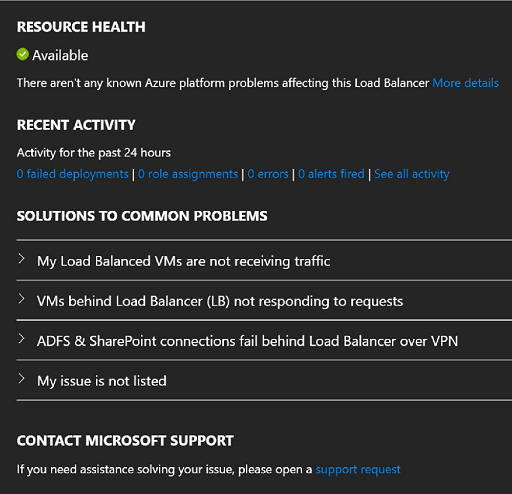
Abbildung: Ressourcenintegritätsstatus
Eine allgemeine Beschreibung eines Ressourcenintegritätsstatus finden Sie in der Übersicht über Resource Health.
Ressourcenintegritätsbenachrichtigungen
Mithilfe von Azure Resource Health-Benachrichtigungen können Sie nahezu in Echtzeit informiert werden, wenn sich der Integritätszustand Ihrer Lastenausgleichsressource ändert. Es wird empfohlen, Ressourcenintegritätswarnungen so festzulegen, dass Sie benachrichtigt werden, wenn sich Ihre Load Balancer-Ressource im Status Beeinträchtigt oder Nicht verfügbar befindet.
Wenn Sie Azure Resource Health-Warnungen für Load Balancer erstellen, sendet Azure Ressourcenintegritätsbenachrichtigungen an Ihr Azure-Abonnement. Sie können Benachrichtigungen auf folgenden Grundlagen erstellen und anpassen:
- Dem betroffenen Abonnement
- Der betroffenen Ressourcengruppe
- Dem betroffenen Ressourcentyp (Lastenausgleich)
- Der spezifischen Ressource (jede Load Balancer-Ressource, für die Sie eine Benachrichtigung einrichten möchten)
- Dem Ereignisstatus der betroffenen Load Balancer-Ressource
- Dem aktuellen Status der betroffenen Load Balancer-Ressource
- Dem vorherigen Status der betroffenen Load Balancer-Ressource
- Dem Ursachentyp der betroffenen Load Balancer-Ressource
Darüber hinaus können Sie konfigurieren, an wen die Warnung gesendet werden soll:
- Eine neue Aktionsgruppe (die für zukünftige Benachrichtigungen verwendet werden kann)
- Eine vorhandene Aktionsgruppe
Weitere Informationen zum Einrichten dieser Ressourcenintegritätswarnungen finden Sie unter:
- Ressourcenintegritätswarnungen über das Azure-Portal
- Ressourcenintegritätswarnungen mithilfe von Resource Manager-Vorlagen
Nächste Schritte
- Weitere Informationen zur Netzwerkanalyse.
- Erfahren Sie mehr über die Verwendung von Erkenntnissen, um diese Metriken für Ihren Load Balancer vorkonfiguriert anzuzeigen.
- Informieren Sie sich über den standardmäßigen Lastenausgleich.