Endpunkte für Rückschlüsse in der Produktion
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Nachdem Sie Machine Learning-Modelle oder Pipelines trainiert haben oder Modelle aus dem Modellkatalog gefunden haben, die Ihren Anforderungen entsprechen, müssen Sie sie in der Produktion bereitstellen, damit andere sie für Rückschlüsseverwenden können. Rückschluss ist der Prozess, bei dem neue Eingabedaten auf ein Machine Learning-Modell oder die Pipeline angewandt werden, um Ausgaben zu generieren. Obwohl diese Ausgaben in der Regel als „Vorhersagen“ bezeichnet werden, können Rückschlüsse verwendet werden, um Ausgaben für andere Aufgaben zum maschinellen Lernen wie Klassifizierung und Clustering zu generieren. In Azure Machine Learning führen Sie Rückschlüsse mithilfe von Endpunkten durch.
Endpunkte und Bereitstellungen
Ein Endpunkt ist eine stabile und dauerhafte URL, die verwendet werden kann, um ein Modell anzufordern oder aufzurufen. Sie stellen die erforderlichen Eingaben für den Endpunkt bereit und rufen die Ausgaben ab. Mit Azure Machine Learning können Sie serverlose API-Endpunkte,Onlineendpunkte und Batchendpunkte implementieren. Ein Endpunkt bietet Folgendes:
- eine stabile und dauerhafte URL (z. B. endpunktname.region.inference.ml.azure.com)
- einen Authentifizierungsmechanismus
- einen Autorisierungsmechanismus
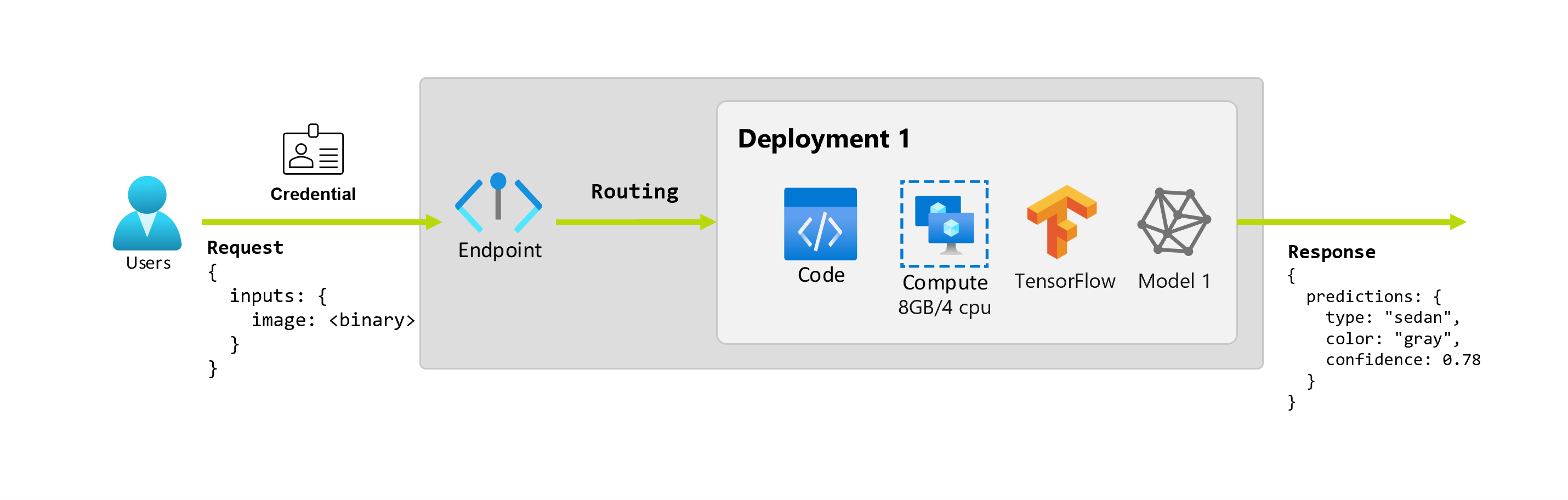
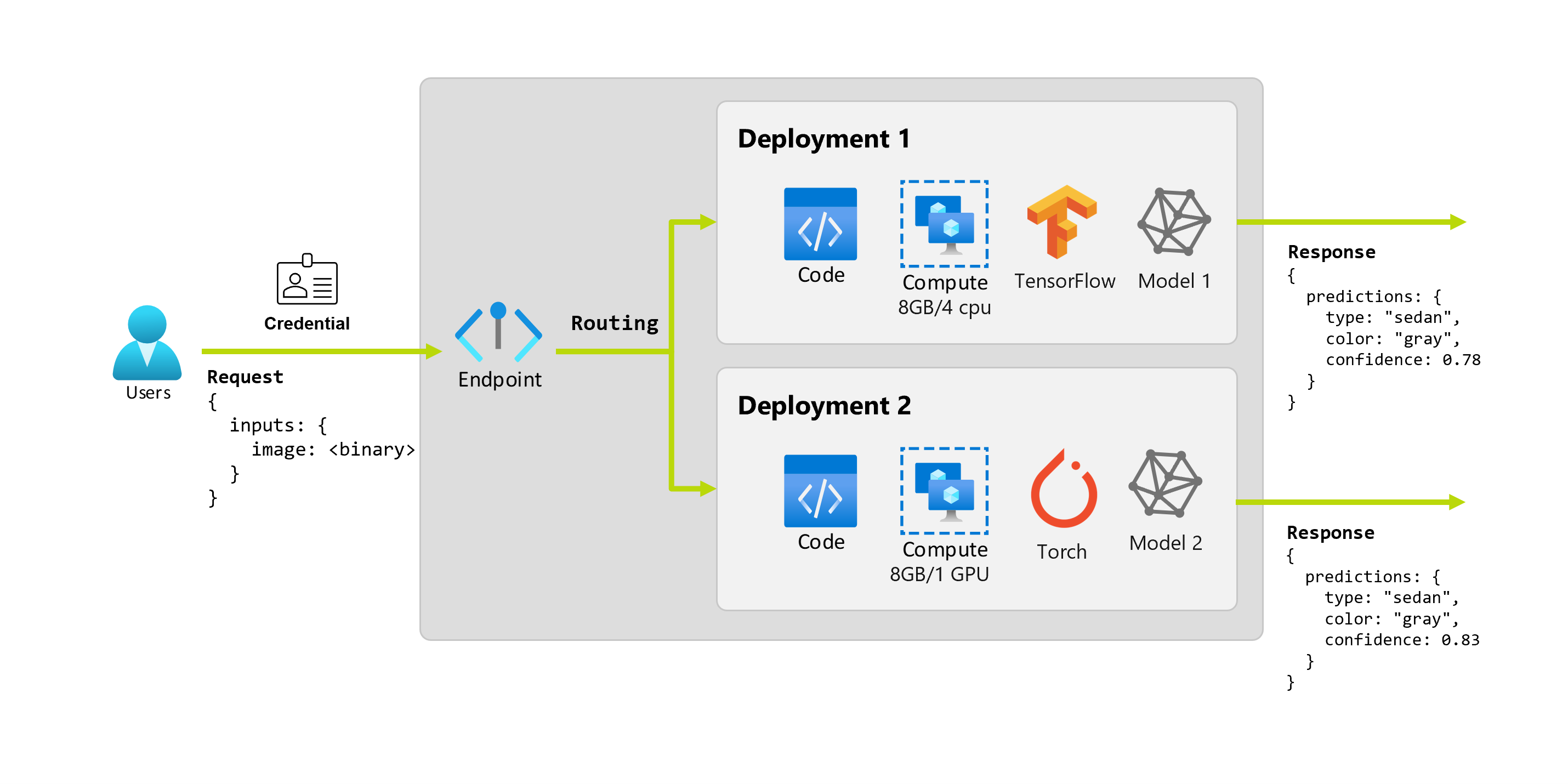
Eine Bereitstellung umfasst (Compute-)Ressourcen, die für das Hosting des Modells oder der Komponente erforderlich sind, das/die den eigentlichen Rückschluss durchführt. Ein Endpunkt enthält eine Bereitstellung, und für Online- und Batchendpunkte kann ein Endpunkt mehrere Bereitstellungen enthalten. Die Bereitstellungen können unabhängige Ressourcen hosten und je nach Bedarf unterschiedliche Ressourcen nutzen. Darüber hinaus verfügt ein Onlineendpunkt über einen Routingmechanismus, der Anforderungen an beliebige seiner Bereitstellungen weiterleiten kann.
Auf der anderen Seite nutzen einige Arten von Endpunkten in Azure Machine Learning dedizierte Ressourcen für ihre Bereitstellungen. Damit diese Endpunkte ausgeführt werden können, müssen Sie über ein Computekontingent für Ihr Azure-Abonnement verfügen. Andererseits unterstützen bestimmte Modelle eine serverlose Bereitstellung, sodass sie kein Kontingent aus Ihrem Abonnement verbrauchen. Für die serverlose Bereitstellung wird die Nutzung in Rechnung gestellt.
Intuition
Angenommen, Sie arbeiten an einer Anwendung, die den Typ und die Farbe eines Autos anhand seines Fotos vorhersagen soll. Für diese Anwendung senden Benutzer*innen mit bestimmten Anmeldeinformationen eine HTTP-Anforderung an eine URL und übergeben darin ein Bild eines Autos. Als Antwort erhalten die Benutzer*innen den Typ und die Farbe des Fahrzeugs als Zeichenfolgenwerte. In diesem Szenario dient die URL als Endpunkt.
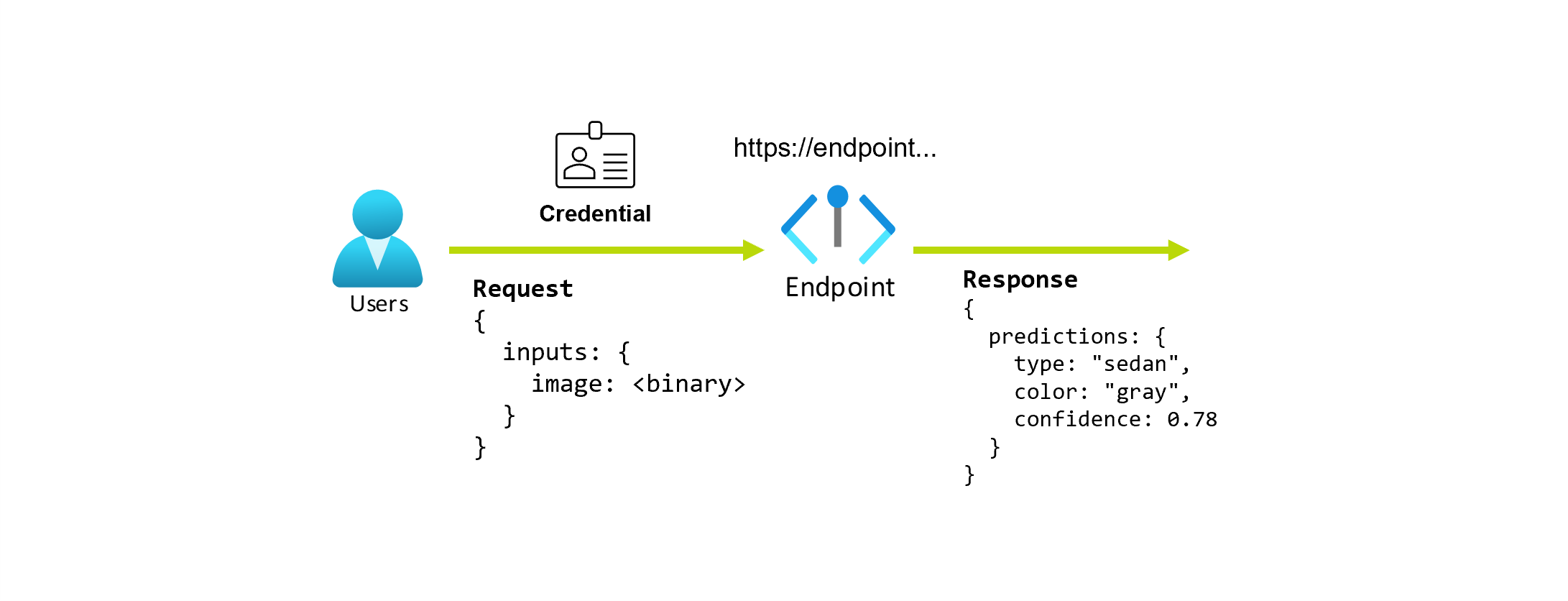
Angenommen, Alice, eine wissenschaftliche Fachkraft für Daten, arbeitet an der Implementierung der Anwendung. Alice weiß viel über TensorFlow und beschließt, das Modell mithilfe eines sequenziellen Keras-Klassifizierers mit einer RestNet-Architektur vom TensorFlow-Hub zu implementieren. Nach dem Testen des Modells ist Alice mit den Ergebnissen zufrieden und beschließt, das Modell zu verwenden, um das Problem mit der Autovorhersage zu lösen. Das Modell ist groß und erfordert für die Ausführung 8 GB Arbeitsspeicher und 4 Kerne. In diesem Szenario bilden das Modell von Alice und die Ressourcen (z. B. Code und Computeressourcen), die zum Ausführen des Modells erforderlich sind, eine Bereitstellung an dem Endpunkt.
Stellen Sie sich vor, dass die Organisation nach einigen Monaten feststellt, dass die Anwendung bei Bildern ohne ideale Beleuchtungsbedingungen schlecht abschneidet. Bob, eine weitere wissenschaftliche Fachkraft für Daten, weiß viel über Datenargumentationstechniken, die dabei helfen können, das Modell in diesem Bereich stabiler zu machen. Bob arbeitet jedoch lieber mit Torch, um das Modell zu implementieren, und er trainiert daher ein neues Modell mit Torch. Bob möchte dieses Modell schrittweise in der Produktion ausprobieren, bis die Organisation bereit ist, das alte auszumustern. Das neue Modell bietet auch eine bessere Leistung, wenn es auf der GPU bereitgestellt wird, sodass die Bereitstellung eine GPU umfassen muss. In diesem Szenario bilden das Modell von Bob und die Ressourcen (z. B. Code und Computeressourcen), die zum Ausführen des Modells erforderlich sind, eine andere Bereitstellung an demselben Endpunkt.
Endpunkte: serverlose API, Online und Batch
Mit Azure Machine Learning können Sie serverlose API-Endpunkte,Onlineendpunkte und Batchendpunkte implementieren.
Serverlose API-Endpunkte und Onlineendpunkte sind für die Echtzeitrückschluss konzipiert. Wenn Sie den Endpunkt aufrufen, werden die Ergebnisse in der Antwort des Endpunkts zurückgegeben. Serverlose API-Endpunkte verbrauchen kein Kontingent aus Ihrem Abonnement; sie werden stattdessen mit nutzungsbasierter Bezahlung in Rechnung gestellt.
Batchendpunkte sind für den Batchrückschluss mit langer Ausführungszeit konzipiert. Wenn Sie einen Batchendpunkt aufrufen, generieren Sie einen Batchauftrag, der die eigentliche Arbeit ausführt.
Verwendung serverloser API, Online- und Batchendpunkte
Serverlose API-Endpunkte:
Verwenden Sie serverlose API-Endpunkte, um große Basismodelle für vorgefertigte Echtzeit-Inferenzen zu nutzen oder solche Modelle zu verfeinern. Nicht alle Modelle sind für die Bereitstellung für serverlose API-Endpunkte verfügbar. Es wird empfohlen, diesen Bereitstellungsmodus zu verwenden, wenn:
- Ihr Modell ist ein grundlegendes Modell oder eine fein abgestimmte Version eines grundlegenden Modells, das für serverlose API-Bereitstellungen verfügbar ist.
- Sie können von einer kontingentlosen Bereitstellung profitieren.
- Sie müssen den ableitenden Stapel, der zum Ausführen des Modells verwendet wird, nicht anpassen.
Onlineendpunkte:
Verwenden Sie Onlineendpunkte, um Modelle für Echtzeitrückschlüsse in synchronen Anforderungen mit niedriger Latenz zu operationalisieren. Es wird empfohlen, sie in folgenden Fällen zu verwenden:
- Ihr Modell ist ein grundlegendes Modell oder eine fein abgestimmte Version eines grundlegenden Modells, wird jedoch nicht in serverlosen API-Endpunkten unterstützt.
- Sie haben Anforderungen mit geringer Latenz.
- Ihr Modell kann die Anforderung in relativ kurzer Zeit beantworten.
- Die Eingaben Ihres Modells passen zur HTTP-Nutzdatenlast der Anforderung.
- Sie müssen die Anzahl der Anforderungen hochskalieren.
Batchendpunkte:
Verwenden Sie Batch-Endpunkte, um Modelle oder Pipelines für langlaufende asynchrone Inferenz zu operationalisieren. Es wird empfohlen, sie in folgenden Fällen zu verwenden:
- Sie verfügen über teure Modelle oder Pipelines, für die die Ausführung mehr Zeit in Anspruch nimmt.
- Sie möchten Machine Learning-Pipelines operationalisieren und Komponenten wiederverwenden.
- Sie müssen Rückschlüsse auf große Datenmengen durchführen, die auf mehrere Dateien verteilt sind.
- Sie haben keine niedrigen Latenzanforderungen.
- Die Eingaben Ihres Modells werden in einem Speicherkonto oder in einem Azure Machine Learning-Datenobjekt gespeichert.
- Sie können die Parallelisierung nutzen.
Vergleich von serverlosen API-, Online- und Batchendpunkten
Alle serverlosen API-, Online- und Batchendpunkte basieren auf der Idee von Endpunkten, die Ihnen den einfachen Übergang von einem zum anderen erleichtern. Online- und Batchendpunkte können außerdem mehrere Bereitstellungen für denselben Endpunkt verwalten.
Endpunkte
Die folgende Tabelle enthält eine Zusammenfassung der verschiedenen Features von serverlosen API, Online- und Batchendpunkten auf Enpunktebene.
| Funktion | Serverlose API-Endpunkte | Onlineendpunkte | Batchendpunkte |
|---|---|---|---|
| Stabile Aufruf-URL | Ja | Ja | Ja |
| Unterstützung für mehrere Bereitstellungen | No | Ja | Ja |
| Routing der Bereitstellung | Keine | Datenverkehrsaufteilung | Wechsel zur Standardeinstellung |
| Spiegeln des Datenverkehrs für einen sicheren Rollout | No | Ja | Nein |
| Swagger-Unterstützung | Ja | Ja | Nein |
| Authentifizierung | Schlüssel | Schlüssel und Microsoft Entra ID (Vorschau) | Microsoft Entra ID |
| Unterstützung für private Netzwerke (Legacy) | No | Ja | Ja |
| Verwaltete Netzwerkisolation | Ja | Ja | Ja (siehe zusätzliche erforderliche Konfiguration) |
| Kundenseitig verwaltete Schlüssel | Nicht zutreffend | Ja | Ja |
| Kostenbasis | Pro Endpunkt, pro Minute1 | Keine | Keine |
1Für serverlose API-Endpunkte pro Minute wird ein kleiner Bruchteil berechnet. Im Abschnitt Bereitstellungen finden Sie die Gebühren für den Verbrauch, die pro Token in Rechnung gestellt werden.
Bereitstellungen
Die folgende Tabelle enthält eine Zusammenfassung der verschiedenen Features von serverlosen API, Online- und Batchendpunkten auf Bereitstellungsebene. Diese Konzepte gelten für jede Bereitstellung unter dem Endpunkt (für Online- und Batchendpunkte) und gelten für serverlose API-Endpunkte (bei denen das Bereitstellungskonzept in den Endpunkt integriert ist).
| Funktion | Serverlose API-Endpunkte | Onlineendpunkte | Batchendpunkte |
|---|---|---|---|
| Bereitstellungstypen | Modelle | Modelle | Modelle und Rohrleitungskomponenten |
| MLflow-Modellimplementierung | Nein, nur bestimmte Modelle im Katalog | Ja | Ja |
| Benutzerdefinierte Modellimplementierung | Nein, nur bestimmte Modelle im Katalog | Ja, mit Bewertungsskript | Ja, mit Bewertungsskript |
| Modellpaketbereitstellung 2 | Integriert | Ja (Vorschau) | No |
| Rückschlussserver 3 | Azure AI Model Inference API | – Azure Machine Learning Inferencing Server – Triton – Benutzerdefiniert (mit BYOC) |
Batchrückschluss |
| Verbrauchte Computeressource | Keine (serverlos) | Instanzen oder granulare Ressourcen | Clusterinstanzen |
| Computetyp | Keine (serverlos) | Verwaltetes Compute und Kubernetes | Verwaltetes Compute und Kubernetes |
| Compute mit niedriger Priorität | Nicht verfügbar | No | Ja |
| Compute mit Skalierung auf 0 (null) | Integriert | No | Ja |
| Compute mit automatischer Skalierung4 | Integriert | Ja, basierend auf der Nutzung der Ressourcen | Ja, basierend auf der Anzahl der Aufträge |
| Verwaltung von Überkapazitäten | Drosselung | Drosselung | Queuing |
| Kostenbasis5 | Pro Token | Pro Bereitstellung: Compute-Instanzen, die ausgeführt werden | Pro Auftrag: Im Auftrag verbrauchte Compute-Instanz (begrenzt auf die maximale Anzahl von Instanzen des Clusters) |
| Lokale Tests von Bereitstellungen | No | Ja | No |
2 Die Bereitstellung von MLflow-Modellen auf Endpunkten ohne ausgehende Internetverbindung oder private Netzwerke erfordert zuerst das Packen des Modells.
3 Rückschlussserver bezieht sich auf die Bereitstellungstechnologie, die Anforderungen akzeptiert und verarbeitet und die Antworten erstellt. Der Rückschlussserver gibt außerdem das Format der Eingabe und der erwarteten Ausgaben vor.
4 Die automatische Skalierung bietet die Möglichkeit, die zugeordneten Ressourcen der Bereitstellung basierend auf ihrer Last dynamisch hoch- oder herunterzuskalieren. Online- und Batchbereitstellungen verwenden unterschiedliche Strategien für die automatische Skalierung. Während Onlinebereitstellungen basierend auf der Ressourcenauslastung (z. B. CPU, Arbeitsspeicher, Anforderungen usw.) hoch- und herunterskaliert werden, werden Batchendpunkte basierend auf der Anzahl der erstellten Aufträge hoch- oder herunterskaliert.
5 Sowohl Online- als auch Batchbereitstellungen werden nach verbrauchten Ressourcen berechnet. Bei Onlinebereitstellungen werden Ressourcen zum Zeitpunkt der Bereitstellung bereitgestellt. Bei der Batchbereitstellung werden zur Bereitstellungszeit keine Ressourcen verbraucht, sondern erst zum Zeitpunkt der Ausführung des Auftrags. Daher fallen keine Kosten im Zusammenhang mit der Batchbereitstellung selbst an. Ebenso verbrauchen auch Aufträge in der Warteschlange keine Ressourcen.
Entwicklerschnittstellen
Endpunkte sollen Organisationen bei der Operationalisierung von Workloads auf Produktionsebene in Azure Machine Learning unterstützen. Endpunkte sind robuste und skalierbare Ressourcen, die die besten Funktionen zum Implementieren von MLOps-Workflows bieten.
Sie können Batch- und Onlineendpunkten mit verschiedenen Entwicklungstools erstellen und verwalten:
- Die Azure CLI und das Python SDK
- Azure-Resource Manager/REST-API
- Azure Machine Learning Studio-Webportal
- Azure-Portal (IT/Administrator)
- Unterstützung für CI/CD-MLOps-Pipelines über die Azure CLI- und REST-/ARM-Schnittstelle