Machine Learning-Registrierungen für MLOps
In diesem Artikel wird beschrieben, wie Azure Machine Learning-Registrierungen Ressourcen des maschinellen Lernens von Arbeitsbereichen entkoppeln, sodass Sie MLOps in Entwicklungs-, Test- und Produktionsumgebungen verwenden können. Ihre Umgebungen können je nach Komplexität Ihrer IT-Systeme variieren. Die folgenden Faktoren beeinflussen die Anzahl und Art der von Ihnen benötigten Umgebungen:
- Sicherheits- und Compliancerichtlinien. Produktionsumgebungen müssen möglicherweise in Bezug auf Zugriffssteuerung, Netzwerkarchitektur und Datengefährdung von Entwicklungsumgebungen isoliert werden.
- Abonnements. Entwicklungsumgebungen und Produktionsumgebungen verwenden häufig separate Abonnements für Abrechnungs-, Budgetierungs- und Kostenverwaltungszwecke.
- Regionen Möglicherweise müssen Sie in verschiedenen Azure-Regionen bereitstellen, um Wartezeit- und Redundanzanforderungen zu unterstützen.
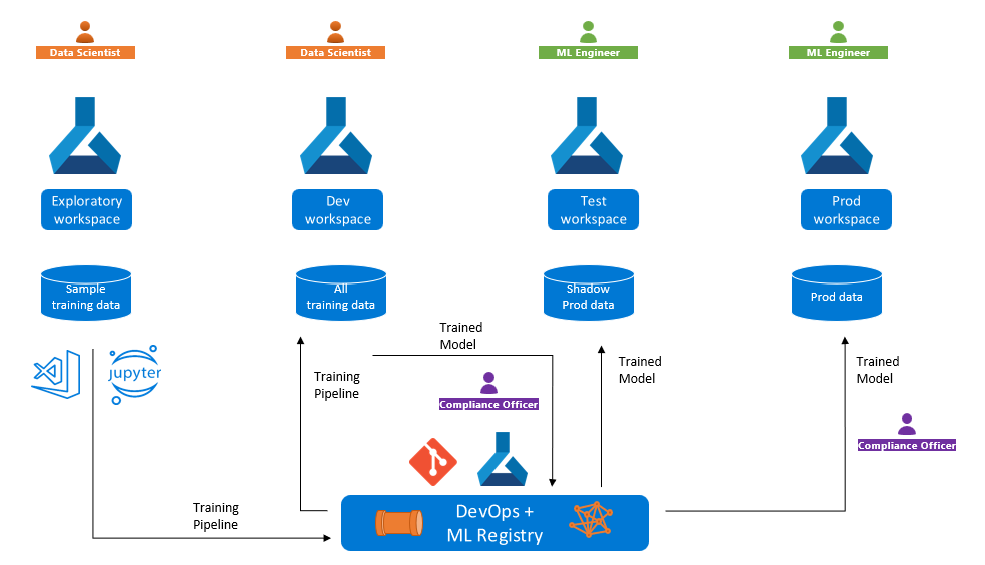
In den vorstehenden Szenarien verwenden Sie möglicherweise verschiedene Azure Machine Learning-Arbeitsbereiche für Entwicklung, Test und Produktion. Diese Konfiguration birgt die folgenden potentiellen Herausforderungen für das Training und die Bereitstellung der Modelle:
Möglicherweise müssen Sie ein Modell in einem Entwicklungsarbeitsbereich trainieren, es aber für einen Endpunkt in einem Produktionsarbeitsbereich bereitstellen, möglicherweise in einem anderen Azure-Abonnement oder einer anderen Region. In diesem Fall müssen Sie in der Lage sein, den Trainingsauftrag zurückzuverfolgen. Wenn Sie beispielsweise Probleme mit der Genauigkeit oder Leistung bei der Produktionsbereitstellung haben, müssen Sie die Metriken, Protokolle, den Code, die Umgebung und die Daten analysieren, die Sie zum Trainieren des Modells verwendet haben.
Möglicherweise müssen Sie eine Trainingspipeline mit Testdaten oder anonymisierten Daten im Entwicklungsarbeitsbereich entwickeln, aber das Modell mit Produktionsdaten im Produktionsarbeitsbereich neu trainieren. In diesem Fall müssen Sie möglicherweise die Trainingsmetriken von Stichproben mit denen der Produktionsdaten vergleichen, um sicherzustellen, dass die Trainingsoptimierungen mit den tatsächlichen Daten gut funktionieren.
Arbeitsbereichsübergreifende MLOps mit Registrierungen
Eine Registrierung, ähnlich wie ein Git-Repository, entkoppelt Ressourcen des maschinellen Lernens von Arbeitsbereichen und hostet die Ressourcen an einem zentralen Speicherort, sodass sie für alle Arbeitsbereiche in Ihrer Organisation verfügbar sind. Sie können Registrierungen verwenden, um Objekte wie Modelle, Umgebungen, Komponenten und Datasets zu speichern und zu teilen.
Um Modelle in Entwicklungs-, Test- und Produktionsumgebungen höher zu stufen, können Sie mit der iterativen Entwicklung eines Modells in der Entwicklungsumgebung beginnen. Wenn Sie über ein geeignetes Kandidatenmodell verfügen, können Sie es in einer Registrierung veröffentlichen. Sie können das Modell dann von der Registrierung aus an Endpunkten in verschiedenen Arbeitsbereichen bereitstellen.
Tipp
Wenn Sie in einem Arbeitsbereich bereits Modelle registriert haben, können Sie die Modelle in eine Registrierung höher stufen. Sie können ein Modell auch direkt aus der Ausgabe eines Trainingsauftrags in einer Registrierung registrieren.
Um eine Pipeline in einem Arbeitsbereich zu entwickeln und dann in anderen Arbeitsbereichen auszuführen, beginnen Sie mit der Registrierung der Komponenten und Umgebungen, welche die Bausteine der Pipeline bilden. Wenn Sie den Pipelineauftrag übermitteln, bestimmen die Compute- und Trainingsdaten, die für jeden Arbeitsbereich eindeutig sind, den Arbeitsbereich, in dem er ausgeführt wird.
Das folgende Diagramm zeigt die Schulungspipeline-Höherstufung zwischen explorativen und Entwicklungsarbeitsbereichen, dann die Höherstufung des trainierten Modells nach Test und Produktion.