Verwenden des Dashboards für verantwortungsvolle KI in Azure Machine Learning Studio
Dashboards für verantwortungsbewusste KI sind mit Ihren registrierten Modellen verknüpft. Um Ihr Dashboard für verantwortungsbewusste KI anzuzeigen, wechseln Sie zu Ihrer Modellregistrierung, und wählen Sie das registrierte Modell aus, für das Sie ein Dashboard für verantwortungsbewusste KI generiert haben. Wählen Sie dann die Registerkarte Verantwortungsvolle KI, um eine Liste der generierten Dashboards anzuzeigen.

Sie können mehrere Dashboards konfigurieren und an Ihr registriertes Modell anhängen. An jedes Responsible-AI-Dashboard können verschiedene Kombinationen von Komponenten (Interpretierbarkeit, Fehleranalyse, Ursachenanalyse usw.) angehängt werden. Die folgende Abbildung zeigt die Anpassung eines Dashboards und die darin generierten Komponenten. In jedem Dashboard können Sie verschiedene Komponenten innerhalb der Dashboard-Benutzeroberfläche selbst anzeigen oder ausblenden.

Wählen Sie den Namen des Dashboards aus, um es in einer Vollansicht in Ihrem Browser zu öffnen. Um zur Liste der Dashboards zurückzukehren, können Sie jederzeit zurück zu Modelldetails auswählen.

Vollständige Funktionalität mit integrierter Computeressource
Einige Funktionen des Responsible AI-Dashboards erfordern dynamische Berechnungen in Echtzeit und in Echtzeit (z. B. Was-wäre-wenn-Analysen). Wenn Sie keine Computeressource mit dem Dashboard verbinden, kann es sein, dass einige Funktionen fehlen. Wenn Sie eine Verbindung zu einer Computeressource herstellen, aktivieren Sie die volle Funktionalität Ihres Responsible AI-Dashboards für die folgenden Komponenten:
- Fehleranalyse
- Wenn Sie Ihre globale Datenkohorte auf eine beliebige gewünschte Kohorte festlegen, wird die Fehlerstruktur aktualisiert, anstatt sie zu deaktivieren.
- Auswählen anderer Fehler- oder Leistungsmetriken wird unterstützt.
- Das Auswählen einer beliebigen Teilmenge von Features zum Trainieren der Fehlerstrukturzuordnung wird unterstützt.
- Das Ändern der Mindestanzahl von Stichproben, die pro Blattknoten erforderlich sind, und der Tiefe der Fehlerstruktur wird unterstützt.
- Die dynamische Aktualisierung der Heatmap für bis zu zwei Features wird unterstützt.
- Featurepriorität
- Ein individuelles bedingtes Erwartungsdiagramm (ICE) auf der Registerkarte „Individuelle Featurerelevanz“ wird unterstützt.
- Kontrafaktische Was-wäre-wenn-Annahme
- Die Generierung eines neuen kontrafaktischen Was-wäre-wenn-Datenpunkts, um die für ein gewünschtes Ergebnis erforderliche Mindeständerung zu verstehen, wird unterstützt.
- Ursachenanalyse
- Das Auswählen eines einzelnen Datenpunkts, das Stören seiner Behandlungsfunktionen und das Anzeigen des erwarteten kausalen Ergebnisses des kausalen Was-wäre-wenn wird unterstützt (nur für Regressionsszenarien für maschinelles Lernen).
Sie können diese Informationen auch auf der Dashboard-Seite von Responsible AI finden, indem Sie das Symbol Informationen auswählen, wie in der folgenden Abbildung gezeigt:

Aktivieren Sie die volle Funktionalität des Responsible AI-Dashboards
Wählen Sie oben im Dashboard in der Dropdown-Liste Compute eine ausgeführte Compute-Instanz aus. Wenn Sie keine ausgeführten Computeressourcen haben, erstellen Sie eine neue Compute-Instanz, indem Sie das Pluszeichen (+) neben der Dropdownliste auswählen. Oder Sie können die Schaltfläche Compute starten auswählen, um eine angehaltene Compute-Instanz zu starten. Das Erstellen oder Starten einer Compute-Instanz kann einige Minuten dauern.

Wenn sich ein Compute im Status Wird ausgeführt befindet, beginnt Ihr Responsible AI-Dashboard, eine Verbindung mit der Compute-Instanz herzustellen. Dazu wird auf der ausgewählten Recheninstanz ein Terminalprozess erstellt und auf dem Terminal ein Responsible AI-Endpunkt gestartet. Wählen Sie Terminalausgaben anzeigen aus, um den aktuellen Terminalprozess anzuzeigen.

Wenn Ihr Dashboard für verantwortungsbewusste KI mit der Compute-Instanz verbunden ist, wird eine grüne Meldungsleiste angezeigt, und das Dashboard ist nun voll funktionsfähig.

Wenn der Vorgang eine Weile dauert und Ihr Responsible AI-Dashboard immer noch nicht mit der Compute-Instanz verbunden ist oder eine rote Fehlermeldungsleiste angezeigt wird, bedeutet dies, dass es Probleme beim Starten Ihres Responsible AI-Endpunkts gibt. Wählen Sie Terminalausgabe anzeigen aus und scrollen Sie nach unten, um die Fehlermeldung anzuzeigen.

Wenn Sie Schwierigkeiten haben, herauszufinden, wie Sie das Problem „Verbindung zur Compute-Instanz konnte nicht hergestellt werden“ lösen, wählen Sie oben rechts das Lächeln-Symbol aus. Senden Sie uns Feedback zu Fehlern oder Problemen, auf die Sie stoßen. Sie können einen Screenshot und Ihre E-Mail-Adresse in das Feedback-Formular einfügen.




Übersicht über die Benutzeroberfläche des Dashboards für verantwortungsbewusste KI
Das Responsible AI-Dashboard enthält einen robusten, reichhaltigen Satz an Visualisierungen und Funktionen, mit denen Sie Ihr maschinelles Lernmodell analysieren oder datengesteuerte Geschäftsentscheidungen treffen können:
- Globale Steuerelemente
- Fehleranalyse
- Modellübersicht und Fairnessmetriken
- Datenanalyse
- Funktionswichtigkeit(Modellerklärungen)
- Kontrafaktische Was-wäre-wenn-Annahme
- Ursachenanalyse
Globale Steuerelemente
Oben im Dashboard können Sie Kohorten (Untergruppen von Datenpunkten, die bestimmte Merkmale gemeinsam haben) erstellen, um Ihre Analyse jeder Komponente zu fokussieren. Der Name der aktuell auf das Dashboard angewendeten Kohorte wird immer oben links auf Ihrem Dashboard angezeigt. Die Standardansicht in Ihrem Dashboard ist Ihr gesamter Datensatz mit dem Titel Alle Daten (Standard).

- Kohorteneinstellungen: Ermöglicht es Ihnen, die Details jeder Kohorte in einem Seitenbereich anzuzeigen und zu ändern.
- Dashboardkonfiguration: Ermöglicht es Ihnen, das Layout des gesamten Dashboards in einem Seitenbereich anzuzeigen und zu ändern.
- Kohorte wechseln: Ermöglicht es Ihnen, eine andere Kohorte auszuwählen und ihre Statistiken in einem Popup-Fenster anzuzeigen.
- Neue Kohorte: Ermöglicht Ihnen das Erstellen und Hinzufügen einer neuen Kohorte zu Ihrem Dashboard.
Wählen Sie Kohorteneinstellungen aus, um ein Fenster mit einer Liste Ihrer Kohorten zu öffnen, in der Sie sie erstellen, bearbeiten, duplizieren oder löschen können.

Wählen Sie oben im Dashboard oder in den Kohorteneinstellungen Neue Kohorte aus, um einen neuen Bereich mit Optionen zum Filtern nach Folgendem zu öffnen:
- Index: Filtert nach der Position des Datenpunkts im vollständigen Datensatz.
- Dataset: Filtert nach dem Wert eines bestimmten Features im Dataset.
- Vorhergesagtes Y: Filtert nach der Vorhersage des Modells.
- Tatsächliches Y: Filtert nach dem tatsächlichen Wert des Ziel-Features.
- Fehler (Regression): Filtert nach Fehler (oder Klassifizierungsergebnis (Klassifizierung): Filtert nach Typ und Genauigkeit der Klassifizierung).
- Kategorische Werte: Filtern Sie nach einer Liste von Werten, die enthalten sein sollten.
- Numerische Werte: Filtern Sie anhand einer booleschen Operation über die Werte (wählen Sie beispielsweise Datenpunkte mit einem Alter von < 64 Jahren aus).

Sie können Ihre neue Datensatzkohorte benennen, Filter hinzufügen auswählen, um jeden Filter hinzuzufügen, den Sie verwenden möchten, und dann einen der folgenden Schritte ausführen:
- Wählen Sie Speichern aus, um die neue Kohorte in Ihrer Kohortenliste zu speichern.
- Wählen Sie Speichern und wechseln aus, um zu speichern und die globale Kohorte des Dashboards sofort auf die neu erstellte Kohorte umzuschalten.

Wählen Sie Dashboard-Konfiguration aus, um ein Fenster mit einer Liste der Komponenten zu öffnen, die Sie auf Ihrem Dashboard konfiguriert haben. Sie können Komponenten auf Ihrem Dashboard ausblenden, indem Sie das Symbol Papierkorb auswählen, wie in der folgenden Abbildung gezeigt:

Sie können Komponenten wieder zu Ihrem Dashboard hinzufügen, indem Sie das blaue runde Pluszeichen (+) in der Trennlinie zwischen den einzelnen Komponenten verwenden, wie in der folgenden Abbildung gezeigt:

Fehleranalyse
In den nächsten Abschnitten wird beschrieben, wie Fehlerbaumkarten und Heatmaps interpretiert und verwendet werden.
Fehlerstrukturzuordnung
Der erste Bereich der Fehleranalysekomponente ist eine Baumkarte, die veranschaulicht, wie Modellfehler über verschiedene Kohorten mit einer Baumvisualisierung verteilt sind. Wählen Sie einen beliebigen Knoten aus, um den Vorhersagepfad für Ihre Features anzuzeigen, wo ein Fehler gefunden wurde.

- Heatmap-Ansicht: Wechselt zur Heatmap-Visualisierung der Fehlerverteilung.
- Funktionsliste: Ermöglicht es Ihnen, die in der Heatmap verwendeten Funktionen mithilfe eines Seitenbereichs zu ändern.
- Fehlerabdeckung: Zeigt den Prozentsatz aller Fehler im Datensatz an, die sich auf den ausgewählten Knoten konzentrieren.
- Fehler (Regression) oder Fehlerrate (Klassifizierung): Zeigt den Fehler oder Prozentsatz der Ausfälle aller Datenpunkte im ausgewählten Knoten an.
- Knoten: Stellt eine Kohorte des Datensatzes dar, möglicherweise mit angewendeten Filtern, und die Anzahl der Fehler aus der Gesamtzahl der Datenpunkte in der Kohorte.
- Fülllinie: Visualisiert die Verteilung von Datenpunkten in untergeordneten Kohorten basierend auf Filtern, wobei die Anzahl der Datenpunkte durch die Linienstärke dargestellt wird.
- Auswahlinformationen: Enthält Informationen über den ausgewählten Knoten in einem Seitenbereich.
- Speichern als neue Kohorte: Erstellt eine neue Kohorte mit den angegebenen Filtern.
- Instanzen in der Basiskohorte: Zeigt die Gesamtzahl der Punkte im gesamten Datensatz und die Anzahl der richtig und falsch vorhergesagten Punkte an.
- Instanzen in der ausgewählten Kohorte: Zeigt die Gesamtzahl der Punkte im ausgewählten Knoten und die Anzahl der richtig und falsch vorhergesagten Punkte an.
- Vorhersagepfad (Filter): Listet die Filter auf, die über dem gesamten Dataset platziert wurden, um diese kleinere Kohorte zu erstellen.
Wählen Sie die Schaltfläche Funktionsliste aus, um einen Seitenbereich zu öffnen, in dem Sie den Fehlerbaum für bestimmte Funktionen neu trainieren können.

- Funktionen suchen: Ermöglicht es Ihnen, bestimmte Features im Datensatz zu finden.
- Funktionen: Listet den Namen des Features im Dataset auf.
- Relevanzen: Eine Richtlinie dafür, in welchem Zusammenhang die Funktion mit dem Fehler stehen könnte. Berechnet über die gegenseitige Informationsbewertung zwischen dem Feature und dem Fehler bei den Bezeichnungen. Anhand dieser Punktzahl können Sie entscheiden, welche Funktionen Sie in der Fehleranalyse auswählen sollten.
- Häkchen: Ermöglicht das Hinzufügen oder Entfernen der Funktion aus der Baumkarte.
- Maximale Tiefe: Die maximale Tiefe der auf Fehler trainierten Ersatzstruktur.
- Anzahl der Blätter: Die Anzahl der Blätter der auf Fehler trainierten Ersatzstruktur.
- Mindestanzahl von Proben in einem Blatt: Die Mindestdatenmenge, die zum Erstellen eines Blatts erforderlich ist.
Fehlerwärmebild
Wählen Sie die Registerkarte Heatmap aus, um zu einer anderen Ansicht des Fehlers im Datensatz zu wechseln. Sie können eine oder mehrere Heatmap-Zellen auswählen und neue Kohorten erstellen. Sie können bis zu zwei Features auswählen, um eine Heatmap zu erstellen.

- Zellen: Zeigt die Anzahl der ausgewählten Zellen an.
- Fehlerabdeckung: Zeigt den Prozentsatz aller Fehler an, die sich auf die ausgewählte(n) Zelle(n) konzentrieren.
- Fehlerrate: Zeigt den Prozentsatz der Fehler aller Datenpunkte in der/den ausgewählten Zelle(n) an.
- Achsenfunktionen: Wählt den Schnittpunkt von Features aus, die in der Heatmap angezeigt werden sollen.
- Zellen: Stellt eine Kohorte des Datensatzes mit angewendeten Filtern und den Prozentsatz der Fehler bezogen auf die Gesamtzahl der Datenpunkte in der Kohorte dar. Eine blaue Umrandung kennzeichnet ausgewählte Zellen, und je dunkler der Rotton, desto höher ist die Konzentration von Fehlern.
- Vorhersagepfad (Filter): Listet die Filter auf, die für jede ausgewählte Kohorte über dem vollständigen Datensatz platziert wurden.
Modellübersicht und Fairnessmetriken
Die Modellübersichtskomponente bietet einen umfassenden Satz von Leistungs- und Fairnessmetriken zur Bewertung Ihres Modells sowie wichtige Leistungsunterschiedsmetriken entlang bestimmter Features und Datensatzkohorten.
Datensatzkohorten
Auf der Registerkarte Datensatzkohorten können Sie Ihr Modell untersuchen, indem Sie die Modellleistung verschiedener benutzerdefinierter Datensatzkohorten vergleichen (aufrufbar über das Kohorteneinstellungen-Symbol oben rechts im Dashboard.

- Hilfe bei der Auswahl von Metriken: Wählen Sie dieses Symbol aus, um einen Bereich mit weiteren Informationen darüber zu öffnen, welche Modellleistungsmetriken zur Anzeige in der Tabelle verfügbar sind. Passen Sie einfach an, welche Metriken angezeigt werden sollen, indem Sie die Dropdown-Liste mit Mehrfachauswahl verwenden, um Leistungsmetriken auszuwählen und abzuwählen.
- Heatmap anzeigen: Ein- und ausschalten, um die Heatmap-Visualisierung in der Tabelle ein- oder auszublenden. Der Gradient der Heatmap entspricht dem normierten Bereich zwischen dem niedrigsten Wert und dem höchsten Wert in jeder Spalte.
- Metriktabelle für jede Datensatzkohorte: Zeigen Sie Spalten von Datensatzkohorten, die Stichprobengröße jeder Kohorte und die ausgewählten Modellleistungsmetriken für jede Kohorte an.
- Balkendiagramm zur Visualisierung einzelner Messwerte: Zeigen Sie den mittleren absoluten Fehler über die Kohorten für einen einfachen Vergleich an.
- Wählen Sie die Metrik (x-Achse): Wählen Sie diese Schaltfläche aus, um auszuwählen, welche Metriken im Balkendiagramm angezeigt werden sollen.
- Wählen Sie die Kohorten (y-Achse): Wählen Sie diese Schaltfläche aus, um auszuwählen, welche Kohorten im Balkendiagramm angezeigt werden sollen. Die Auswahl der Funktionskohorte ist möglicherweise deaktiviert, es sei denn, Sie geben zuerst die gewünschten Merkmale auf der Registerkarte Funktionskohorte der Komponente an.
Wählen Sie Hilfe bei der Auswahl von Metriken aus, um einen Bereich mit einer Liste von Modellleistungsmetriken und ihren Definitionen zu öffnen, die Ihnen bei der Auswahl der richtigen anzuzeigenden Metriken helfen können.
| Szenario für maschinelles Lernen | Metriken |
|---|---|
| Regression | Mittlerer absoluter Fehler, mittlerer quadratischer Fehler, R-Quadrat, mittlere Vorhersage. |
| Klassifizierung | Genauigkeit, Präzision, Abruf, F1-Punktzahl, Falsch-Positiv-Rate, Falsch-Negativ-Rate, Auswahlrate. |
Feature-Kohorten
Im Bereich Funktionskohorten können Sie Ihr Modell untersuchen, indem Sie die Modellleistung über vom Benutzer angegebene sensible und nicht sensible Merkmale hinweg vergleichen (z.

Hilfe bei der Auswahl von Metriken: Wählen Sie dieses Symbol aus, um einen Bereich mit weiteren Informationen darüber zu öffnen, welche Metriken in der Tabelle angezeigt werden können. Passen Sie einfach an, welche Metriken angezeigt werden sollen, indem Sie die Dropdown-Liste mit Mehrfachauswahl verwenden, um Leistungsmetriken auszuwählen und abzuwählen.
Hilfe bei der Auswahl von Funktionen: Wählen Sie dieses Symbol aus, um ein Fenster mit weiteren Informationen darüber zu öffnen, welche Funktionen zur Anzeige in der Tabelle verfügbar sind, mit Beschreibungen für jede Funktion und ihre Klassierungsfähigkeit (siehe unten). Passen Sie einfach an, welche Funktionen angezeigt werden sollen, indem Sie sie über das Dropdown-Menü mit Mehrfachauswahl auswählen und abwählen.

Heatmap anzeigen: Ein- und ausschalten, um eine Heatmap-Visualisierung anzuzeigen. Der Gradient der Heatmap entspricht dem normalisierten Bereich zwischen dem niedrigsten Wert und dem höchsten Wert in jeder Spalte.
Tabelle mit Metriken für jede Funktionskohorte: Eine Tabelle mit Spalten für Funktionskohorten (Unterkohorte Ihres ausgewählten Merkmals), Stichprobenumfang jeder Kohorte und die ausgewählten Modellleistungsmetriken für jede Funktionskohorte.
Fairness-Metriken/Disparitätsmetriken: Eine Tabelle, die der Metriktabelle entspricht und die maximale Differenz oder das maximale Verhältnis der Leistungswerte zwischen zwei beliebigen Funktionskohorten anzeigt.
Balkendiagramm zur Visualisierung einzelner Messwerte: Zeigen Sie den mittleren absoluten Fehler über die Kohorten für einen einfachen Vergleich an.
Wählen Sie die Kohorten (y-Achse): Wählen Sie diese Schaltfläche aus, um auszuwählen, welche Kohorten im Balkendiagramm angezeigt werden sollen.
Wenn Sie Kohorten auswählen auswählen, wird ein Bereich mit der Option geöffnet, entweder einen Vergleich ausgewählter Datensatzkohorten oder Funktionskohorten anzuzeigen, je nachdem, was Sie in der Dropdown-Liste mit Mehrfachauswahl darunter auswählen. Wählen Sie Bestätigen, um die Änderungen an der Balkendiagrammansicht zu speichern.

Wählen Sie die Metrik (x-Achse): Wählen Sie diese Schaltfläche aus, um auszuwählen, welche Metrik im Balkendiagramm angezeigt werden soll.


Datenanalyse
Mit der Datenanalysekomponente wird im Bereich Tabellenansicht eine Tabellenansicht Ihres Datasets für alle Features und Zeilen angezeigt.
Im Bereich Diagrammansicht werden aggregierte und einzelne Plots von Datenpunkten angezeigt. Sie können Datenstatistiken entlang der X- und Y-Achse analysieren, indem Sie Filter wie vorhergesagtes Ergebnis, Dataset-Features und Fehlergruppen verwenden. Diese Ansicht hilft Ihnen, die Überrepräsentation und Unterrepräsentation in Ihrem Dataset zu verstehen.

Dataset-Kohorte für Untersuchung auswählen: Geben Sie an, für welche Datenkohorte aus Ihrer Liste von Kohorten Sie Datenstatistiken anzeigen möchten.
X-Achse: Zeigt den Typ des horizontal gezeichneten Werts an. Ändern Sie die Werte, indem Sie die Schaltfläche zum Öffnen eines Seitenbereichs auswählen.
Y-Achse: Zeigt den Werttyp an, der vertikal dargestellt wird. Ändern Sie die Werte, indem Sie die Schaltfläche zum Öffnen eines Seitenbereichs auswählen.
Diagrammtyp: Gibt den Diagrammtyp an. Wählen Sie zwischen aggregierten Diagrammen (Balkendiagramme) oder einzelnen Datenpunkten (Streudiagramm).
Durch Auswahl der Option Einzelne Datenpunkte unter Diagrammtyp können Sie zu einer disaggregierten Ansicht der Daten mit der Verfügbarkeit einer Farbachse wechseln.

Featurerelevanz (Modellerklärungen)
Mithilfe der Modellerklärungskomponente können Sie sehen, welche Features in den Vorhersagen Ihres Modells am wichtigsten waren. Sie können im Bereich Aggregierte Funktionswichtigkeit anzeigen, welche Features die Vorhersage Ihres Modells insgesamt beeinflusst haben, oder im Bereich Individuelle Featurerelevanz die Featurerelevanz für einzelne Datenpunkte anzeigen.
Aggregierte Featurerelevanzen (globale Erklärungen)

Top-k-Features: Listet die wichtigsten globalen Merkmale für eine Vorhersage auf und ermöglicht es Ihnen, sie mithilfe eines Schiebereglers zu ändern.
Aggregierte Funktionswichtigkeit: Visualisiert das Gewicht jedes Features bei der Beeinflussung von Modellentscheidungen über alle Vorhersagen hinweg.
Sortieren nach: Ermöglicht es Ihnen, die Wichtigkeiten der Kohorte auszuwählen, nach der das Diagramm der aggregierten Funktionswichtigkeit sortiert werden soll.
Diagrammtyp: Ermöglicht die Auswahl zwischen einer Balkendiagrammansicht der durchschnittlichen Wichtigkeiten für jede Funktion und einem Boxdiagramm der Wichtigkeiten für alle Daten.
Wenn Sie eines der Funktionen im Balkendiagramm auswählen, wird das Abhängigkeitsdiagramm ausgefüllt, wie in der folgenden Abbildung gezeigt. Das Abhängigkeitsdiagramm zeigt die Beziehung der Werte einer Funktion zu den entsprechenden Funktionswichtigkeitswerten, die sich auf die Modellvorhersage auswirken.

Funktionswichtigkeit von [Funktion ] (Regression) oder Funktionswichtigkeit von [Funktion ] auf [vorhergesagte Klasse] (Klassifizierung): Zeichnet die Wichtigkeit einer bestimmten Funktion über die Vorhersagen hinweg auf. Bei Regressionsszenarien beziehen sich die Wichtigkeitswerte auf die Ausgabe, sodass eine positive Funktionswichtigkeit bedeutet, dass sie positiv zur Ausgabe beigetragen hat. Bei negativer Funktionsbedeutung gilt das Gegenteil. Bei Klassifizierungsszenarien bedeuten positive Funktionsbedeutungen, dass der Merkmalswert zu der vorhergesagten Klasse beiträgt, die im Titel der y-Achse angegeben ist. Eine negative Wichtigkeit der Funktion bedeutet, dass sie gegen die vorhergesagte Klasse beiträgt.
Abhängigkeitsplot anzeigen für : Wählt die Funktion aus, deren Wichtigkeiten Sie darstellen möchten.
Dataset-Kohorte auswählen: Wählt die Kohorte aus, deren Wichtigkeiten Sie darstellen möchten.

Relevanzen einzelner Features (lokale Erklärungen)
Die folgende Abbildung veranschaulicht, wie Features die Vorhersagen beeinflussen, die für bestimmte Datenpunkte gemacht werden. Sie können bis zu fünf Datenpunkte auswählen, um deren Wichtigkeit zu vergleichen.

Punktauswahltabelle: Zeigen Sie Ihre Datenpunkte an und wählen Sie bis zu fünf Punkte aus, die im Funktionswichtigkeitsdiagramm oder im ICE-Diagramm unterhalb der Tabelle angezeigt werden sollen.

Funktionswichtigkeitsdiagramm: Ein Balkendiagramm der Wichtigkeit jedes Merkmals für die Vorhersage des Modells für die ausgewählten Datenpunkte.
- Top-k-Funktionen: Ermöglicht es Ihnen, mithilfe eines Schiebereglers die Anzahl der Funktionen anzugeben, für die die Wichtigkeit angezeigt werden soll.
- Sortieren nach: Ermöglicht Ihnen die Auswahl des Punktes (der oben markierten), dessen Funktionswichtigkeiten in absteigender Reihenfolge auf dem Funktionswichtigkeitsdiagramm angezeigt werden.
- Absolute Werte anzeigen: Aktivieren Sie diese Option, um das Balkendiagramm nach den absoluten Werten zu sortieren. Auf diese Weise können Sie die wirkungsvollsten Funktionen unabhängig von ihrer positiven oder negativen Richtung sehen.
- Balkendiagramm: Zeigt die Wichtigkeit jeder Funktion im Dataset für die Modellvorhersage der ausgewählten Datenpunkte an.
Diagramm der individuellen bedingten Erwartung (ICE): Wechselt zum ICE-Diagramm, das Modellvorhersagen über einen Bereich von Werten einer bestimmten Funktion zeigt.

- Min (numerische Funktionen): Gibt die untere Grenze des Bereichs der Vorhersagen im ICE-Plot an.
- Max (numerische Funktionen): Gibt die obere Grenze des Bereichs der Vorhersagen im ICE-Plot an.
- Schnitte (numerische Funktionen): Gibt die Anzahl der Punkte an, für die innerhalb des Intervalls Vorhersagen angezeigt werden sollen.
- Funktionswerte (kategorische Funktionen): Gibt an, für welche kategorischen Funktionswerte Vorhersagen angezeigt werden sollen.
- Funktion: Gibt die Funktion an, für das Vorhersagen gemacht werden sollen.
Kontrafaktische Was-wäre-wenn-Annahme
Die kontrafaktische Analyse bietet eine Vielzahl von Was-wäre-wenn-Beispielen, die durch minimale Änderung der Werte von Merkmalen generiert werden, um die gewünschte Vorhersageklasse (Klassifizierung) oder den gewünschten Bereich (Regression) zu erzeugen.

Punktauswahl: Wählt den Punkt aus, für den ein kontrafaktisches Ergebnis erstellt und im Diagramm der obersten Funktionen darunter angezeigt werden soll.
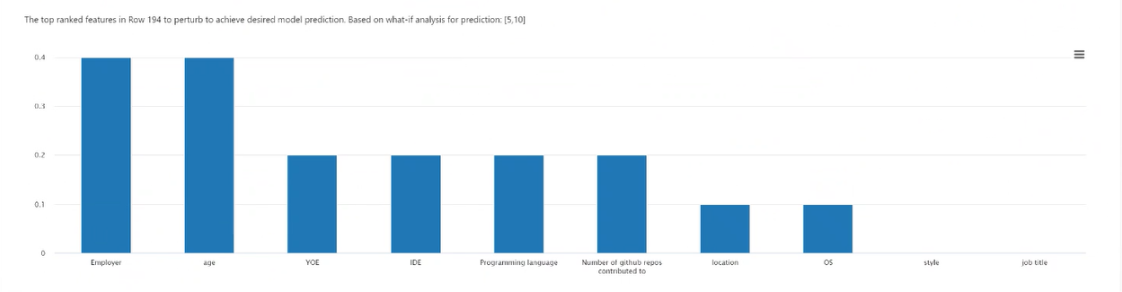
Plot der ranghöchsten Funktionen: Zeigt in absteigender Reihenfolge der durchschnittlichen Häufigkeit die zu störenden Funktionen an, um einen vielfältigen Satz von Kontrafaktualen der gewünschten Klasse zu erstellen. Sie müssen mindestens 10 verschiedene Kontrafaktuale pro Datenpunkt generieren, um dieses Diagramm zu aktivieren, da es bei einer geringeren Anzahl von Kontrafaktualen an Genauigkeit mangelt.
Ausgewählter Datenpunkt: Führt die gleiche Aktion wie die Punktauswahl in der Tabelle aus, außer in einem Dropdown-Menü.
Gewünschte Klasse für Kontrafaktuale: Gibt die Klasse oder den Bereich an, für die Kontrafaktuale generiert werden sollen.
Was-wäre-wenn-Kontrafaktual erstellen: Öffnet ein Fenster für die kontrafaktische Erstellung von Was-wäre-wenn-Datenpunkten.
Wählen Sie die Schaltfläche Was-wäre-wenn-Kontrafaktual erstellen aus, um ein vollständiges Fensterfeld zu öffnen.

Funktionen suchen: Findet Funktionen zum Beobachten und Ändern von Werten.
Kontrafaktisches nach Rangfolgefunktionen sortieren: Sortiert kontrafaktische Beispiele in der Reihenfolge des Störungseffekts. (Siehe auch Diagramm der Funktionen mit dem höchsten Rang, weiter oben besprochen.)
Kontrafaktische Beispiele: Listet Funktionswerte von Beispielkontrafaktualen mit der gewünschten Klasse oder dem gewünschten Bereich auf. Die erste Zeile ist der ursprüngliche Referenzdatenpunkt. Wählen Sie Wert setzen, um alle Werte Ihres eigenen kontrafaktischen Datenpunkts in der unteren Zeile mit den Werten des vorgenerierten kontrafaktischen Beispiels zu setzen.
Vorgesagter Wert oder Klasse: Listet die Modellvorhersage einer kontrafaktischen Klasse unter Berücksichtigung dieser geänderten Funktionen auf.
Erstellen Sie ihre eigenes Kontrafaktum: Ermöglicht es Ihnen, Ihre eigenen Funktionen zu stören, um das Kontrafaktual zu ändern. Die Funktionen, die gegenüber dem ursprünglichen Funktionswert geändert wurden, sind durch einen fett gedruckten Titel gekennzeichnet (z. B. Arbeitgeber und Programmiersprache). Wählen Sie Vorhersage-Delta anzeigen aus, um die Differenz zwischen dem neuen Vorhersagewert und dem ursprünglichen Datenpunkt anzuzeigen.
Was-wäre-wenn-Kontrafaktualname: Ermöglicht Ihnen, das Kontrafaktual eindeutig zu benennen.
Als neuen Datenpunkt speichern: Speichert die von Ihnen erstellte Gegendarstellung.


Ursachenanalyse
In den nächsten Abschnitten wird erläutert, wie Sie die Ursachenanalyse für Ihr Dataset bei ausgewählten benutzerdefinierten Behandlungen lesen.
Aggregierte kausale Auswirkungen
Wählen Sie die Registerkarte Aggregierte kausale Effekte der Kausalanalysekomponente aus, um die durchschnittlichen kausalen Effekte für vordefinierte Behandlungsmerkmale anzuzeigen (die Merkmale, die Sie behandeln möchten, um Ihr Ergebnis zu optimieren).
Hinweis
Die globale Kohortenfunktionalität wird von der Komponente „Ursachenanalyse“ nicht unterstützt.

Direkt aggregierte Kausaleffekttabelle: Zeigt den kausalen Effekt jedes Merkmals aggregiert auf das gesamte Dataset und die zugehörigen Konfidenzstatistiken an.
- Kontinuierliche Behandlungen: Die Erhöhung dieses Features um eine Einheit führt im Durchschnitt bei dieser Stichprobe dazu, dass die Wahrscheinlichkeit der Klasse um X Einheiten steigt, wobei X die kausale Auswirkung ist.
- Binäre Behandlungen: Das Aktivieren dieses Features führt im Durchschnitt bei dieser Stichprobe dazu, dass die Wahrscheinlichkeit der Klasse um X Einheiten steigt, wobei X die kausale Auswirkung ist.
Whisker-Diagramm für direkte aggregierte kausale Effekte: Visualisiert die kausalen Effekte und Konfidenzintervalle der Punkte in der Tabelle.
Individuelle kausale Auswirkungen und kausale Was-wäre-wenn-Annahmen
Um eine detaillierte Ansicht der kausalen Auswirkungen auf einen einzelnen Datenpunkt zu erhalten, wechseln Sie zur Registerkarte Individueller kausaler Was-wäre-wenn.

- X-Achse: Wählt die Funktion aus, die auf der x-Achse dargestellt werden soll.
- Y-Achse: Wählt die Funktion aus, die auf der y-Achse dargestellt werden soll.
- Individuelles kausales Streudiagramm: Visualisiert Punkte in der Tabelle als Streudiagramm, um Datenpunkte für die Analyse des kausalen Was-wäre-wenn auszuwählen und die einzelnen kausalen Auswirkungen darunter anzuzeigen.
- Neuen Behandlungswert festlegen:
- (Numerisch): Zeigt einen Schieberegler an, um den Wert der numerischen Funktion als realen Eingriff zu ändern.
- (Kategorisch): Zeigt eine Dropdown-Liste zur Auswahl des Werts der kategorialen Funktion an.
Behandlungsrichtlinie
Wählen Sie die Registerkarte Behandlungsrichtlinie aus, um zu einer Ansicht zu wechseln, die bei der Bestimmung realer Interventionen hilft und Behandlungen anzeigt, die angewendet werden müssen, um ein bestimmtes Ergebnis zu erzielen.

Behandlungsfeature festlegen: Wählt eine Funktion aus, die als realer Eingriff geändert werden soll.
Empfohlene globale Behandlungsrichtlinie: Zeigt empfohlene Eingriffe für Datenkohorten an, um den Zielfunktionswert zu verbessern. Die Tabelle kann von links nach rechts gelesen werden, wobei die Segmentierung des Datasets zuerst in Zeilen und dann in Spalten erfolgt. Beispielsweise besteht die empfohlene Behandlungsrichtlinie für 658 Personen, deren Arbeitgeber nicht Snapchat und deren Programmiersprache nicht JavaScript ist, darin, die Anzahl der GitHub-Repository zu erhöhen, zu denen beigetragen wird.
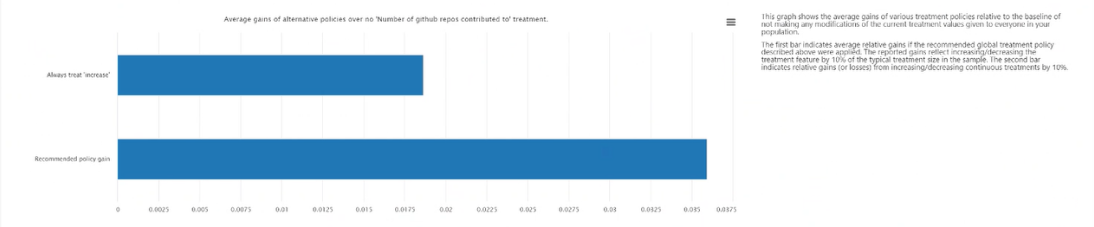
Durchschnittliche Gewinne alternativer Richtlinien bei ständiger Anwendung der Behandlung: Stellt den Zielfunktionswert in einem Balkendiagramm des durchschnittlichen Gewinns Ihres Ergebnisses für die oben empfohlene Behandlungsrichtlinie im Vergleich zur ständigen Anwendung der Behandlung dar.
Empfohlene individuelle Behandlungsrichtlinie:

Top-k-Datenpunktbeispiele anzeigen, sortiert nach kausalen Wirkungen für empfohlene Behandlungsfunktion: Wählt die Anzahl der Datenpunkte aus, die in der Tabelle angezeigt werden sollen.
Tabelle der empfohlenen individuellen Behandlungsrichtlinien: Listet in absteigender Reihenfolge der kausalen Wirkung die Datenpunkte auf, deren Zielfunktionen durch eine Intervention am stärksten verbessert würden.


Nächste Schritte
- Fassen Sie Ihre Erkenntnisse zu verantwortungsvoller KI zusammen, und teilen Sie sie über die Scorecard für verantwortungsbewusste KI als PDF-Export.
- Erfahren Sie mehr über die Konzepte und Methoden hinter dem Dashboard für verantwortungsbewusste KI.
- Zeigen Sie YAML- und Python-Beispiel-Notebooks an, um ein Dashboard für verantwortungsbewusste KI mit YAML oder Python zu generieren.
- Erkunden Sie die Funktionen des Responsible AI-Dashboards in dieser interaktiven AI Lab-Webdemo.
- Erfahren Sie mehr darüber, wie Sie das Responsible AI-Dashboard und die Scorecard verwenden können, um Daten und Modelle zu debuggen und eine bessere Entscheidungsfindung in diesem Tech-Community-Blogbeitrag zu ermöglichen.
- Erfahren Sie in einer realen Kundengeschichte, wie das Responsible AI-Dashboard und die Scorecard vom britischen National Health Service (NHS) verwendet wurden.