Tutorial: Modellentwicklung auf einer Cloudarbeitsstation
Erfahren Sie, wie Sie ein Trainingsskript mit einem Notebook auf einer Azure Machine Learning-Cloudarbeitsstation entwickeln. In diesem Tutorial werden die Grundlagen behandelt, die Sie für die ersten Schritte benötigen:
- Richten Sie die Cloudarbeitsstation ein und konfigurieren Sie sie. Ihre Cloudarbeitsstation basiert auf einer Azure Machine Learning-Compute-Instanz, die mit Umgebungen vorkonfiguriert ist, um Ihre verschiedenen Modellentwicklungsanforderungen zu unterstützen.
- Verwenden Sie cloudbasierte Entwicklungsumgebungen.
- Verwenden Sie MLflow, um Ihre Modellmetriken in einem Notebook nachzuverfolgen.
Voraussetzungen
Um Azure Machine Learning verwenden zu können, benötigen Sie zuerst einen Arbeitsbereich. Wenn Sie noch keinen haben, schließen Sie Erstellen von Ressourcen, die Sie für die ersten Schritte benötigen ab, um einen Arbeitsbereich zu erstellen, und mehr über dessen Verwendung zu erfahren.
Beginnen mit Compute
Im Abschnitt Compute in Ihrem Arbeitsbereich können Sie Computeressourcen erstellen. Eine Compute-Instanz ist eine vollständig von Azure Machine Learning verwaltete cloudbasierte Arbeitsstation. In dieser Tutorialreihe wird eine Compute-Instanz verwendet. Sie können sie auch verwenden, um Ihren eigenen Code auszuführen und Modelle zu entwickeln und zu testen.
- Melden Sie sich bei Azure Machine Learning Studio an.
- Wählen Sie Ihren Arbeitsbereich aus, wenn er noch nicht geöffnet ist.
- Wählen Sie im linken Navigationsbereich Compute aus.
- Wenn Sie keine Compute-Instanz haben, wird in der Mitte des Bildschirms Neu angezeigt. Wählen Sie Neu aus, und füllen Sie das Formular aus. Sie können alle Standardwerte verwenden.
- Wenn Sie über eine Compute-Instanz verfügen, wählen Sie sie in der Liste aus. Falls sie beendet wurde, wählen Sie Starten aus.
Öffnen von Visual Studio Code (VS Code)
Sobald Sie über eine ausgeführte Compute-Instanz verfügen, haben Sie verschiedene Möglichkeiten, auf sie zuzugreifen. In diesem Tutorial wird die Verwendung der Compute-Instanz über VS Code gezeigt. VS Code bietet eine vollständige integrierte Entwicklungsumgebung (Integrated Development Environment, IDE) mit der Leistungsfähigkeit von Azure Machine Learning-Ressourcen.
Wählen Sie in der Liste der Compute-Instanzen den Link VS Code (Web) oder VS Code (Desktop) für die Compute-Instanz aus, die Sie verwenden möchten. Wenn Sie VS Code (Desktop) auswählen, wird möglicherweise ein Popup angezeigt, in dem Sie gefragt werden, ob Sie die Anwendung öffnen möchten.

Diese VS Code-Instanz ist an Ihre Compute-Instanz und Ihr Arbeitsbereichsdateisystem angefügt. Selbst wenn Sie sie auf Ihrem Desktop öffnen, sind die angezeigten Dateien Dateien in Ihrem Arbeitsbereich.
Einrichten einer neuen Umgebung für die Prototyperstellung (optional)
Damit Ihr Skript ausgeführt werden kann, müssen Sie in einer Umgebung arbeiten, die mit den vom Code erwarteten Abhängigkeiten und Bibliotheken konfiguriert ist. In diesem Abschnitt können Sie eine Umgebung erstellen, die auf Ihren Code zugeschnitten ist. Um den neuen Jupyter-Kernel zu erstellen, mit dem Ihr Notebook eine Verbindung herstellt, verwenden Sie eine YAML-Datei, die die Abhängigkeiten definiert.
Laden Sie eine Datei hoch.
Dateien, die Sie hochladen, werden in einer Azure-Dateifreigabe gespeichert, und diese Dateien werden in jede Compute-Instanz eingebunden und innerhalb des Arbeitsbereichs freigegeben.
Laden Sie diese Conda-Umgebungsdatei workstation_env.yml auf Ihren Computer herunter, indem Sie die Schaltfläche Rohdatei herunterladen oben rechts verwenden.
Ziehen Sie die Datei von Ihrem Computer in das VS Code-Fenster. Die Datei wird in Ihren Arbeitsbereich hochgeladen.
Verschieben Sie die Datei in den Ordner mit Ihrem Benutzernamen.
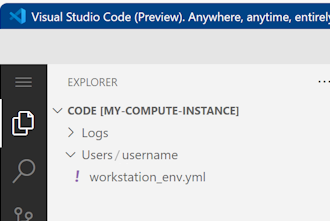
Wählen Sie diese Datei aus, um eine Vorschau anzuzeigen und zu sehen, welche Abhängigkeiten sie angibt. Sie werden Inhalte wie diese sehen:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibErstellen Sie einen Kernel.
Verwenden Sie nun das Terminal, um einen neuen Jupyter-Kernel basierend auf der Datei workstation_env.yml zu erstellen.
Wählen Sie auf der oberen Menüleiste Terminal > Neues Terminal aus.
Zeigen Sie Ihre aktuellen Conda-Umgebungen an. Die aktive Umgebung ist mit einem * gekennzeichnet.
conda env listFühren Sie
cdfür den Ordner aus, in den Sie die Datei workstation_env.yml hochgeladen haben. Wenn Sie sie beispielsweise in Ihren Benutzerordner hochgeladen haben, verwenden Sie den folgenden Befehl:cd Users/myusernameStellen Sie sicher, dass sich die Datei „workstation_env.yml“ in diesem Ordner befindet.
lsErstellen Sie die Umgebung basierend auf der bereitgestellten Conda-Datei. Die Erstellung dieser Umgebung dauert einige Minuten.
conda env create -f workstation_env.ymlAktivieren Sie die neue Umgebung.
conda activate workstation_envHinweis
Wenn „CommandNotFoundError“ angezeigt wird, befolgen Sie die Anweisungen zum Ausführen von
conda init bash, schließen Sie das Terminal, und öffnen Sie ein neues. Führen Sie dann den Befehlconda activate workstation_enverneut aus.Überprüfen Sie, ob die richtige Umgebung (mit * gekennzeichnet) aktiv ist.
conda env listErstellen Sie einen neuen Jupyter-Kernel basierend auf Ihrer aktiven Umgebung.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Schließen Sie das Terminalfenster.
Sie verfügen jetzt über einen neuen Kernel. Als Nächstes öffnen Sie ein Notebook und verwenden diesen Kernel.
Erstellen eines Notebooks
- Wählen Sie auf der oberen Menüleiste Datei > Neue Datei aus.
- Nennen Sie Ihre neue Datei develop-tutorial.ipynb (oder geben Sie Ihren bevorzugten Namen ein). Verwenden Sie unbedingt die Erweiterung ipynb.
Festlegen des Kernels
- Wählen Sie in der rechten oberen Ecke Kernel auswählen aus.
- Wählen Sie Azure ML-Compute-Instanz (Name der Compute-Instanz) aus.
- Wählen Sie den von Ihnen erstellten Kernel Tutorial Workstation Env aus. Wird er nicht angezeigt, wählen Sie oben rechts das Tool Aktualisieren aus.
Entwickeln eines Trainingsskripts
In diesem Abschnitt entwickeln Sie ein Python-Trainingsskript, das Zahlungsverzug bei Kreditkartenzahlungen vorhersagt, indem Sie die vorbereiteten Test- und Trainingsdatasets aus dem UCI-Dataset verwenden.
Dieser Code verwendet sklearn für das Training und MLflow zum Protokollieren der Metriken.
Beginnen Sie mit Code, der die Pakete und Bibliotheken importiert, die Sie im Trainingsskript verwenden.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitLaden und verarbeiten Sie als Nächstes die Daten für dieses Experiment. In diesem Tutorial lesen Sie die Daten aus einer Datei im Internet.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Bereiten Sie die Daten für das Training vor:
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesFügen Sie Code hinzu, um die automatische Protokollierung mit
MLflowzu starten, damit Sie die Metriken und Ergebnisse nachverfolgen können. Dank der iterativen Modellentwicklung können Sie mitMLflowModellparameter und Ergebnisse protokollieren. Sehen Sie sich diese Ausführungen an, um die Leistung Ihres Modells zu vergleichen und zu verstehen. Die Protokolle liefern auch den Kontext dafür, wann Sie bereit sind, von der Entwicklungsphase zur Trainingsphase Ihrer Workflows in Azure Machine Learning überzugehen.# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Trainieren des Modells.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Hinweis
Sie können die mlflow-Warnungen ignorieren. Sie erhalten weiterhin alle Ergebnisse, die nachverfolgt werden müssen.
Durchlaufen
Nachdem Sie nun die Modellergebnisse erhalten haben, können Sie etwas ändern und es erneut versuchen. Probieren Sie beispielsweise ein anderes Klassifizierungsverfahren aus:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Hinweis
Sie können die mlflow-Warnungen ignorieren. Sie erhalten weiterhin alle Ergebnisse, die nachverfolgt werden müssen.
Untersuchen der Ergebnisse
Nachdem Sie nun zwei verschiedene Modelle ausprobiert haben, verwenden Sie die von MLFfow nachverfolgten Ergebnisse, um zu entscheiden, welches Modell besser ist. Sie können auf Metriken wie Genauigkeit oder andere Indikatoren verweisen, die für Ihre Szenarien am wichtigsten sind. Sie können diese Ergebnisse ausführlicher untersuchen, indem Sie sich die von MLflow erstellten Aufträge ansehen.
Kehren Sie zu Ihrem Arbeitsbereich in Azure Machine Learning Studio zurück.
Wählen Sie im linken Navigationsbereich Aufträge aus.
Wählen Sie den Link zum Tutorial Entwickeln in der Cloud aus.
Es werden zwei verschiedene Aufträge angezeigt, einer für jedes der Modelle, die Sie ausprobiert haben. Diese Namen werden automatisch generiert. Verwenden Sie das Stifttool neben dem Namen, das angezeigt wird, wenn Sie mit dem Mauszeiger auf einen Namen zeigen, wenn Sie ihn umbenennen möchten.
Wählen Sie den Link für den ersten Auftrag aus. Der Name wird oben angezeigt. Sie können es auch hier mit dem Stifttool umbenennen.
Auf der Seite werden Details des Auftrags angezeigt, z. B. Eigenschaften, Ausgaben, Tags und Parameter. Unter Tags wird „estimator_name“ angezeigt, der den Typ des Modells beschreibt.
Wählen Sie die Registerkarte Metriken aus, um die Metriken anzuzeigen, die von
MLflowprotokolliert wurden. (Die Ergebnisse unterscheiden sich von Ihren, da Sie über einen anderen Trainingssatz verfügen.)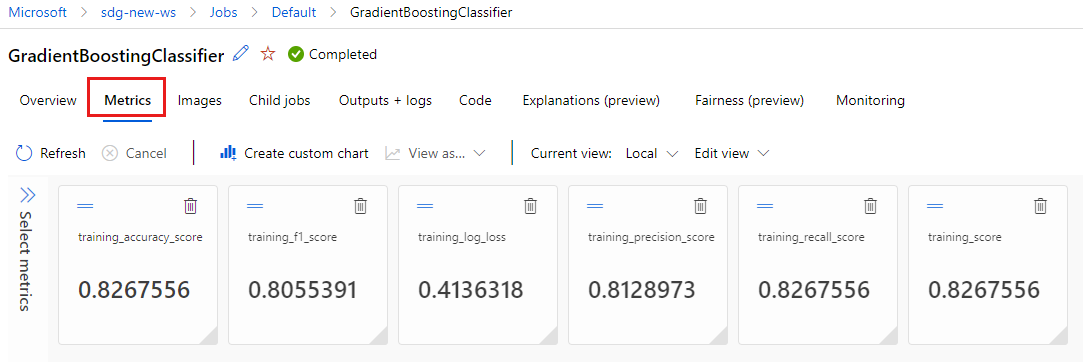
Wählen Sie die Registerkarte Images aus, um die von
MLflowgenerierten Bilder anzuzeigen.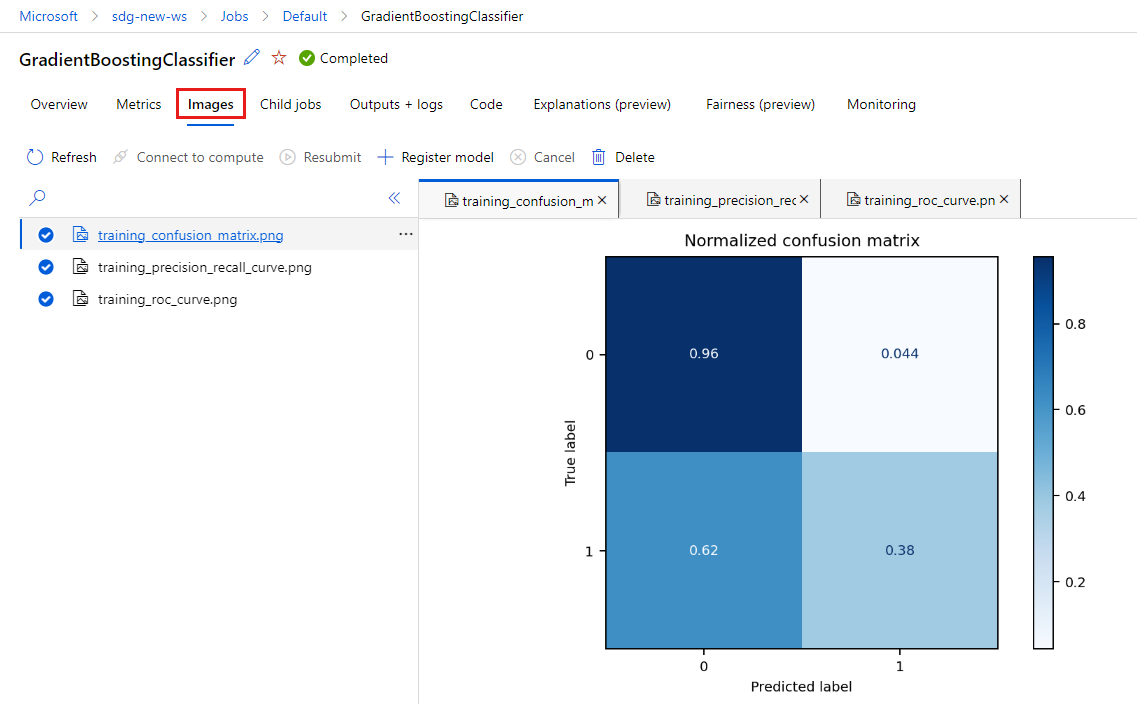
Gehen Sie zurück und überprüfen Sie die Metriken und Images für das andere Modell.
Erstellen eines Python-Skripts
Erstellen Sie nun ein Python-Skript aus Ihrem Notebook für das Modelltraining.
Klicken Sie in Ihrem VS Code-Fenster mit der rechten Maustaste auf den Dateinamen des Notebooks, und wählen Sie Notebook in Skript importieren aus.
Verwenden Sie das Menü Datei > Speichern, um diese neue Skriptdatei zu speichern. Nennen Sie sie train.py.
Durchsuchen Sie diese Datei, und löschen Sie den Code, den Sie nicht im Trainingsskript verwenden möchten. Behalten Sie beispielsweise den Code für das Modell bei, das Sie verwenden möchten, und löschen Sie Code für das Modell, das Sie nicht möchten.
- Stellen Sie sicher, dass Sie den Code beibehalten, der die automatische Protokollierung (
mlflow.sklearn.autolog()) startet. - Wenn Sie das Python-Skript (wie hier) interaktiv ausführen, können Sie die Zeile beibehalten, die den Experimentnamen definiert (
mlflow.set_experiment("Develop on cloud tutorial")). Sie können ihm sogar einen anderen Namen geben, um ihn als einen anderen Eintrag im Abschnitt Aufträge zu sehen. Wenn Sie jedoch das Skript für einen Trainingsauftrag vorbereiten, gilt diese Zeile nicht und sollte weggelassen werden. Die Auftragsdefinition enthält den Namen des Experiments. - Wenn Sie ein einzelnes Modell trainieren, sind die Linien zum Starten und Beenden einer Ausführung (
mlflow.start_run()undmlflow.end_run()) ebenfalls nicht erforderlich (sie haben keine Auswirkung), können aber beibehalten werden.
- Stellen Sie sicher, dass Sie den Code beibehalten, der die automatische Protokollierung (
Wenn Sie mit den Bearbeitungen fertig sind, speichern Sie die Datei.
Sie verfügen jetzt über ein Python-Skript, das Sie zum Trainieren Ihres bevorzugten Modells verwenden können.
Ausführen des Python-Skripts
Vorerst führen Sie diesen Code auf Ihrer Compute-Instanz aus, d. h. auf Ihrer Azure Machine Learning-Entwicklungsumgebung. Im Tutorial: Trainieren eines Modells erfahren Sie, wie Sie ein Trainingsskript auf skalierbare Weise auf leistungsstärkere Computeressourcen ausführen.
Wählen Sie die Umgebung, die Sie zuvor in diesem Tutorial erstellt haben, als Ihre Python-Version (workstations_env) aus. In der unteren rechten Ecke des Notebooks wird der Umgebungsname angezeigt. Wählen Sie ihn und dann in der Mitte des Bildschirms die Umgebung aus.
Führen Sie nun das Python-Skript aus. Verwenden Sie oben rechts das Tool Python-Datei ausführen.
Hinweis
Sie können die mlflow-Warnungen ignorieren. Sie erhalten weiterhin alle Metriken und Bilder aus der automatischen Protokollierung.
Untersuchen der Skriptergebnisse
Wechseln Sie zurück zu Aufträge in Ihrem Arbeitsbereich in Azure Machine Learning Studio, um die Ergebnisse des Trainingsskripts anzuzeigen. Beachten Sie, dass sich die Trainingsdaten mit jeder Aufteilung ändern, sodass sich die Ergebnisse auch zwischen den Ausführungen unterscheiden.
Bereinigen von Ressourcen
Wenn Sie nun mit dem anderen Tutorials fortfahren möchten, springen Sie zu Nächste Schritte.
Beenden der Compute-Instanz
Wenn Sie die Compute-Instanz jetzt nicht verwenden möchten, beenden Sie sie:
- Wählen Sie im Studio im linken Navigationsbereich Compute aus.
- Wählen Sie auf den oberen Registerkarten Compute-Instanzen aus.
- Wählen Sie in der Liste die Compute-Instanz aus.
- Wählen Sie auf der oberen Symbolleiste Beenden aus.
Löschen aller Ressourcen
Wichtig
Die von Ihnen erstellten Ressourcen können ggf. auch in anderen Azure Machine Learning-Tutorials und -Anleitungen verwendet werden.
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie diese, damit Ihnen keine Kosten entstehen:
Wählen Sie ganz links im Azure-Portal Ressourcengruppen aus.
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Wählen Sie die Option Ressourcengruppe löschen.
Geben Sie den Ressourcengruppennamen ein. Wählen Sie anschließend die Option Löschen.
Nächste Schritte
Weitere Informationen:
- Von Artefakten zu Modellen in MLflow
- Using Git with Azure Machine Learning (Verwenden von Git mit Azure Machine Learning)
- Ausführen von Jupyter Notebooks in Ihrem Arbeitsbereich
- Arbeiten mit einem Compute-Instanzterminal in Ihrem Arbeitsbereich
- Verwalten von Notebook- und Terminalsitzungen
In diesem Tutorial wurden die ersten Schritte zum Erstellen eines Modells gezeigt, wobei der Prototyp auf demselben Rechner erstellt wurde, auf dem sich auch der Code befindet. Erfahren Sie für Ihr Produktionstraining, wie Sie dieses Trainingsskript für leistungsfähigere Remotecomputeressourcen verwenden: