Behandeln von Problemen mit der Replikationswartezeit in Azure Database for MySQL – Flexible Server
GILT FÜR: Azure Database for MySQL Single Server Azure Database for MySQL Flexible Server
Azure Database for MySQL Single Server Azure Database for MySQL Flexible Server
Wichtig
Azure Database for MySQL Single Server wird eingestellt. Es wird dringend empfohlen, ein Upgrade auf Azure Database for MySQL Flexible Server auszuführen. Weitere Informationen zum Migrieren zu Azure Database for MySQL Flexible Server finden Sie unter Was geschieht mit Azure Database for MySQL Single Server?
Hinweis
Dieser Artikel enthält Verweise auf einen Begriff, den Microsoft nicht mehr verwendet. Sobald der Begriff aus der Software entfernt wurde, wird er auch aus diesem Artikel entfernt.
Mithilfe des Lesereplikat-Features können Sie Daten von einem Azure Database for MySQL-Server auf einem schreibgeschützten Replikatserver replizieren. Sie können Workloads aufskalieren, indem Sie Lese- und Berichterstellungsabfragen von der Anwendung an Replikatserver weiterleiten. Durch dieses Setup wird die Belastung des primären Servers verringert, und die Gesamtleistung und Wartezeit der Anwendung bei deren Skalierung werden verbessert.
Replikate werden asynchron mithilfe des auf der Position der nativen, binären Protokolldatei (binlog) basierenden Replikationsverfahrens der MySQL-Engine aktualisiert. Weitere Informationen finden Sie unter Binary Log File Position Based Replication Configuration Overview für MySQL.
Die Replikationsverzögerung der sekundären Lesereplikate hängt von mehreren Faktoren ab. Diese Faktoren umfassen u. a. Folgendes:
- Netzwerklatenz.
- Transaktionsvolumen auf dem Quellserver.
- Computeebene des Quellservers und des sekundären Lesereplikatservers.
- Abfragen, die auf dem Quellserver und sekundären Server ausgeführt werden.
In diesem Artikel erfahren Sie, wie Sie Probleme mit der Replikationswartezeit in Azure Database for MySQL behandeln. Außerdem erhalten Sie besseren Einblick in einige häufige Gründe für eine größere Replikationswartezeit auf Replikatservern.
Hinweis
Dieser Artikel enthält Verweise auf den Begriff Slave, einen Begriff, den Microsoft nicht mehr verwendet. Sobald der Begriff aus der Software entfernt wurde, wird er auch aus diesem Artikel entfernt.
Replikationskonzepte
Wenn binäre Protokollierung aktiviert ist, schreibt der Quellserver Transaktionen mit Commit in das binäre Protokoll. Das binäre Protokoll wird für die Replikation verwendet. Es ist standardmäßig für alle neu bereitgestellten Server aktiviert, die bis zu 16 TB Speicher unterstützen. Auf Replikatservern werden jeweils zwei Threads ausgeführt. Ein Thread ist der E/A-Thread, der andere ist der SQL-Thread:
- Der E/A-Thread stellt eine Verbindung mit dem Quellserver her und fordert aktualisierte binäre Protokolle (Transaktionsprotokolle) an. Dieser Thread empfängt die Binärprotokollaktualisierungen. Diese Updates werden auf einem Replikatserver in einem lokalen Protokoll namens Relaisprotokoll gespeichert.
- Der SQL-Thread liest das Relaisprotokoll und wendet dann die Datenänderungen auf Replikatservern an.
Überwachen der Replikationswartezeit
Azure Database for MySQL stellt die Metrik „Replication lag in seconds“ (Replikationsverzögerung in Sekunden) in Azure Monitor bereit. Diese Metrik ist nur auf Lesereplikatservern verfügbar. Sie wird mit der „seconds_behind_master“-Metrik berechnet, die in MySQL verfügbar ist.
Um die Ursache der vergrößerten Replikationswartezeit zu verstehen, stellen Sie über MySQL Workbench oder Azure Cloud Shell eine Verbindung mit dem Replikatserver her. Führen Sie dann den folgenden Befehl aus.
Hinweis
Ersetzen Sie die Beispielwerte in Ihrem Code durch den Namen des Replikatservers und den Namen des Administratorbenutzers. Für den Namen des Administratorbenutzers ist @\<servername> für Azure Database for MySQL erforderlich.
mysql --host=myreplicademoserver.mysql.database.azure.com --user=myadmin@mydemoserver -p
So sieht die Anzeige im Cloud Shell-Terminal aus:
Requesting a Cloud Shell.Succeeded.
Connecting terminal...
Welcome to Azure Cloud Shell
Type "az" to use Azure CLI
Type "help" to learn about Cloud Shell
user@Azure:~$mysql -h myreplicademoserver.mysql.database.azure.com -u myadmin@mydemoserver -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 64796
Server version: 5.6.42.0 Source distribution
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
Führen Sie im selben Azure Cloud Shell-Terminal den folgenden Befehl aus:
mysql> SHOW SLAVE STATUS;
Hier sehen Sie eine typische Ausgabe:
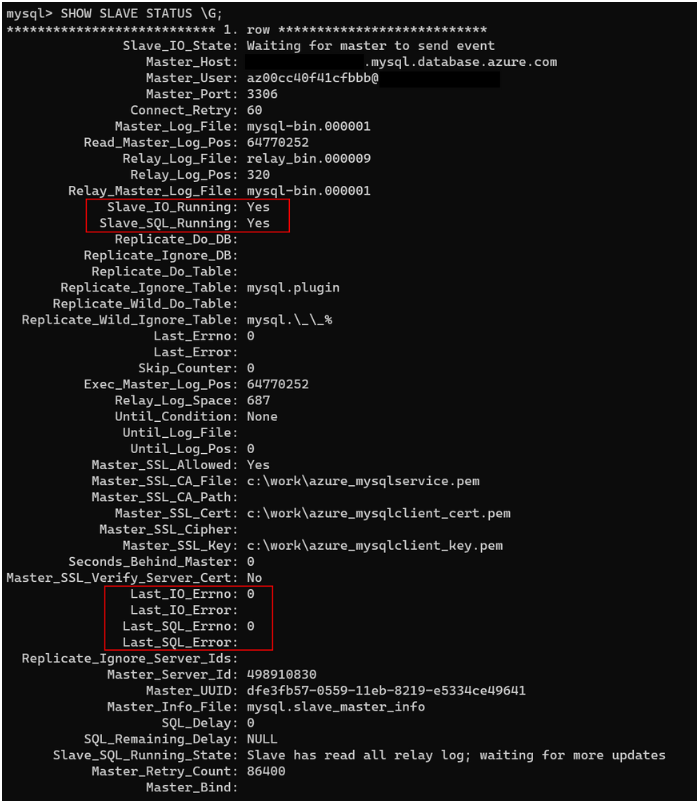
Die Ausgabe enthält zahlreiche Informationen. Normalerweise müssen Sie sich nur auf die Zeilen konzentrieren, die in der folgenden Tabelle beschrieben werden.
| Metrik | Beschreibung |
|---|---|
| Slave_IO_State | Stellt den aktuellen Status des E/A-Threads dar. Normalerweise ist der Status gleich „Waiting for master to send event“, wenn der Quellserver (Master) synchronisiert wird. Der Status „Connecting to master“ zeigt an, dass die Verbindung des Replikats mit dem Quellserver verloren gegangen ist. Stellen Sie sicher, dass der Quellserver ausgeführt wird, oder prüfen Sie, ob eine Firewall die Verbindung blockiert. |
| Master_Log_File | Stellt die binäre Protokolldatei dar, in die der Quellserver schreibt. |
| Read_Master_Log_Pos | Gibt an, an welcher Stelle in der binären Protokolldatei der Quellserver schreibt. |
| Relay_Master_Log_File | Stellt die binäre Protokolldatei dar, die der Replikatserver vom Quellserver liest. |
| Slave_IO_Running | Kennzeichnet, ob der E/A-Thread ausgeführt wird. Der Wert sollte Yes lauten. Lautet der Wert NO, ist die Replikation wahrscheinlich beschädigt. |
| Slave_SQL_Running | Kennzeichnet, ob der SQL-Thread ausgeführt wird. Der Wert sollte Yes lauten. Lautet der Wert NO, ist die Replikation wahrscheinlich beschädigt. |
| Exec_Master_Log_Pos | Zeigt die Position aus „Relay_Master_Log_File“ an, die im Replikat angewendet wird. Gibt es eine Wartezeit, sollte diese Positionssequenz kleiner sein als „Read_Master_Log_Pos“. |
| Relay_Log_Space | Zeigt die kombinierte Gesamtgröße aller vorhandenen Relais-Protokolldateien an. Sie können die obere Grenzgröße überprüfen, indem Sie SHOW GLOBAL VARIABLES wie relay_log_space_limit abfragen. |
| Seconds_Behind_Master | Zeigt die Replikationswartezeit in Sekunden an. |
| Last_IO_Errno | Zeigt ggf. den Fehlercode des E/A-Threads an. Weitere Informationen zu diesen Codes finden Sie in der Referenz der MySQL-Serverfehlermeldungen. |
| Last_IO_Error | Zeigt ggf. die Fehlermeldung des E/A-Threads an. |
| Last_SQL_Errno | Zeigt ggf. den Fehlercode des SQL-Threads an. Weitere Informationen zu diesen Codes finden Sie in der Referenz der MySQL-Serverfehlermeldungen. |
| Last_SQL_Error | Zeigt ggf. die Fehlermeldung des SQL-Threads an. |
| Slave_SQL_Running_State | Kennzeichnet den aktuellen Status des SQL-Threads. In diesem Status ist System lock normal. Es ist auch normal, wenn der Status Waiting for dependent transaction to commit angezeigt wird. Dieser Status bedeutet, dass das Replikat darauf wartet, dass SQL-Arbeitsthreads Transaktionen mit Commit aktualisieren. |
Ist „Slave_IO_Running“ gleich Yes und „Slave_SQL_Running“ gleich Yes, wird die Replikation ordnungsgemäß ausgeführt.
Überprüfen Sie im nächsten Schritt „Last_IO_Errno“, „Last_IO_Error“, „Last_SQL_Errno“ und „Last_SQL_Error“. Diese Felder zeigen jeweils die Fehlernummer und die Fehlermeldung des letzten Fehlers an, der dazu geführt hat, dass der SQL-Thread angehalten wurde. Die Fehlernummer 0 und eine leere Meldung bedeuten, dass kein Fehler vorliegt. Untersuchen Sie alle Fehlerwerte, die ungleich 0 sind, indem Sie den Fehlercode in der Referenz der MySQL-Serverfehlermeldungen überprüfen.
Übliche Szenarien für hohe Replikationswartezeit
Die folgenden Abschnitte befassen sich mit Szenarien, in denen eine hohe Replikationswartezeit üblich ist.
Netzwerklatenz oder hohe CPU-Auslastung auf dem Quellserver
Wenn die folgenden Werte angezeigt werden, wird die Replikationswartezeit wahrscheinlich durch eine hohe Netzwerklatenz oder eine hohe CPU-Auslastung auf dem Quellserver verursacht.
Slave_IO_State: Waiting for master to send event
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller than Master_Log_File, e.g. mysql-bin.00010
In diesem Fall wartet der aktive E/A-Thread auf den Quellserver. Der Quellserver hat bereits in die binäre Protokolldateinummer 20 geschrieben. Das Replikat hat nur die Dateinummer 10 empfangen. Die Hauptfaktoren für eine hohe Replikationswartezeit in diesem Szenario sind die Netzwerkgeschwindigkeit oder eine hohe CPU-Auslastung auf dem Quellserver.
In Azure kann die Netzwerklatenz innerhalb einer Region typischerweise in Millisekunden gemessen werden. Regionsübergreifend liegt die Latenz zwischen Millisekunden und Sekunden.
In den meisten Fällen wird die Verbindungsverzögerung zwischen E/A-Threads und dem Quellserver durch eine hohe CPU-Auslastung auf dem Quellserver verursacht. Die E/A-Threads werden langsam verarbeitet. Sie können dieses Problem ermitteln, indem Sie die CPU-Auslastung und die Anzahl der gleichzeitigen Verbindungen auf dem Quellserver mit Azure Monitor überprüfen.
Stellen Sie keine hohe CPU-Auslastung auf dem Quellserver fest, kann die Netzwerklatenz die mögliche Ursache sein. Wenn die Netzwerklatenz plötzlich anormal hoch ist, überprüfen Sie die Azure-Statusseite auf bekannte Probleme oder Ausfälle.
Starke Zunahme von Transaktionen auf dem Quellserver
Wenn die folgenden Werte angezeigt werden, führt eine starke Zunahme von Transaktionen auf dem Quellserver möglicherweise zu der Replikationswartezeit.
Slave_IO_State: Waiting for the slave SQL thread to free enough relay log space
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller then Master_Log_File, e.g. mysql-bin.00010
Die Ausgabe zeigt, dass das Replikat das Binärprotokoll hinter dem Quellserver abrufen kann. Der Replikat-E/A-Thread deutet jedoch darauf hin, dass der Relaisprotokollspeicherplatz bereits voll ist.
Die Netzwerkgeschwindigkeit ist nicht die Ursache für die Verzögerung. Das Replikat versucht, Schritt zu halten. Aber die aktualisierte Größe des binären Protokolls überschreitet die Obergrenze des Relaisprotokollspeicherplatzes.
Um dieses Problem zu beheben, aktivieren Sie das langsame Abfrageprotokoll auf dem Quellserver. Verwenden Sie langsame Abfrageprotokolle, um zeitintensive Transaktionen auf dem Quellserver zu erkennen. Optimieren Sie anschließend die erkannten Abfragen, um die Wartezeit auf dem Server zu verringern.
Replikationswartezeiten dieser Art werden häufig durch die Datenlast auf dem Quellserver verursacht. Wenn es auf dem Quellserver wöchentlich oder monatlich zu Datenlasten kommt, ist eine Replikationswartezeit leider unvermeidlich. Die Replikatserver ziehen schließlich gleich, nachdem die Datenlast auf dem Quellserver abgeschlossen ist.
Langsamkeit auf dem Replikatserver
Wenn Sie die folgenden Werte sehen, könnte das Problem auf dem Replikatserver liegen.
Slave_IO_State: Waiting for master to send event
Master_Log_File: The binary log file sequence equals to Relay_Master_Log_File, e.g. mysql-bin.000191
Read_Master_Log_Pos: The position of master server written to the above file is larger than Relay_Log_Pos, e.g. 103978138
Relay_Master_Log_File: mysql-bin.000191
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Exec_Master_Log_Pos: The position of slave reads from master binary log file is smaller than Read_Master_Log_Pos, e.g. 13468882
Seconds_Behind_Master: There is latency and the value here is greater than 0
In diesem Szenario zeigt die Ausgabe, dass sowohl der E/A-Thread als auch der SQL-Thread ordnungsgemäß ausgeführt werden. Das Replikat liest dieselbe binäre Protokolldatei, die der Quellserver schreibt. Auf dem Replikatserver tritt jedoch eine gewisse Wartezeit auf, bis die jeweilige Transaktion des Quellservers eingetragen ist.
In den folgenden Abschnitten werden häufige Ursachen für diese Art von Wartezeit beschrieben.
Kein Primärschlüssel oder eindeutiger Schlüssel für eine Tabelle
Für Azure Database for MySQL wird zeilenbasierte Replikation verwendet. Der Quellserver schreibt Ereignisse in das binäre Protokoll und zeichnet Änderungen in einzelnen Tabellenzeilen auf. Der SQL-Thread wiederum repliziert diese Änderungen in die entsprechenden Tabellenzeilen auf dem Replikatserver. Wenn einer Tabelle ein Primärschlüssel oder ein eindeutiger Schlüssel fehlt, führt der SQL-Thread einen Scan aller Zeilen in der Zieltabelle aus, um die Änderungen anzuwenden. Dieser Scan kann eine Replikationswartezeit verursachen.
In MySQL ist der Primärschlüssel ein zugeordneter Index, der eine hohe Abfrageleistung sicherstellt, da er keine NULL-Werte enthalten darf. Wenn Sie die InnoDB-Speicher-Engine verwenden, werden die Tabellendaten physisch angeordnet, um extrem schnelle Lookup- und Sortiervorgänge auf Basis des Primärschlüssels durchzuführen.
Es empfiehlt sich, vor dem Erstellen des Replikatservers auf dem Quellserver einen Primärschlüssel für Tabellen hinzuzufügen. Fügen Sie Primärschlüssel auf dem Quellserver hinzu, und erstellen Sie Lesereplikate neu, um die Replikationswartezeit zu verkürzen.
Verwenden Sie die folgende Abfrage, um herauszufinden, bei welchen Tabellen ein Primärschlüssel auf dem Quellserver fehlt:
select tab.table_schema as database_name, tab.table_name
from information_schema.tables tab left join
information_schema.table_constraints tco
on tab.table_schema = tco.table_schema
and tab.table_name = tco.table_name
and tco.constraint_type = 'PRIMARY KEY'
where tco.constraint_type is null
and tab.table_schema not in('mysql', 'information_schema', 'performance_schema', 'sys')
and tab.table_type = 'BASE TABLE'
order by tab.table_schema, tab.table_name;
Zeitintensive Abfragen auf dem Replikatserver
Die Workload auf dem Replikationsserver kann zu einer Verzögerung zwischen SQL-Thread und E/A-Thread führen. Zeitintensive Abfragen auf dem Replikatserver sind eine der häufigsten Ursachen für eine lange Replikationswartezeit. Um dieses Problem zu beheben, aktivieren Sie das langsame Abfrageprotokoll auf dem Replikatserver.
Langsame Abfragen können die Ressourcennutzung erhöhen oder den Server verlangsamen, sodass der Replikatserver nicht mit dem Quellserver Schritt halten kann. Optimieren Sie in diesem Szenario die langsamen Abfragen. Schnellere Abfragen verhindern das Blockieren von SQL-Threads und verkürzen die Replikationswartezeit erheblich.
DDL-Abfragen auf dem Quellserver
Auf dem Quellserver kann ein Befehl der Datendefinitionssprache (DDL) wie ALTER TABLE viel Zeit in Anspruch nehmen. Während der DDL-Befehl ausgeführt wird, werden auf dem Quellserver möglicherweise Tausende weiterer Abfragen parallel ausgeführt.
Wenn der DDL-Befehl repliziert wird, muss der DDL-Befehl von der MySQL-Engine in einem einzigen Replikationsthread ausgeführt werden, damit die Konsistenz der Datenbank sichergestellt ist. Während dieser Aufgabe werden alle anderen replizierten Abfragen blockiert und müssen warten, bis der DDL-Vorgang auf dem Replikatserver abgeschlossen ist. Auch Online-DDL-Vorgänge verursachen diese Verzögerung. DDL-Vorgänge erhöhen die Replikationswartezeit.
Wenn Sie das langsame Abfrageprotokoll auf dem Quellserver aktiviert haben, können Sie dieses Latenzproblem ermitteln, indem Sie nach einem auf dem Quellserver ausgeführten DDL-Befehl suchen. Durch das Ablegen, Umbenennen und Erstellen eines Index können Sie den INPLACE-Algorithmus für die ALTER TABLE-Anweisung verwenden. Möglicherweise müssen Sie die Tabellendaten kopieren und die Tabelle neu erstellen.
Typischerweise werden für den INPLACE-Algorithmus gleichzeitige DML-Vorgänge unterstützt. Sie können jedoch kurz eine exklusive Metadatensperre für die Tabelle erstellen, wenn Sie den Vorgang vorbereiten und ausführen. Bei der CREATE INDEX-Anweisung können Sie also mit den Klauseln ALGORITHM und LOCK die Methode zum Kopieren von Tabellen und den Grad der Gleichzeitigkeit von Lese- und Schreibvorgängen beeinflussen. Sie können DML-Vorgänge trotzdem verhindern, indem Sie einen FULLTEXT- oder SPATIAL-Index hinzufügen.
Im folgenden Beispiel wird mithilfe von ALGORITHM- und LOCK-Klauseln ein Index erstellt.
ALTER TABLE table_name ADD INDEX index_name (column), ALGORITHM=INPLACE, LOCK=NONE;
Für eine DDL-Anweisung, die eine Sperre erfordert, ist es leider nicht möglich, Replikationswartezeit zu vermeiden. Um die möglichen Auswirkungen zu verringern, sollten DDL-Vorgänge dieser Art außerhalb der Stoßzeiten durchgeführt werden, z. B. in der Nacht.
Heruntergestufter Replikatserver
In Azure Database for MySQL verwenden Lesereplikate dieselbe Serverkonfiguration wie der Quellserver. Sie können die Replikatserverkonfiguration nach der Erstellung ändern.
Wird der Replikatserver herabgestuft, kann die Workload zu einer höheren Ressourcenauslastung führen, die wiederum zu einer Replikationswartezeit führen kann. Zum Erkennen dieses Problem verwenden Sie Azure Monitor, um die CPU-Auslastung und die Arbeitsspeichernutzung des Replikationsservers zu überprüfen.
In diesem Szenario sollten die Konfigurationswerte des Replikationsservers gleich oder größer als die Werte des Quellservers sein. Diese Konfiguration ermöglicht, dass das Replikat mit dem Quellserver Schritt hält.
Verkürzen der Replikationswartezeit durch Optimieren der Parameter auf dem Quellserver
In Azure Database for MySQL ist die standardmäßig Replikation so optimiert, dass sie mit parallelen Threads für Replikate ausgeführt wird. Wenn Workloads mit großer Parallelität auf dem Quellserver dazu führen, dass der Replikatserver nicht Schritt halten kann, können Sie die Replikationswartezeit verkürzen, indem Sie den Parameter „binlog_group_commit_sync_delay“ auf dem Quellserver konfigurieren.
Mit dem Parameter „binlog_group_commit_sync_delay“ wird gesteuert, wie viele Mikrosekunden für das Commit des binären Protokolls gewartet wird, bevor die binäre Protokolldatei synchronisiert wird. Der Vorteil dieses Parameters besteht darin, dass der Quellserver die Aktualisierungen des binären Protokolls in einem Block sendet, anstatt jede Transaktion mit Commit sofort anzuwenden. Durch diese Verzögerung werden die E/A-Vorgänge auf dem Replikatserver verringert, wodurch sich die Leistung verbessert.
Es kann sinnvoll sein, den Parameter „binlog_group_commit_sync_delay“ beispielsweise auf 1000 festzulegen. Überwachen Sie dann die Replikationswartezeit. Verwenden Sie diesen Parameter mit Bedacht und nur für Workloads mit großer Parallelität.
Wichtig
Für den Replikatserver sollte der Parameter „binlog_group_commit_sync_delay“ auf „0“ festgelegt sein. Dies wird empfohlen, da der Replikatserver im Gegensatz zum Quellserver nicht über eine hohe Parallelität verfügt und die Erhöhung des Werts für „binlog_group_commit_sync_delay“ für den Replikatserver eine ungewollte Erhöhung der Replikationsverzögerung zur Folge haben kann.
Für Workloads mit geringer Parallelität, die viele Singleton-Transaktionen enthalten, kann die „binlog_group_commit_sync_delay“-Einstellung die Latenz erhöhen. Die Latenz kann sich erhöhen, weil der E/A-Thread auf Massenupdates von binären Protokollen wartet, selbst wenn nur einige wenige Transaktionen committet wird.
Erweiterte Problembehandlungsoptionen
Wenn die Verwendung des Befehls „show slave status“ nicht genügend Informationen zur Problembehandlung für die Replikationswartezeit bietet, versuchen Sie, diese zusätzlichen Optionen anzuzeigen, um zu erfahren, welche Prozesse aktiv sind oder warten.
Anzeigen der Tabelle der Threads
Die performance_schema.threads-Tabelle zeigt den Prozessstatus an. Ein Prozess mit dem Status „Waiting“ (warten) für den lock_type (Sperrtyp) „lock“ (Sperre) gibt an, dass es für eine der Tabellen eine Sperre gibt, die verhindert, dass der Replikationsthread die Tabelle aktualisiert.
SELECT name, processlist_state, processlist_time FROM performance_schema.threads WHERE name LIKE '%slave%';
Weitere Informationen finden Sie unter Allgemeine Threadstatus.
Anzeigen der Tabelle „replication_connection_status“
Die Tabelle „performance_schema.replication_connection_status“ zeigt den aktuellen Status des Replikations-E/A-Threads an, der die Verbindung des Replikats mit der Quelle verarbeitet, und er wird häufiger geändert. Die Tabelle enthält Werte, die während der Verbindung variieren.
SELECT * FROM performance_schema.replication_connection_status;
Anzeigen der Tabelle „replication_applier_status_by_worker“
In der performance_schema.replication_applier_status_by_worker-Tabelle werden die Status der Arbeitsthreads, die zuletzt gesehene Transaktion zusammen mit der letzten Fehlernummer und der Meldung angezeigt, die Ihnen helfen, die Transaktion mit dem Problem zu finden und die Grundursache zu identifizieren.
Sie können die folgenden Befehle in der Replikation eingehender Daten ausführen, um Fehler oder Transaktionen zu überspringen:
az_replication_skip_counter
oder
az_replication_skip_gtid_transaction
SELECT * FROM performance_schema.replication_applier_status_by_worker;
Anzeigen der Anweisung „SHOW RELAYLOG EVENTS“
Die show relaylog events-Anweisung zeigt die Ereignisse im Relaisprotokoll eines Replikats an.
· Für die GITD-basierte Replikation (Lesereplikat) zeigt die Anweisung die GTID-Transaktion und die Binärprotokolldatei und deren Position an. Sie können „mysqlbinlog“ verwenden, um Inhalte und Anweisungen abzurufen, die ausgeführt werden. · Für die Positionsreplikation des MySQL-Binärprotokolls (das für die Datenreplikation verwendet wird) werden Anweisungen angezeigt, die ausgeführt werden. Dies hilft herauszufinden, für welche Tabellen Transaktionen ausgeführt werden
Überprüfen der Ausgabe des InnoDB-Standardmonitors und des Sperrmonitors
Sie können auch versuchen, die Ausgabe des InnoDB-Standardmonitors und des Sperrmonitors zu überprüfen, um Sperren und Deadlocks aufzulösen und die Replikationsverzögerung zu minimieren. Der Sperrmonitor ist identisch mit dem Standardmonitor, außer dass er zusätzliche Sperrinformationen enthält. Um diese zusätzlichen Informationen zu Sperren und Deadlocks anzuzeigen, führen Sie den Befehl „show engine innodb status\G“ aus.
Nächste Schritte
Weitere Informationen finden Sie in der Übersicht über die binlog-Replikation in MySQL.