Übersicht über die Geschäftskontinuität mit Azure Database for PostgreSQL – Flexible Server
GILT FÜR:  Azure Database for PostgreSQL – Flexibler Server
Azure Database for PostgreSQL – Flexibler Server
Geschäftskontinuität in Azure Database for PostgreSQL – Flexible Server bezieht sich auf die Mechanismen, Richtlinien und Verfahren, die es Ihrem Unternehmen ermöglichen, angesichts von Störungen, insbesondere in der Computerinfrastruktur, weiter zu arbeiten. In den meisten Fällen behandelt Azure Database for PostgreSQL Flexible Server die Störungen, die in der Cloudumgebung auftreten können, und stellt sicher, dass Ihre Anwendungen und Geschäftsprozesse weiter ausgeführt werden. Es gibt jedoch einige Ereignisse, die nicht automatisch behandelt werden können. Hierzu zählen beispielsweise folgende:
- Ein Benutzer löscht oder aktualisiert versehentlich eine Zeile in einer Tabelle.
- Ein Erdbeben verursacht einen Stromausfall und deaktiviert eine Verfügbarkeitszone oder -region vorübergehend.
- Erforderliches Datenbankpatching, um einen Fehler oder ein Sicherheitsproblem zu beheben.
Der flexible Azure Database for PostgreSQL-Server bietet Features, die Daten schützen und Downtimes für Ihre unternehmenskritischen Datenbanken während Ereignissen mit geplanten und ungeplanten Downtimes reduzieren. Der Azure Database for PostgreSQL Flexible Server baut auf der Azure-Infrastruktur auf, die robuste Resilienz und Verfügbarkeit bietet. Er hat Features für die Geschäftskontinuität, die einen zusätzlichen Fehlerschutz bieten, Anforderungen an die Wiederherstellungszeit erfüllen und die Gefahr von Datenverlusten verringern. Wenn Sie die Architektur Ihrer Anwendungen entwerfen, sollten Sie die Downtimetoleranz – die Recovery Time Objective (RTO) – und die Datenverlustgefahr – die Recovery Point Objective (RPO) – berücksichtigen. Beispielsweise müssen für Ihre unternehmenskritische Datenbank strengere Uptimeanforderungen erfüllt werden als bei einer Testdatenbank.
Die folgende Tabelle veranschaulicht die Features, die Azure Database for PostgreSQL Flexible Server bietet.
| Feature | Beschreibung | Überlegungen |
|---|---|---|
| Automatische Sicherungen | Azure Database for PostgreSQL Flexible Server führt automatisch tägliche Sicherungen Ihrer Datenbankdateien durch und sichert kontinuierlich Transaktionsprotokolle. Sicherungen können zwischen 7 Tagen und 35 Tagen aufbewahrt werden. Sie können Ihren Datenbankserver für jeden beliebigen Zeitpunkt innerhalb des Aufbewahrungszeitraums Ihrer Sicherung wiederherstellen. RTO hängt von der Größe der wiederherzustellenden Daten und der Zeit für die Durchführung der Protokollwiederherstellung ab. Der Wert kann zwischen wenigen Minuten und 12 Stunden liegen. Weitere ausführliche Informationen finden Sie unter Konzepte: Sicherung und Wiederherstellung. | Sicherungsdaten verbleiben innerhalb der Region. |
| Zonenredundante Hochverfügbarkeit | Azure Database for PostgreSQL Flexible Server kann mit zonenredundanter Hochverfügbarkeitskonfiguration bereitgestellt werden, bei der primäre und Standbyserver in zwei verschiedenen Verfügbarkeitszonen innerhalb einer Region bereitgestellt werden. Diese Hochverfügbarkeitskonfiguration schützt Ihre Datenbank vor Fehlern auf Zonenebene und hilft auch bei der Reduzierung der Downtime von Anwendungen während geplanter und ungeplanter Downtimeereignisse. Die Daten vom primären Server werden im synchronen Modus auf das Standbyreplikat repliziert. Im Falle einer Unterbrechung des primären Servers erfolgt automatisch ein Failover für den Server auf das Standbyreplikat. In den meisten Fällen wird ein RTO von unter 120 s erwartet. Es wird erwartet, dass RPO den Wert 0 (kein Datenverlust) hat. Weitere Informationen finden Sie unter [Konzepte – Hohe Verfügbarkeit]/azure/reliability/reliability-postgresql-flexible-server. | Unterstützt auf den Computeebenen „Allgemeiner Zweck“ und „Arbeitsspeicheroptimiert“. Nur verfügbar in Regionen, in denen mehrere Zonen verfügbar sind. |
| Hochverfügbarkeit in derselben Zone | Azure Database for PostgreSQL Flexibler Server kann mit Konfiguration der Hochverfügbarkeit (HA) in derselben Zone bereitgestellt werden, wobei primäre und Standbyserver innerhalb einer Region in derselben Zone bereitgestellt werden. Diese Hochverfügbarkeitskonfiguration schützt Ihre Datenbank vor Fehlern auf Knotenebene und hilft auch bei der Reduzierung der Downtime von Anwendungen während geplanter und ungeplanter Downtimeereignisse. Die Daten vom primären Server werden im synchronen Modus auf das Standbyreplikat repliziert. Im Falle einer Unterbrechung des primären Servers erfolgt automatisch ein Failover für den Server auf das Standbyreplikat. In den meisten Fällen wird ein RTO von unter 120 s erwartet. Es wird erwartet, dass RPO den Wert 0 (kein Datenverlust) hat. Weitere Informationen finden Sie unter [Konzepte – Hohe Verfügbarkeit]/azure/reliability/reliability-postgresql-flexible-server. | Unterstützt auf den Computeebenen „Allgemeiner Zweck“ und „Arbeitsspeicheroptimiert“. |
| Managed Disks Premium | Datenbankdateien werden in einem sehr langlebigen und zuverlässigen verwalteten Premiumspeicher gespeichert. Dies bietet Datenredundanz mit drei Replikatkopien, die in einer Verfügbarkeitszone mit automatischer Datenwiederherstellung gespeichert sind. Weitere Informationen finden Sie in der Dokumentation zu verwalteten Datenträgern. | In einer Verfügbarkeitszone gespeicherte Daten. |
| Zonenredundante Sicherung | Sicherungen von Azure Database for PostgreSQL Flexible Server werden automatisch und sicher in einem zonenredundanten Speicher innerhalb einer Region gespeichert, sofern die Region die Verfügbarkeitszonen unterstützt. Wenn es auf der Ebene der Zone, in der Ihr Server bereitgestellt ist, zu einem Ausfall kommt und Ihr Server nicht mit Zonenredundanz konfiguriert ist, können Sie Ihre Datenbank mithilfe des neuesten Wiederherstellungspunkts in einer anderen Zone wiederherstellen. Weitere Informationen finden Sie unter Konzepte: Sicherung und Wiederherstellung. | Nur gültig in Regionen, in denen mehrere Zonen verfügbar sind. |
| Georedundante Sicherung | Sicherungen von Azure Database for PostgreSQL Flexible Server werden in eine Remoteregion kopiert. Dies hilft bei der Notfallwiederherstellung im Fall eines Ausfalls der primären Serverregion. | Dieses Feature ist derzeit in ausgewählten Regionen aktiviert. Je nach Größe der wiederherzustellenden Daten und Umfang der durchzuführenden Wiederherstellung ist das RTO länger und das RPO höher. |
| Lesereplikat | Regionsübergreifende Lesereplikate können bereitgestellt werden, um Ihre Datenbanken vor Ausfällen auf Regionsebene zu schützen. Lesereplikate werden mithilfe der physischen Replikationstechnologie von PostgreSQL asynchron aktualisiert und können damit zu Verzögerungen auf dem primären Server führen. Weitere Informationen finden Sie unter Konzepte für Lesereplikate. | Unterstützt auf den Computeebenen „Allgemeiner Zweck“ und „Arbeitsspeicheroptimiert“. |
In der folgenden Tabelle werden RTO und RPO in einem Szenario mit einer typischen Workload verglichen:
| Funktion | Burstfähig | Allgemeiner Zweck | Arbeitsspeicheroptimiert |
|---|---|---|---|
| Point-in-Time-Wiederherstellung von Sicherung | Beliebiger Wiederherstellungspunkt innerhalb der Aufbewahrungsdauer RTO: variiert RPO < 5 min |
Beliebiger Wiederherstellungspunkt innerhalb der Aufbewahrungsdauer RTO: variiert RPO < 5 min |
Beliebiger Wiederherstellungspunkt innerhalb der Aufbewahrungsdauer RTO: variiert RPO < 5 min |
| Geowiederherstellung von georeplizierten Sicherungen | RTO: variiert RPO < 1 Std. |
RTO: variiert RPO < 1 Std. |
RTO: variiert RPO < 1 Std. |
| Lesereplikate | RTO – Minuten* RPO < 5 Min.* |
RTO – Minuten* RPO < 5 Min.* |
RTO – Minuten* RPO < 5 Min.* |
* RTOs und RPOs können in einigen Fällen in Abhängigkeit von verschiedenen Faktoren wie der Latenz zwischen den Standorten, der Menge der zu übertragenden Daten und vor allem der Schreibworkload in der primären Datenbank deutlich höher sein.
Geplante Downtimeereignisse
Im Folgenden finden Sie einige Szenarien mit geplanter Wartung. Diese Ereignisse verursachen in der Regel bis zu wenige Minuten Downtime, und diese ohne Datenverlust.
| Szenario | Process |
|---|---|
| Computeskalierung (vom Benutzer initiiert) | Während des Computeskalierungsvorgangs können aktive Prüfpunkte abgeschlossen werden, Clientverbindungen werden entladen, alle Transaktionen ohne Commit werden abgebrochen, Speicher wird getrennt, und der Server wird anschließend heruntergefahren. Eine neue Azure Database for PostgreSQL Flexible Serverinstanz mit demselben Datenbankservernamen wird mit der skalierten Computekonfiguration bereitgestellt. Der Speicher wird dann an den neuen Server angefügt und die Datenbank gestartet, die bei Bedarf eine Wiederherstellung durchführt, bevor sie Clientverbindungen akzeptiert. |
| Hochskalieren des Speichers (vom Benutzer initiiert) | Wenn ein Vorgang zum Hochskalieren des Speichers initiiert wird, können aktive Prüfpunkte abgeschlossen werden, Clientverbindungen werden entladen, und alle Transaktionen, die noch nicht committet wurden, werden abgebrochen. Danach wird der Server heruntergefahren. Der Speicher wird auf die gewünschte Größe skaliert und dann an den neuen Server angefügt. Bei Bedarf wird eine Wiederherstellung ausgeführt, bevor Clientverbindungen akzeptiert werden. Beachten Sie, dass die Herunterskalierung der Speichergröße nicht unterstützt wird. |
| Bereitstellung neuer Software (von Azure initiiert) | Das Rollout neuer Features oder die Behebung von Fehlern erfolgt automatisch als Teil der geplanten Wartungsarbeiten des Diensts, und Sie können planen, wann diese Aktivitäten stattfinden sollen. Weitere Informationen finden Sie in Ihrem Portal. |
| Upgrades auf Nebenversionen (von Azure initiiert) | Azure Database for PostgreSQL patcht Datenbankserver automatisch auf die von Azure festgelegte Nebenversion. Dies erfolgt im Rahmen der geplanten Wartung des Diensts. Der Datenbankserver wird automatisch mit der neuen Nebenversion neu gestartet. Weitere Informationen finden Sie in der Dokumentation. Sie können auch in Ihrem Portal nachsehen. |
Wenn die flexible Serverinstanz von Azure Database für PostgreSQL mit hoher Verfügbarkeit konfiguriert ist, führt der Dienst zuerst die Skalierung und die Wartungsvorgänge auf dem Standbyserver aus. Weitere Informationen finden Sie unter [Konzepte – Hohe Verfügbarkeit]/azure/reliability/reliability-postgresql-flexible-server.
Minimierung von ungeplanter Downtime
Ungeplante Downtimes können aufgrund von unvorhergesehenen Unterbrechungen auftreten, darunter Fehler in der zugrunde liegenden Hardware, Netzwerkprobleme und Softwarefehler. Wenn der mit Hochverfügbarkeit konfigurierte Datenbankserver unerwartet ausfällt, wird das Standbyreplikat aktiviert, und die Clients können ihren Betrieb fortsetzen. Wenn er nicht mit Hochverfügbarkeit konfiguriert wurde, wird bei Fehlschlagen des Neustartversuchs automatisch ein neuer Datenbankserver bereitgestellt. Ungeplante Downtime lässt sich zwar nicht vollständig vermeiden, wird aber von Azure Database for PostgreSQL Flexible Server durch automatisches Ausführen von Wiederherstellungsvorgängen minimiert, ohne dass ein Eingreifen durch einen Benutzer erforderlich ist.
Obwohl wir uns kontinuierlich darum bemühen, eine hohe Verfügbarkeit zu gewährleisten, kann es vorkommen, dass Azure Database for PostgreSQL Flexibler Server ausfällt, sodass die Datenbank nicht verfügbar ist und Ihre Anwendung beeinträchtigt wird. Wenn unsere Dienstüberwachung Probleme erkennt, die zu weit verbreiteten Konnektivitätsfehlern, Ausfällen oder Leistungsproblemen führen, deklariert der Dienst automatisch einen Ausfall, um Sie auf dem Laufenden zu halten.
Dienstunterbrechung
Im Falle eines Azure Database für PostgreSQL Flexible Serverausfalls können Sie weitere Details zu dem Ausfall an den folgenden Stellen anzeigen:
- Banner im Azure-Portal: Wenn festgestellt wird, dass Ihr Abonnement betroffen ist, wird in den Benachrichtigungen im Azure-Portal ein Systemproblem mit einer Ausfallwarnung angezeigt.
- Hilfe + Support oder Support + Problembehandlung: Wenn Sie ein Supportticket über Hilfe + Support oder Support + Problembehandlung erstellen, werden Informationen zu Problemen angezeigt, die sich auf Ihre Ressourcen auswirken. Wählen Sie Details zum Ausfall anzeigen aus, um weitere Informationen und eine Zusammenfassung der Auswirkungen zu erhalten. Es wird auch eine Warnung auf der Seite Neue Supportanfrage angezeigt.
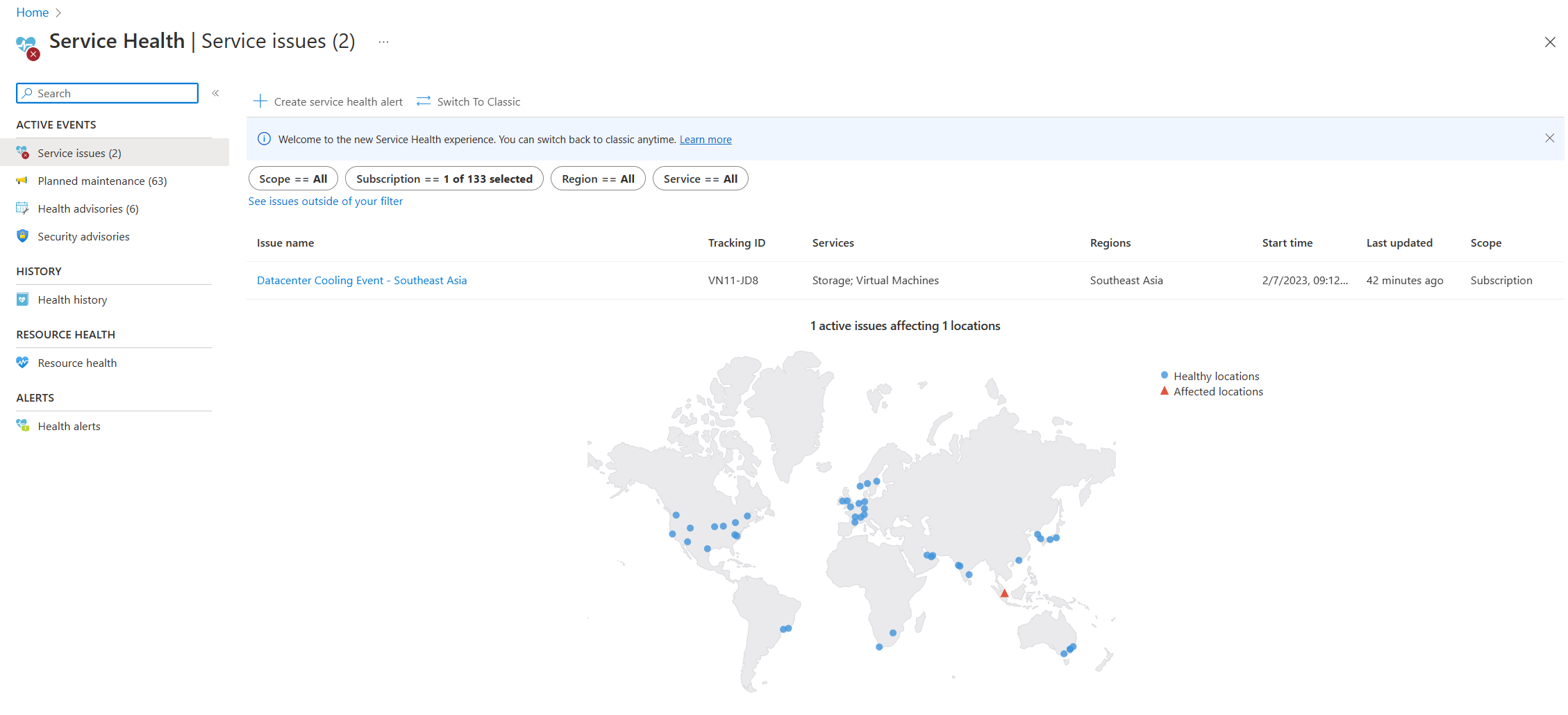
- Dienststatus: Die Seite Dienststatus im Azure-Portal enthält Informationen zum globalen Azure-Rechenzentrumsstatus. Suchen Sie in der Suchleiste im Azure-Portal nach „Dienststatus“, und zeigen Sie dann Dienstprobleme in der Kategorie Aktive Ereignisse an. Sie können die Integrität einzelner Ressourcen auch auf der Seite Ressourcenintegrität einer beliebigen Ressource im Menü Hilfe anzeigen. Es folgt ein Beispielscreenshot der Seite Dienststatus mit Informationen zu einem aktiven Dienstproblem in Südostasien.
- E-Mail-Benachrichtigung Wenn Sie Warnungen eingerichtet haben, erhalten Sie eine E-Mail-Benachrichtigung, wenn sich ein Dienstausfall auf Ihr Abonnement und Ihre Ressource auswirkt. Absender der E-Mail ist „azure-noreply@microsoft.com“. Der Text der E-Mail beginnt mit „Die Aktivitätsprotokollwarnung... wurde durch ein Dienstproblem für das Azure-Abonnement... ausgelöst“. Weitere Informationen zu Dienststatuswarnungen finden Sie unter Erstellen von Aktivitätsprotokollwarnungen zu Dienstbenachrichtigungen über das Azure-Portal.
Wichtig
Wie der Name schon sagt, werden temporäre Tabellenbereiche in PostgreSQL für temporäre Objekte sowie andere interne Datenbankvorgänge wie Sortierung verwendet. Daher wird das Erstellen von Benutzerschemaobjekten im temporären Tabellenbereich nicht empfohlen, da wir die Dauerhaftigkeit solcher Objekte nach Serverneustarts, Hochverfügbarkeitsfailovern usw. nicht garantieren.
Ungeplante Downtime: Fehlerszenarios und Dienstwiederherstellung
Im Folgenden finden Sie einige Szenarien mit ungeplanten Fehlern und dem zugehörigen Wiederherstellungsprozess.
| Szenario | Wiederherstellungsprozess [Ohne zonenredundante Hochverfügbarkeit konfigurierte Server] |
Wiederherstellungsprozess [Mit zonenredundanter Hochverfügbarkeit konfigurierte Server] |
|---|---|---|
| Ausfall des Datenbankservers | Wenn der Datenbankserver nicht verfügbar ist, versucht Azure, den Datenbankserver neu zu starten. Wenn dabei ein Fehler auftritt, wird der Datenbankserver auf einem anderen physischen Knoten neu gestartet. Die Wiederherstellungszeit (Recovery Time Objective, RTO) hängt von verschiedenen Faktoren ab, z. B. der Aktivität zum Zeitpunkt des Fehlers. Zu diesen Aktivitäten zählen große Transaktionen und das Volume der Wiederherstellungsvorgänge, die während des Starts des Datenbankservers ausgeführt wurden. Anwendungen, die die PostgreSQL-Datenbanken verwenden, müssen so konzipiert sein, dass sie getrennte Verbindungen und Transaktionsfehler erkennen und entsprechende Wiederholungsversuche durchführen. |
Wenn der Datenbankserverfehler erkannt wird, wird ein Failover des Servers auf den Standbyserver durchgeführt, wodurch die Downtime verringert wird. Weitere Informationen finden Sie unter [Konzepte – Hochverfügbarkeit]/azure/reliability/reliability-postgresql-flexible-server. Es wird erwartet, dass RTO einen Wert von 60–120 s hat, ohne Datenverlust. |
| Speicherfehler | Speicherbezogene Probleme wie der Ausfall eines Datenträgers oder physische Blockbeschädigungen haben keine Auswirkungen auf Anwendungen. Da drei Kopien der Daten gespeichert werden, wird eine Kopie der Daten vom verbleibenden Speicher bereitgestellt. Der beschädigte Datenblock wird automatisch repariert, und eine neue Kopie der Daten wird automatisch erstellt. | Bei seltenen oder nicht behebbaren Fehlern wie der Unmöglichkeit, auf den gesamten Speicher zuzugreifen, erfolgt ein Failover der Azure Database for PostgreSQL Flexible Serverinstanz auf das Standbyreplikat, um die Downtime zu reduzieren. Weitere Informationen finden Sie unter [Konzepte – Hochverfügbarkeit]/azure/reliability/reliability-postgresql-flexible-server. |
| Logische Fehler/Benutzerfehler | Zur Wiederherstellung nach Benutzerfehlern, z. B. versehentlich gelöschte Tabellen oder fehlerhaft aktualisierte Daten, müssen Sie eine Zeitpunktwiederherstellung (Point-in-Time Recovery, PITR) ausführen. Während der Ausführung des Wiederherstellungsvorgangs geben Sie den benutzerdefinierten Wiederherstellungspunkt an, bei dem es sich um den Zeitpunkt direkt vor dem Auftreten des Fehlers handelt. Wenn Sie anstelle aller Datenbanken auf dem Datenbankserver nur eine Teilmenge von Datenbanken oder bestimmte Tabellen wiederherstellen möchten, können Sie den Datenbankserver in einer neuen Instanz wiederherstellen, die Tabelle(n) über pg_dump exportieren und sie dann über pg_restore in Ihrer Datenbank wiederherstellen. |
Diese Benutzerfehler sind nicht durch Hochverfügbarkeit geschützt, da alle Änderungen synchron auf den Standbyserver repliziert werden. Sie müssen eine Zeitpunktwiederherstellung durchführen, um eine Wiederherstellung solcher Fehler zu ermöglichen. |
| Verfügbarkeitszonenfehler | Wenn Sie eine Wiederherstellung nach einem Ausfall auf Zonenebene durchführen möchten, können Sie eine Zeitpunktwiederherstellung mithilfe der Sicherung und der Auswahl eines benutzerdefinierten Wiederherstellungspunkts mit der neuesten Zeit durchführen, um die neuesten Daten wiederherzustellen. Eine neue Azure Database for PostgreSQL Flexible Serverinstanz wird in einer anderen nicht betroffenen Zone bereitgestellt. Die für die Wiederherstellung benötigte Zeit hängt von der vorherigen Sicherung und dem Volume der wiederherzustellenden Transaktionsprotokolle ab. | Für Azure Database for PostgreSQL Flexible Server erfolgt automatisch ein Failover auf den Standbyserver innerhalb von 60–120 s ohne Datenverlust. Weitere Informationen finden Sie unter [Konzepte – Hochverfügbarkeit]/azure/reliability/reliability-postgresql-flexible-server. |
| Regionsausfall | Wenn Ihr Server mit georedundanter Sicherung konfiguriert ist, können Sie die Geowiederherstellung in der gekoppelten Region durchführen. Ein neuer Server wird bereitgestellt und mit den letzten verfügbaren Daten wiederhergestellt, die in diese Region kopiert wurden. Sie können auch regionsübergreifende Lesereplikate verwenden. Bei einem Regionsausfall können Sie einen Notfallwiederherstellungsvorgang durchführen, indem Sie Ihr Lesereplikat zu einem eigenständigen Server mit Lese- und Schreibzugriff heraufstufen. Als RPO wird ein Wert von bis zu 5 Minuten erwartet (Datenverlust möglich), mit Ausnahme eines schwerwiegenden regionalen Fehlers, bei dem die RPO zum Zeitpunkt des Fehlers nahe an der Replikationsverzögerung liegen kann. |
Der gleiche Prozess. |
Konfigurieren Ihrer Datenbank nach der Wiederherstellung nach einem regionalen Ausfall
- Wenn Sie Geowiederherstellung oder Georeplikation ausführen, um Ihre Anwendung nach einem Ausfall wiederherzustellen, müssen Sie sicherstellen, dass die Verbindung mit der neuen Datenbank ordnungsgemäß konfiguriert ist, sodass der normale Anwendungsbetrieb wieder aufgenommen werden kann. Sie können die Aufgaben nach der Wiederherstellung durchführen.
- Wenn Sie zuvor eine Diagnoseeinstellung auf dem ursprünglichen Server eingerichtet haben, sollten Sie dies bei Bedarf auf dem Zielserver tun, wie unter Konfiguration und Zugriffsprotokolle für Azure Database for PostgreSQL – Flexible Server erläutert.
- Richten Sie Telemetriewarnungen ein: Sie müssen sicherstellen, dass Ihre vorhandenen Einstellungen zu Warnungsregeln aktualisiert werden, sodass auf den neuen Server verwiesen wird. Weitere Informationen zu Warnungsregeln finden Sie unter Verwenden des Azure-Portals zum Einrichten von Warnungen zu Metriken für Azure Database for PostgreSQL: Flexible Server.
Wichtig
Gelöschte Server können nicht wiederhergestellt werden. Wenn Sie den Server löschen, können Sie unsere Anleitung Wiederherstellen eines gelöschten Azure Database for PostgreSQL – Flexibler Server zur Wiederherstellung befolgen. Verwenden Sie die Azure-Ressourcensperre, um einer versehentlichen Löschung Ihres Servers vorzubeugen.