Zuverlässigkeit in Azure KI Search
In Azure bedeutet Zuverlässigkeit Resilienz und Verfügbarkeit, wenn ein Dienstausfall oder eine Verschlechterung vorhanden ist. In Azure KI Search kann Zuverlässigkeit innerhalb eines einzelnen Diensts oder über mehrere Suchdienste in separaten Regionen erreicht werden.
Stellen Sie einen einzelnen Suchdienst bereit und skalieren Sie für hohe Verfügbarkeit. Sie können mehrere Replikate hinzufügen, um höhere Indizierungs- und Abfrageworkloads zu verarbeiten. Wenn Ihr Suchdienst Verfügbarkeitszonenunterstützt, werden Replikate automatisch in verschiedenen physischen Rechenzentren für zusätzliche Resilienz bereitgestellt.
Stellen Sie mehrere Suchdienste in verschiedenen geografischen Regionen bereit. Alle Suchworkloads sind vollständig in einem einzigen Dienst enthalten, der in einer einzelnen geografischen Region ausgeführt wird, aber in einem Szenario mit mehreren Diensten haben Sie Optionen zum Synchronisieren von Inhalten, sodass sie für alle Dienste gleich sind. Sie können auch eine Lastenausgleichslösung einrichten, um Anforderungen neu zu verteilen oder fehlschlagen zu lassen, wenn ein Dienstausfall auftritt.
Planen Sie für Geschäftskontinuität und zur Wiederherstellung aus Notfällen auf regionaler Ebene eine regionsübergreifende Topologie, die aus mehreren Suchdiensten besteht, die über identische Konfiguration und Inhalte verfügen. Ihr benutzerdefiniertes Skript oder Code stellt den Ausfall-Mechanismus für einen alternativen Suchdienst bereit, wenn ein Suchdienst plötzlich nicht mehr verfügbar ist.
Hochverfügbarkeit
In Azure KI Search handelt es sich bei Replikaten um Kopien Ihres Index. Ein Suchdienst wird mit mindestens einem Replikat in Auftrag gegeben und kann bis zu 12 Replikate enthalten. Das Hinzufügen von Replikatenermöglicht es Azure KI Search, Computerneustarts und Wartungsaktivitäten für ein Replikat durchzuführen, während gleichzeitig in den anderen Replikaten weiterhin Abfragen ausgeführt werden.
Für jeden einzelnen Suchdienst garantiert Microsoft eine Verfügbarkeit von mindestens 99,9 Prozent, sofern die Konfigurationen die folgenden Kriterien erfüllen:
Zwei Replikate für Hochverfügbarkeit von schreibgeschützten Workloads (Abfragen)
Drei oder mehr Replikate für Hochverfügbarkeit von Lese-/Schreib-Workloads (Abfragen und Indizierung)
Das System verfügt über interne Mechanismen zur Überwachung der Replikatintegrität und Partitionsintegrität. Wenn Sie eine bestimmte Kombination aus Replikaten und Partitionen bereitstellen, stellt das System sicher, dass die Kapazitätsauslastung für Ihren Dienst erreicht wird.
Für den Free-Tarif wird keine Vereinbarung zum Service Level (SLA) bereitgestellt. Weitere Informationen finden Sie unter SLA für Azure KI-Suche.
Unterstützung für Verfügbarkeitszonen
Verfügbarkeitszonen sind eine Funktion der Azure-Plattform und dienen dazu, die Rechenzentren einer Region in verschiedene physische Standortgruppen zu unterteilen, um Hochverfügbarkeit innerhalb der Region zu gewährleisten. In Azure KI Search sind einzelne Replikate die Einheiten für die Zonenzuweisung. Ein Suchdienst wird innerhalb einer Region ausgeführt; Ihre Replikate werden in verschiedenen physischen Rechenzentren (oder Zonen) innerhalb dieser Region ausgeführt.
Verfügbarkeitszonen werden verwendet, wenn Sie Ihrem Suchdienst zwei oder mehr Replikate hinzufügen. Jedes Replikat wird in einer anderen Verfügbarkeitszone innerhalb der Region platziert. Wenn Sie mehr Replikate als verfügbare Zonen in der Suchdienstregion haben, werden die Replikate so gleichmäßig wie möglich verteilt. Es gibt keine spezifische Aktion Ihrerseits, abgesehen vom Erstellen eines Suchdiensts in einer Region mit Verfügbarkeitszonen und dem anschließenden Konfigurieren des Diensts für die Verwendung mehrerer Replikate.
Voraussetzungen
- Die Dienstebene muss Standard oder höher sein.
- Die Dienstregion muss sich in einer Region befinden, die über verfügbare Zonen verfügt (im folgenden Abschnitt aufgeführt).
- Die Konfiguration muss mehrere Replikate enthalten: zwei für schreibgeschützte Abfrageworkloads, drei für Lese-/Schreib-Workloads, die Indizierung enthalten.
Unterstützte Regionen
Die Unterstützung für Verfügbarkeitszonen hängt von der Infrastruktur und dem Speicher ab. Für die folgende Zone steht derzeit nicht genügend Speicher und keine Verfügbarkeitszone für Azure KI-Suche zur Verfügung:
- Japan, Westen
Andererseits werden Verfügbarkeitszonen für Azure KI-Suche in den folgenden Regionen unterstützt:
| Region | Rolloutdatum |
|---|---|
| Australien (Osten) | 30. Januar 2021 oder später |
| Brasilien Süd | 2. Mai 2021 oder später |
| Kanada, Mitte | 30. Januar 2021 oder später |
| Indien, Mitte | 20. Januar 2022 oder später |
| USA (Mitte) | 4. Dezember 2020 oder später |
| China, Norden 3 | 7. September 2022 oder später |
| Asien, Osten | 13. Januar 2022 oder später |
| USA, Osten | 27. Januar 2021 oder später |
| USA (Ost) 2 | 30. Januar 2021 oder später |
| Frankreich, Mitte | 23. Oktober 2020 oder später |
| Deutschland, Westen-Mitte | 3. Mai 2021 oder später |
| Israel, Mitte | 1. April 2024 oder später |
| Italien, Norden | 1. April 2024 oder später |
| Japan, Osten | 30. Januar 2021 oder später |
| Korea, Mitte | 20. Januar 2022 oder später |
| Nordeuropa | 28. Januar 2021 oder später |
| Norwegen, Osten | 20. Januar 2022 oder später |
| Katar, Mitte | 25. August 2022 oder später |
| Südafrika, Norden | 7. September 2022 oder später |
| USA Süd Mitte | 30. April 2021 oder später |
| Südostasien | 31. Januar 2021 oder später |
| Schweden, Mitte | 21. Januar 2022 oder später |
| Schweiz, Norden | 7. September 2022 oder später |
| Vereinigte Arabische Emirate, Norden | 9. September 2022 oder später |
| UK, Süden | 30. Januar 2021 oder später |
| US Government, Virginia | 30. April 2021 oder später |
| Europa, Westen | 29. Januar 2021 oder später |
| USA, Westen 2 | 30. Januar 2021 oder später |
| USA, Westen 3 | 02. Juni 2021 oder höher |
Hinweis
Verfügbarkeitszonen ändern die Bedingungen der SLA nicht. Sie benötigen für Hochverfügbarkeit weiterhin mindestens drei Replikate.
Mehrere Dienste in separaten geografischen Regionen
Dienstredundanz ist erforderlich, wenn Ihre betrieblichen Anforderungen folgendes umfassen:
Anforderungen an Business Continuity & Disaster Recovery (BCDR): Die Azure KI-Suche bietet kein sofortiges Failover bei einem Ausfall.
Schnelle Leistung für eine global verteilte Anwendung. Bei Abfrage- und Indizierungsanforderungen aus aller Welt werden die Benutzer, die dem Hostrechenzentrum am nächsten sind, schnellere Leistung erleben. Durch Erstellen weiterer Dienste in Regionen, die sich in der Nähe dieser Benutzer befinden, kann dafür gesorgt werden, dass die Leistung für alle Benutzer gleich ist.
Wenn Sie zwei oder mehr Suchdienste benötigen, können Sie sie in verschiedenen Regionen erstellen, um die Anwendungsanforderungen hinsichtlich Kontinuität und Wiederherstellung zu erfüllen und schnellere Antwortzeiten für eine globale Benutzerbasis zu erzielen.
Azure KI Search bietet keine automatisierte Methode zur regionsübergreifenden Georeplikation von Suchindizes. Es gibt allerdings einige Verfahren, mit denen sich ein solcher Prozess einfach implementieren und verwalten lässt. Diese werden in den nächsten Abschnitten beschrieben.
Ziel der Einrichtung geografisch verteilter Suchdienste ist es, über mindestens zwei Indizes in mindestens zwei Regionen zu verfügen, sodass Benutzer zum Azure KI Search-Dienst mit der geringsten Wartezeit weitergeleitet werden:
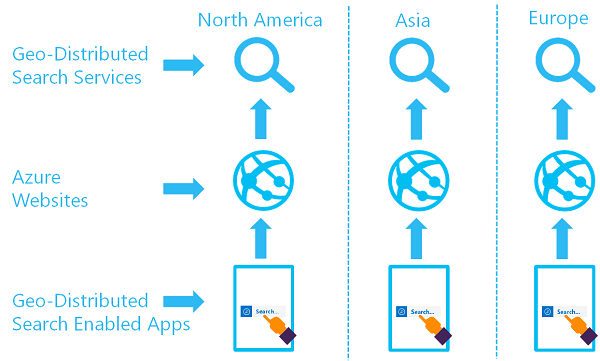
Sie können diese Architektur implementieren, indem Sie mehrere Dienste erstellen und eine Strategie für die Datensynchronisierung entwerfen. Optional können Sie eine Ressource wie Azure Traffic Manager für Routinganforderungen einschließen.
Tipp
Hilfe bei der Bereitstellung mehrerer Suchdienste in mehreren Regionen finden Sie in diesem Bicep-Beispiel auf GitHub, das eine vollständig konfigurierte, multiregionale Suchlösung bereitstellt. Das Beispiel bietet ihnen zwei Optionen für die Indexsynchronisierung und die Anforderungsumleitung mithilfe von Traffic Manager.
Synchronisieren von Daten zwischen mehreren Diensten
Es gibt zwei Optionen, um zwei oder mehr unterschiedliche Suchdienste synchron zu halten:
- Abrufen von Inhaltsaktualisierungen in einen Suchindex mithilfe eines Indexers.
- Übertragen Sie Inhalte mithilfe der „Hinzufügen oder Aktualisieren von Dokumenten“ (REST) API oder einer Azure-SDK-äquivalenten API in einen Index.
Um eine der Optionen zu konfigurieren, empfehlen wir die Verwendung des Bicep-Beispielskripts im „azure-search-multiple-region“-Repository, angepasst für Ihre Regionen und Indizierungsstrategien.
Option 1: Aktualisieren von Inhalten in mehreren Diensten mithilfe von Indexern
Wenn Sie bereits einen Indexer für einen Dienst verwenden, können Sie einen zweiten Indexer für einen zweiten Dienst so konfigurieren, dass er dasselbe Datenquellenobjekt verwendet und somit Daten vom selben Standort abruft. Jeder Dienst in jeder Region hat einen eigenen Indexer und einen Zielindex (der Suchindex wird nicht gemeinsam verwendet, sodass jeder Index seine eigene Kopie der Daten hat), aber jeder Indexer verweist auf die gleiche Datenquelle.
Diese Architektur würde ganz allgemein in etwa wie folgt aussehen.
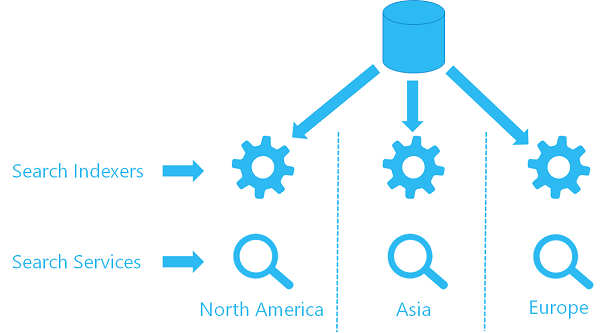
Option 2: Pushen von Inhaltsaktualisierungen in mehreren Diensten mithilfe von REST-APIs
Wenn Sie die Azure KI Search-REST-API zum Pushen von Inhalten an Ihren Suchindex verwenden, können Sie die verschiedenen Suchdienste synchronisieren, indem Sie Änderungen bei jeder Aktualisierung an alle Suchdienste pushen. Stellen Sie sicher, dass Ihr Code auch mit Fällen zurecht kommt, in denen die Aktualisierung eines einzelnen Suchdiensts nicht erfolgreich ist, andere Suchdienste aber erfolgreich aktualisiert werden.
Failover- oder Abfrageumleitungsanforderungen
Wenn Sie Redundanz auf Anforderungsebene benötigen, bietet Azure mehrere Optionen für den Lastenausgleich:
- Azure Traffic Manager wird verwendet, um Anforderungen an mehrere Websites an verschiedenen geografischen Standorten weiterzuleiten, die dann von mehreren Diensten unterstützt werden.
- Application Gateway wird verwendet, um Lastenausgleich zwischen den Servern in einer Region auf Anwendungsebene vorzunehmen.
- Azure Front Door, das zum Optimieren des globalen Routings von Webdatenverkehr und zur Bereitstellung eines globalen Failovers verwendet wird.
Einige Punkte, die beim Auswerten von Lastenausgleichsoptionen beachtet werden sollten:
Die Suche ist ein Back-End-Dienst, der Abfrage- und Indizierungsanforderungen von einem Client akzeptiert.
Anforderungen vom Client an einen Suchdienst müssen authentifiziert werden. Für den Zugriff auf Suchvorgänge muss der Aufrufer über rollenbasierte Berechtigungen verfügen oder einen API-Schlüssel für die Anforderung bereitstellen.
Dienst-Endpunkte werden standardmäßig über eine öffentliche Internetverbindung erreicht. Wenn Sie einen privaten Endpunkt für Clientverbindungen einrichten, die aus einem virtuellen Netzwerk stammen, verwenden Sie Application Gateway.
Azure KI Search akzeptiert Anforderungen, die an den
<your-search-service-name>.search.windows.netEndpunkt adressiert sind. Wenn Sie denselben Endpunkt erreichen, indem Sie einen anderen DNS-Namen im Hostheader verwenden, z. B. einen CNAME, wird die Anforderung abgelehnt.
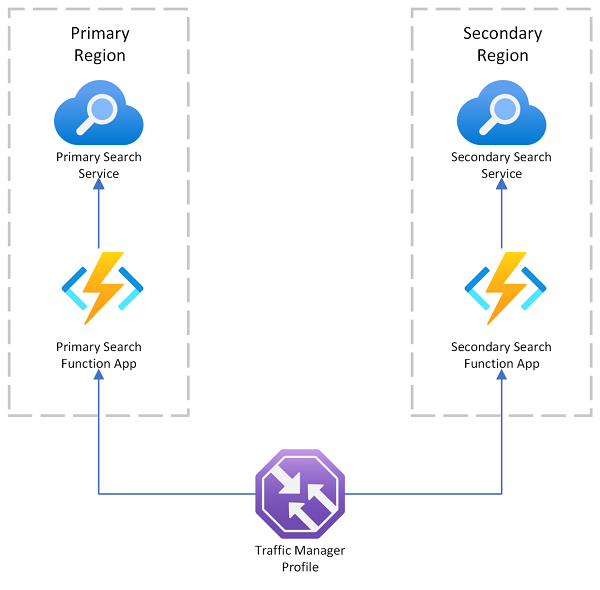
Azure KI Search bietet ein Beispiel für eine Bereitstellung mit mehreren Regionen, das Azure Traffic Manager für die Anforderungsumleitung verwendet, wenn der primäre Endpunkt fehlschlägt. Diese Lösung ist nützlich, wenn Sie an einen suchfähigen Client weiterleiten, der nur einen Suchdienst in derselben Region aufruft.
Azure Traffic Manager wird hauptsächlich für das Routing von Netzwerkdatenverkehr über verschiedene Endpunkte basierend auf bestimmten Routingmethoden (z. B. Priorität, Leistung oder geografischer Standort) verwendet. Er fungiert auf DNS-Ebene, um eingehende Anforderungen an den entsprechenden Endpunkt zu leiten. Wenn ein Endpunkt, der von Traffic Manager gewartet wird, mit der Ablehnung von Anforderungen beginnt, wird der Datenverkehr an einen anderen Endpunkt weitergeleitet.
Der Traffic Manager stellt keinen Endpunkt für eine direkte Verbindung mit Azure KI Search bereit, was bedeutet, dass Sie einen Suchdienst nicht direkt hinter Traffic Manager setzen können. Stattdessen wird davon ausgegangen, dass Anforderungen an Traffic Manager, dann an einen suchfähigen Webclient und schließlich an einen Suchdienst im Back-End fließen. Der Client und der Dienst befinden sich in derselben Region. Wenn ein Suchdienst ausfällt, fängt der Suchclient an, auszusetzen, und der Traffic Manager leitet zum verbleibenden Client um.
Datenresidenz in einer Bereitstellung mit mehreren Regionen
Wenn Sie mehrere Suchdienste in verschiedenen geografischen Regionen bereitstellen, werden Ihre Inhalte in der Region gespeichert, die Sie für jeden Suchdienst ausgewählt haben.
Azure KI-Suche speichert ohne Ihre Zustimmung keine Daten außerhalb der von Ihnen angegebenen Region. Die Autorisierung ist implizit, wenn Sie Features verwenden, welche die folgenden Daten in eine Azure Storage-Ressource schreiben: Anreicherungscache, Debugsitzung, Wissensspeicher. In allen Fällen ist das Speicherkonto eines, das Sie in der Region Ihrer Wahl angeben.
Hinweis
Wenn sich sowohl das Speicherkonto als auch der Suchdienst in derselben Region befinden, werden für den Netzwerkdatenverkehr zwischen Suchdienst und Speicher eine private IP-Adresse und das Microsoft-Backbonenetzwerk verwendet. Da private IP-Adressen verwendet werden, können Sie für Netzwerksicherheit weder IP-Firewalls noch einen privaten Endpunkt konfigurieren. Verwenden Sie stattdessen als Alternative die Ausnahme für vertrauenswürdige Dienste, wenn sich beide Dienste in der gleichen Region befinden.
Über Dienstausfälle und katastrophale Ereignisse
Wie in der SLA aufgeführt, garantiert Microsoft eine hohe Verfügbarkeit für Indexabfrageanforderungen, wenn eine Azure KI-Suche-Dienstinstanz mit zwei oder mehr Replikaten konfiguriert ist, und für Indexaktualisierungsanforderungen, wenn eine Azure KI-Suche-Dienstinstanz mit drei oder mehr Replikaten konfiguriert ist. Es steht jedoch kein integrierter Mechanismus für die Notfallwiederherstellung bereit. Sollte ein unterbrechungsfreier Dienst im Falle schwerwiegender Fehler, die nicht der Kontrolle von Microsoft unterliegen, benötigt werden, empfehlen wir, dass Sie einen zweiten Dienst in einer anderen Region bereitstellen und eine Georeplikationsstrategie implementieren, um sicherzustellen, dass Indizes für alle Dienste vollständig redundant sind.
Kunden, die Indexer zum Auffüllen und Aktualisieren von Indizes verwenden, können die Notfallwiederherstellung über geospezifische Indizes ausführen, welche die gleiche Datenquelle verwenden. Zwei Dienste in unterschiedlichen Regionen, die jeweils einen Indexer ausführen, könnten die gleiche Datenquelle indizieren, um Georedundanz zu erzielen. Wenn Sie Daten aus Datenquellen indizieren, die auch georedundant sind, denken Sie daran, dass Azure KI Search-Indexer eine inkrementelle Indizierung (Zusammenführen von Updates neuer, geänderter oder gelöschter Dokumente) nur aus primären Replikaten ausführen können. Achten Sie im Falle eines Failoverereignisses darauf, den Indexer erneut auf das neue primäre Replikat umzulenken.
Wenn Sie keine Indexer verwenden, können Sie Ihren Anwendungscode verwenden, um Objekte und Daten gleichzeitig per Push an verschiedene Dienste zu übermitteln. Weitere Informationen finden Sie unter Synchronisieren von Daten über mehrere Dienste hinweg.
Alternativen für Sicherung und Wiederherstellung
Eine Geschäftskontinuitätsstrategie für die Datenschicht umfasst in der Regel einen Schritt zur Wiederherstellung aus einer Sicherungskopie. Da Azure KI Search keine primäre Datenspeicherlösung ist, wird von Microsoft kein formales Verfahren für Self-Service-Sicherung und -Wiederherstellung bereitgestellt. Sie können jedoch den index-backup-restore-Beispielcode in diesem Azure KI Search .NET-Beispielrepository verwenden, um Ihre Indexdefinition und die Schattenkopie in einer Reihe von JSON-Dateien zu sichern, und diese Dateien dann bei Bedarf zu verwenden, um den Index wiederherzustellen. Mit diesem Tool können Sie auch Indizes zwischen Dienstebenen verschieben.
Andernfalls ist Ihr Anwendungscode, der zum Erstellen und Auffüllung eines Index verwendet wird, de facto die Wiederherstellungsoption, wenn Sie aus Versehen einen Index löschen. Um einen Index neu zu erstellen, würden Sie ihn (sofern vorhanden) löschen, den Index im Dienst wiederherstellen und ihn erneut laden, indem Sie Daten aus Ihrem primären Datenspeicher abrufen.
Zugehöriger Inhalt
- Überprüfen Sie Grenzwerte des Diensts, um weitere Informationen zu den Tarifen und den Grenzwerten zu erhalten.
- Weitere Informationen zu Partitions- und Replikatkombinationen finden Sie unter Planen der Kapazität.
- Weitere Hilfe zur Konfiguration finden Sie unter Case Study: Use Cognitive Search to Support Complex AI Scenarios (Fallstudie: Verwenden von Cognitive Search zur Unterstützung komplexer KI-Szenarien).